Diffusion LLMs from the Ground Up: Training, Inference, and Practical Engineering
Diffusion LLMs Part 2: How dLLMs scale to 100B parameters, the inference stack that makes them fast, hands-on code, and when to actually use them.
Recap of Part 1
In the previous article, we built a complete understanding of how diffusion language models work from first principles.
We started with the two structural bottlenecks in autoregressive (AR) generation.
- First, sequential decoding is memory-bandwidth bound. The GPU spends the vast majority of its time shuttling weights from memory to compute cores, achieving about 1 FLOP per byte when modern hardware is designed for 100+.
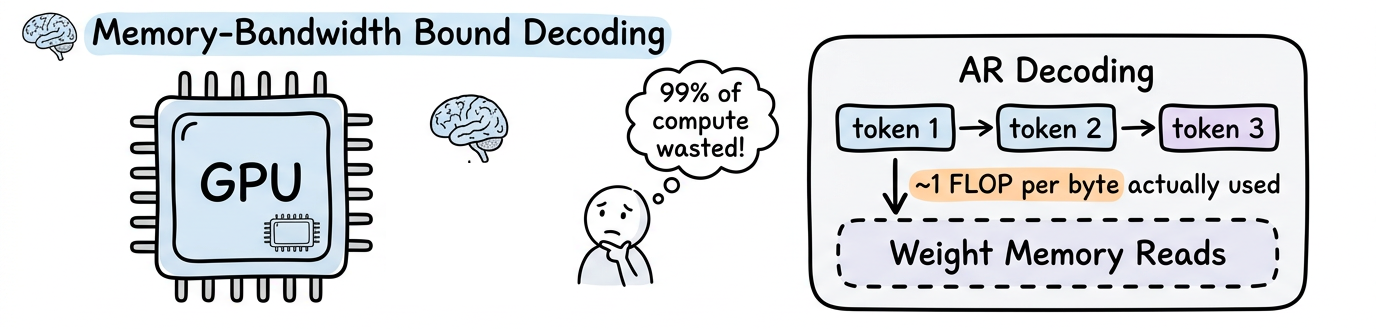
- Second, left-to-right factorization creates the reversal curse: a model trained on "A is B" cannot reliably infer "B is A" unless that ordering also appears in the training data.
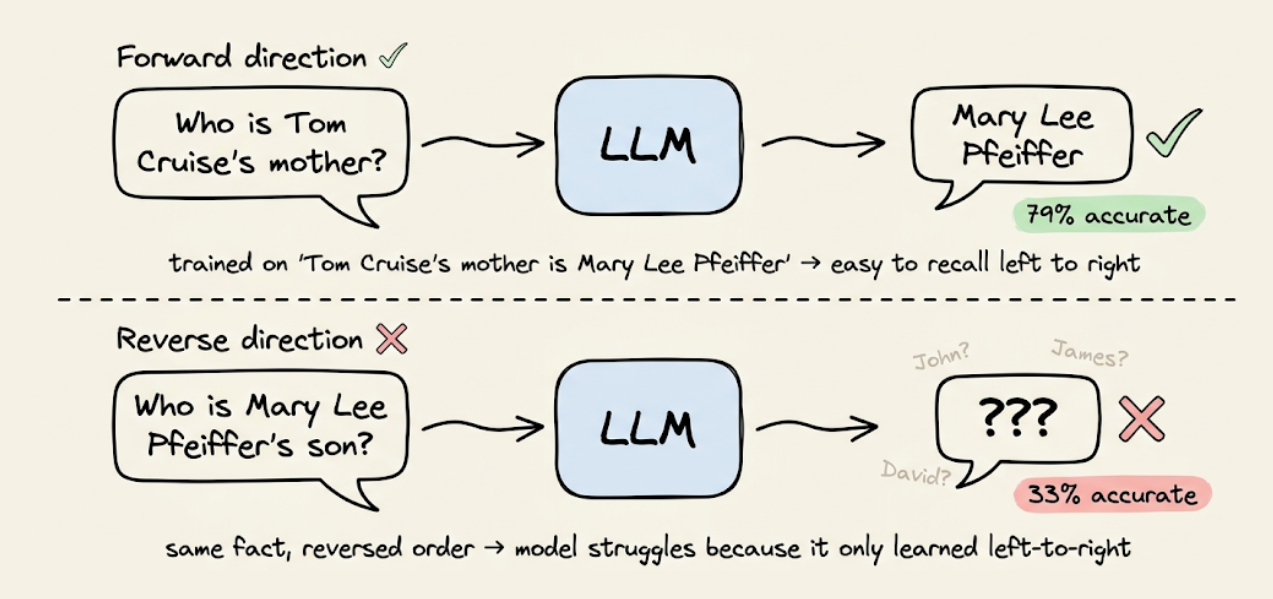
We then explored how diffusion works in images (Gaussian noise added to continuous pixel values, reversed by a denoising network) and why that approach breaks for text (tokens are discrete, you cannot add a tiny amount of noise to "cat" and get something meaningful).
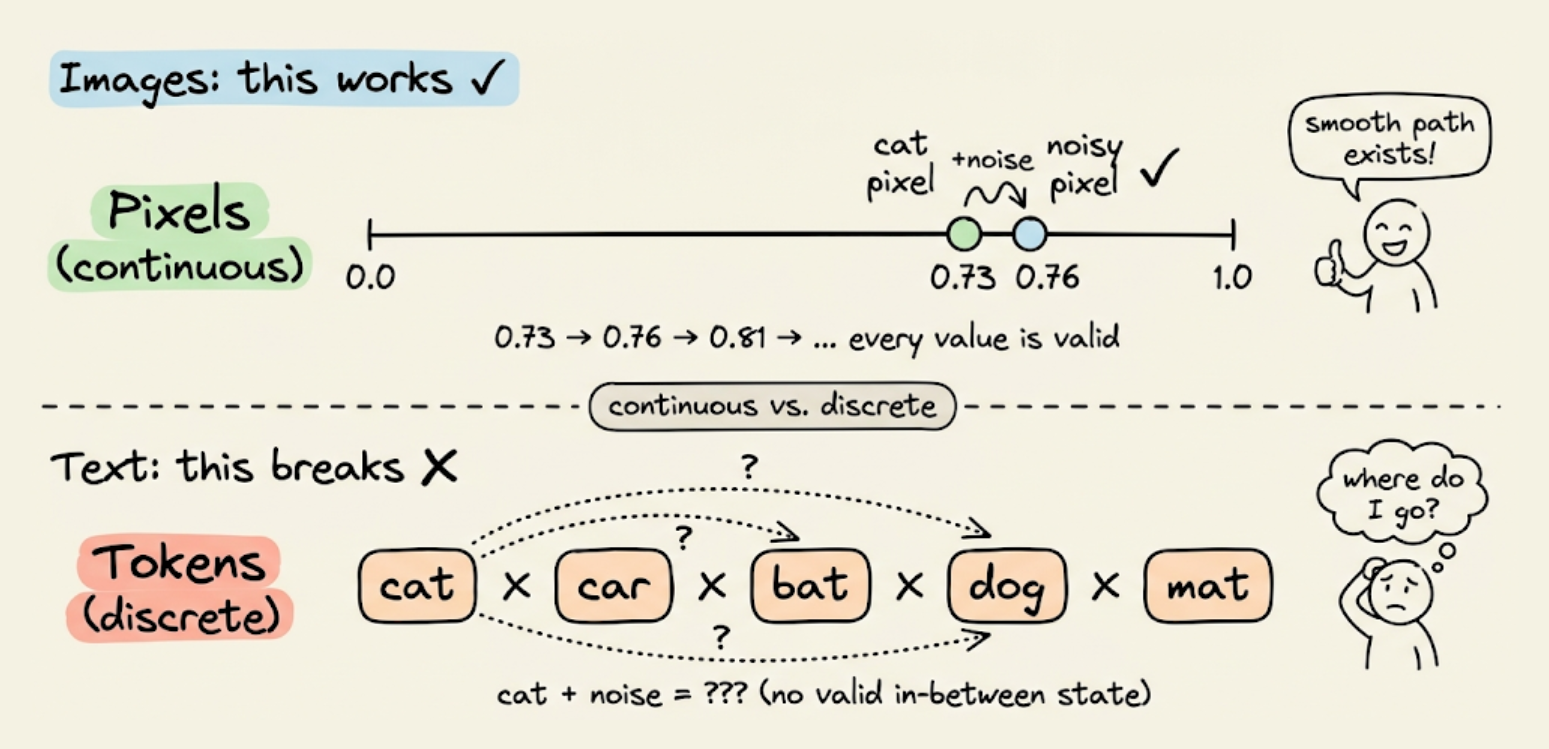
The field converged on masking as the right noise process for discrete tokens, which replaces tokens with [MASK] at increasing rates, then trains a model to predict the originals.
The reverse process uses a Transformer with bidirectional attention to predict masked tokens, weighted by an ELBO-derived $1/t$ factor that properly accounts for prediction difficulty at different masking rates.
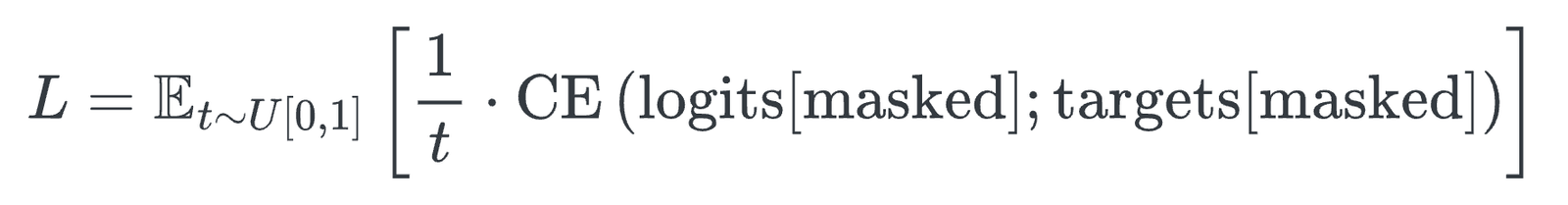
This ELBO guarantee is what separates dLLMs from BERT and makes them principled generative models.
We covered unmasking strategies (random, confidence-based, margin-based), the quality-speed dial controlled by the number of denoising steps, and block diffusion as the practical architecture that enables KV caching between blocks while using diffusion within each block.
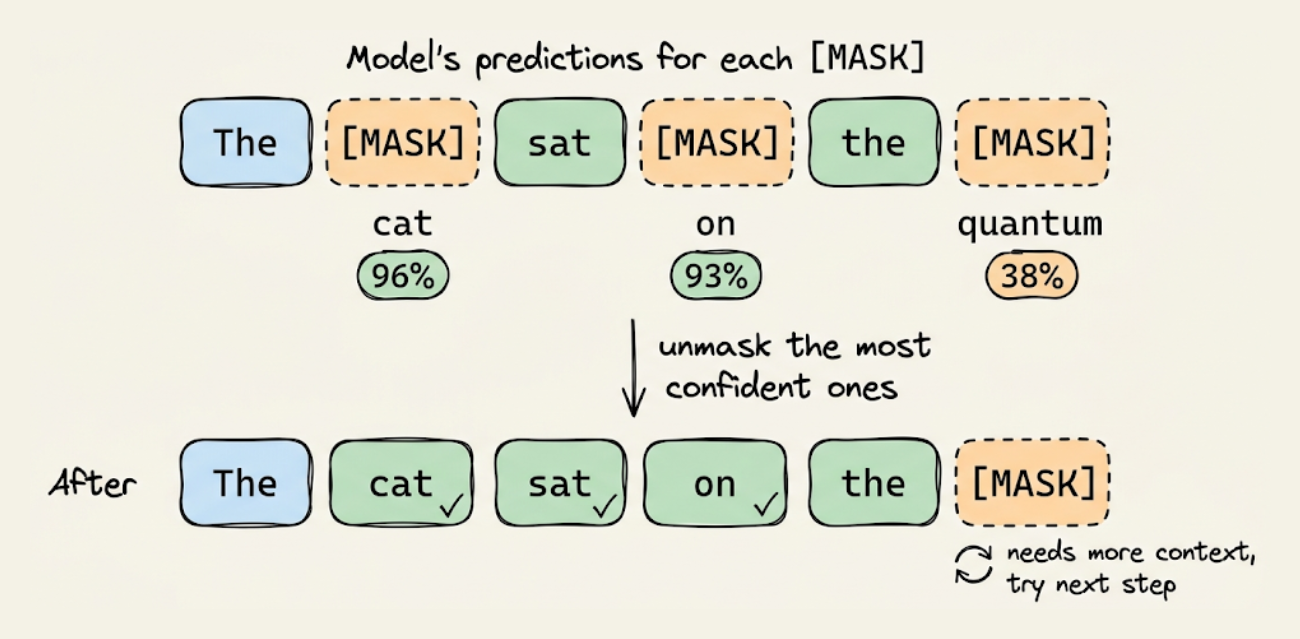
Towards the end we looked at a structured comparison of the engineering differences between AR and diffusion models across eleven dimensions: generation order, attention mechanism, training objective, KV cache compatibility, inference bottleneck type, inference flexibility, the reversal curse, quality-speed tradeoff, output length, streaming UX, and alignment maturity.
This article covers the practical side.
We will explore the training techniques that scaled dLLMs from 8B to 100B parameters (including converting pre-trained AR models into dLLMs), the inference acceleration stack (block-wise KV caching, confidence-aware parallel decoding, serving with SGLang), hands-on code for running Dream 7B and serving LLaDA 2.0, and an honest decision framework for when to choose a dLLM over an autoregressive model.
Let's begin!
Training dLLMs at scale
There are two approaches to building a large-scale dLLM.
You can train one from scratch on trillions of tokens, just like an AR model. Or you can take an existing pre-trained AR model and convert it into a dLLM through continual pre-training.
Both approaches are commonly used and produce competitive results.
Training from scratch: LLaDA 8B
LLaDA (Large Language Diffusion with mAsking) was the first dLLM trained from scratch at the 8B parameter scale.
It was published in February 2025 by Nie et al. and demonstrated that diffusion models can match autoregressive models on standard benchmarks when given comparable compute budgets.

The architecture is a standard Transformer with bidirectional attention. No architectural modifications beyond the single line of code we discussed in Part 1:
The training pipeline follows the same stages as any modern LLM, involving:
- data preparation
- pre-training on a large corpus
- and supervised fine-tuning (SFT)
LLaDA 8B was pre-trained on 2.3 trillion tokens using 0.13 million H800 GPU hours.
During pre-training, each token is masked at a ratio $t$ sampled uniformly from the range $[0, 1]$.
During SFT, only the response tokens are masked (the prompt tokens remain visible), which is the natural equivalent of how AR models only compute loss on the response during instruction tuning.
The results are worth examining closely.

- On MMLU, LLaDA 8B scores 65.9 compared to LLaMA3 8B's 65.4.
- On TruthfulQA, LLaDA scores 46.4 versus LLaMA3's 44.0.
- On HumanEval (code generation), LLaDA reaches 33.5 versus LLaMA3's 34.2.
- The model also surpasses GPT-4o on a reversal poem completion task, directly demonstrating the bidirectional advantage of diffusion models. LLaDA was accepted as an oral presentation at NeurIPS 2025.
The trade-off is straightforward. Training a dLLM from scratch costs roughly the same as training an AR model of the same size. And the computational savings of diffusion models show up at inference time, not at training time.
Diffusion models achieve this through the ELBO objective rather than next-token prediction, but the outcome is the same.
Converting AR models to dLLMs: DiffuLLaMA
Training any large model from scratch is expensive.
To make things practically feasible, can we take an existing pre-trained AR model and convert it into a dLLM?
DiffuLLaMA, published at ICLR 2025 by Hong Kong researchers, answered this conclusively.

The team converted pre-trained GPT-2 models (127M and 355M parameters) and LLaMA2 (7B parameters) into diffusion models using less than 200B tokens of continual pre-training.
The conversion involves two key steps:
- The first is attention mask annealing:
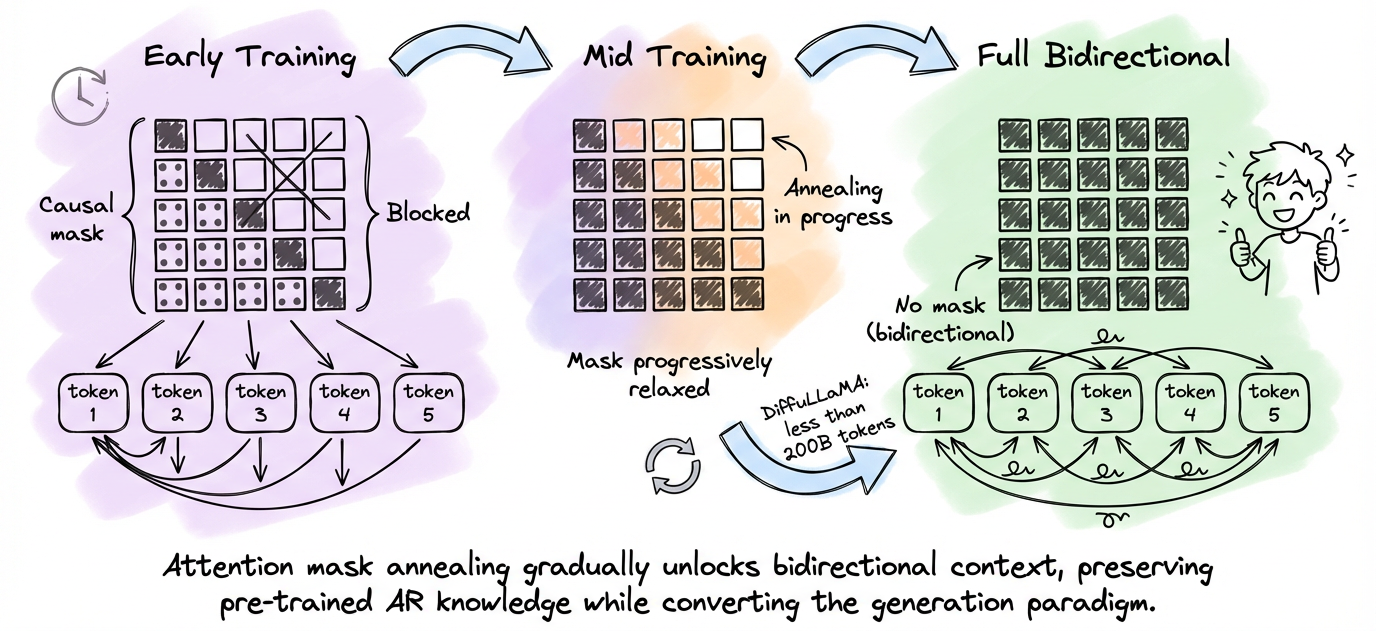
- Attention mask annealing gradually transitions from causal to bidirectional attention over the course of training.
- In the early steps, the model still mostly uses causal attention.
- As training progresses, the mask is progressively relaxed until the model operates with full bidirectional context.
- This preserves the pre-trained knowledge while changing the generation paradigm.
- The second is switching the training objective:
- The model transitions from next-token prediction to the masked diffusion objective (variable masking rate with ELBO-derived weighting).
The results show that DiffuGPT and DiffuLLaMA outperform earlier diffusion language models and are competitive with their AR counterparts on language modeling, reasoning, and common sense benchmarks.
The converted models can perform in-context learning, follow instructions, and do fill-in-the-middle generation without any special FIM training.
The trade-off is that converted models typically underperform models trained from scratch on the same data budget, because they need to "unlearn" the causal attention bias.
But the conversion cost (less than 200B tokens) is an order of magnitude cheaper than training from scratch (trillions of tokens), which makes it the practical choice when you have access to a good AR checkpoint.
Scaling to 100B: LLaDA 2.0
In December 2025, a team of reseachers released LLaDA 2.0, the first dLLM scaled to 100B parameters. This was a significant engineering milestone.
LLaDA 2.0 does not train from scratch. Instead, it converts a pre-trained AR model using a novel three-phase training scheme called block-level WSD (warm-up, stable, decay):
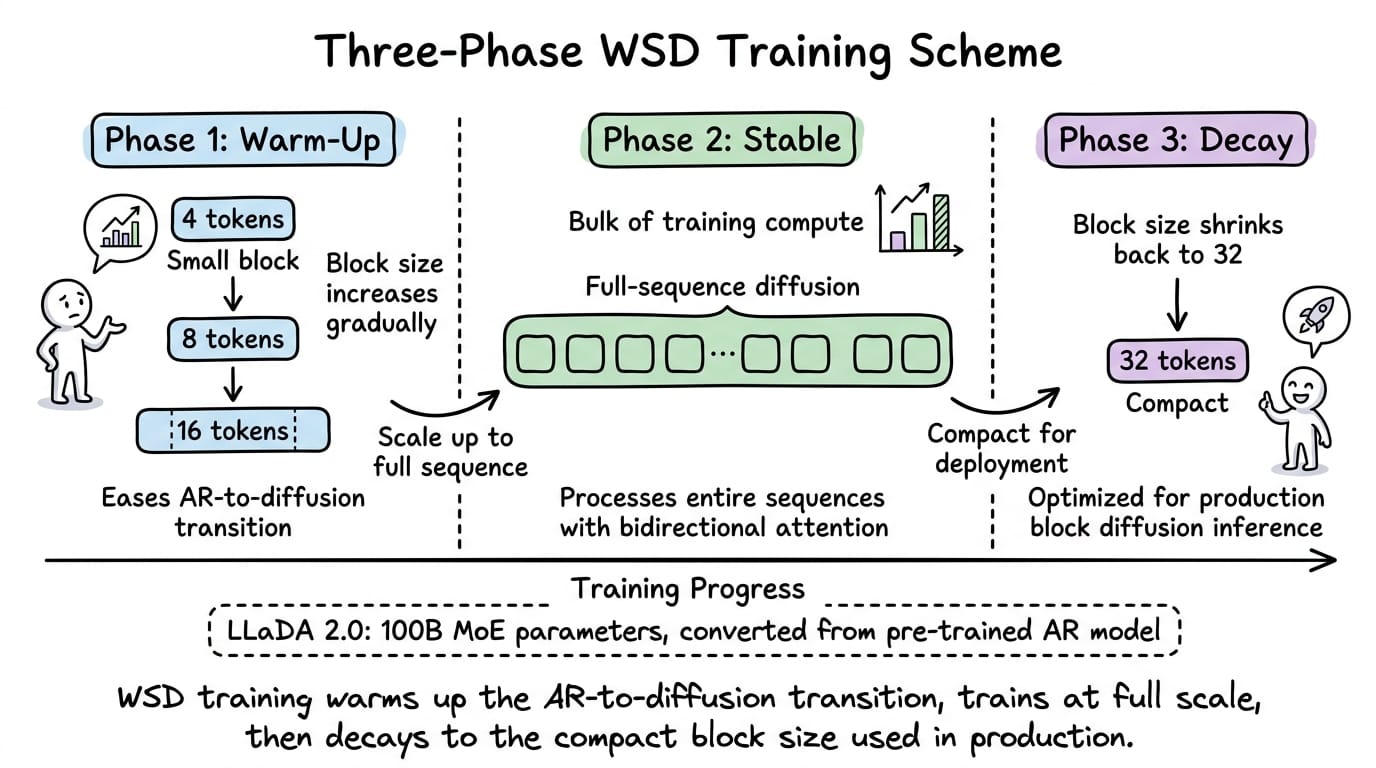
- Phase 1 (warm-up): the model trains with block diffusion, starting with small block sizes and progressively increasing them. This eases the transition from AR to diffusion by initially generating just a few tokens in parallel per block.
- Phase 2 (stable): the model trains at full-sequence diffusion scale, processing entire sequences with bidirectional attention. This is the bulk of the compute.
- Phase 3 (decay): the model reverts to compact block sizes (e.g., 32 tokens per block) for deployment efficiency. This phase optimizes the model for the block diffusion inference pattern it will actually use in production.
After pre-training conversion, the model goes through standard post-training alignment, which we do in autoregressive models like supervised fine-tuning, followed by DPO (Direct Preference Optimization).
The LLaDA 2.0 family uses a Mixture of Experts (MoE) architecture, which means not all parameters are active for every token.
Dream 7B: AR initialization with context-adaptive noise
Dream 7B, takes a different approach to the same problem. Instead of elaborate multi-phase training, it uses two simple but effective techniques.
- The first is AR-based initialization. Dream 7B initializes its weights from Qwen2.5 7B, a pre-trained AR model. This gives the model a strong starting point with rich linguistic knowledge. Training then continues with the diffusion objective on 580 billion tokens.
- The second technique is context-adaptive token-level noise rescheduling. Standard dLLMs apply the same noise schedule to every token in a sequence. But not all tokens are equally difficult to predict. For example: function words like "the" and "is" need less denoising refinement than content words like "quantum" or "architecture."
Dream's context-adaptive scheduling adjusts the effective noise level per token based on its local context during training. This means the model allocates more learning capacity to tokens that actually need it.
Coming to training, it required 96 H800 GPUs for 256 hours, which is substantially less than training from scratch. Dream 7B matches or exceeds Qwen2.5 7B and LLaMA3 8B on general, math, and coding benchmarks.
On planning tasks (Countdown and Sudoku), Dream 7B significantly outperforms AR models of the same size, even outperforming DeepSeek V3 (671B parameters) on Countdown. This planning advantage is a direct consequence of bidirectional attention enabling global constraint satisfaction.
The commercial frontier: Mercury and Gemini Diffusion
Two commercial efforts validate the dLLM paradigm at production scale.
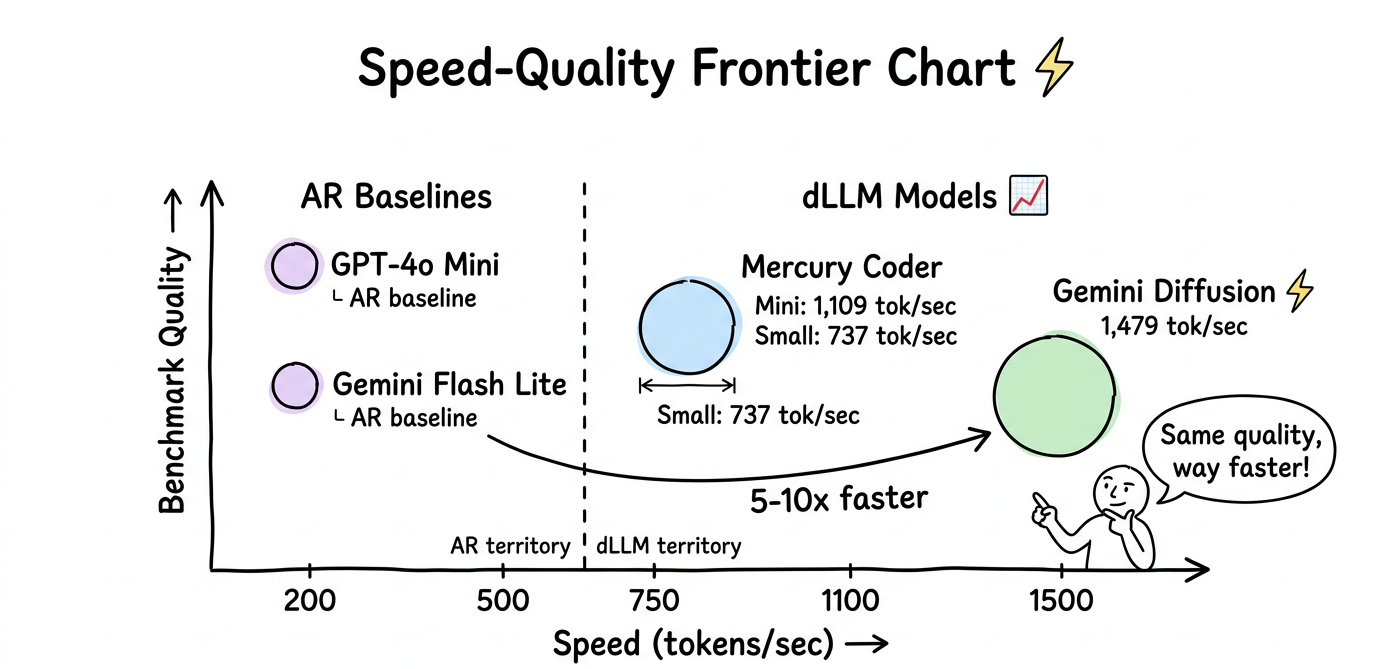
- Mercury Coder, launched in February 2025 by Inception Labs, was the first commercially available dLLM. Mercury Coder Mini achieves 1,109 tokens per second on H100 GPUs, and Mercury Coder Small reaches 737 tokens/sec. These speeds are 5 to 10 times faster than comparable AR models.
- Gemini Diffusion, announced at Google I/O in May 2025, is Google DeepMind's experimental text diffusion model. It generates at 1,479 tokens per second, roughly five times faster than Gemini 2.0 Flash Lite. On coding benchmarks, it matches its AR counterpart: HumanEval 89.6% versus 90.2%, MBPP 76.0% versus 75.8%.
Neither model is open-source, which limits hands-on experimentation. But their existence confirms that the dLLM paradigm works at production quality and scale. As of early 2026, dLLMs have moved from research papers to deployed products.
In summary, the training story has matured rapidly.
The dominant pattern in early 2026 is to initialize from a pre-trained AR model and continue training with the diffusion objective, rather than training from scratch. This is more compute-efficient and produces competitive results. Block diffusion with a compact block size (typically 32 tokens) has emerged as the standard architecture for production deployment.
The inference acceleration stack
Part 1 established that dLLMs are compute-bound rather than memory-bandwidth bound, which is a theoretical advantage.
But the practical inference speed of early open-source dLLMs (LLaDA, Dream) was often slower than AR models.
The gap between theoretical advantage and practical speed was closed through three key innovations, which were block-wise KV caching, confidence-aware parallel decoding, and production-grade serving infrastructure.
The inference problem
Recall from Part 1 that pure bidirectional attention is incompatible with KV caching.
In an AR model, once a token is generated, its key-value states in the attention layers are cached and reused for all subsequent tokens. This avoids redundant computation.