A Detailed and Beginner-Friendly Introduction to PyTorch Lightning: The Supercharged PyTorch
Immensely simplify deep learning model building with PyTorch Lightning.
Introduction
PyTorch is the go-to choice for researchers and practitioners for building deep learning models due to its flexibility, intuitive Pythonic API design, and ease of use.
It takes a programmer just three steps to create a deep learning model in PyTorch:
- First, we define a model class inherited from PyTorch’s
nn.Moduleclass

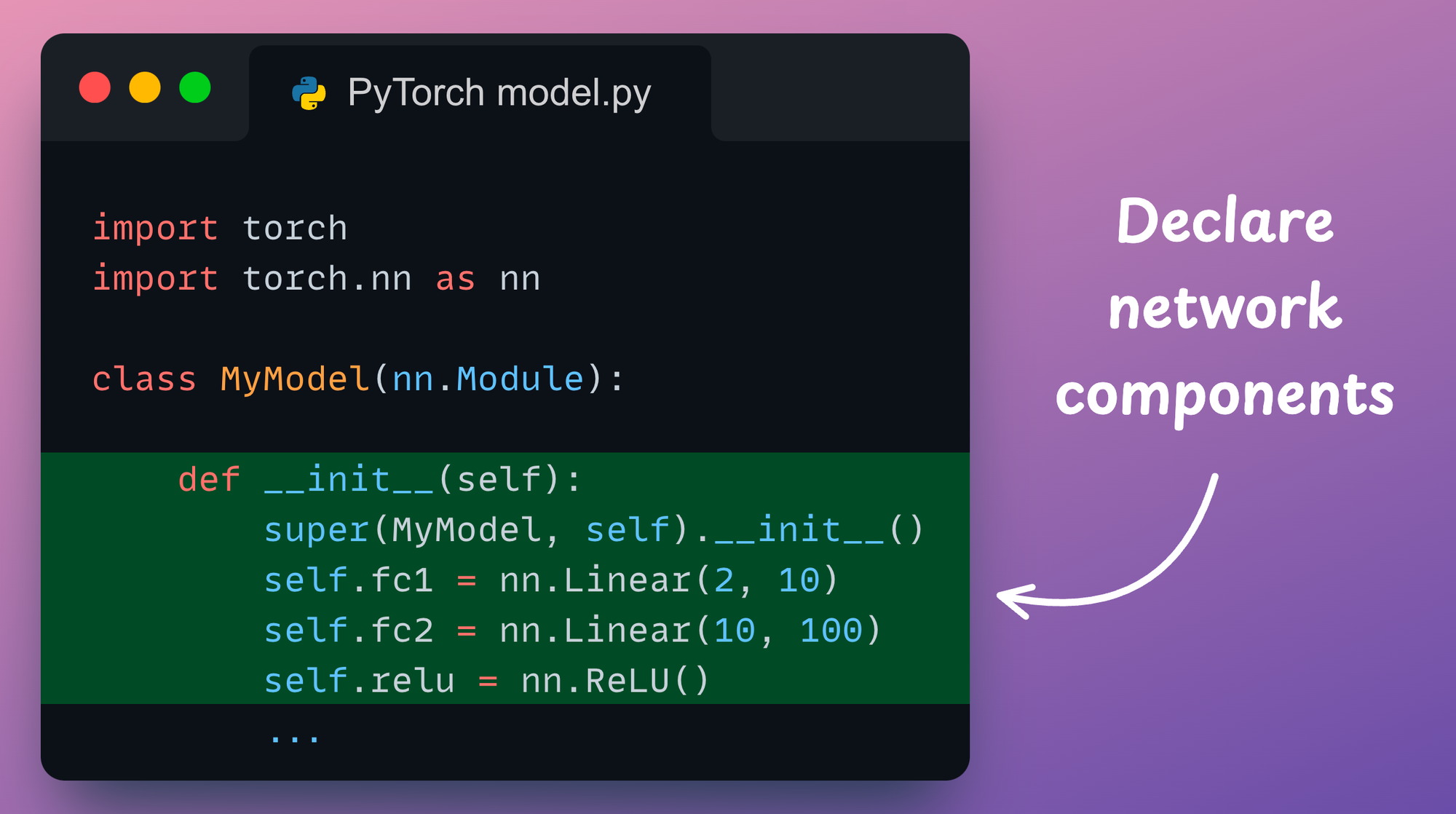
- Moving on, we declare all the network components (layers, dropout, batch norm, etc.) in the
__init__()method:
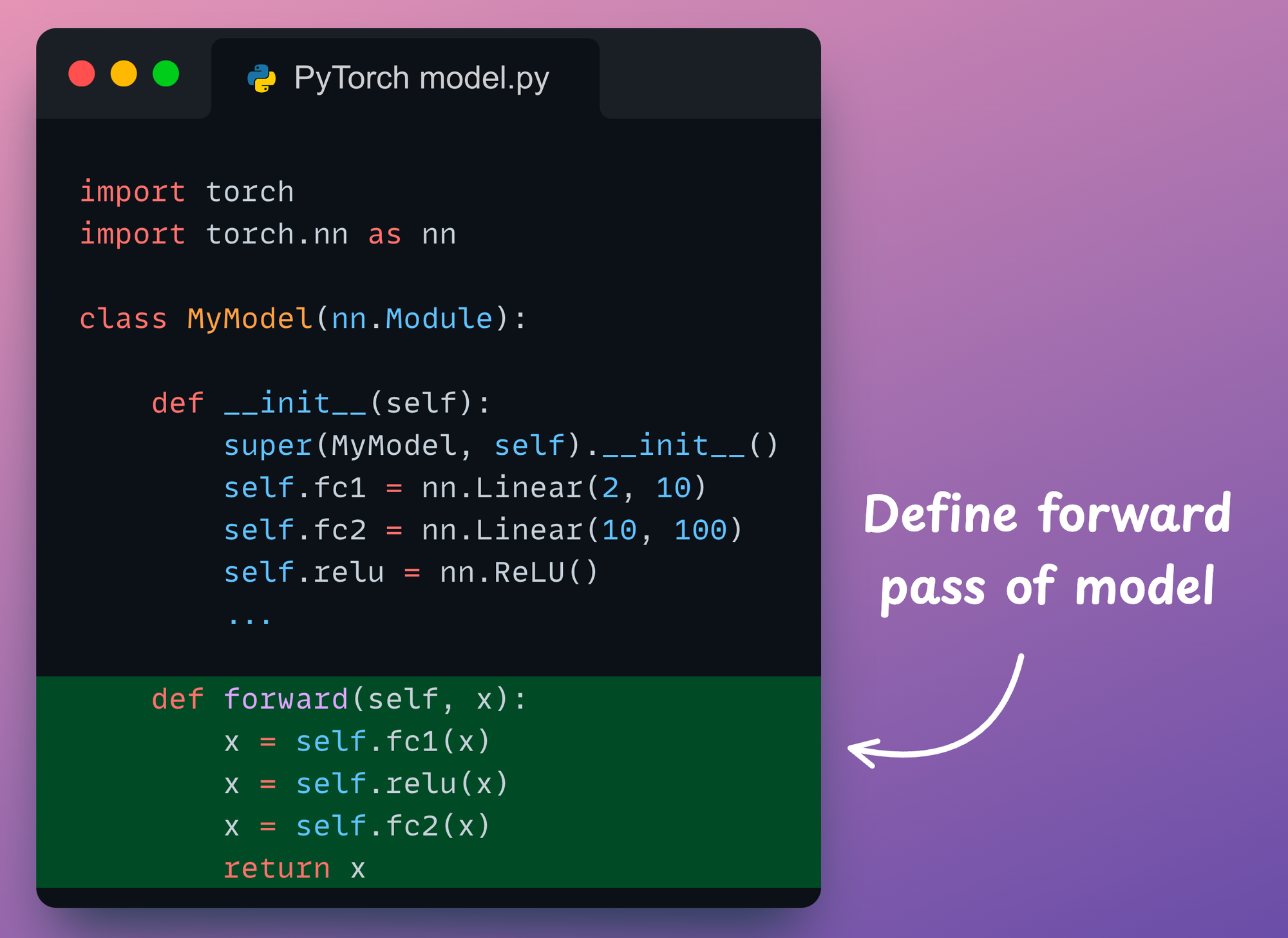
- Finally, we define the forward pass of the neural network in the
forward()method:
That’s it!
Once we have defined the network, we can proceed with training the model by declaring the optimizer, loss function, etc., without having to define the backward pass explicitly.
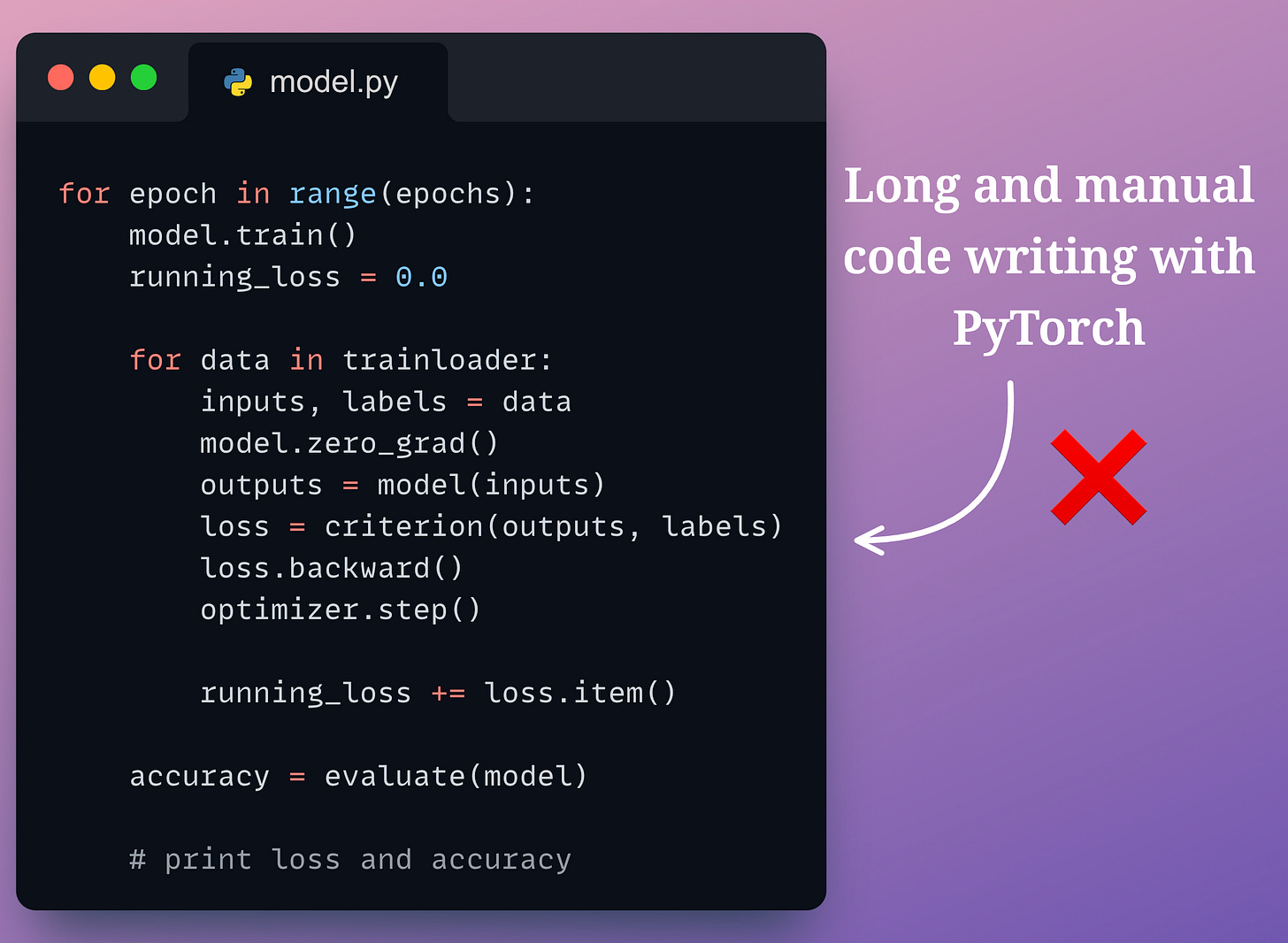
More specifically, one can define the training loop as demonstrated below and train the model easily:
Issues with PyTorch
As we saw above, defining the network was so simple and elegant, wasn’t it?
However, as our models grow more complex and larger, several challenges arise when using PyTorch:
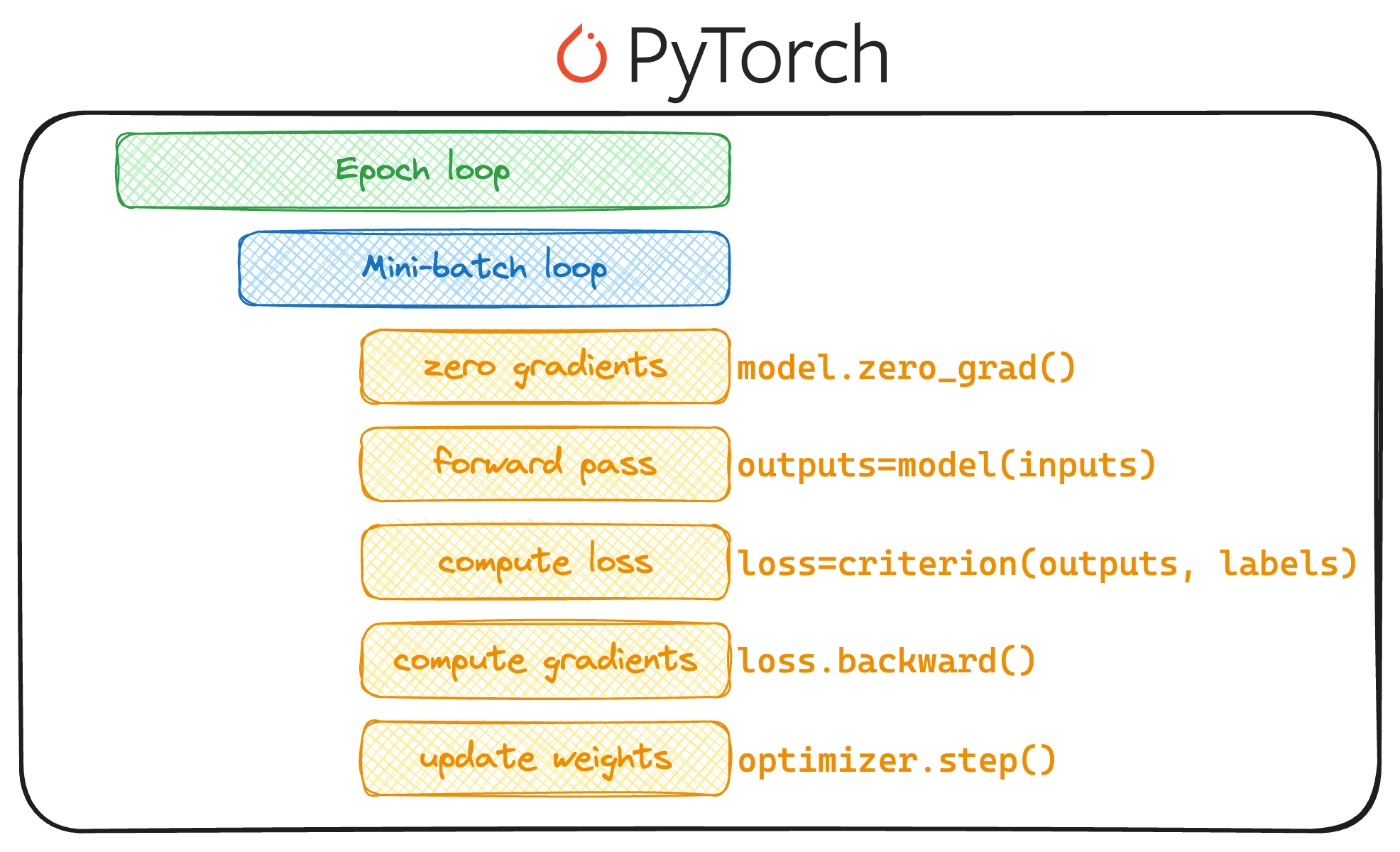
#1) Managing training loops
With complex models, manually managing the training loop in PyTorch can become tedious.
This includes iterating over the dataset, performing forward and backward passes, and updating the model parameters, which, of course, is quite standardized as shown below, but it does need some review and maintainability.
#2) Logging
Logging is crucial for monitoring the training process and analyzing model performance.
PyTorch does not provide built-in support for logging, requiring users to implement their own logging solutions or integrate external logging frameworks.
#3) Handling distributed training
As models grow larger, training them on multiple GPUs or across multiple machines becomes necessary to reduce training time.
PyTorch provides support for distributed training, but the implementation can be complex, involving setting up processes, synchronizing gradients, and handling communication between processes.
#4) Debugging in a distributed setting
Debugging distributed training can be challenging due to the complexity of the setup and the potential for issues to arise from communication between processes.
#5) Mixed-precision training
Mixed-precision training, which involves using lower precision (e.g., half-precision floating-point numbers) for certain parts of the training process, can help reduce memory usage and speed up training.
PyTorch supports mixed-precision training, but managing the precision of different operations manually is pretty challenging.
We also saw this in a recent newsletter issues, where we into full detail about mixed-precision training, and how it works in PyTorch:
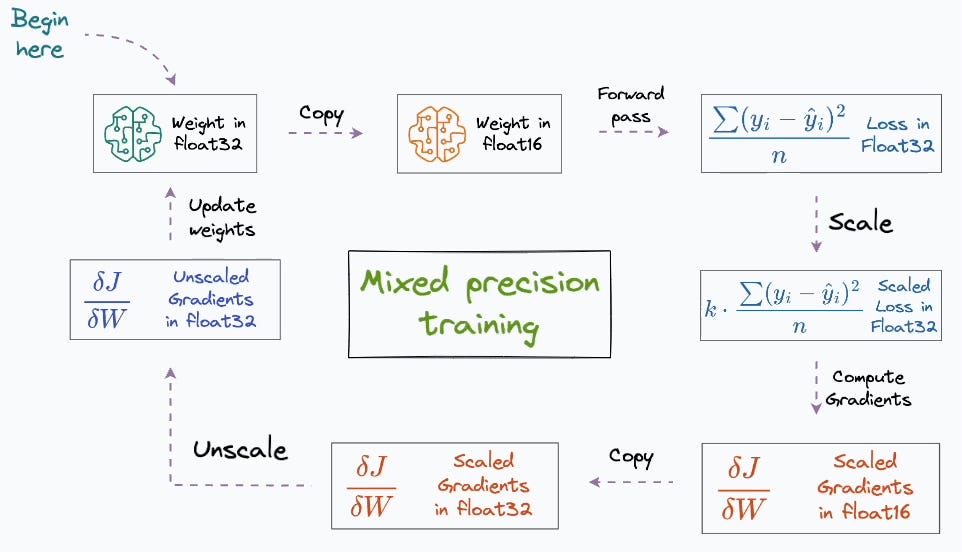
#6) Running models on TPUs
PyTorch natively supports running models on GPUs, but running models on TPUs (Tensor Processing Units) requires additional setup and configuration.
From the above discussion, it’s clear that PyTorch doesn’t provide out-of-the-box solutions for many important tasks, leading to boilerplate code and increased chances of errors.
Of course, these challenges may not be major concern for all types of models, especially small or simple ones.
For small-scale projects, the overhead of managing training loops, logging, and distributed training may not outweigh the benefits of using PyTorch directly. However, as models grow in complexity and size, these challenges become more pronounced.
PyTorch Lightning
PyTorch Lightning resolves each of the above-discussed challenges with PyTorch.
You can think of PyTorch Lightning as a lightweight wrapper around PyTorch that abstracts away the boilerplate code, which we typically write with PyTorch, and makes the training process more streamlined and readable.
Just like Keras is a wrapper on TensorFlow, PyTorch lightning is a wrapper on PyTorch, but one that makes it much more efficient than the traditional way of training the model.
Thus, one can use ANY PyTorch model as a PyTorch Lightning model.
As the library is an optimized wrapper around PyTorch, the developers claim to reduce the repeated (boilerplate) code by 70-80%, which minimizes the surface area for bugs and lets us focus on delivering value instead of engineering.
Moreover, as we shall see ahead, with PyTorch Lightning, we can define our model and training logic in a clear and concise manner, which lets us focus more on the research and less on the implementation details.
In fact, the utility is pretty evident from its popularity because its GitHub repo has over 26k stars:
Revisiting the challenges with PyTorch, we discussed above, here’s how PyTorch Lightning addresses them.
- Managing training loops: PyTorch Lightning simplifies this process by providing a high-level abstraction for defining the training loop, reducing the amount of boilerplate code required.
- Logging: PyTorch Lightning integrates with popular logging frameworks like TensorBoard and Comet, making it easier to log training metrics and visualize them in real-time.
- Handling distributed training: PyTorch Lightning simplifies distributed training by providing a unified interface. This abstracts away the complexity of the underlying implementation.
- Debugging in a distributed setting: PyTorch Lightning provides tools and utilities to facilitate debugging in a distributed setting, making it easier to identify and resolve issues.
- Mixed-precision training: PyTorch Lightning simplifies mixed-precision training by providing utilities to automatically handle the precision of operations based on user-defined settings.
- Running models on TPUs: PyTorch Lightning supports running models on TPUs, abstracting away the complexity of the underlying TPU architecture and allowing users to focus on their model implementation.
Along with that, one of the best things about PyTorch Lightning is that it has a minimal API. In most cases, the LightningModule and Trainer class are the only 2 APIs one must learn because the rest is just organized PyTorch.
If none of these things is clear yet, don’t worry. Let’s get into a complete walkthrough of using PyTorch Lightning.
Now that we understand what PyTorch Lightning is and the motivation to use it over PyTorch, let’s get into more details about its implementation and how PyTorch Lightning works.
More specifically:
- We shall begin with a standard PyTorch code, and learn how to convert that into PyTorch Lightning code.
- Next, we shall look at how we use the Trainer() class from PyTorch Lightning to simplify model training and define various methods for training, validation, testing and predicting. Here, we shall also learn how to log model training and integrate various performance metrics during training.
- Finally, we shall deep dive into the additional utilities offered by PyTorch Lightning like mixed precision training, callbacks, profiling code for optimization.
Let’s begin!
PyTorch to PyTorch Lightning
In this section, let’s build a simple neural network on the MNIST dataset using PyTorch. Then, we will see how we can convert that code to a PyTorch Lightning code.
PyTorch Model
Here are the traditional steps to building a model in PyTorch:
Step 1) Import required packages and libraries
First, we import the required packages from PyTorch:
Step 2) Load the dataset
Next, we load the MNIST dataset (train and test) and create their respective PyTorch dataloaders.
Step 3) Define the PyTorch Model
Moving on, we define a simple feedforward neural network architecture. This is demonstrated below:
Step 4) Initialize the model and define the loss function and optimizer
Moving on, we shall initialize the model and define the loss function to train it — the CrossEntropyLoss.
Step 5) Define the evaluation method
To evaluate the model after every epoch, let’s define an evaluate() method that will iterate over the examples in the testloader and compute the accuracy. This is demonstrated below:
Step 6) Train the model
Now, we will train the PyTorch model.
With this, we are done with the PyTorch model.
Now, if we go back to the above code, there’s too much boilerplate code here.
Simply put, boilerplate means the repetitive and standardized sections of code that are necessary for the functioning of the program, but they are not unique to the model we are training. Instead, this is something that we would almost always write in most other projects too.
For instance, the accuracy() method and the training loop contribute to the boilerplate code here.

While these boilerplate sections are essential for training a neural network, they can be cumbersome to write and maintain, and they are pretty repetitive as well.
PyTorch Lightning Model
Now that we have defined a network in PyTorch, let’s see how we can convert this to a Pytorch Lightning with just two to three simple changes.
But first, we must install PyTorch Lightning, which we can do as follows:
Next, we import PyTorch Lightning as follows: