Bi-encoders and Cross-encoders for Sentence Pair Similarity Scoring (Part 1)
A deep dive into why BERT isn't effective for sentence similarity and advancements that shaped this task forever.
Introduction
It fascinates me that SO MANY real-world NLP systems, either implicitly or explicitly, rely on pairwise sentence scoring in one form or another.
- A retrieval-augmented generation (RAG) system heavily relies on pairwise sentence scoring (at varying levels of granularity based on how you chunk the data) to retrieve relevant context, which is then fed to the LLM for generation:
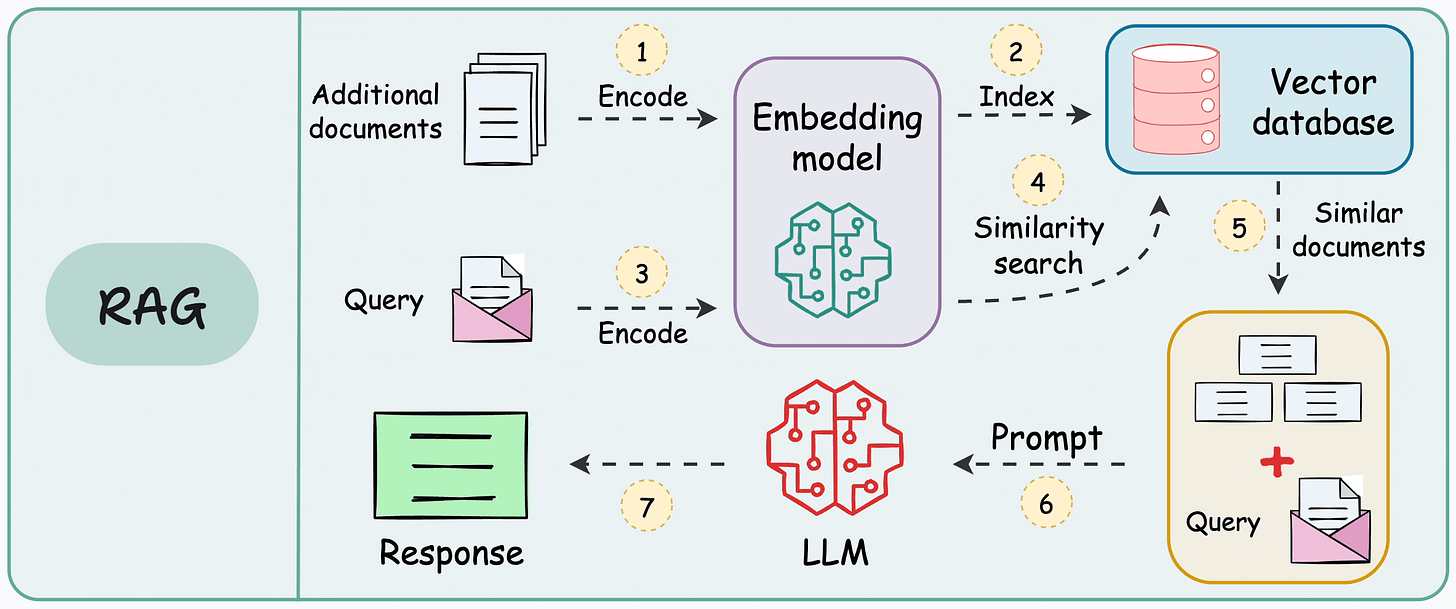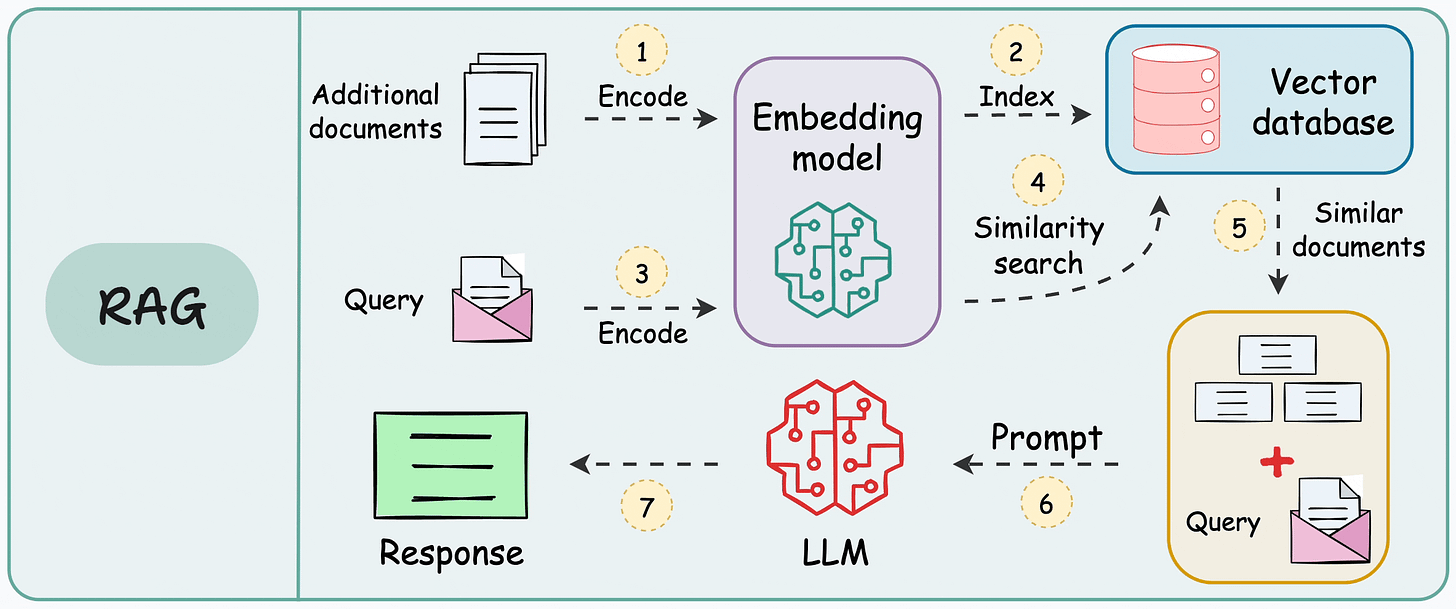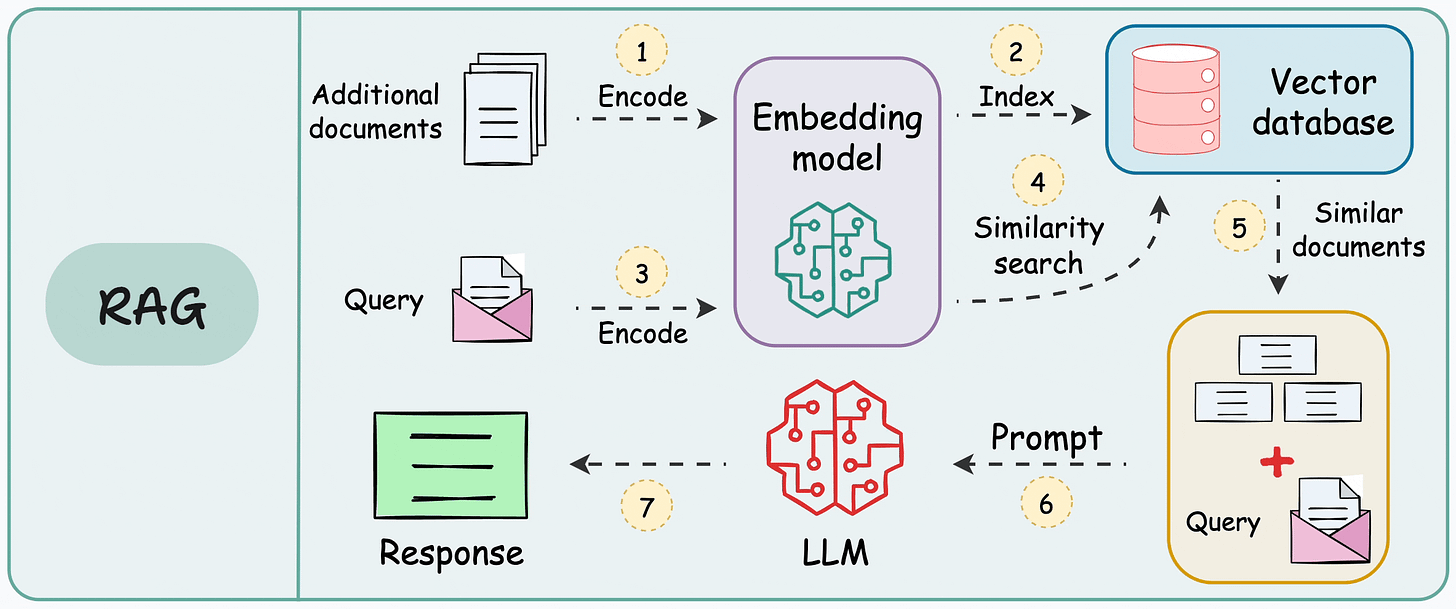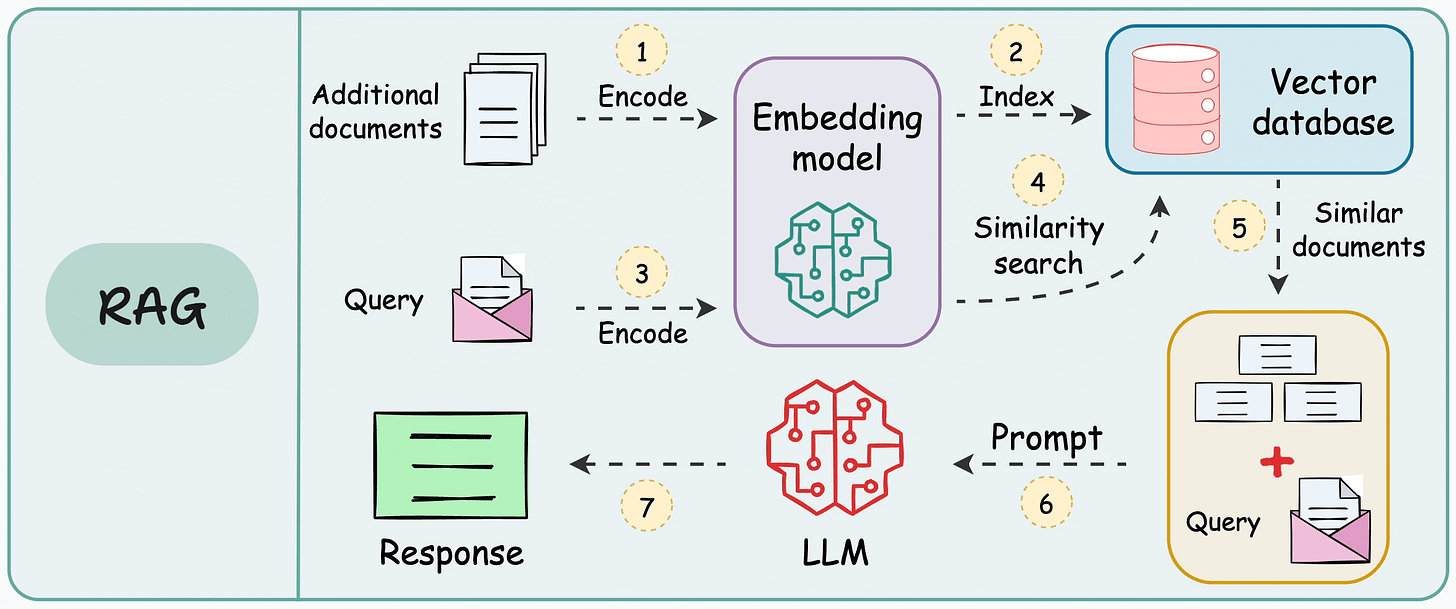
- That is why RAG is 75% retrieval and 25% generation.
- In other words, everything boils down to how well you can retrieve relevant context.
- Several question answering systems implicitly evaluate the relationship between questions and potential answers, determining the most relevant pairings.
- Several information retrieval (IR) systems depend on scoring query-document pairs to rank the most suitable documents for a given query.
- Duplicate detection engines assess whether two sentences or questions convey the same meaning, which is especially observed in community-driven platforms (Stackoverflow, Medium, Quora, etc.). In fact, there's also a dataset on this by Quora, where the objective is to determine whether two user-posted questions are duplicates. The objective is to accurately identify semantically equivalent questions, helping them to reduce redundancy and improve user experience by grouping similar queries.
This list of tasks that depend on pairwise sentence scoring can go on and on. But the point I am trying to make here is that pairwise sentence (paragraphs, documents, etc.) scoring is a fundamental building block in several NLP applications.
In this article, I want to walk you through some prevalent approaches proposed after BERT but still remain highly relevant in the field.
These are bi-encoders and cross-encoders.
As we shall learn shortly in part 1 of this series (this article), while both these approaches possess unique strengths to pairwise sentence scoring, they all face limitations, particularly when balancing accuracy and efficiency.
Once you have understood these approaches, in part 2, we shall continue our discussion with Augmented SBERT (AugSBERT)—a method that combines the best of both worlds by using Cross-encoders to augment the training data for Bi-encoders, along with the implementation.
Of course, if you don't know any of these models, don't worry since that is what we intend to cover today with proper context, like we always do.
Let's dive in!
Background
Feel free to skip to "the problem with BERT section" if you already know about word embeddings, their purpose, background of word embeddings, and BERT.
A machine cannot use bland unstructured data to predict if two sentences convey the same meaning.
Consider an all-text unstructured data, say thousands of news articles, and we wish to search for an answer from that data.
Traditional search methods rely on exact keyword search, which is entirely a brute-force approach and does not consider the inherent complexity of text data.
In other words, languages are incredibly nuanced, and each language provides various ways to express the same idea or ask the same question.
For instance, a simple inquiry like "What's the weather like today?" can be phrased in numerous ways, such as "How's the weather today?", "Is it sunny outside?", or "What are the current weather conditions?".
This linguistic diversity makes traditional keyword-based search methods inadequate.
As you may have already guessed, representing this data as vectors can be pretty helpful in this situation too.
Instead of relying solely on keywords and following a brute-force search, we can first represent text data in a high-dimensional vector space and store them in a vector database.
When users pose queries, the vector database can compare the vector representation of the query with that of the text data, even if they don't share the exact same wording.
How to generate embeddings?
At this point, if you are wondering how do we even transform words (strings) into vectors (a list of numbers), let me explain.
We also covered this in the following newsletter issue but not in much detail, so let’s discuss those details here.
To build models for language-oriented tasks, it is crucial to generate numerical representations (or vectors) for words.
This allows words to be processed and manipulated mathematically and perform various computational operations on words.
The objective of embeddings is to capture semantic and syntactic relationships between words. This helps machines understand and reason about language more effectively.
In the pre-Transformers era, this was primarily done using pre-trained static embeddings.
Essentially, someone would train embeddings on, say, 100k, or 200k common words using deep learning techniques and open-source them.
Consequently, other researchers would utilize those embeddings in their projects.
The most popular models at that time (around 2013-2017) were:
- Glove
- Word2Vec
- FastText, etc.
These embeddings genuinely showed some promising results in learning the relationships between words.
For instance, at that time, an experiment showed that the vector operation (King - Man) + Woman returned a vector near the word Queen.
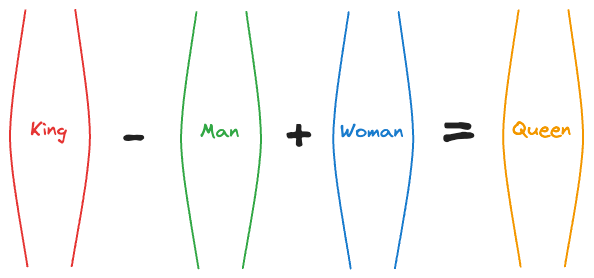
That’s pretty interesting, isn’t it?
In fact, the following relationships were also found to be true:
Paris - France + Italy ≈ RomeSummer - Hot + Cold ≈ WinterActor - Man + Woman ≈ Actress- and more.
So, while these embeddings captured relative word representations, there was a major limitation.
Consider the following two sentences:
- Convert this data into a table in Excel.
- Put this bottle on the table.
Here, the word “table” conveys two entirely different meanings:
- The first sentence refers to a “data” specific sense of the word “table.”
- The second sentence refers to a “furniture” specific sense of the word “table.”
Yet, static embedding models assigned them the same representation.
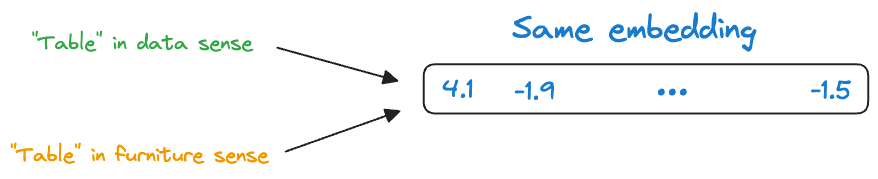
Thus, these embeddings didn’t consider that a word may have different usages in different contexts.
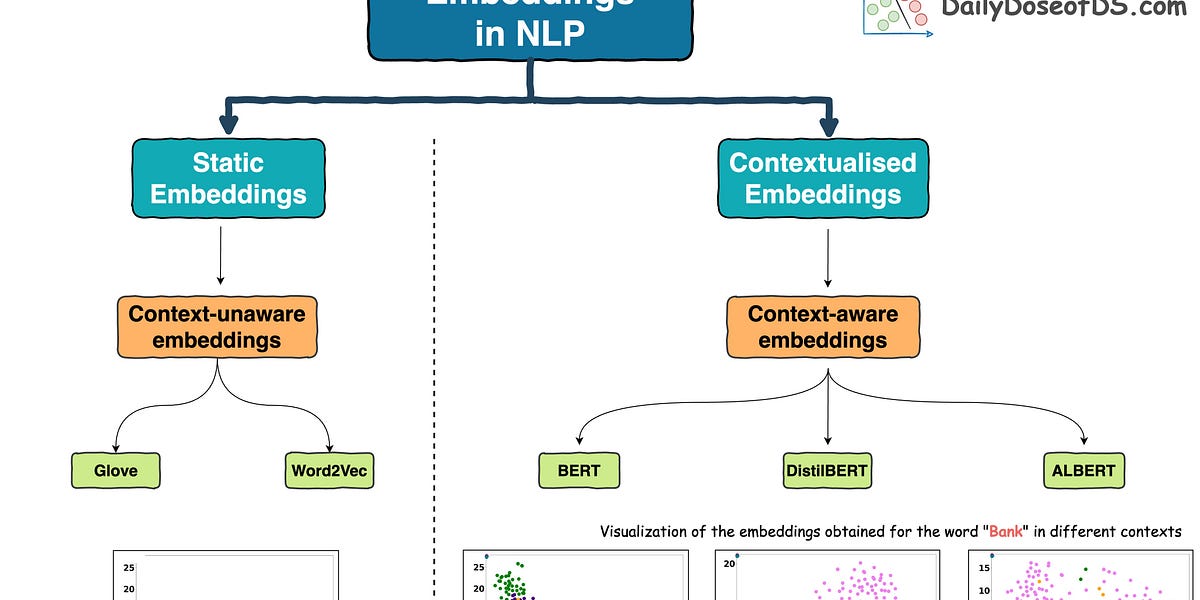
But this was addressed in the Transformer era, which resulted in contextualized embedding models powered by Transformers, such as:
- BERT: A language model trained using two techniques:
- Masked Language Modeling (MLM): Predict a missing word in the sentence, given the surrounding words.
- Next Sentence Prediction (NSP).
- We shall discuss it in a bit more detail shortly.
- DistilBERT: A simple, effective, and lighter version of BERT, which is around 40% smaller:
- Utilizes a common machine learning strategy called student-teacher theory.
- Here, the student is the distilled version of BERT, and the teacher is the original BERT model.
- The student model is supposed to replicate the teacher model’s behavior.
- If you want to learn how this is implemented practically, we discussed it here:
The idea is that these models are quite capable of generating context-aware representations, thanks to their self-attention mechanism and appropriate training mechanism.
BERT
For instance, if we consider BERT again, we discussed above that it uses the masked language modeling (MLM) technique and next sentence prediction (NSP).
These steps are also called the pre-training step of BERT because they involve training the model on a large corpus of text data before fine-tuning it on specific downstream tasks.
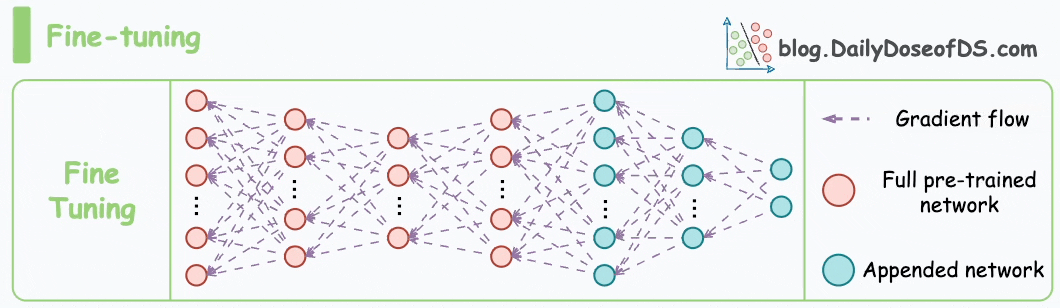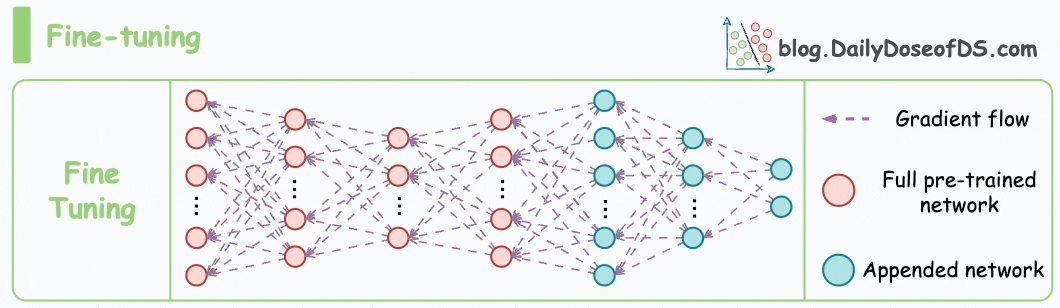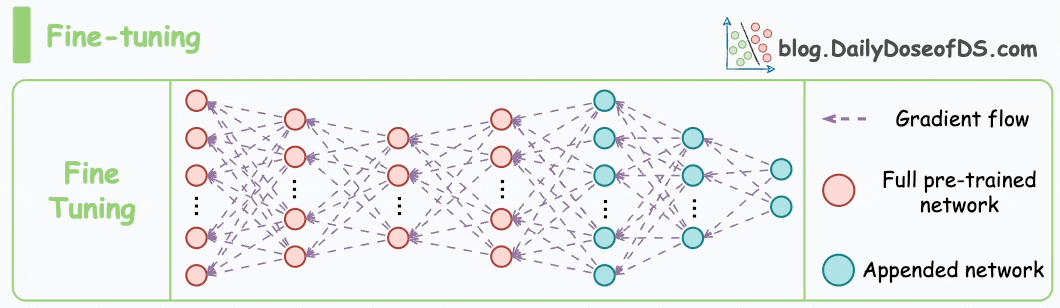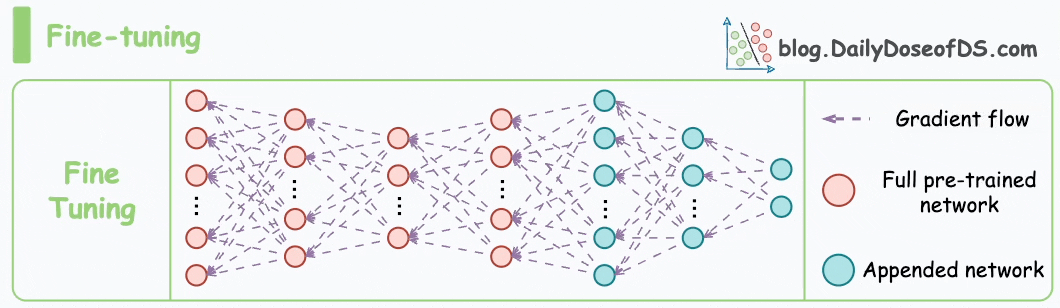
Moving on, let’s see how the pre-training objectives of masked language modeling (MLM) and next sentence prediction (NSP) help BERT generate embeddings.
#1) Masked Language Modeling (MLM)
- In MLM, BERT is trained to predict missing words in a sentence. To do this, a certain percentage of words in most (not all) sentences are randomly replaced with a special token,
[MASK].
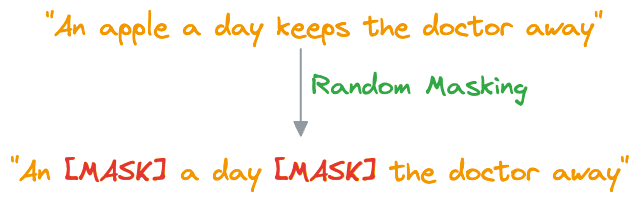
- BERT then processes the masked sentence bidirectionally, meaning it considers both the left and right context of each masked word, that is why the name “Bidirectional Encoder Representation from Transformers (BERT).”

- For each masked word, BERT predicts what the original word is supposed to be from its context. It does this by assigning a probability distribution over the entire vocabulary and selecting the word with the highest probability as the predicted word.
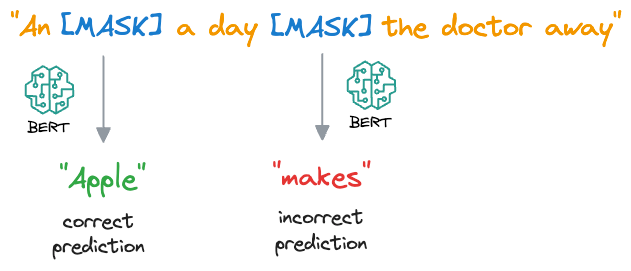
- During training, BERT is optimized to minimize the difference between the predicted words and the actual masked words, using techniques like cross-entropy loss.
#2) Next Sentence Prediction (NSP)
- In NSP, BERT is trained to determine whether two input sentences appear consecutively in a document or whether they are randomly paired sentences from different documents.
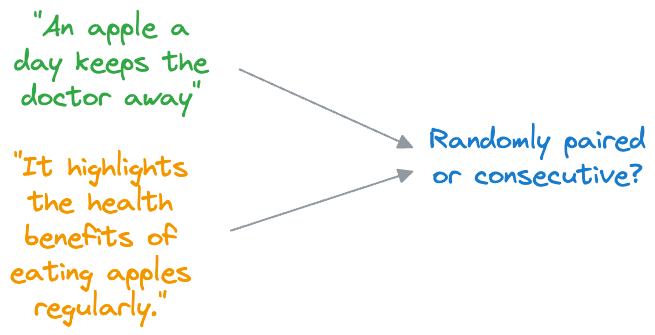
- During training, BERT receives pairs of sentences as input. Half of these pairs are consecutive sentences from the same document (positive examples), and the other half are randomly paired sentences from different documents (negative examples).
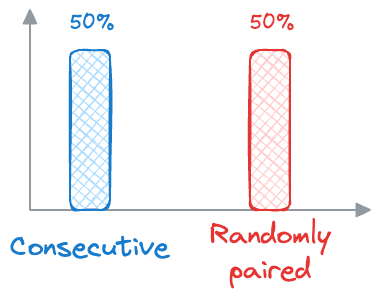
- BERT then learns to predict whether the second sentence follows the first sentence in the original document (
label 1) or whether it is a randomly paired sentence (label 0). - Similar to MLM, BERT is optimized to minimize the difference between the predicted labels and the actual labels, using techniques like binary cross-entropy loss.
Now, let's see how these pre-training objectives help BERT generate embeddings:
- MLM: By predicting masked words based on their context, BERT learns to capture the meaning and context of each word in a sentence. The embeddings generated by BERT reflect not just the individual meanings of words but also their relationships with surrounding words in the sentence.
- NSP: By determining whether sentences are consecutive or not, BERT learns to understand the relationship between different sentences in a document. This helps BERT generate embeddings that capture not just the meaning of individual sentences but also the broader context of a document or text passage.
With consistent training, the model learns how different words relate to each other in sentences. It learns which words often come together and how they fit into the overall meaning of a sentence.
This learning process helps BERT create embeddings for words and sentences, which are contextualized, unlike earlier embeddings like Glove and Word2Vec:
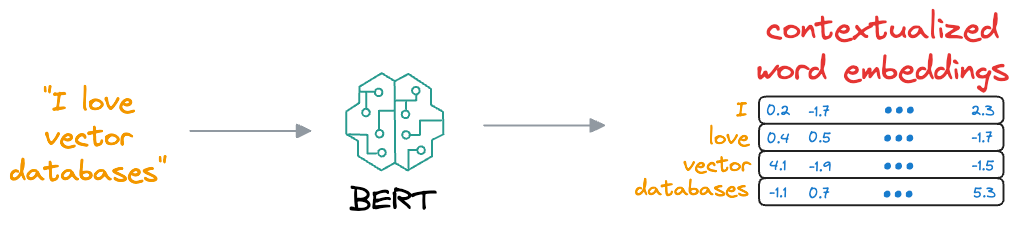
Contextualized means that the embedding model can dynamically generate embeddings for a word based on the context they were used in.
As a result, if a word would appear in a different context, the model would return a different representation.
This is precisely depicted in the image below for different uses of the word Bank.
For visualization purposes, the embeddings have been projected into 2d space using t-SNE.
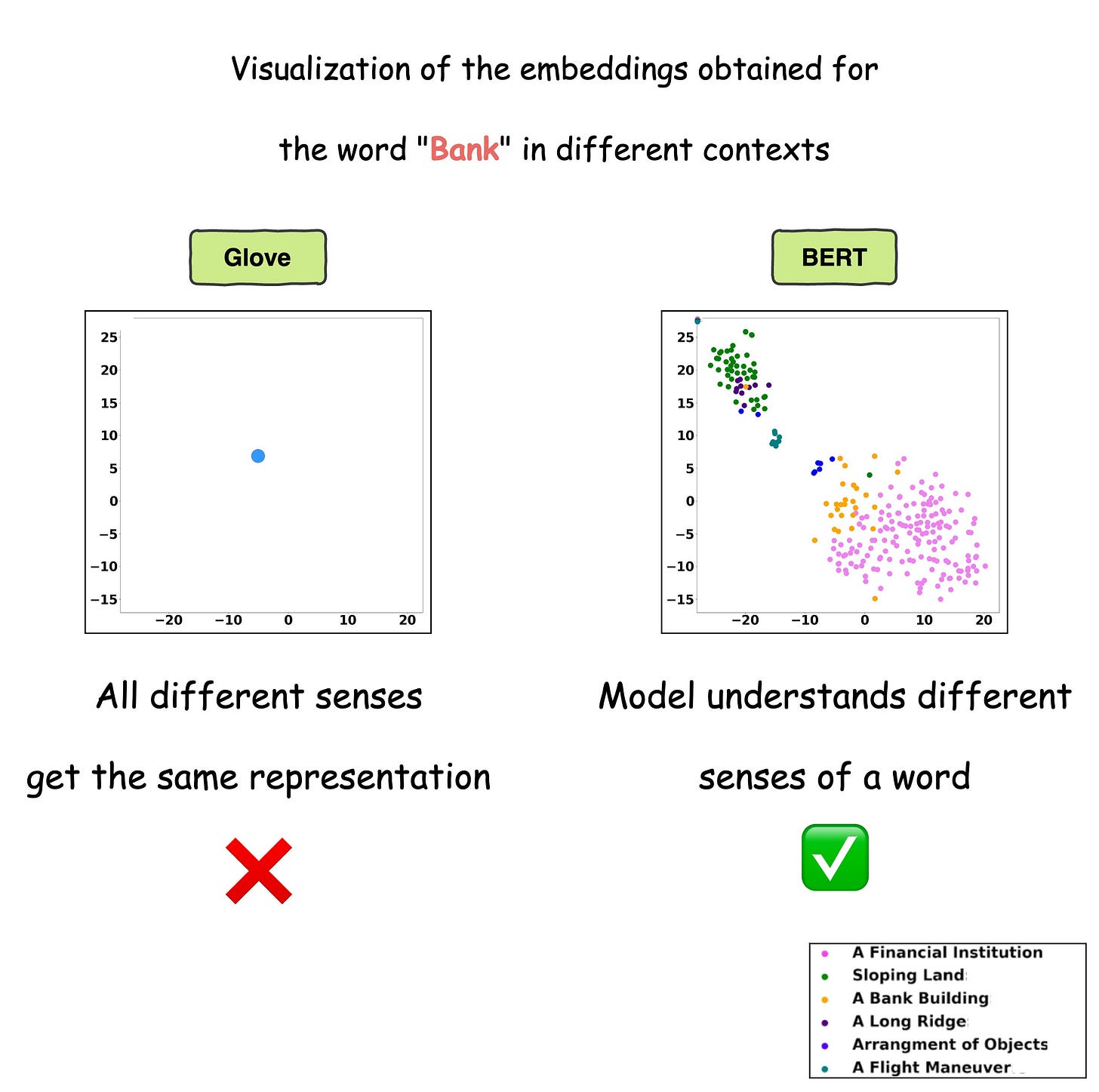
As depicted above, the static embedding models — Glove and Word2Vec produce the same embedding for different usages of a word.
However, contextualized embedding models don’t.
In fact, contextualized embeddings understand the different meanings/senses of the word “Bank”:
- A financial institution
- Sloping land
- A Long Ridge, and more.
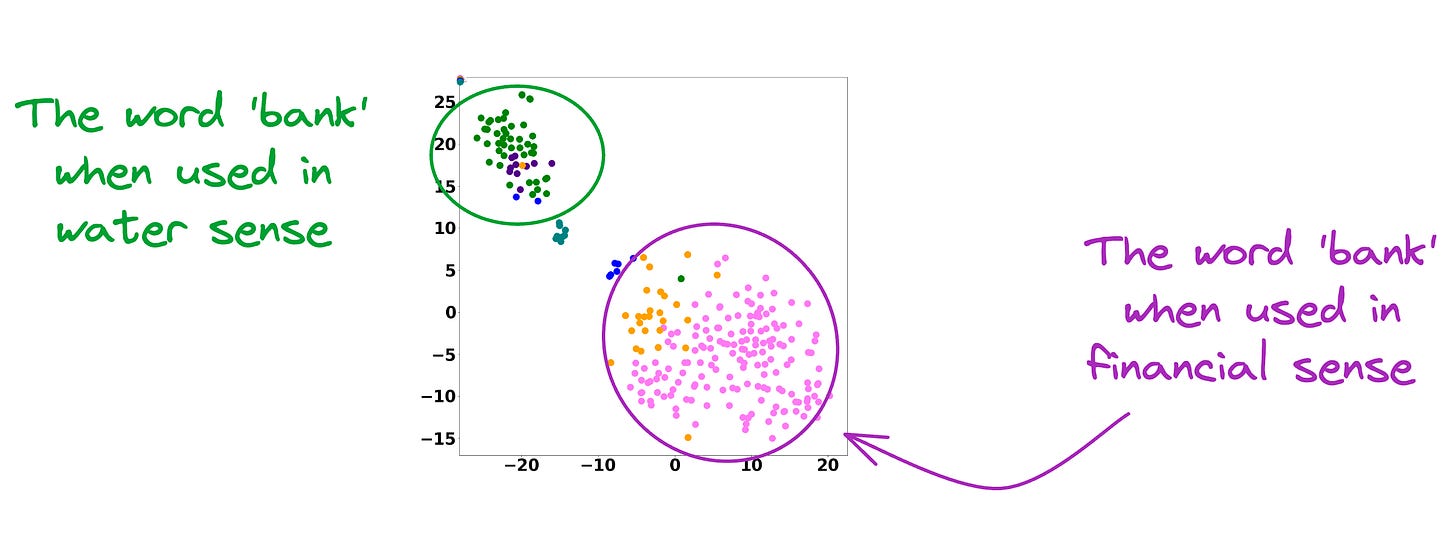
As a result, these contextualized embedding models address the major limitations of static embedding models.
The point of the above discussion is that modern embedding models are quite proficient at the encoding task.
As a result, they can easily transform documents, paragraphs, or sentences into a numerical vector that captures its semantic meaning and context.
The problem with BERT
Here, one of the most obvious options to achieve sentence pair scoring is just to use the pre-trained BERT model, create embeddings for sentences, and then use a similarity search between those embeddings and the query vector.
We could treat cosine similarity as a scoring mechanism.
But we run into a problem.