Model Interpretability (Part 1)
A deep dive into PDPs and ICE plots, along with their intuition, considerations, how to avoid being misled, and code.
Introduction
More than ever do we need methods that can reliably communicate (or explain) a model's behavior.
This is because blindly trusting an ML model’s predictions can be fatal at times, especially in high-stakes environments where decisions based on these predictions can affect human lives, financial stability, or critical infrastructure.
For instance, if a model predicts that a patient is healthy and does not need any treatment, this information may not be very helpful to a doctor.
In reality, a doctor performs a differential diagnosis, where understanding nuances like a 10% chance that the patient might have cancer-based on an MRI is crucial.
In such cases, it’s not just about making predictions but also understanding the underlying reasons for those predictions.
While methods like conformal predictions are generally well-suited for providing non-technical users with confidence intervals or prediction sets (which we have already discussed below)...

...data scientists and machine learning developing these models often need to dive deeper for more technical insights into the model.
In other words, data scientists and machine learning practitioners require tools that offer a granular understanding of how features influence predictions, and a prediction set or prediction confidence may not be that useful to them.
In several cases, Partial Dependence Plots (PDPs) and Individual Conditional Expectation (ICE) are my go-to for such analysis since they help data scientists go beyond simple confidence intervals and dive into the relationship between specific features and a model's predictions, and how a model makes its predictions.
If you have seen the following visual before where we covered the 11 most important plots in data science, you may have noticed that we covered PDPs here:
In this article, let's dive into the technical details of how PDPs and ICE plots are created, and how to interpret them (while ensuring that they don't mislead you).
Let's dive in!
#1) Partial dependency plots (PDPs)
Introduction
In my experience, this name—Partial Dependence Plots—creates so much havoc in a learner's mind, but it actually becomes quite simple once you break it down.
- Partial indicates that we are not concentrating on the entire feature space but rather only a subset of features.
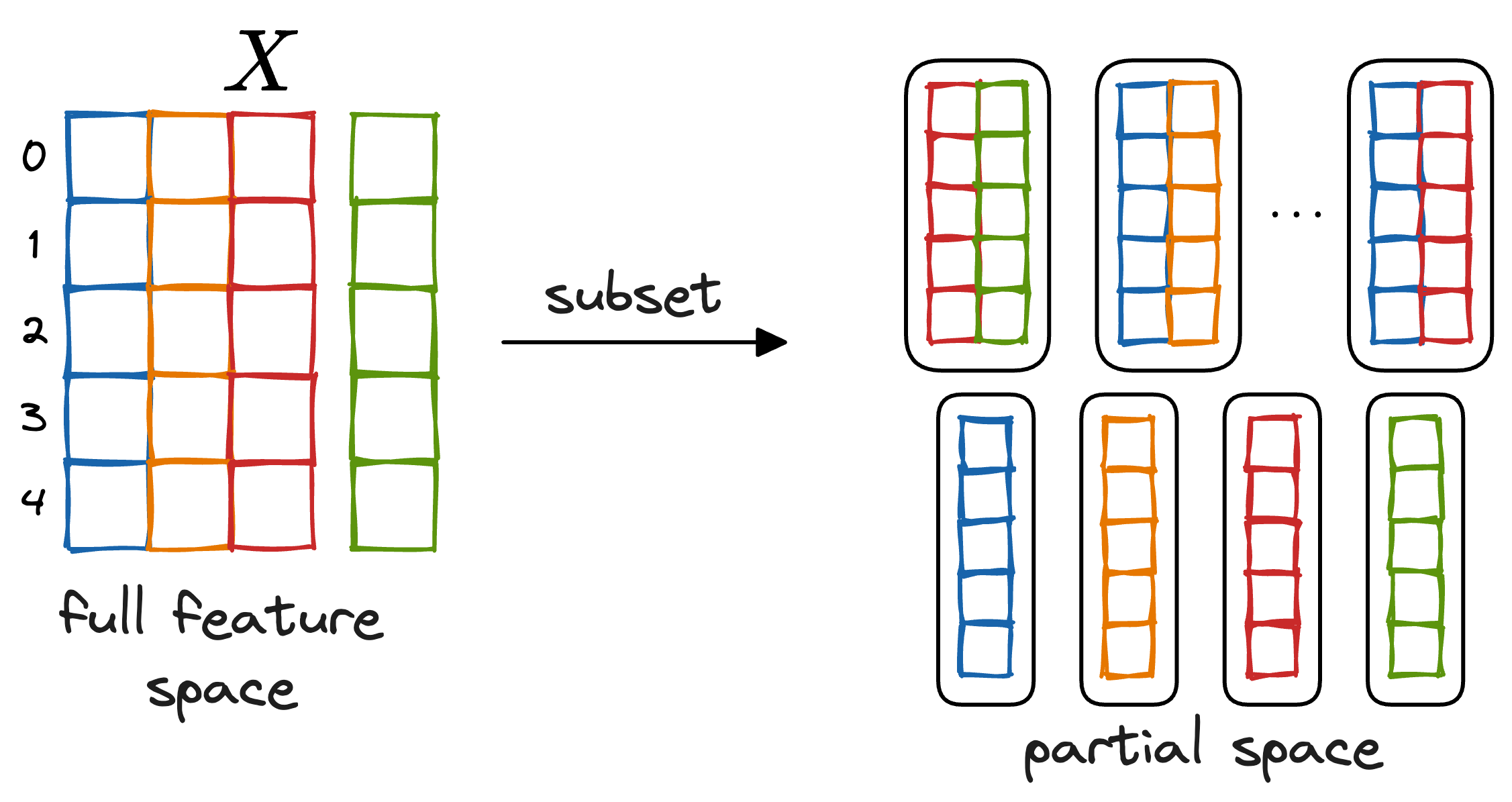
- Thus, we must isolate one or two features of interest while holding all other features constant, hence the term "partial."
- This allows us to study the impact of specific features on the model’s predictions without interference from others.
- Dependency means the relationship between the above subsetted features and the model’s predictions.
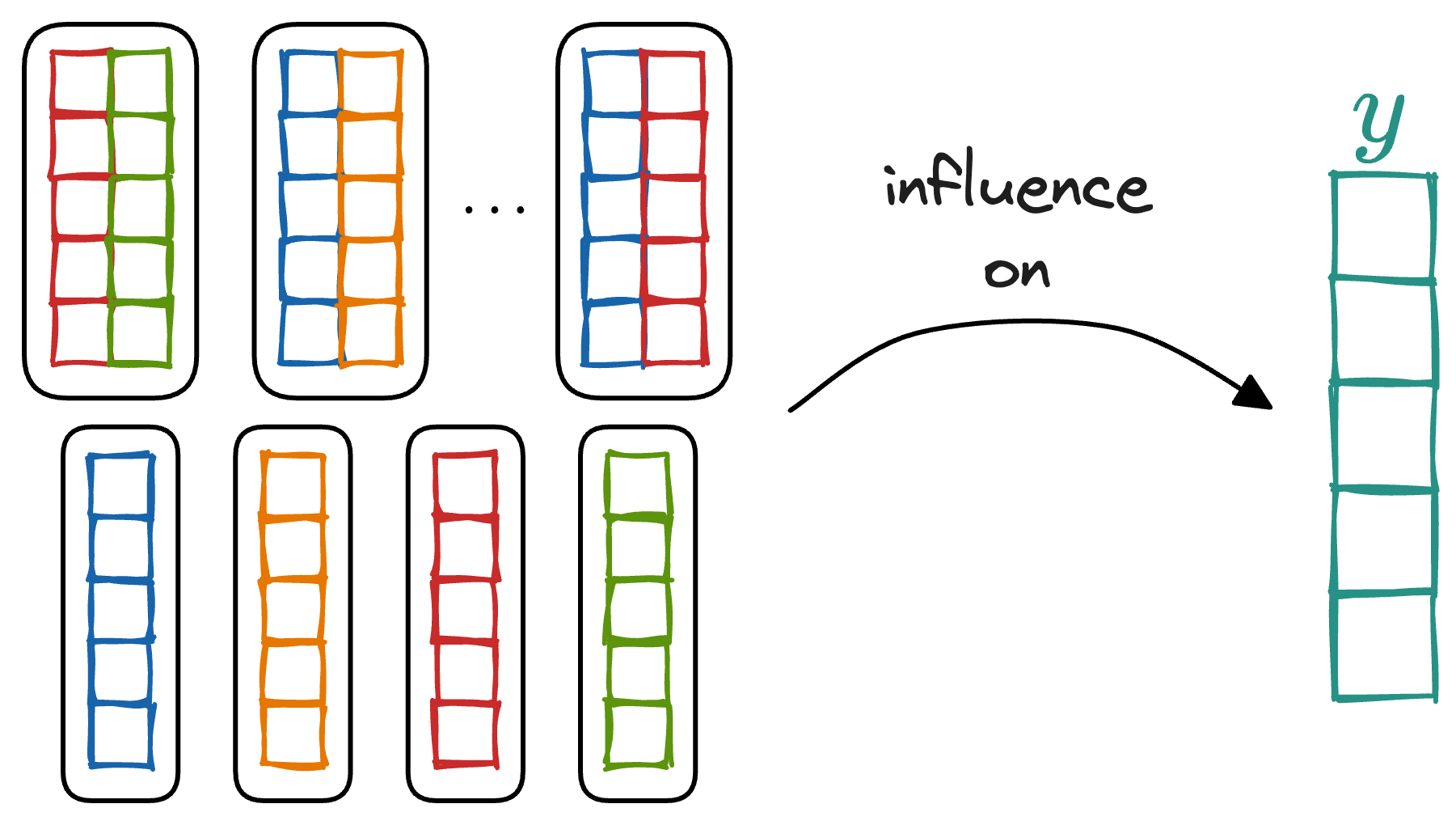
- We're looking to understand how changes in the values of these features influence the predicted outcome.
- In other words, we are plotting how dependent the predictions are on these particular features.
Now, putting these two together, Partial Dependency refers to the relationship between a specific feature (or pair of features) and the predicted outcome while assuming all other features remain fixed.
This simplification is key to understanding the marginal effect of one or two features at a time, making the behavior of the model easier to interpret.
Let me make that more concrete by explaining the steps to create a PDP plot.
Creating a PDP
Let’s walk through the process of creating a PDP with code explanations using Python’s sklearn and numpy libraries, along with a Random Forest model.
For the sake of this tutorial, we'll create a dummy dataset, train the model, and then compute the Partial Dependence Plot (PDP) without plotting it.
1) Dummy dataset
First, we’ll create a dummy dataset with sklearn and train a Random Forest model.
For now, we are not concerned with overfitting since training the best model isn't the purpose of this tutorial.
2) Choose the Feature(s) of Interest
In this case, I’ve chosen a dataset with five features and trained a Random Forest regressor. We’ll focus on feature at index 0 for generating the PDP.