Agentic Systems 101: Fundamentals, Building Blocks, and How to Build Them (Part A)
AI Agents Crash Course—Part 1 (with implementation).
Introduction
Our RAG crash course was an incredible deep dive into practical applications, covering everything from retrieval pipelines to multimodal integration and efficient retrieval strategies.
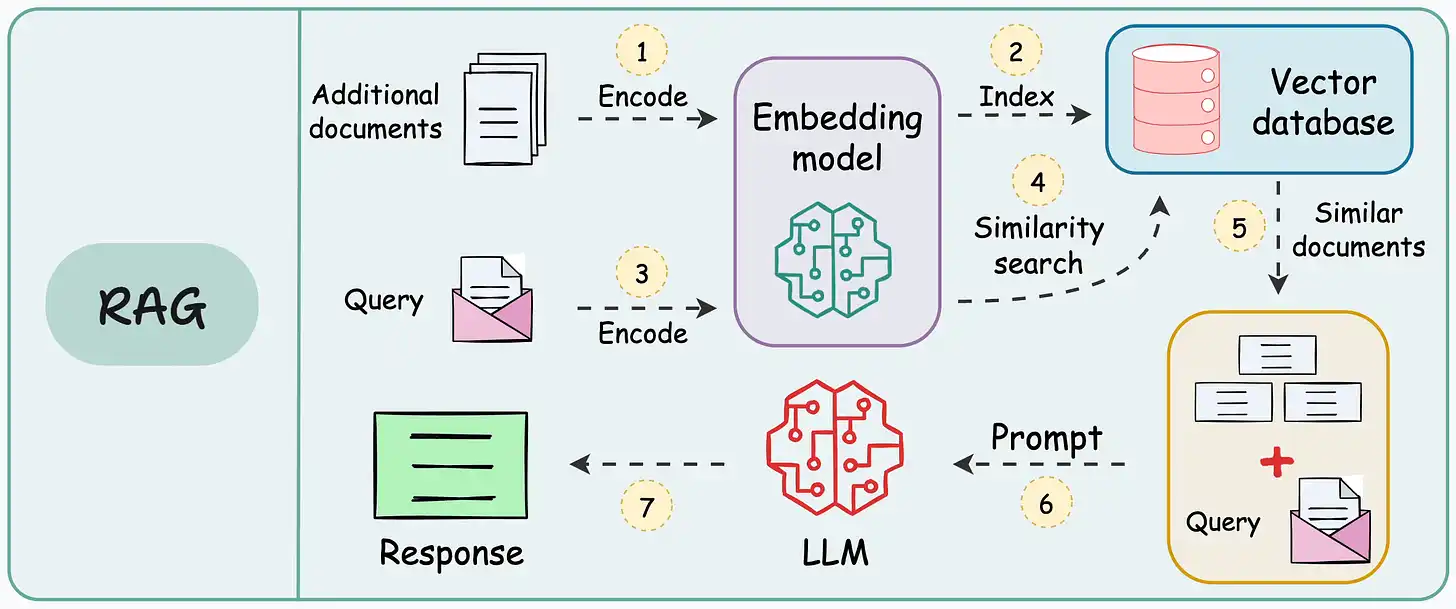
We explored how to optimize large-scale retrieval systems, how to evaluate them, and even how to extend them beyond text into images and structured data.
Now, it’s time to take things a step further in this new crash course on AI Agents!
If RAG systems are about retrieving and enhancing information, AI agents take it to the next level—they reason, plan, and autonomously take action based on the information they process.
Instead of simply fetching relevant content, agents can coordinate workflows, interact with external tools, and dynamically adapt to changing scenarios.
Let's dive into more details to understand the motivations for AI Agents.
Motivation
There are three perspectives to understanding the motivation behind AI Agents:
1) RAG perspective
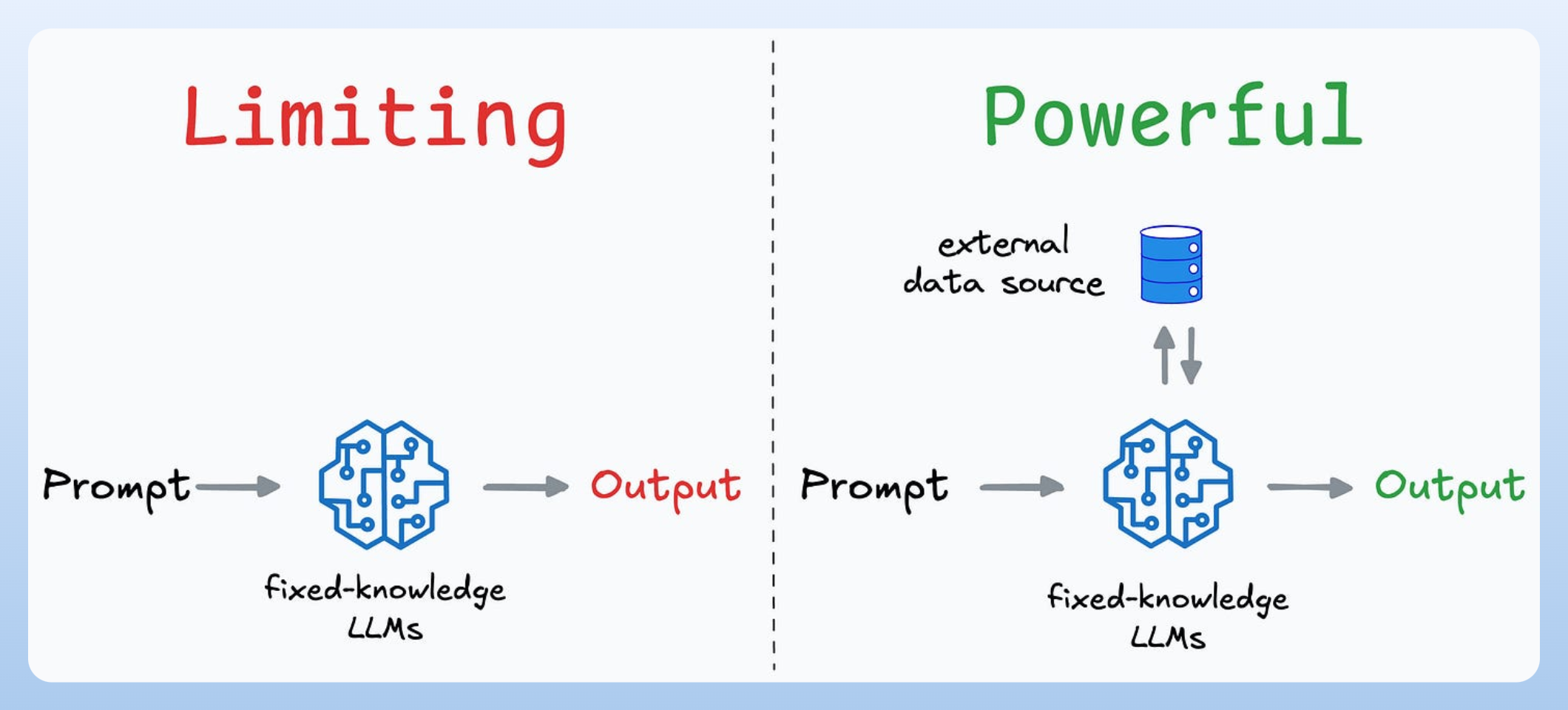
Given the scale and capabilities of modern LLMs, it feels limiting to use them as “standalone generative models” for pretty ordinary tasks like text summarization, text completion, code completion, etc.
Instead, their true potential is only realized when you build systems around these models, where they are allowed to:
- access, retrieve, and filter data from relevant sources,
- analyze and process this data to make real-time decisions and more.
RAG was a pretty successful step towards building such compound AI systems:
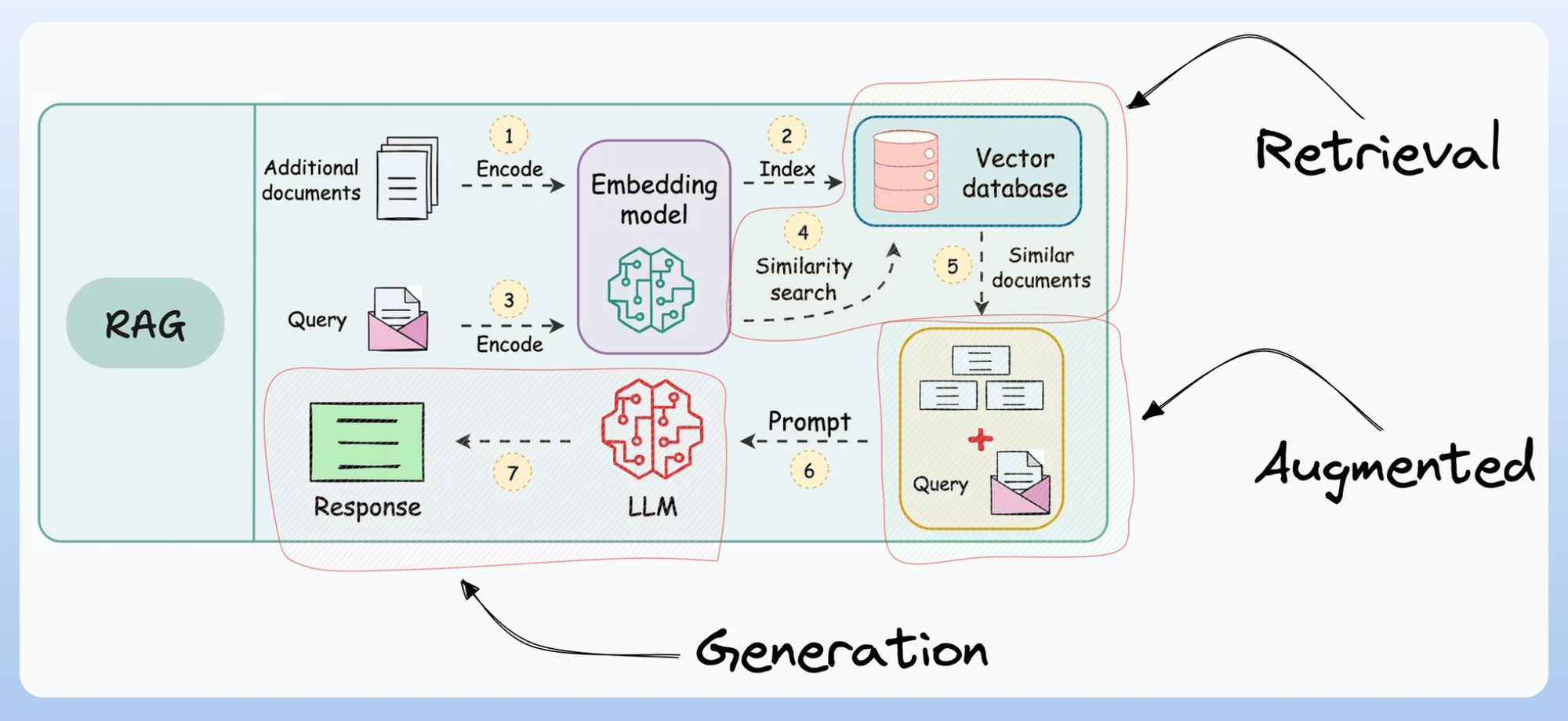
But since most RAG systems follow a programmatic flow (you, as a programmer, define the steps, the database to search for, the context to retrieve, etc.), it does not unlock the full autonomy one may expect these compound AI systems to possess.
That is why the primary focus in 2024 was (and going ahead in 2025 will be) on building and shipping AI Agents—autonomous systems that can reason, think, plan, figure out the relevant sources and extract information from them when needed, take actions, and even correct themselves if something goes wrong.
2) Software development perspective
Think about how traditional software applications work. They follow rigid, pre-defined rules:
- If you want a program to complete a task, you explicitly define every step.

- As new scenarios arise, developers must add more conditions and logic.
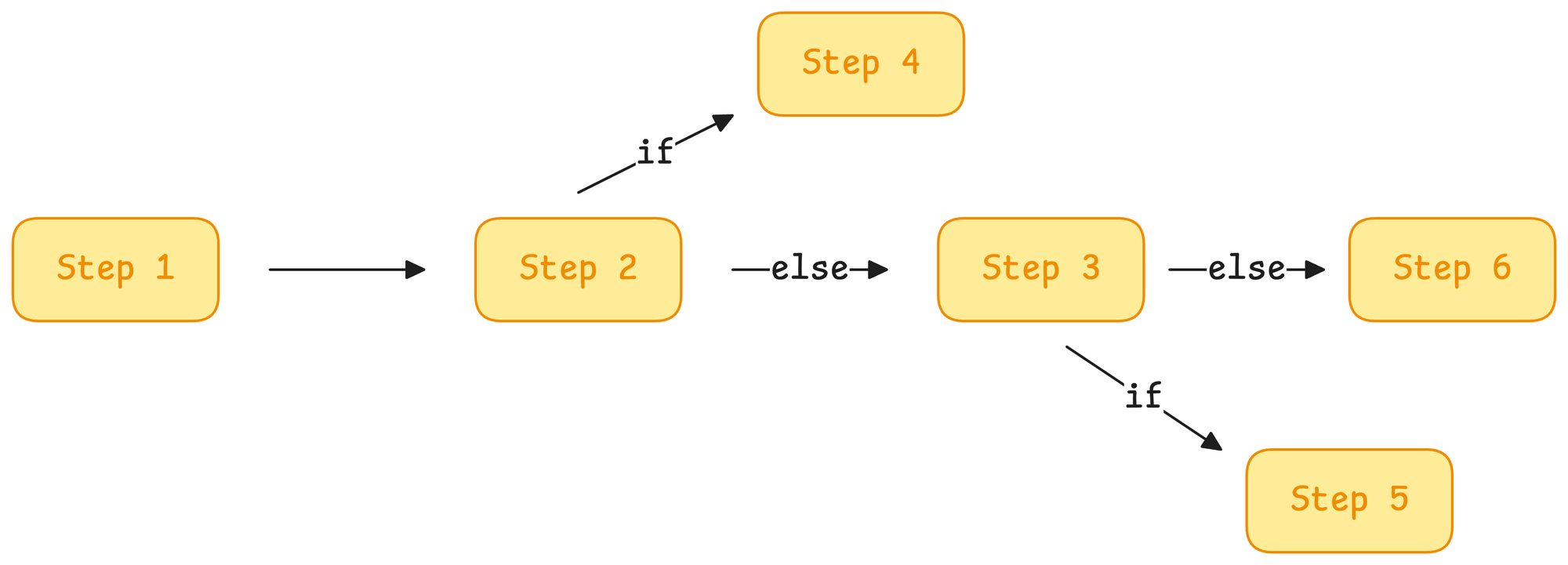
- Over time, the system becomes harder to scale and maintain.
In other words, traditional automation requires strict pre-defined logic:
- If condition A is met, do X.
- If condition B is met, do Y.
- Else, do Z.
That's not all, even these are mostly fixed in traditional automation:

- Inputs have a defined data type (text, numeric, etc.)
- Transformations on that input are mostly fixed.
- Output types are also fixed.
But all of that changes with AI Agents.
Firstly, AI agents don’t need explicit instructions for every case. Instead, they:
- Gather information dynamically.
- Use reasoning to handle ambiguous problems.
- Collaborate with other agents to complete tasks.
- Leverage external tools to make decisions in real time.
Moreover:
- Inputs do not have to be of any defined data type. It could be string, integer, PDFs, tables, markdown, JSON, etc.

- Transformations could be anything based on what you ask the LLM to do.
- Outputs can be anything—tokens, lists, structured output, JSON, code, etc.
Let's take an example to thoroughly understand the utility of AI Agents.
Imagine you run a news aggregation platform that pulls articles from different sources. Traditionally, you would:
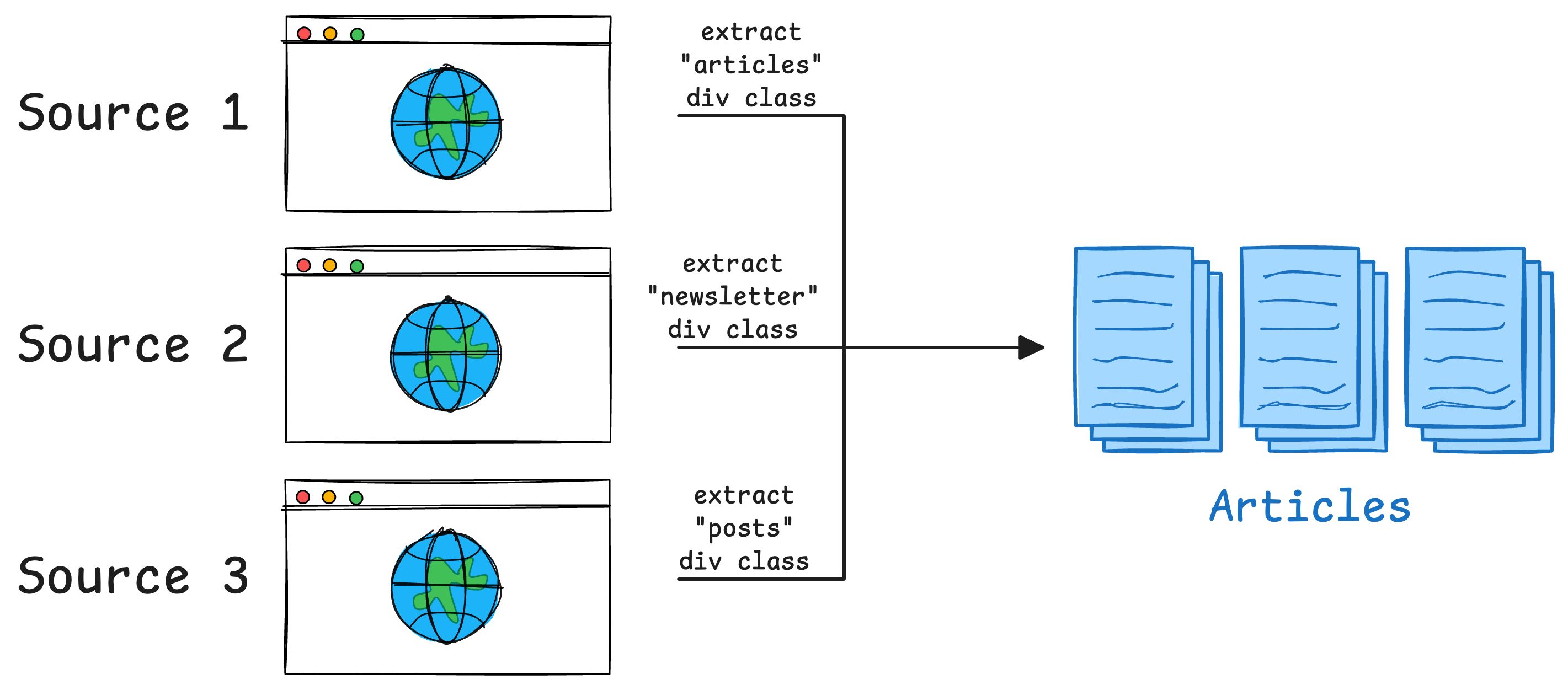
- Write scripts to scrape multiple websites.
- Filter and categorize the articles based on hardcoded rules.
- Manually verify whether an article is relevant.
This works—but it’s rigid.
Also, if a website changes its layout, your scraper breaks.
If new topics emerge, you have to update the filtering logic manually.
Now, let’s see how AI agents would handle this differently: