Graph Neural Networks Part 1 (Implementation Included)
A practical and beginner-friendly guide to building neural networks on graph data.
Background
Traditional deep learning typically relies on data formats that are tabular, image-based, or sequential (like language) in nature. These formats are well-suited for conventional neural network architectures like RNNs, CNNs, Transformers, etc.
These types of data are well-understood, and the models designed to handle them have become highly optimized.
However, with time, we have also realized the inherent challenges of such traditional approaches, one of which is their inability to naturally model complex relationships and dependencies between entities that are not easily captured by fixed grids or sequences.

More specifically, a significant proportion of our real-world data often exists in the form of graphs, where entities (nodes) are connected by relationships (edges), and these connections carry significant meaning, which, if we knew how to model, can lead to much more robust models.
For instance:
- Instead of representing e-commerce data in a tabular form (this user purchased this product at this time for this amount...), it can be better represented as interactions between users and products in the form of graphs. As a result, we can use this representation to learn from and possibly make more relevant personalized recommendations.
- In social networks, by using a graph to describe the relationship between users and how they are connected and engage with each other (comment, react, messaging, etc.), we can possibly train a model to detect fake accounts and bots. This can become an anomaly detection problem or a simple binary node classification problem — fake, not-fake classification.
Graph learning
The field of Graph Neural Networks (GNNs) intends to fill this gap, offering a way to extend deep learning techniques to graph-structured data. As a result, they have been emerging as a technique to learn smartly from data.
To understand how they have evolved over the years, have a look at the image below, which depicts the number of research papers published every year with the keyword "Graph neural networks" in their title:
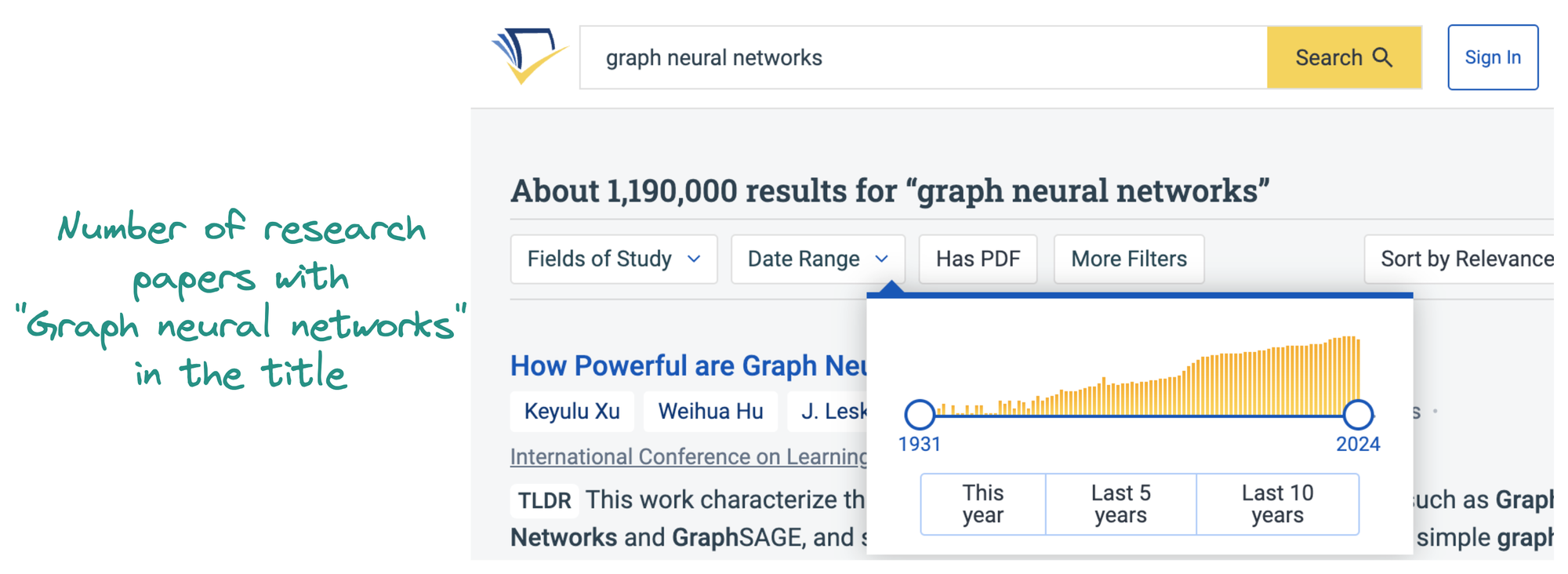
We can observe a similar pattern if we look at the global interest in the search term "graph neural networks" on Google Trends:
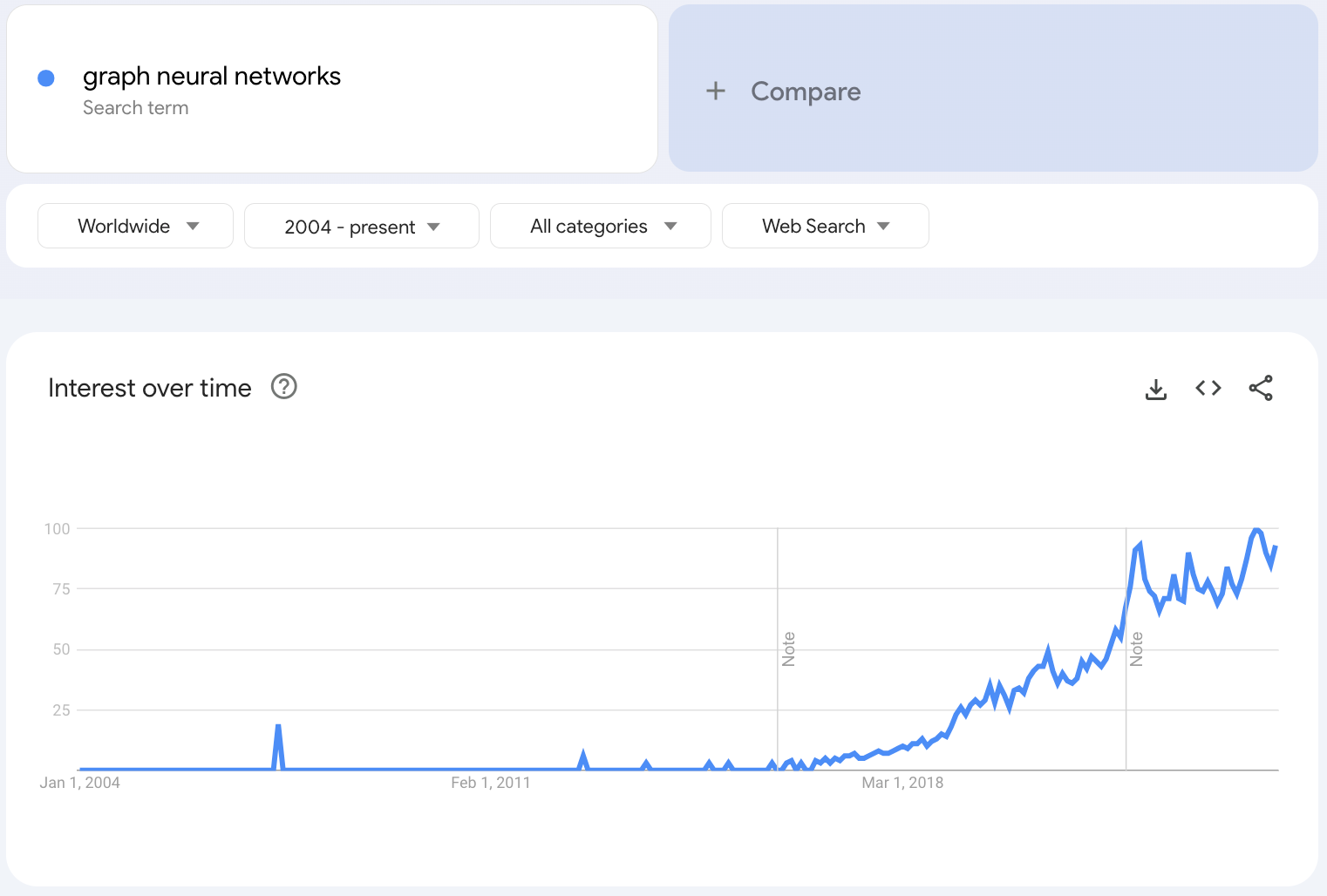
Of course, this is much more than just hype since several research papers have proven that they can lead to more accurate and robust models, and such models being actively used in real-world systems.
This is due to their ability to learn sophisticated representations (embeddings) using the graph structure and combining it with the predictive power of deep learning models we use today.
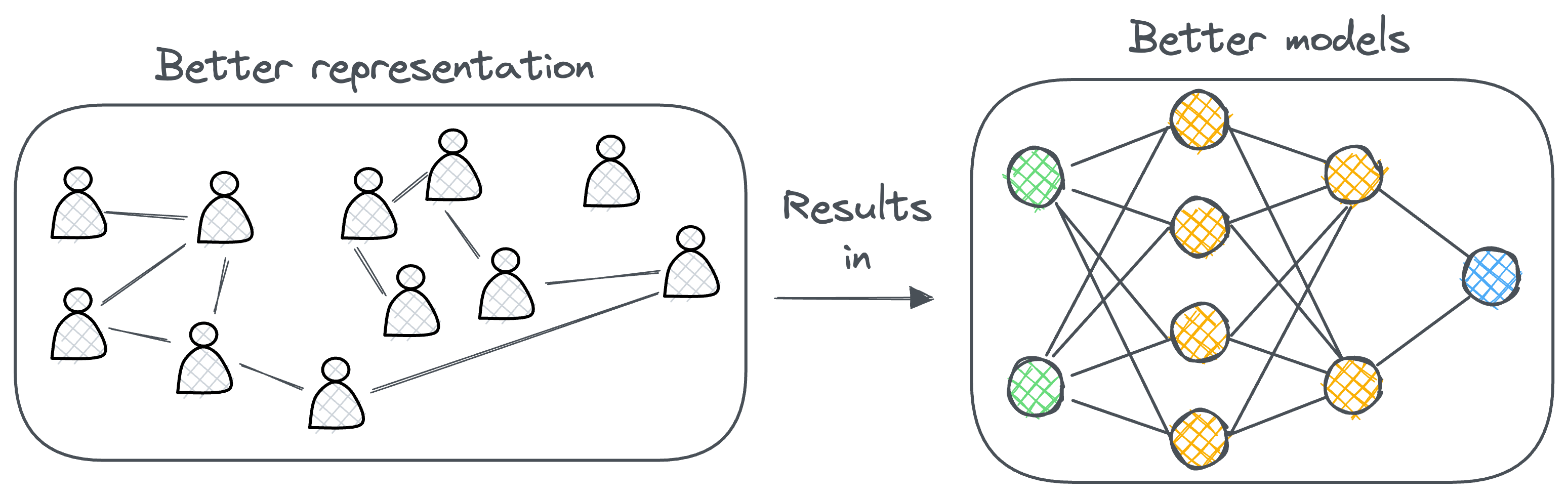
The benefits
From the discussion so far, it might be obvious to understand that one of the most significant advantages of using graph-based representations is their ability to capture both the attributes of individual nodes and the relationships between them.
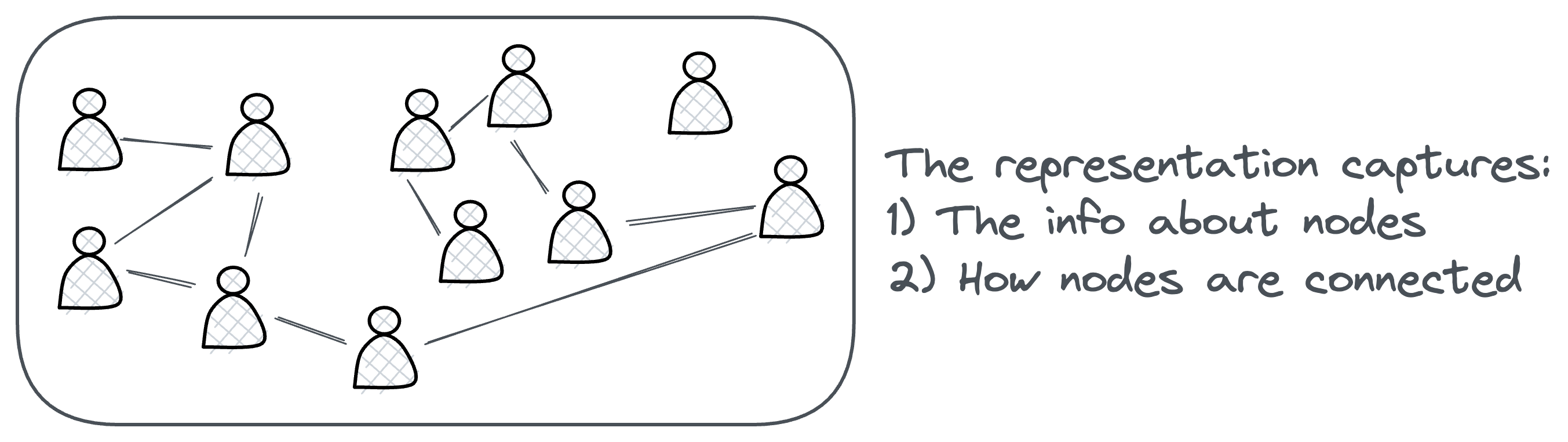
This dual capability allows for a richer and more comprehensive understanding of the data.
In most cases, the way I happen to decide if the problem at hand can benefit from graphs is by assessing if there is any interdependence or connection between data points.
- Products and users can have a connection.
- People can have a connection.
- Cardholders and merchants can have a connection.
- Related web pages can be connected through hyperlinks.
- and more.
For instance, consider Wikipedia.
Each article on Wikipedia can be viewed as a node in a graph, and hyperlinks between articles represent the edges connecting these nodes.
This structure forms a vast and intricate web of knowledge, where the connections between articles are just as important as their content.
If we wanted to build a model to recommend related articles to a reader, a traditional approach might only consider the text within each article.
However, by utilizing the graph of hyperlinks, we can identify clusters of related topics, track the flow of information across articles, and make more contextually relevant recommendations.
It makes sense, doesn't it?
Types of tasks
Before diving deeper, it's crucial to understand the three main categories of tasks that graph-based models are typically designed to address:
1) Node-level task
The objective here is to predict a specific label, type, category, or attribute associated with individual nodes within a graph, which could be classification and regression.
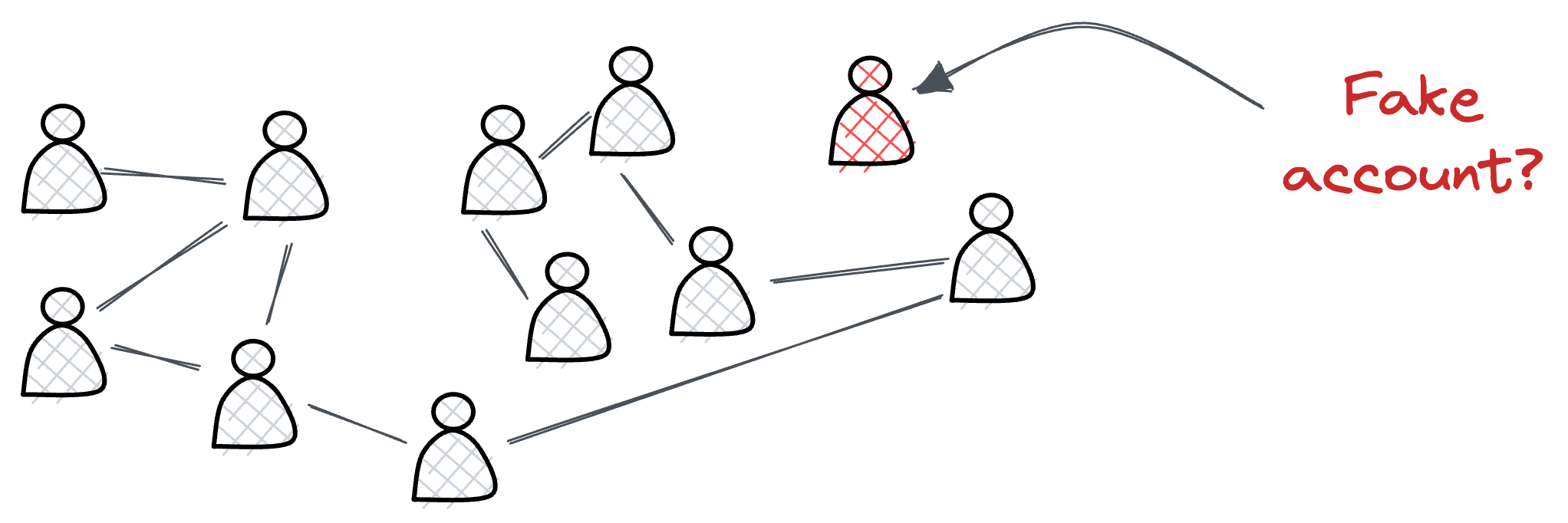
For instance, on a vast social network with millions of users, node-level tasks could involve detecting fake accounts by predicting whether each user node is legitimate or fraudulent based on their connections and activity patterns.
2) Edge-level task
For edge-level tasks, the focus is on predicting the existence or characteristics of edges (relationships) between nodes. This is particularly useful when you have a set of nodes and a partially known set of edges and must infer the missing connections.
Recommending someone to follow (or add as a friend) on social media can actually be considered an edge-level task.
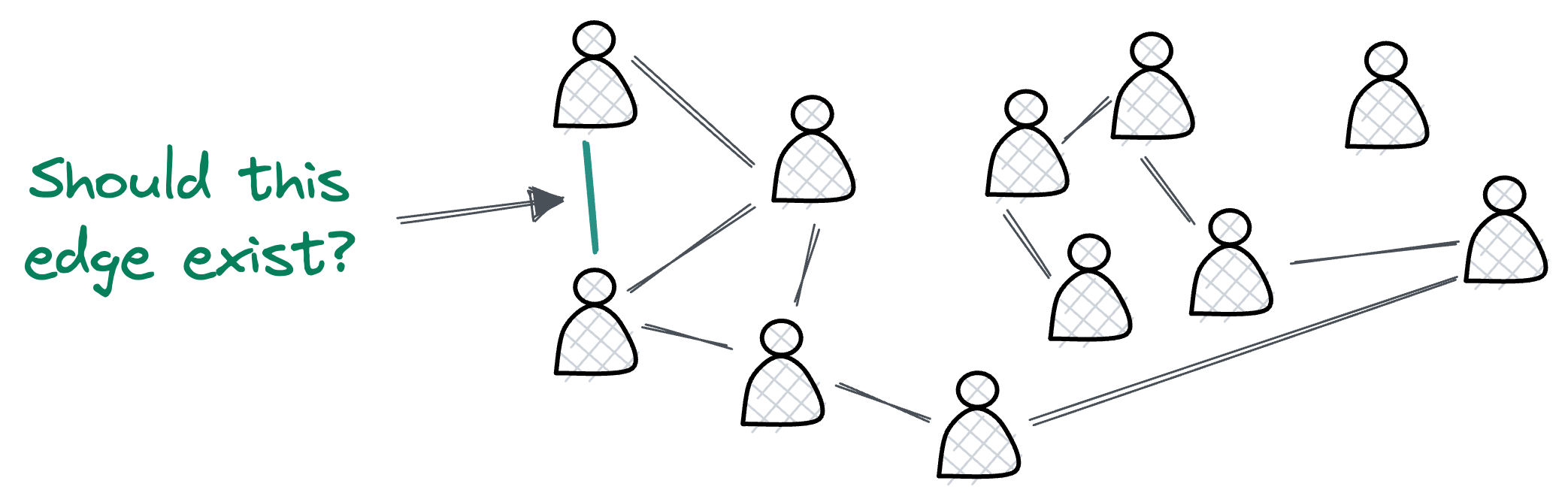
It's like predicting whether an edge should exist between two people or not (Person A should follow Person B or not).
3) Graph-level tasks
As the name suggests, graph-level tasks involve performing classification, regression, or clustering on entire graphs rather than individual nodes or edges. This is useful when the graph itself, as a whole, represents a meaningful entity or structure.
In NLP, documents can be represented as graphs where nodes correspond to words or phrases, and edges represent co-occurrences or syntactic relationships. Graph-level tasks can then be used to classify entire documents based on their graph structure.
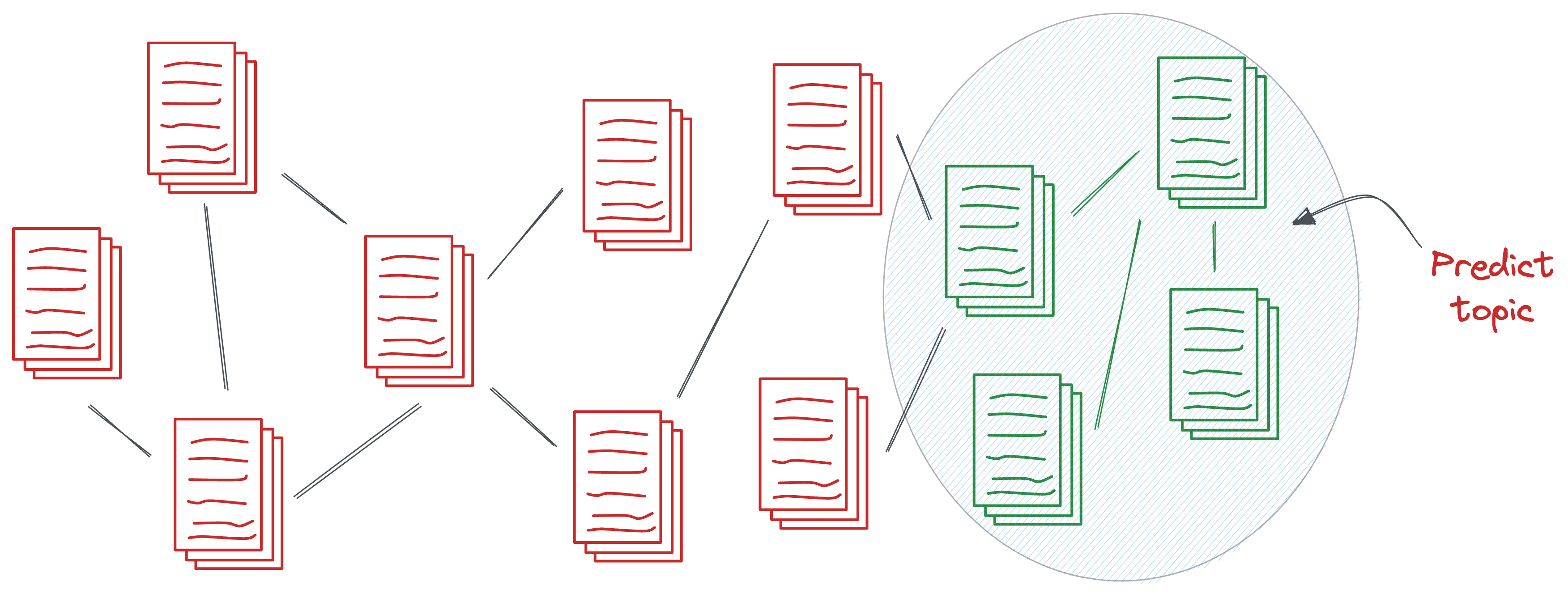
For example, given a set of research papers represented as graphs, a graph neural network could classify them into different categories (e.g., medical, engineering, computer science) based on the relationships between the concepts discussed in the papers.
Going ahead, we shall:
- Focus on node classification.
- Learn how GNNs work and are trained. While there are several types of GNNs, Graph Convolutional Networks (GCNs) stand out as the most widely applied architecture for graph learning. We shall learn how they work and why they are the most prevalent neural network architecture for graph learning.
- Do a practical demo of GCNs on a dataset and visualize the node classification results.
But first, let's understand how to use PyTorch Geometric.
PyTorch Geometric
Introduction
PyTorch Geometric, as the name suggests, is a PyTorch extension specifically developed for developing and implementing graph-based neural networks.

 pyg-team
pyg-teamIt has an intuitive and user-friendly API that facilitates inspecting and analyzing graphs and building machine learning models on graph-based datasets.
To use it, we must first install the library as follows:
Now that we have installed PyTorch Geometric, we can start learning how to use it to analyze graph datasets and build machine learning models on it.
Datasets
We need a dataset to get started and for the sake of simplicity, I'll be using the smallest dataset – the Karate Club dataset, which is already available in PyTorch Geometric.
PyTorch Geometric has several datasets, here's a brief description of each dataset (click to expand):
1) KarateClub
- Description: Social network of a karate club.
- Number of Nodes: 34
2) Cora
- Description: Citation network dataset where nodes represent documents, and edges represent citations between them.
- Number of Nodes: 2,708
3) CiteSeer
- Description: Another citation network dataset similar to Cora.
- Number of Nodes: 3,327
4) PubMed
- Description: A large-scale citation network dataset.
- Number of Nodes: 19,717
5) Planetoid
- Description: A set of citation network datasets including Cora, CiteSeer, and PubMed.
- Number of Nodes: Varies by dataset (e.g., Cora: 2,708, CiteSeer: 3,327, PubMed: 19,717)
6) Reddit
- Description: A dataset derived from Reddit posts, used for community detection.
- Number of Nodes: 232,965
7) TUDataset
- Description: A large collection of graph datasets for various tasks, such as graph classification.
- Number of Nodes: Varies by dataset (e.g., MUTAG: 188 nodes across all graphs)
7) PPI (Protein-Protein Interaction)
- Description: A dataset of protein-protein interaction networks from multiple species.
- Number of Nodes: 56,944 across multiple graphs
8) QM9
- Description: A dataset of small molecules with various properties for each molecule.
- Number of Nodes: Typically 9 atoms per molecule; 130,831 molecules in total
9) ENZYMES
- Description: A dataset of protein tertiary structures where each protein is represented as a graph.
- Number of Nodes: 19,235 across all graphs (1000 graphs)
10) OGBN-Arxiv
- Description: A citation network of papers from the arXiv repository.
- Number of Nodes: 169,343
10) Flickr
- Description: An image-based social network dataset.
- Number of Nodes: 89,250
11) Amazon Products
- Description: A product co-purchasing network.
- Number of Nodes: 1,569,960
12) Facebook Page-Page Network
- Description: A dataset representing Facebook pages as nodes and mutual likes as edges.
- Number of Nodes: 22,470
To give you more idea about the Karate Club dataset, it captures the relationships formed between club members, where every node denotes a member of the club. Moreover, the edges between these nodes depict the interactions that happened between these members.
The members have been divided into four classes, and our objective is to use graph-based machine learning techniques to assign the correct group to each member, i.e., classify nodes – node classification using the interactions available in the dataset.
To get started, we import the KarateClub class as follows:
After importing, we define the dataset by instantiating an objecting of this class:
Inspecting the graph
PyTorch Geometric provides several utility functions to inspect the dataset and print some of its properties. For instance, we can use the data object defined above to determine the number of graphs in the dataset, the number of features, and the number of classes as follows:
This suggests that:
- Our data only has one sub-graph, meaning, there are no disconnected components.
- Every node has a 34-dimensional feature vector
- The nodes have been grouped into four classes in this graph data.
If the graph has multiple sub-graphs, the data object can be indexed to access the individual components. Since in our karate club dataset, there is only 1 component, we can access it as follows:
Printing the graph reveals more information about the graph structure: