Federated Learning: A Critical Step Towards Privacy-Preserving ML
Learn real-world ML model development with a primary focus on data privacy – A practical guide.
In many practical machine learning (ML) projects, it is a common practice to consolidate the data at a central location.
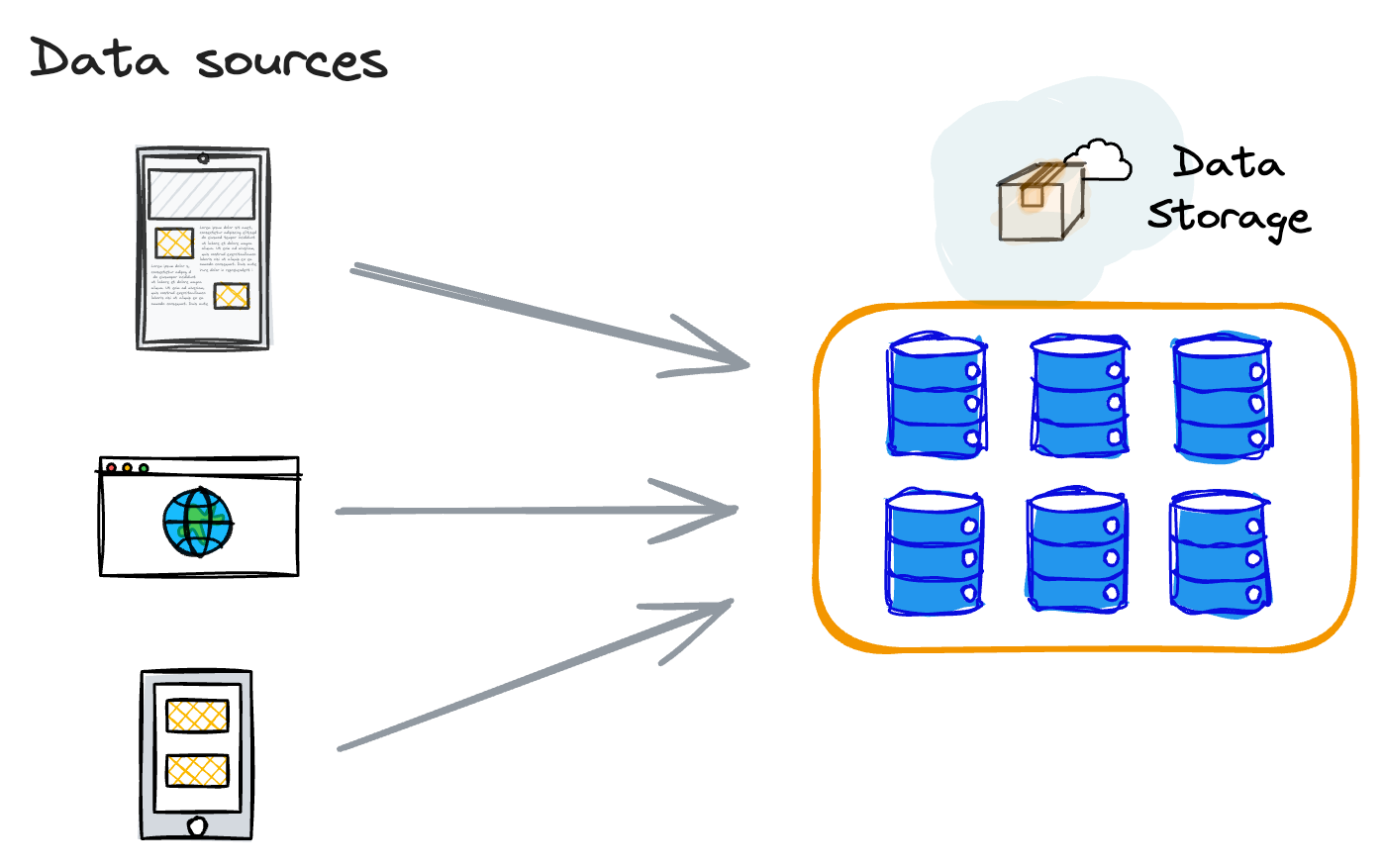
Subsequently, machine learning engineers leverage this centralized data for:
- Analysis,
- Conducting feature engineering,
- And ultimately proceed with the model training, validation, scaling, deployment, and ongoing production monitoring.
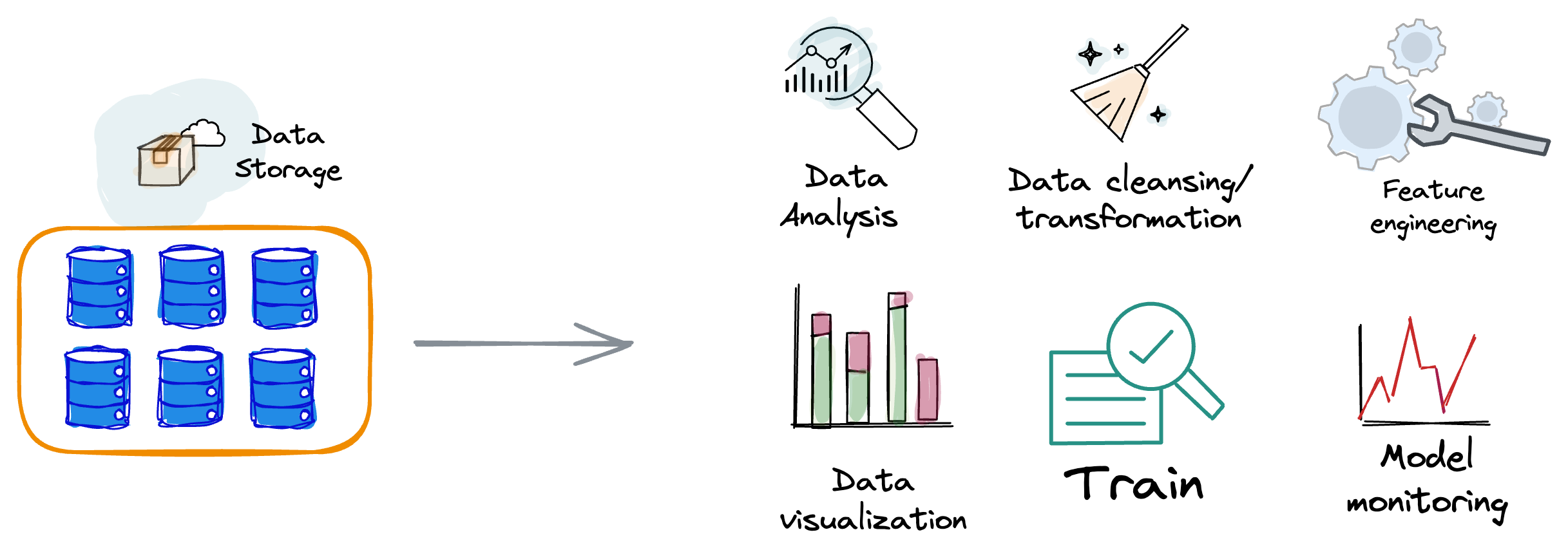
This traditional method is widely accepted and employed in developing ML models.
Nevertheless, a notable challenge associated with this conventional approach is its requirement for data to be physically centralized before any subsequent processing can occur.
Let's understand the issues with this in detail!
Issues with Traditional ML modeling
Consider that our application has a user base of millions. It’s evident that data quantity can be extremely high to deal with.
This data is valuable because modern devices have access to a wealth of data that can be suitable for machine learning models.
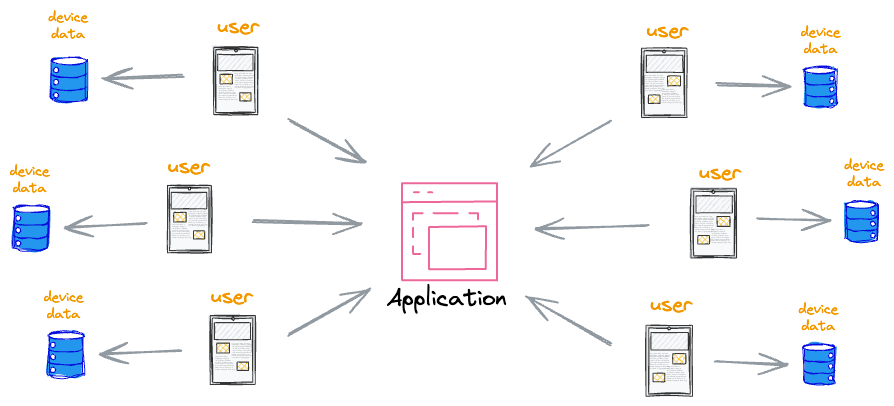
This data can significantly improve the user experience on the device.
For instance:
- If it’s text data, then language models can improve speech recognition and text entry
- If it’s image data, then many downstream image models can be improved, and more.
However, the conventional machine learning approach, which involves aggregating all data in a central repository, presents many challenges in such situations.
More specifically, in this approach, transferring data from individual user devices to a central location is both bandwidth and time-intensive, discouraging users from participating.
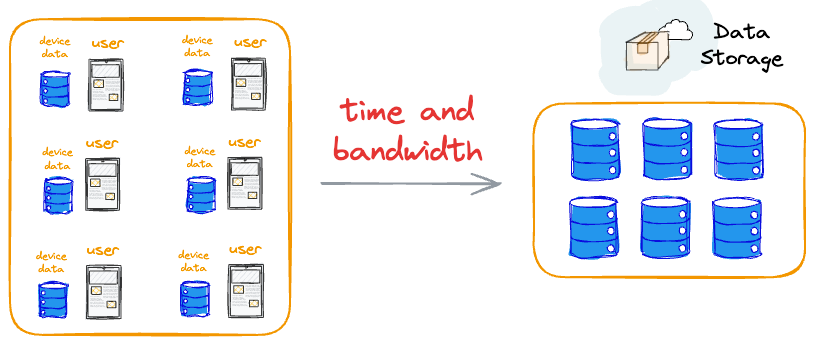
Even if users were incentivized to contribute data, the redundancy of having the data on both the user's device and the central server could be logistically infeasible because of the amount of data we might be dealing with.
Moreover, the data often contains personal information such as photos, private texts, and voice notes.
Requesting users to upload such sensitive data not only jeopardizes privacy but also raises legal concerns. Storing such data in a centralized database becomes problematic, introducing feasibility issues and privacy violations.
This creates problems in storing this data in a centralized database. Simply put, it can be both infeasible and raise many privacy violations.
Moving large amounts of data to a central server can be costly in terms of user bandwidth and time.
But the data is still valuable to us, isn’t it? We want to utilise it some way.
Federated learning is an incredible machine learning model training technique that minimizes data transfer, making it suitable for low-bandwidth and high-latency environments.
Let’s understand!
How Federated learning solves these concerns
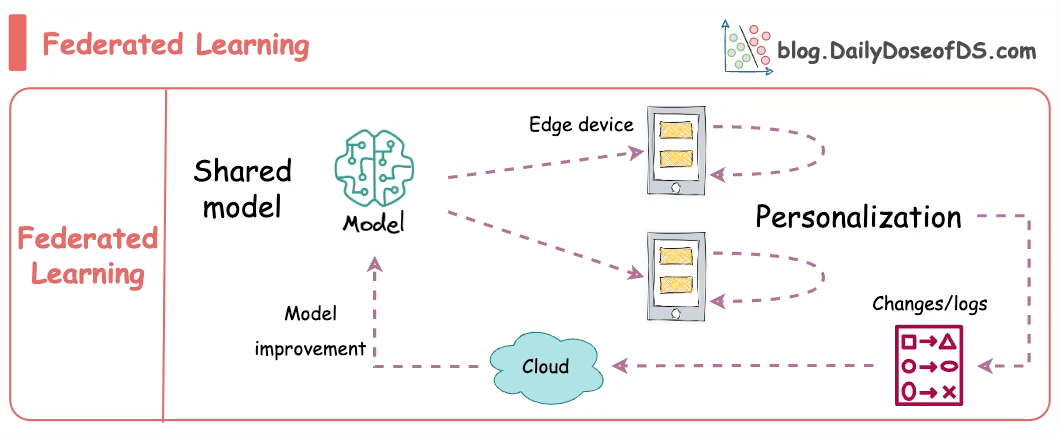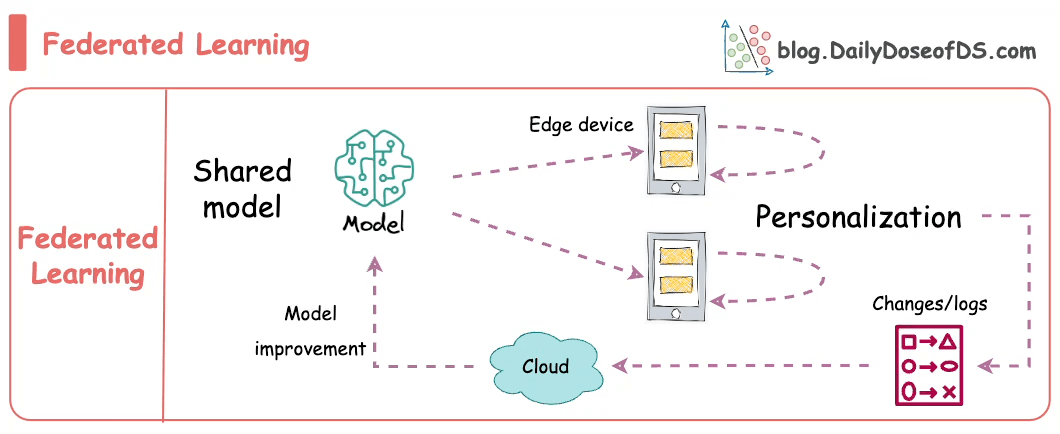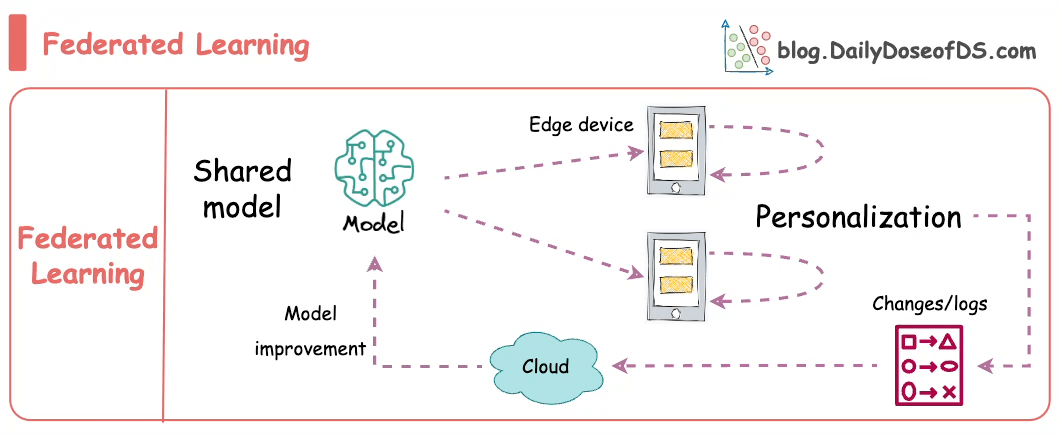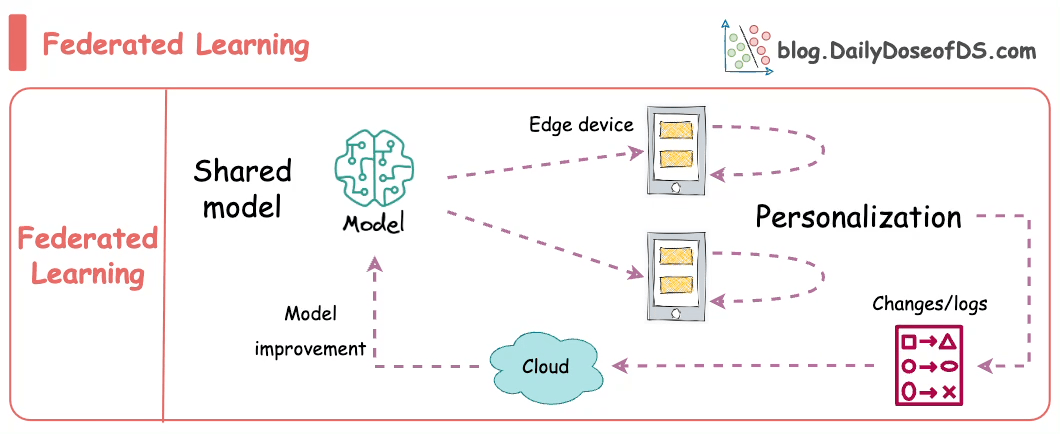
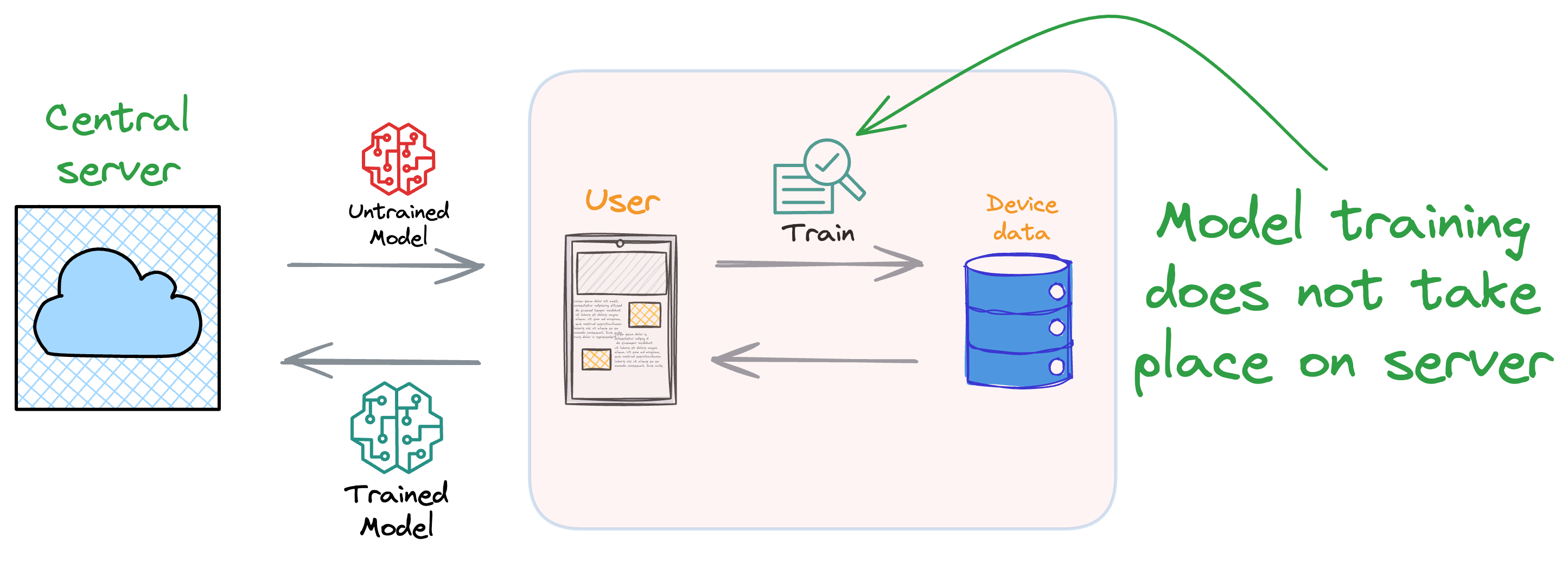
Formally, federated learning represents a decentralized approach to machine learning, wherein the training data remains localized on individual devices, such as smartphones.
Instead of transmitting data to a central server, models are dispatched to devices, trained locally, and only the resultant model updates are gathered and sent back to the server.
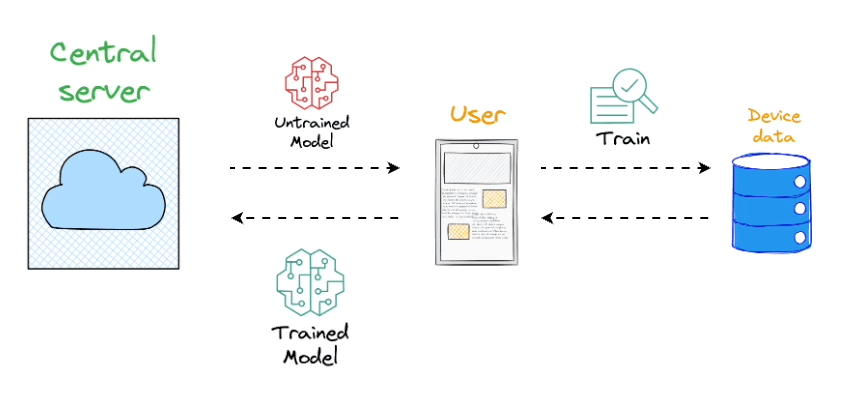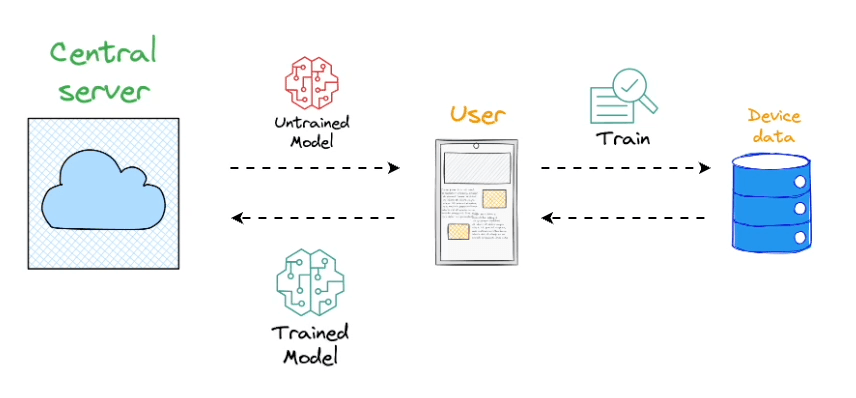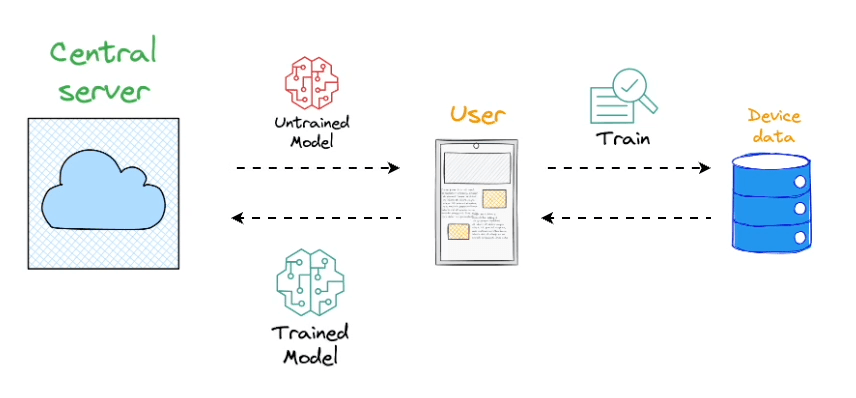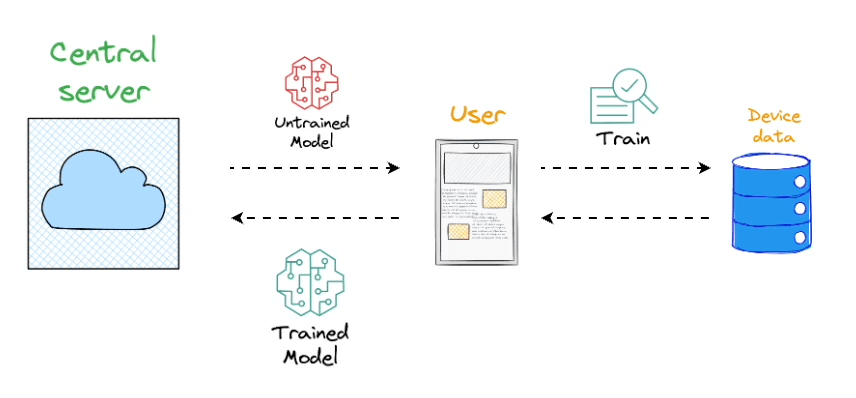
In essence, this approach involves leaving the training data on individual devices while learning a shared model by aggregating locally computed gradient updates.
One of its primary merits lies in enhancing privacy and security by eliminating all dependencies on centralized data collection.
This is because each client possesses a local training dataset that remains exclusively on the device and is never uploaded to the server.
Instead, clients compute updates to the global model maintained by the server, transmitting only the essential "model update."
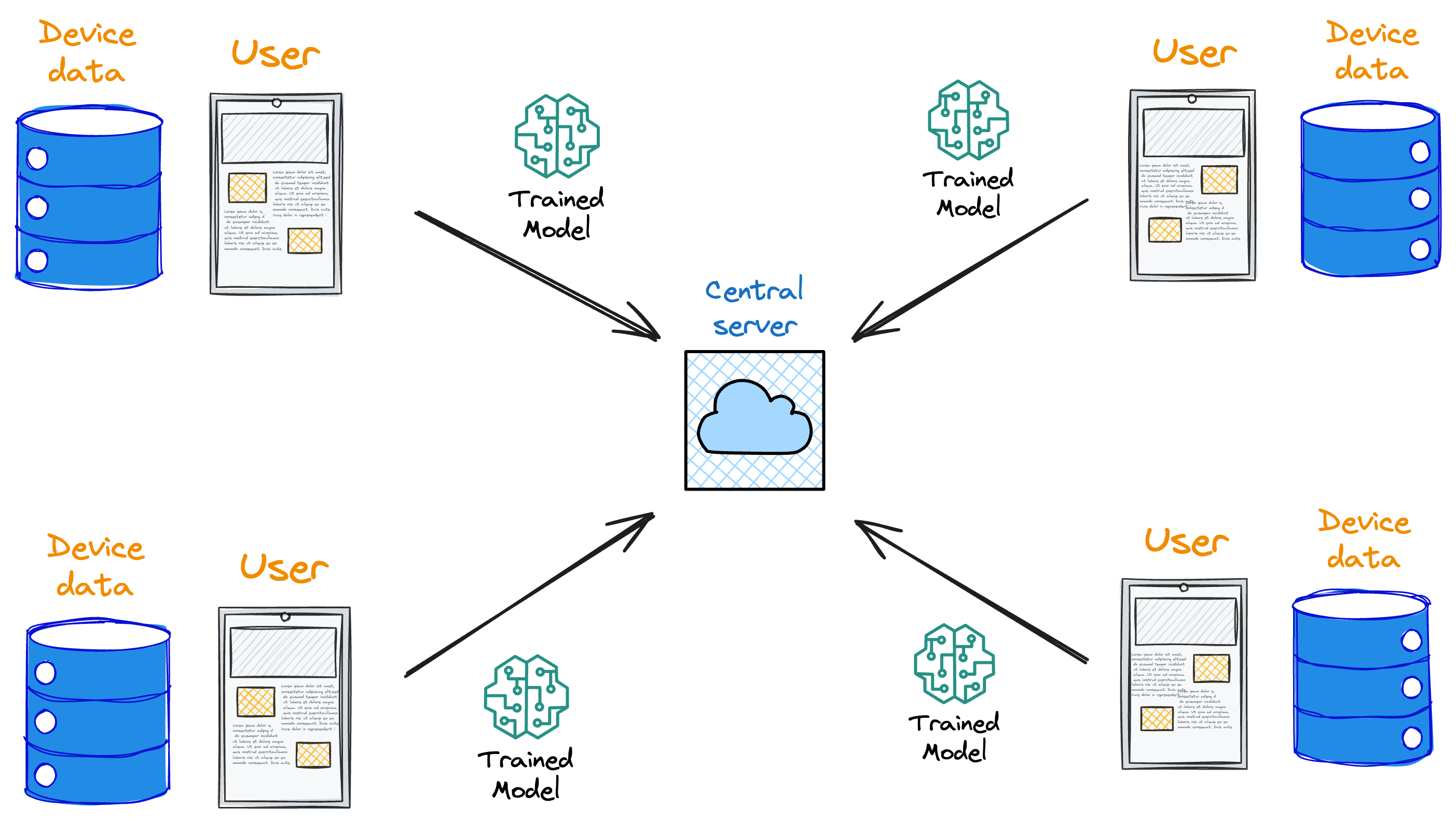
As a result, the entire model update process occurs on the client side, providing a key advantage by decoupling model training from the necessity for direct access to raw training data.
While a degree of trust in the coordinating server is required, federated learning effectively addresses major concerns associated with the conventional centralized approach to machine learning model training.
By facilitating on-device training and minimizing the need for extensive data transfer, federated learning presents practical solutions to challenges inherent in the traditional model training paradigm.
The primary motivations for using federated learning are:
- Privacy:
- Safeguarding user data is a top priority, especially because, lately, more and more users have started caring about their privacy.
- Centralized data repositories pose inherent privacy risks, while federated learning mitigates these concerns by allowing data to reside exclusively on user devices, minimizing exposure.
- Bandwidth and Latency:
- As previously discussed, the resource-intensive process of transferring substantial data volumes to a central server can be both time and bandwidth-consuming.
- Federated learning strategically minimizes data transfer, proving particularly advantageous in environments characterized by low bandwidth and high latency.
- Data Ownership:
- Users maintain control and ownership of their data within the federated learning framework.
- This not only addresses concerns related to data ownership but also ensures the preservation of data rights, offering a user-centric approach to machine learning.
- Scalability:
- Federated learning exhibits a natural scalability that aligns seamlessly with the increasing number of devices.
- This inherent scalability renders it well-suited for applications on a large scale, spanning mobile devices, IoT devices, and edge computing scenarios.
In essence, federated learning represents a paradigm shift by bringing our models to where the data resides, as opposed to the conventional approach of moving data to the location where the model is situated.
This inversion of the traditional model training process emphasizes the adaptability and efficiency of federated learning in contemporary data-driven applications.
How federated learning systems provide privacy?
Certainly, at this point, the argument may arise that anonymizing data before uploading it to central servers can address privacy concerns.
Simply put, anonymizing means removing all personally identifiable information (PII) from a dataset.
This typically involves replacing or encrypting specific data elements to prevent the identification of individuals associated with the information.
However, contrary to common belief, even handling anonymized data can introduce privacy issues.
Consider a scenario with a database of cardholders — a highly sensitive dataset.
While masking card numbers is a common practice, additional details such as cardholder addresses, necessary for processing, may still be present.
Thus, anonymizing the dataset does not always guarantee the elimination of privacy concerns.
Federated learning, on the other hand, minimizes the transmission of data-specific information to centralized locations. As discussed above, the information transmitted is minimal, typically containing significantly less raw data.
In this paradigm, only model updates are sent to the central server, and remarkably, the aggregation algorithm on the server side does not require knowledge of the source of these updates. Thus, the source information can be entirely ignored.
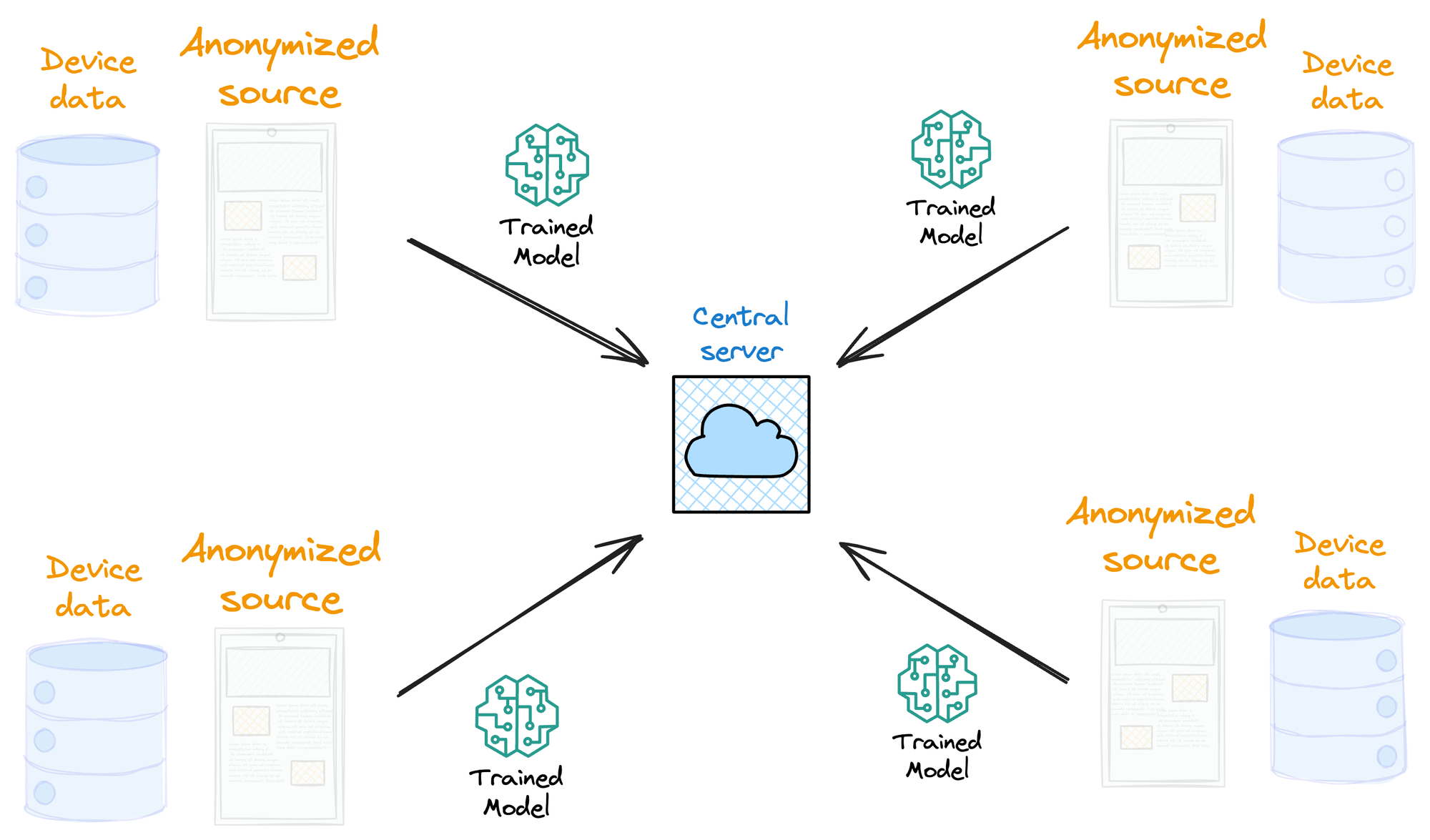
This lack of dependence on the source information guarantees true anonymity by ensuring that locally generated model updates can be transmitted without revealing any other details that might compromise user privacy.
This creates a mutually beneficial scenario.
- Users are content as their experience is driven by high-quality ML models without compromising their data.
- Simultaneously, teams benefit by successfully addressing various challenges, including:
- Privacy Concerns: Federated learning effectively sidesteps privacy issues associated with traditional centralized approaches.
- Reduced Model Training Cost: The approach helps mitigate costs associated with centralized model training.
- Minimized Data Maintenance Cost: Federated learning significantly diminishes the burden of data maintenance costs.
- Large Dataset Training: Teams can train models on expansive datasets without the need for centralized storage.
- Better user experience: Despite centralized data storage, high-quality ML models can be developed.
In essence, federated learning provides a win-win solution for everyone.
Additional benefits of federated learning
More data exposition
In federated learning, the scope of data used for model training extends beyond what centralized data engineering may have collected and managed.
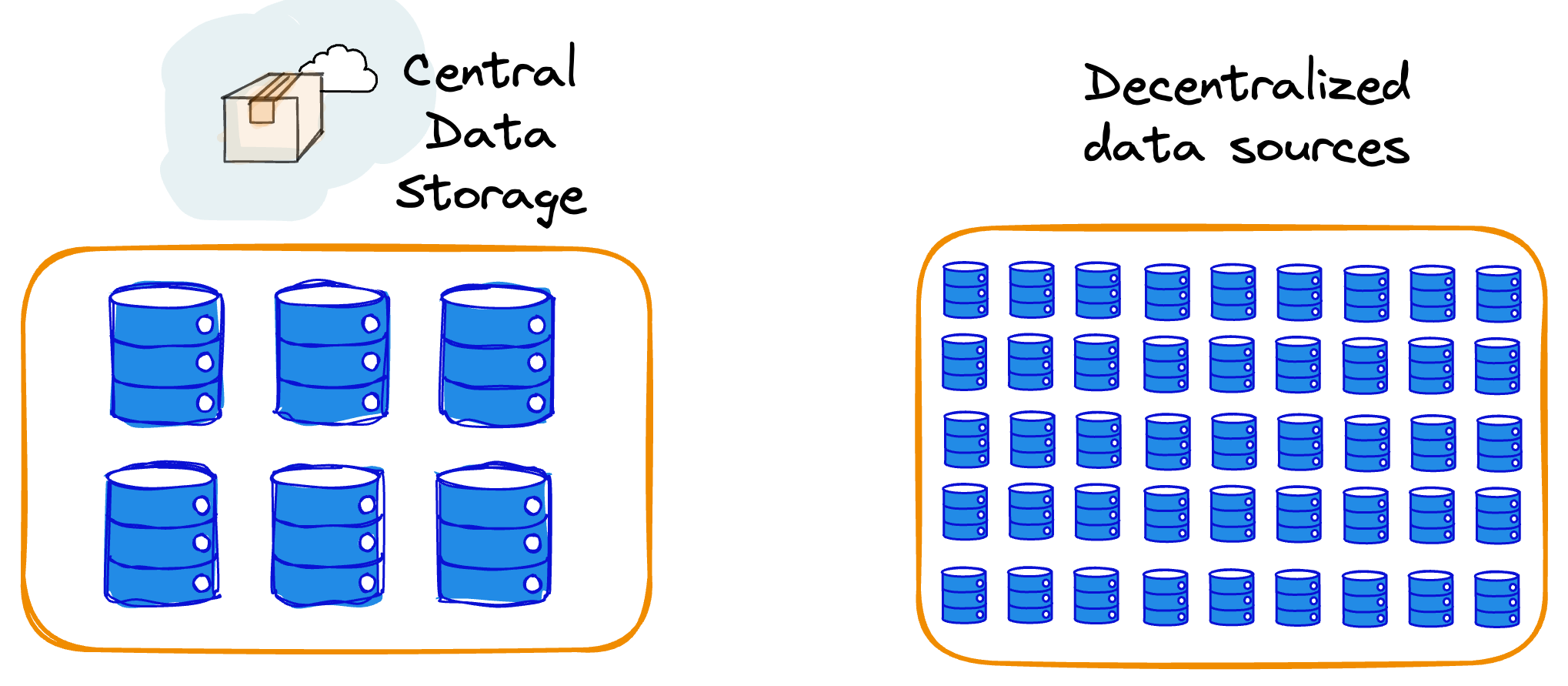
By tapping into the full spectrum of data residing on individual user devices, federated learning enables models to learn from diverse and rich datasets.
This diversity enhances the robustness of models, making them more representative of real-world scenarios.
Mutual benefit
Federated learning not only improves models through collaborative training but also extends benefits directly to users.
When a user's device participates in model training, it receives updates based on collective knowledge, enhancing the user experience.
For example, in a personalized recommendation system, a user benefits from a model trained on the preferences of a larger user base, leading to more accurate and tailored recommendations.
Limited compute requirement
Unlike traditional centralized approaches that demand substantial computational resources for data processing and model training on a central server, federated learning redistributes most computation to user devices.
This shift brings several advantages:
- Reduced Server Load: Central servers require less computational power as they no longer need to process and train on massive amounts of data.
- Lower Latency: Users experience lower latency since data doesn't need to be transmitted to a remote server for processing, thereby improving the overall user experience.
- Energy Efficiency: The local computation on user devices can be more energy-efficient.
When is Federated learning suitable?
Before understanding key strategies for federated learning, it is essential to understand that the applicability of federated learning is not a one-size-fits-all proposition.
Rather than adopting it everywhere, understanding the specific situations when federated learning is the optimal approach is critical.
This is because if you understand these specific types of situations and come across them someday, you will immediately know that federated learning is the way out here.
In my experience, ideal problems for federated learning have the following properties: