Classical ML and Deep Learning
A Beginner-friendly Introduction to Kolmogorov Arnold Networks (KAN)
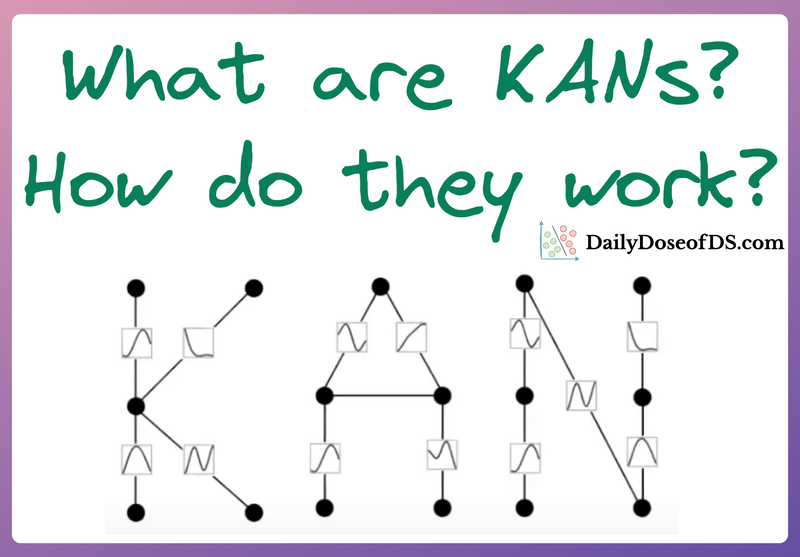
What are KANs, how are they trained, and what makes them so powerful?
A collection of 62 posts
What are KANs, how are they trained, and what makes them so powerful?
A beginner-friendly guide for curious minds who don't know the internal workings of model.cuda().
8 data science lesson I wish I had known earlier.
Techniques that help you become a "machine learning engineer" from a "machine learning model developer."
Immensely simplify deep learning model building with PyTorch Lightning.
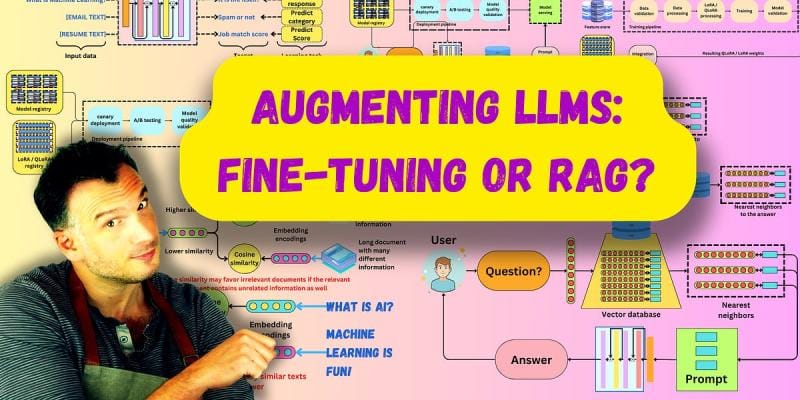
Understanding the tradeoffs between RAG and Fine-tuning, and owning the model vs. using a third-party host.
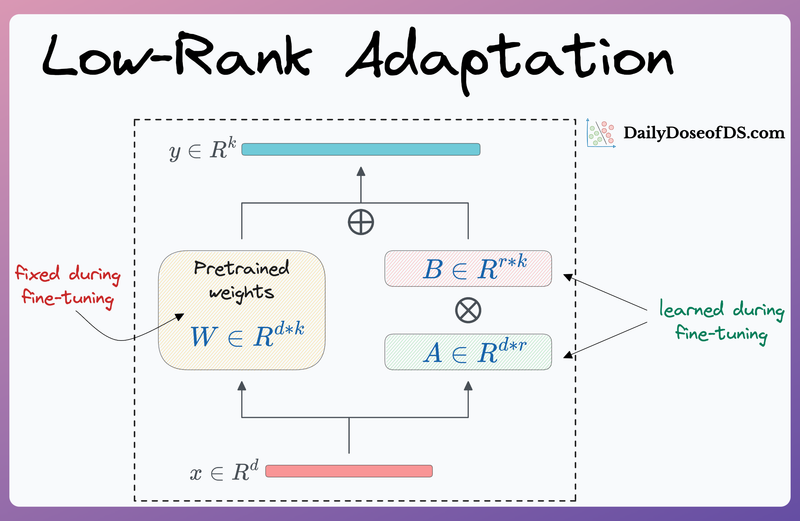
Understanding the challenges of traditional fine-tuning and addressing them with LoRA.
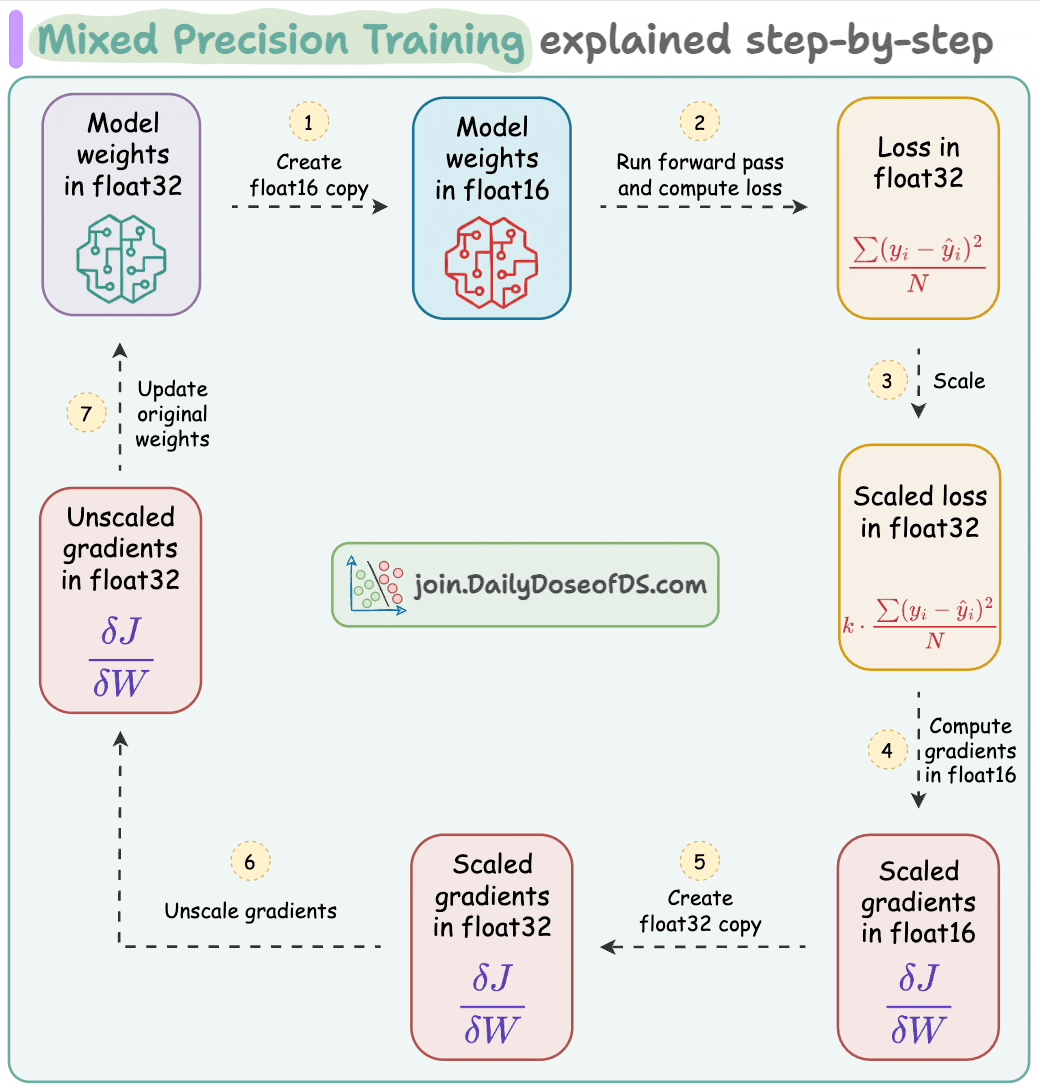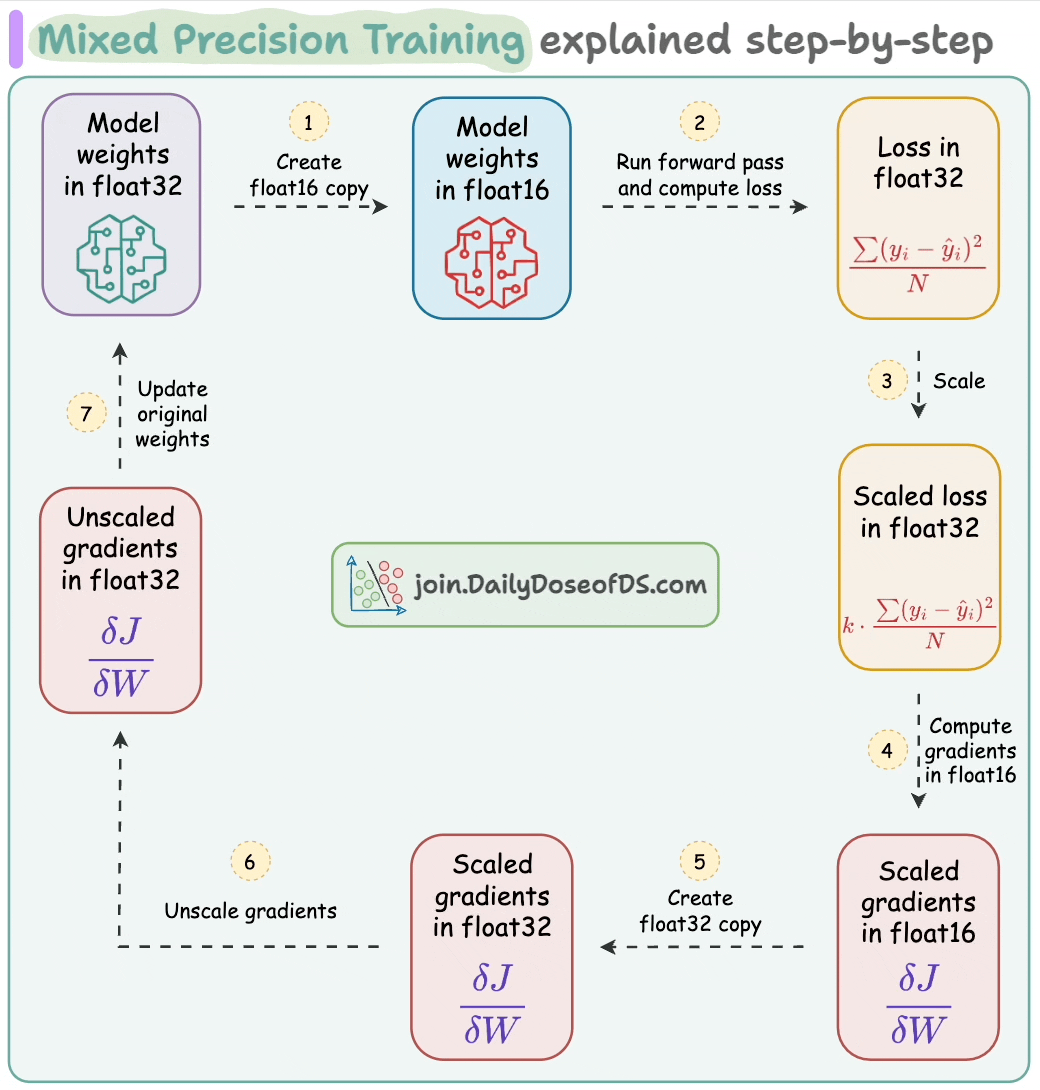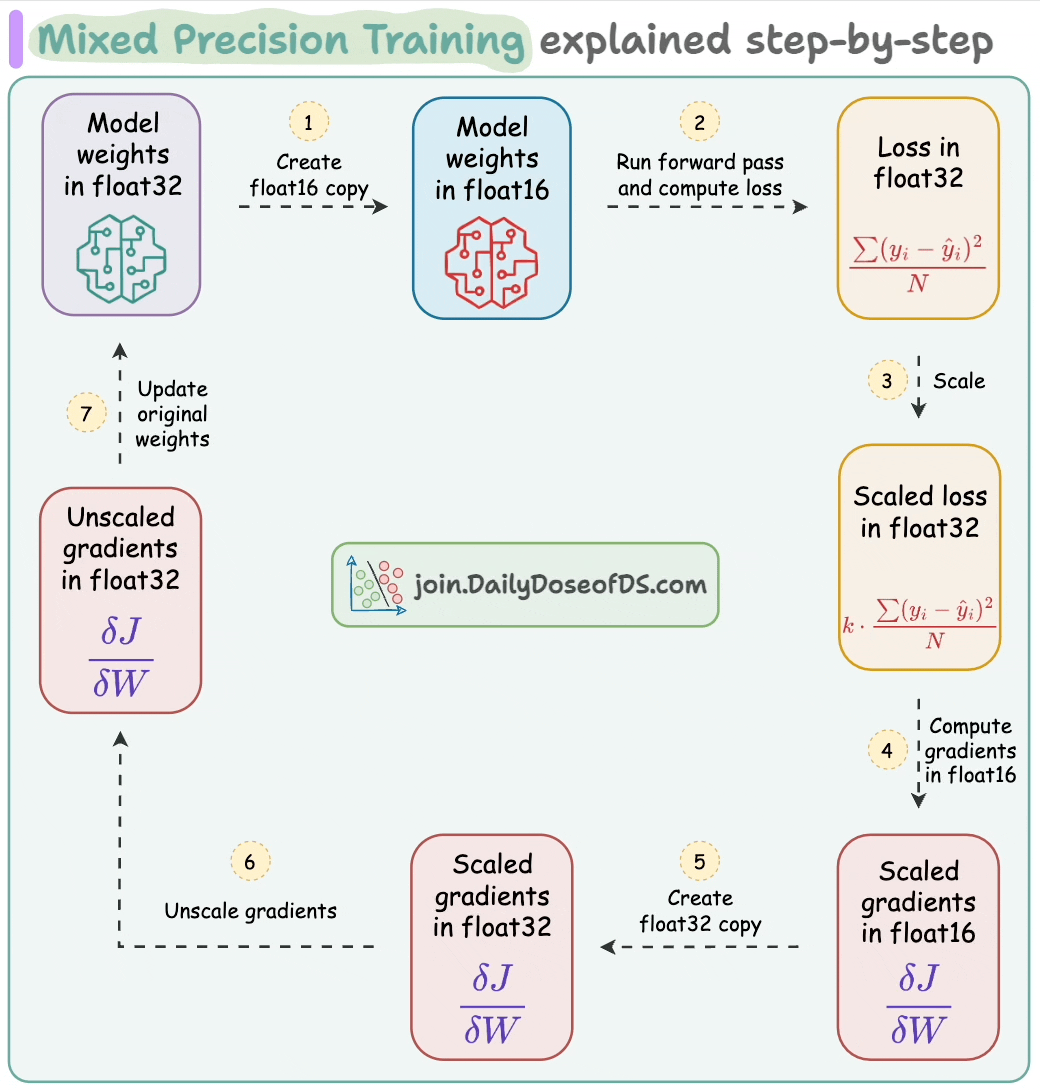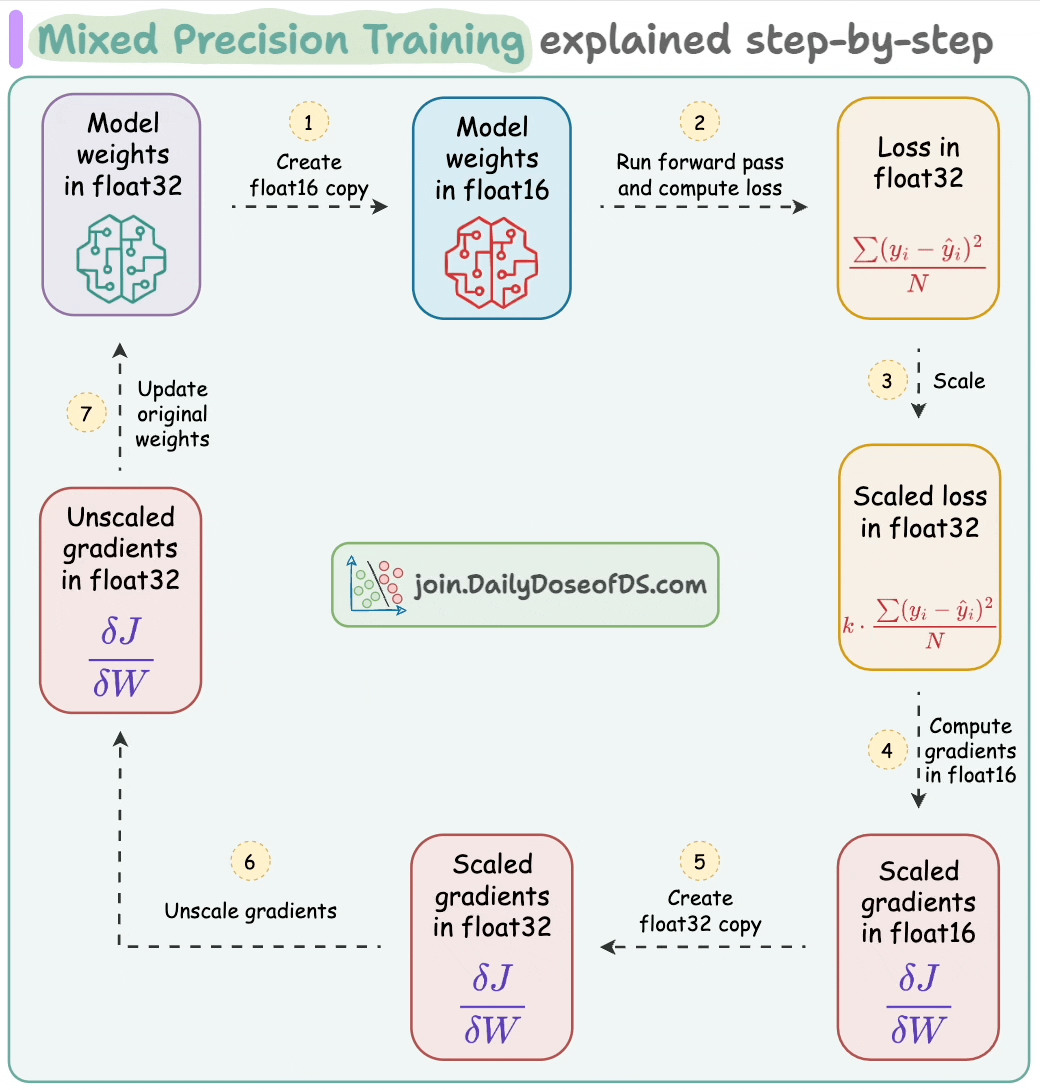
Train large deep learning models efficiently.
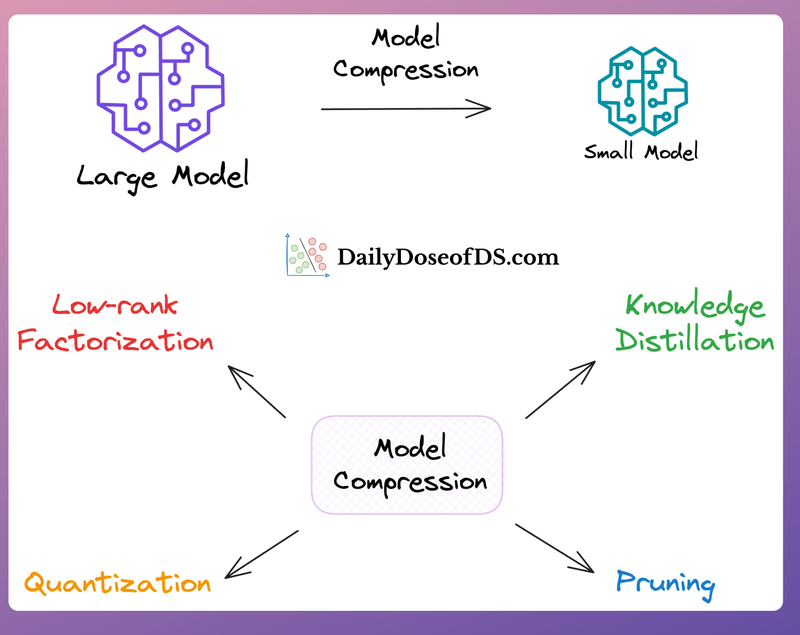
Four critical ways to reduce model footprint and inference time.
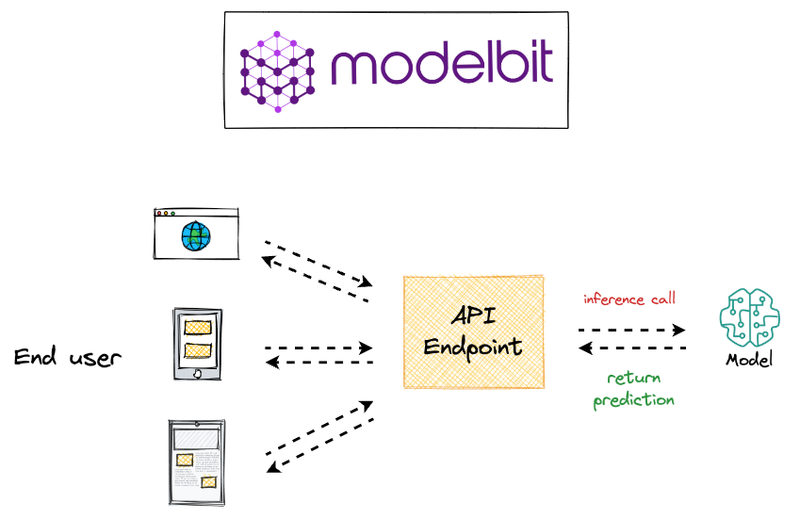
Deployment has possibly never been so simple.
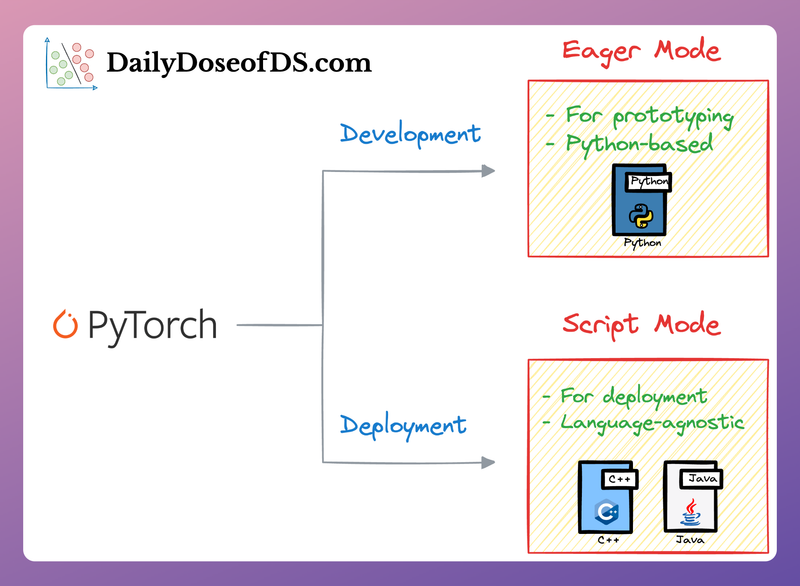
Eliminating the dependence of PyTorch models on Python.
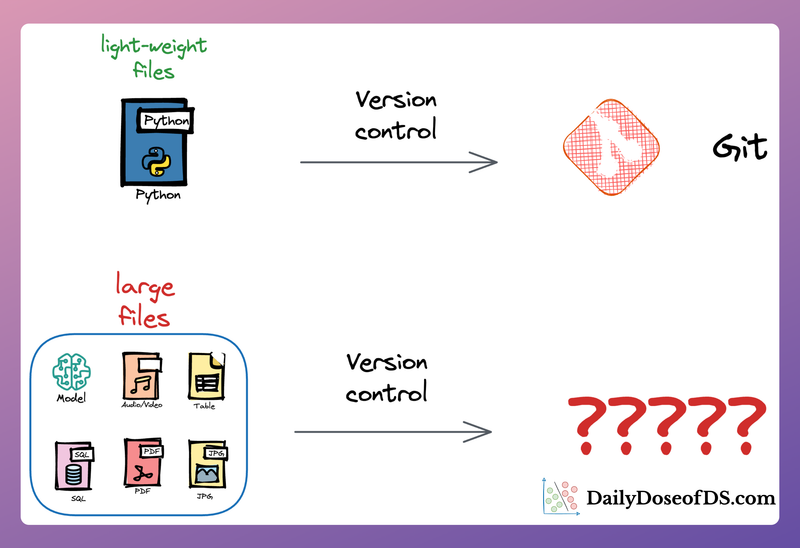
The guide that every data scientist must read to manage ML experiments like a pro.
The guide that every data scientist must read to manage ML experiments like a pro.
The underappreciated, yet critical, skill that most data scientists overlook.
Mathematically understanding the surprising phenomena that arise when dealing with data in high dimensions.
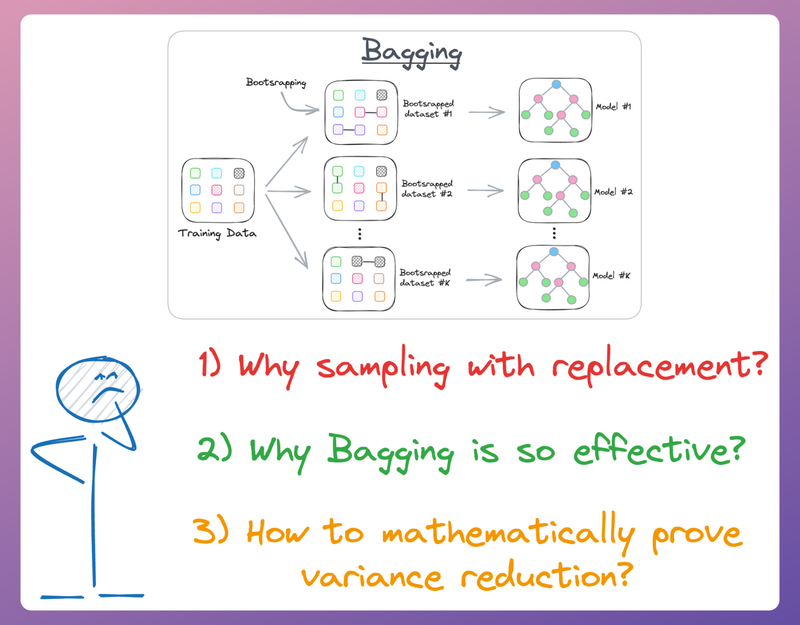
Diving into the mathematical motivation for using bagging.
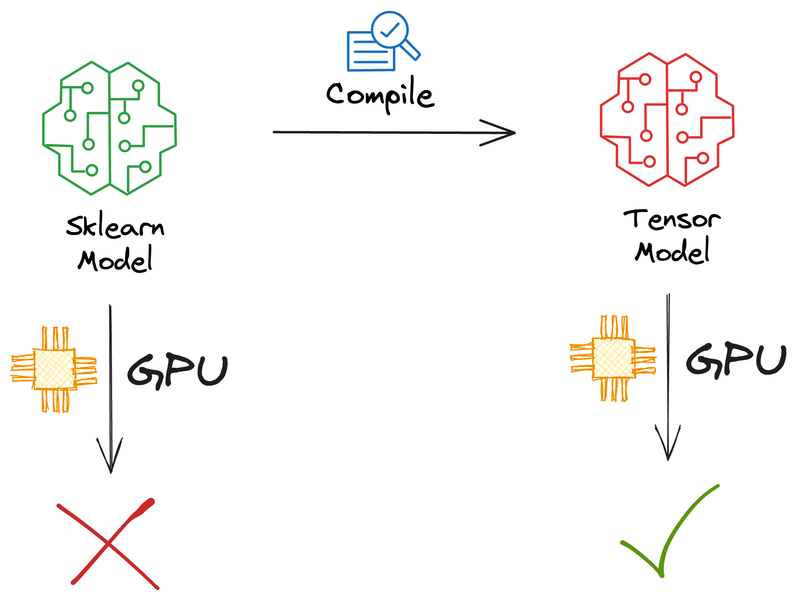
Speed up sklearn model inference up to 50x with GPU support.
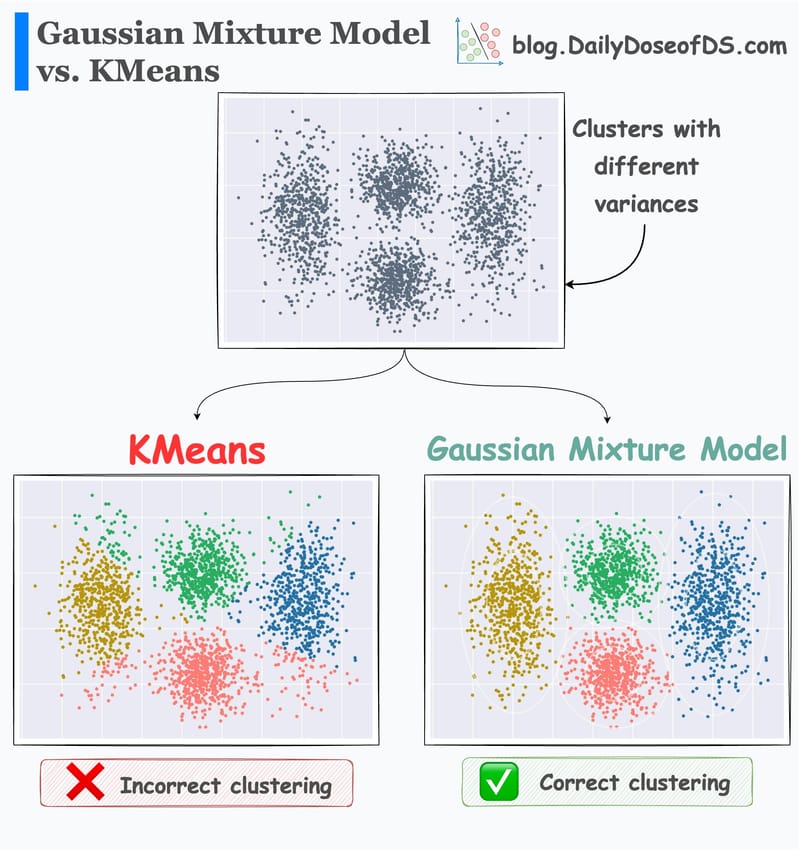
Gaussian Mixture Models: A more robust alternative to KMeans.
Addressing major limitations of the most popular density-based clustering algorithm — DBSCAN.
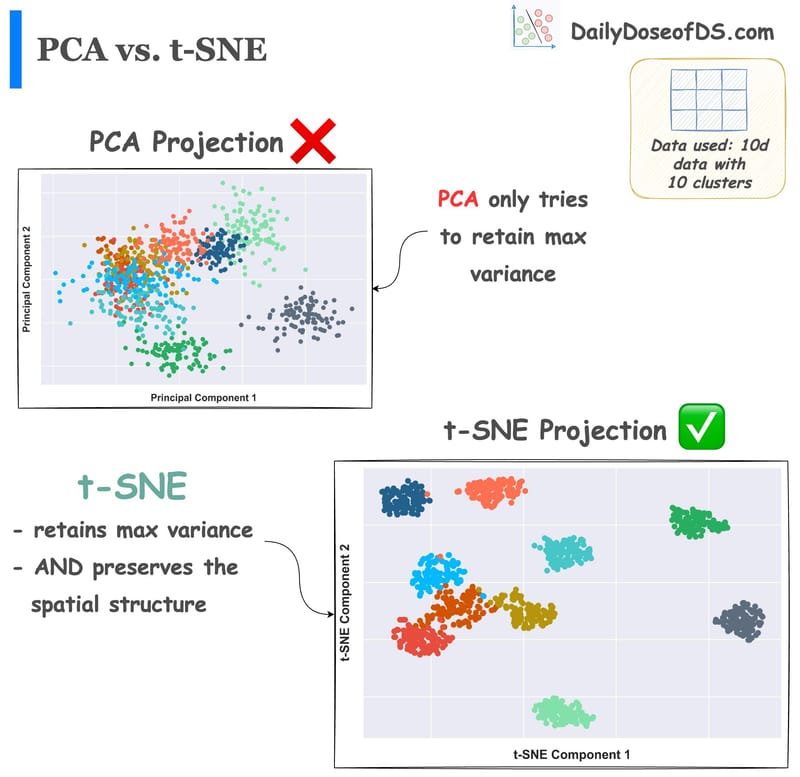
The most extensive visual guide to never forget how t-SNE works.
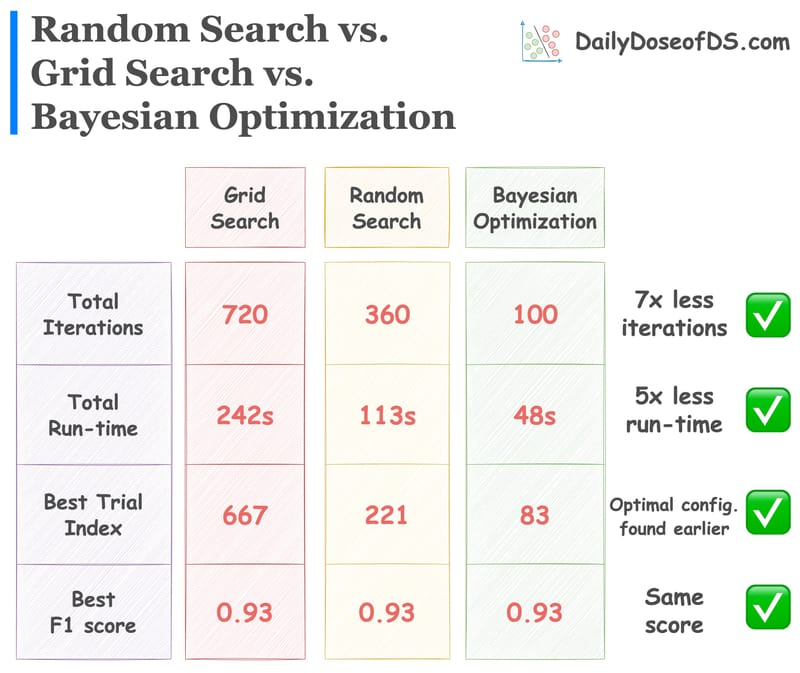
The caveats of grid search and random search and how Bayesian optimization addresses them.
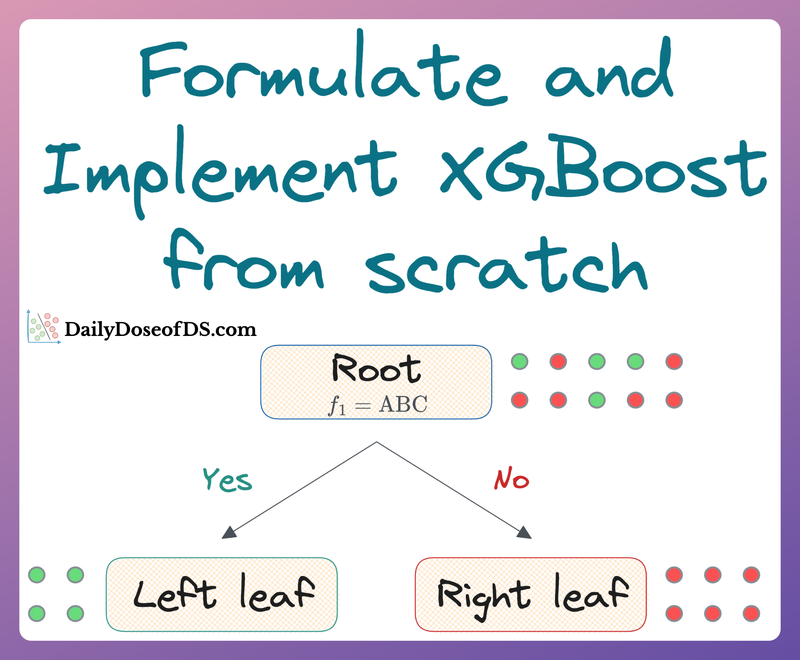
An extensive visual guide to never forget how XGBoost works.
Approaching PCA as an optimization problem.
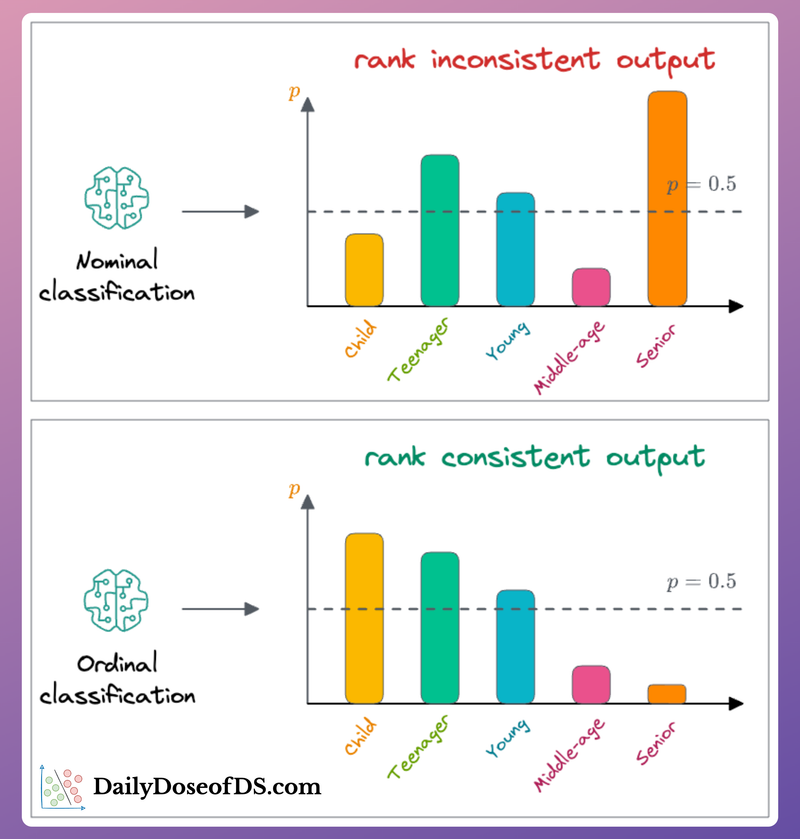
The limitations of always using cross-entropy loss in ordinal datasets.
The lesser-known limitations of the R-squared metric.
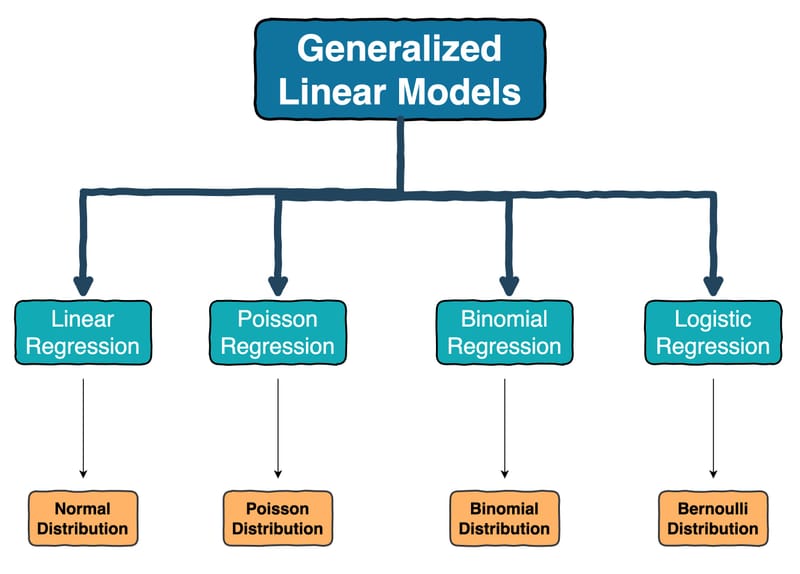
The limitations of linear regression and how GLMs solve them.
What are we missing here?
The origin of log-loss.
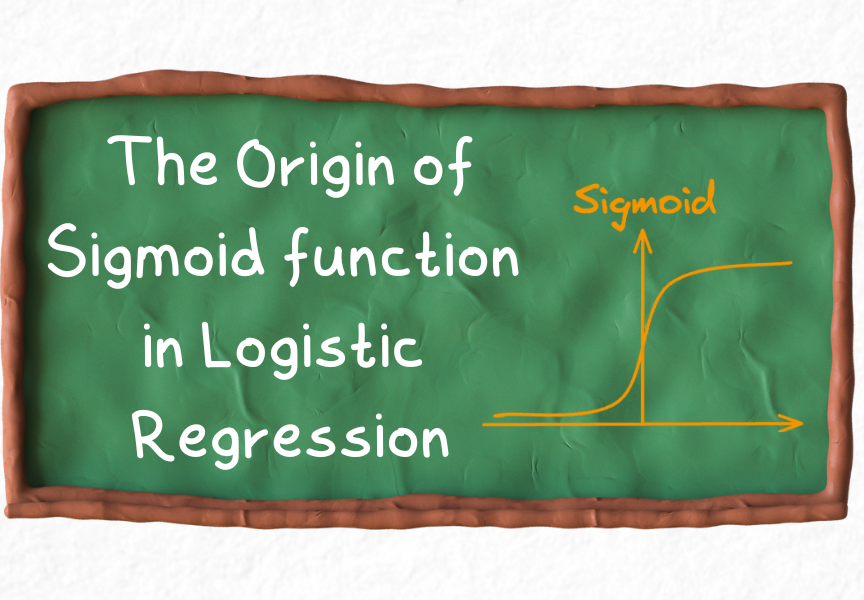
The origin of the Sigmoid function and a guide on modeling classification datasets.
Where did the regularization term come from?