How to Streamline Your Machine Learning Workflow With DVC
The guide that every data scientist must read to manage ML experiments like a pro.
Introduction
In my experience, most ML projects lack a dedicated experimentation management/tracking system.
As the name suggests, this helps us track:
- Model configuration → critical for reproducibility.
- Model performance → critical for comparing different models.
…across all experiments.
What’s more, consider that our ML pipeline has three steps:
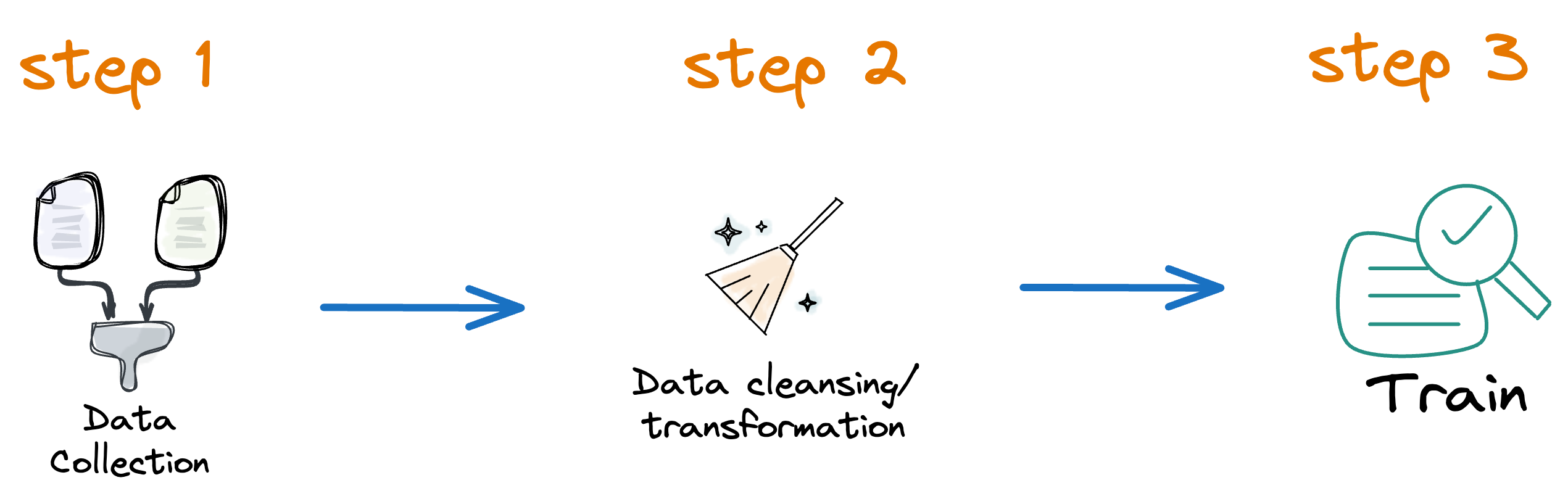
If we only made some changes in model training (step 3), say, we changed a hyperparameter, does it make any sense to rerun the first two steps?
No, right?
Yet, typically, most ML pipelines rerun the entire pipeline, wasting compute resources and time.
Of course, we may set some manual flags to avoid this.
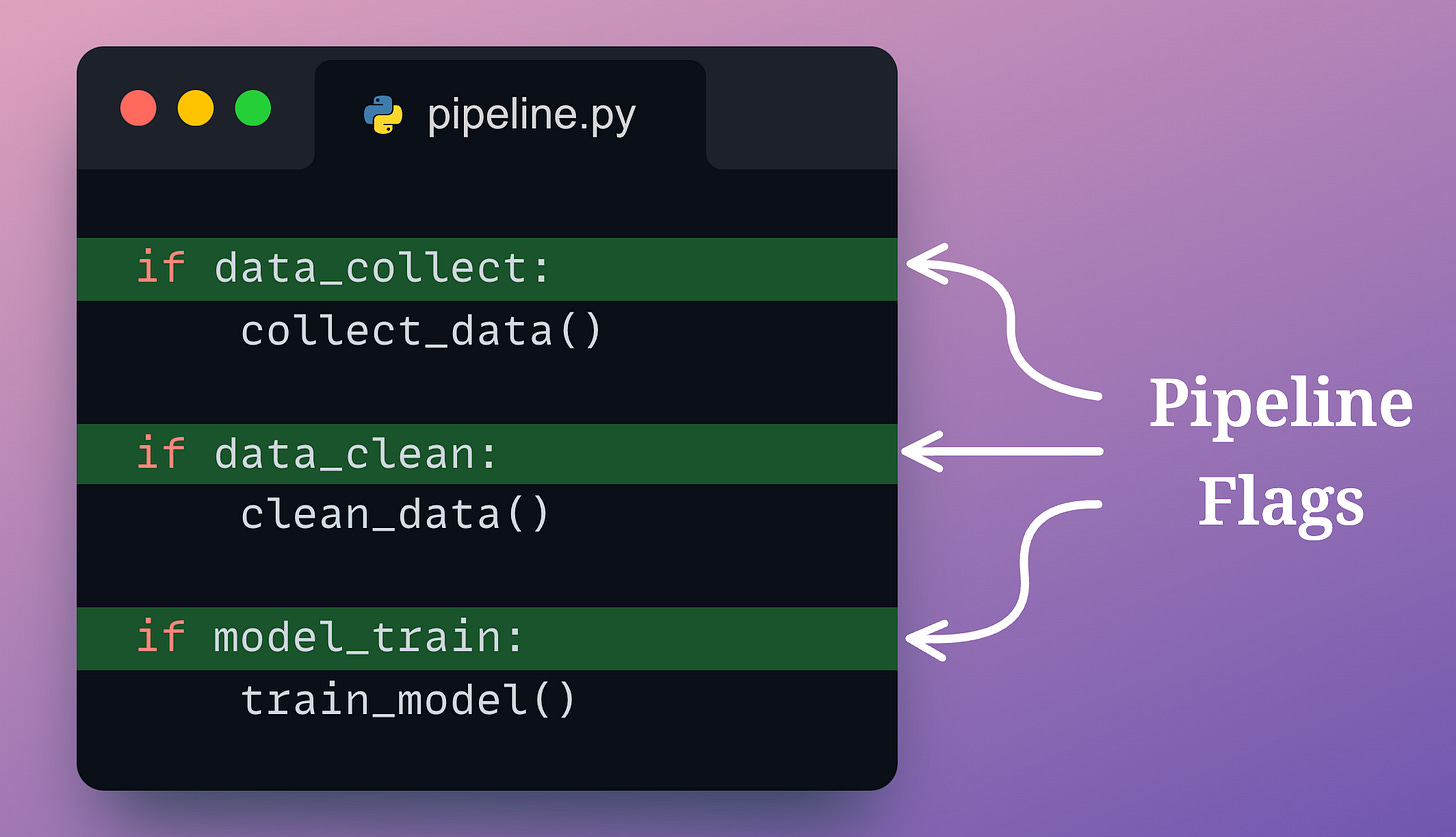
But being manual, it will always be prone to mistakes.
To avoid this hassle and unnecessary friction, an ideal tracking system must be aware of:
- All changes made to an ML pipeline.
- The steps it can avoid rerunning.
- The only steps it must execute to generate the final results.
While the motivation is quite clear, this is a critical skill that most people ignore, and they continue to leverage highly inefficient and manual tracking systems — Sheets, Docs, etc.
To help you develop that critical skill, I'm excited to bring you a special guest post by Bex Tuychiev.
Bex is a Kaggle Master, he’s among the top 10 AI/ML writers on Medium, and I am a big fan of his writing.

In this machine learning deep dive, he will provide a detailed guide on where we left last week — data version control with DVC.
Make sure you have read that article before proceeding ahead:
More specifically, this article will expand on further highly useful features of DVC for machine learning projects.
The article has been divided into two parts, and by the end of this article, you will learn:
- How to efficiently track and log your ML experiments?
- How to build efficient ML pipelines?
Over to Bex!
Why track experiments in machine learning?
Keeping track of machine learning experiments is like keeping FIVE dogs in a bathtub.
Without help, at least FOUR of them are bound to slip out of your hands and ruin everything.
A total disaster is what’s going to happen if you don’t have a proper experiment management system.
First, you’ll probably end up with a complete mess of code, with no idea which version of the model is the most recent or the best performing.
You’ll constantly be overwriting and losing important code, and it will be almost impossible to reproduce your results or track your progress.
On top of that, you’ll have no way of keeping track of hyperparameters, metrics, or any other important details of your experiments (unless you want to write them down). You’ll be flying blind.
In all seriousness, a proper experiment management system is crucial for any machine learning project.
It allows you to track and compare your experiments, reproduce results, and make informed decisions about the direction of your project.
Without it, you’re just shooting in the dark and hoping for the best.
What you will learn in Part 1
By finishing this tutorial, you will be able to track your machine-learning experiments by adding a single line of code to your training script.
In the end, you will have a table of experiments, which you can sort by any metric or parameter to find the best model for your use case.
Let's begin!