Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
A beginner-friendly guide for curious minds who don't know the internal workings of model.cuda().
Introduction
Due to advancements in open-source frameworks like PyTorch, utilizing GPUs to accelerate the training of deep learning models just takes one simple step, as demonstrated below:
While this encapsulation is as easy as it can get, the underlying implementation of how GPUs accelerate computing tasks is still unknown to many.

More specifically, what happens under the hood when we do a .cuda() call?
In this article, let’s understand the mechanics of GPU programming.
More specifically, we shall understand how CUDA, a programming interface developed by NVIDIA, allows developers to run processes on their GPU devices and how the underlying implementations work.
Thus, we shall do a hands-on demo on CUDA programming and implement parallelized implementations of various operations we typically perform in deep learning.
Let’s begin!
What is CUDA?
Simply put, CUDA, also known as Compute Unified Device Architecture, is a parallel computing platform and application programming interface (API) model created by NVIDIA (as mentioned above).
It allows developers to use a CUDA-enabled graphics processing unit (GPU) for general-purpose processing.
In order to leverage the processing power of GPU, CUDA provides an interface implemented in C/C++. This allows us to access the GPU’s memory and run compute operations.
In the context of deep learning, these are typical mathematical operations and general operations like:
- Adding matrics/vectors
- Multiplying matrices
- Transforming a matrix by applying a function, such as an activation function, dropout, etc.
- Moving data from CPU to GPU, and then back to CPU.
- And more.
To put it another way, just like Pandas allows developers to interact seamlessly with tabular datasets through high-level data structures and operations, CUDA enables a similar level of abstraction but for processing on NVIDIA GPUs.
By abstracting the underlying complexities associated with GPU, such as memory management, thread handling, and handling blocks, developers get to focus more on solving the computational problems at hand rather than the intricacies of the hardware they are running on.
Of course, as mentioned above, the CUDA provides a C/C++ interface, and deep learning frameworks like PyTorch made this simpler by building a Python-based wrapper around it:

So when we develop deep learning models, we use a Python API, which, under the hood, has implemented C/C++ instructions provided by CUDA to talk to GPU.
Thus, just to be clear, the objective of this deep dive is to understand the CUDA -> GPU instructions and how they are implemented.
While some proficiency in C/C++ is good to have, it is not entirely necessary as the API design is quite intuitive. Yet, I will provide some supporting texts at every stage of the programming if you have never used C++ before.
The problem with CPUs
When it comes to parallelization, the traditional approach with CPUs involves leveraging threads, which carry instructions that the processor can execute independently.
For instance, consider this simple for-loop written in C, which performs the operations of a typical linear layer:
Notice the for-loop in the above code. It iterates over the elements of the arrays one by one, computes the individual result, and stores it in the output array.
Here, if you notice closely, all these individual operations are independent of each other.

Thus, they can be executed in parallel. However, the above implementation uses a sequential approach where each operation waits for the previous one to complete before starting.
Given that modern CPUs can handle multiple threads simultaneously through techniques like multi-threading, we can make use of it to allow the loop to spawn multiple threads, potentially one per core, to handle different parts of the array simultaneously.
And this must be obvious to understand that typically, the more threads we add, the higher the level of parallelism we can achieve.
In deep learning, however, things are different.
The building blocks of deep learning models – vectors and matrices, can have millions of elements.
However, by their very nature, CPUs are limited in the degree of parallelism they can achieve because of a limited number of cores (even high-end consumer CPUs rarely have more than 16 cores).
GPUs are modern architectures that can run millions of threads in parallel. This enhances the run-time performance of these mathematical operations when dealing with massively sized vectors and matrices.
A motivating example
Let’s consider the matrix multiplication operation depicted below, which is quite prevalent in deep learning:
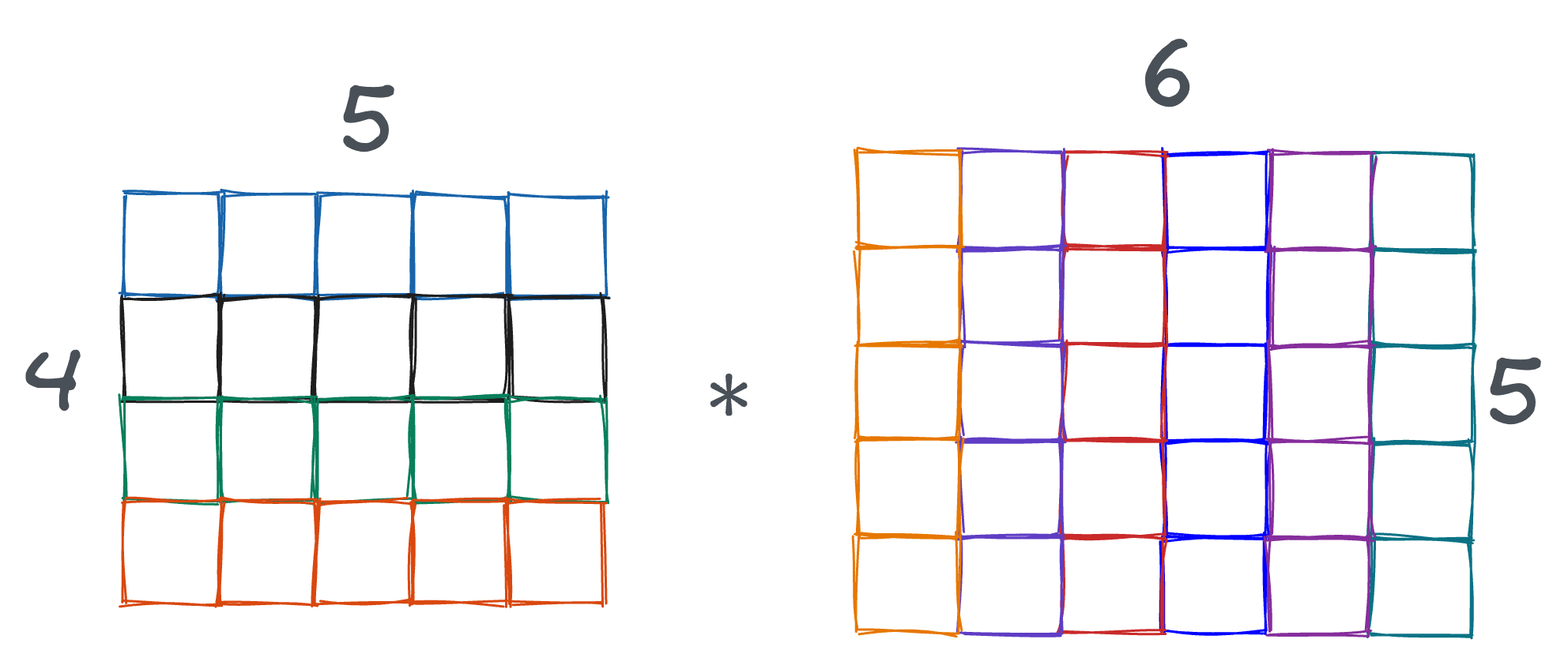
At its core, matrix multiplication is just a series of various independent vector dot products, as depicted in the animation below:
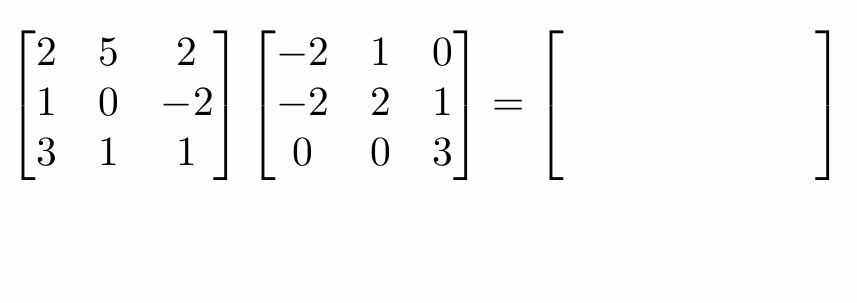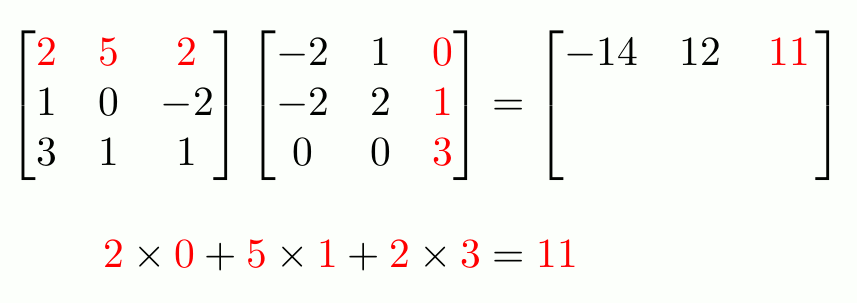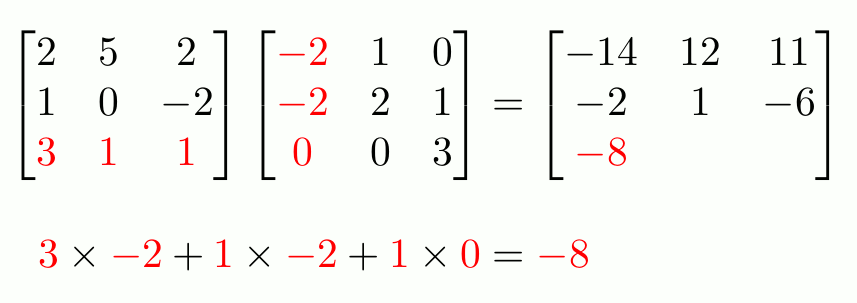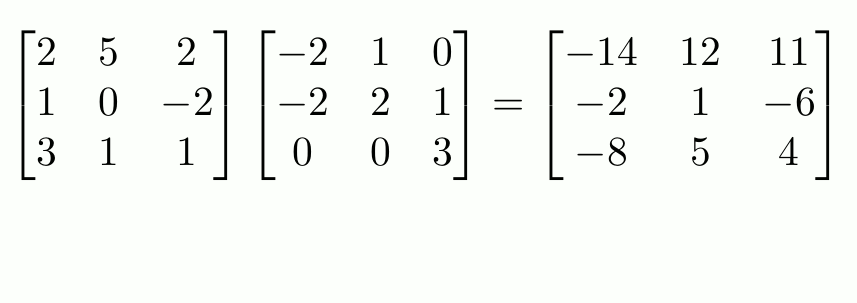
- $1^{st}$ row of left matrix is multiplied with:
- $1^{st}$ column of the right matrix.
- $2^{nd}$ column of the right matrix.
- $3^{rd}$ column of the right matrix.
- And so on.
- $2^{nd}$ row of left matrix is multiplied with:
- $1^{st}$ column of the right matrix.
- $2^{nd}$ column of the right matrix.
- $3^{rd}$ column of the right matrix.
- And so on.
- And so on...
If you look closely, all these operations are independent of one another. As a result, all these operations can be potentially executed in parallel.
However, as discussed above, since CPUs have fairly limited threads, they are not ideal for exploiting the full potential of parallelizing these matrix multiplication operations.
In other words, CPUs typically handle only a few dozen threads simultaneously, which limits their efficiency in executing numerous independent operations at once, such as those required by large-scale matrix multiplications.
How do GPUs help?
Here, it is essential to clarify one point that CPUs are not "bad."
There's a reason why all modern computers always come with a CPU, but they may or may not have a “fast” GPU. This is because the CPU and GPU are designed to accomplish completely different goals.
To begin, CPU computations are usually faster than that of GPU for a single operation. In other words, they are designed to quickly execute a sequence of single-threaded operations. Thus, to maintain that speed, they can only execute a few threads in parallel.
In contrast, GPUs are designed to execute millions of threads in parallel at the cost of the speed of individual threads.
So while a thread may take less time to execute on a CPU, but as GPUs can execute millions of them in parallel, it tremendously boosts the overall run-time.
A real-life analogy
One real-life analogy I heard when I first learned about them many years back compared the CPU to an F1 car and the GPU to a bus.

If the objective is to move just one person from point A to point B, then the F1 car, i.e., the CPU, will be an ideal choice.
On the other hand, if the objective is to move many people from one point to another, then the bus, i.e., the GPU, will be an ideal choice. This is despite the fact that an F1 car will take less time to travel from point A to point B.
While the bus can transport everyone in one trip, an F1 car would require multiple trips.
CUDA programming
Now that we have covered the basics, let’s get into the programming related details.
In this section, we shall learn how CUDA programs are written. We shall first start by understanding the components of CUDA programming and then get into the implementations.
Components of CUDA programming
There are three components in CUDA programming – host, device, and kernel. These three components are foundational to how CUDA interfaces with the hardware and manages computations.
Here's a brief overview of each of them:
#1) Host
In CUDA terminology, the "host" refers to the CPU and its memory. It's where your program starts and runs before offloading any parallel compute-intensive tasks to the GPU.
The host controls the entire application flow, it initiates data transfers to and from the GPU memory, and it launches GPU kernels.
In other words, it orchestrates the preparation and execution of GPU tasks from a higher level.
#2) Device
The "device" refers to the GPU itself and its associated memory. In the context of CUDA, when we mention the device, we're typically talking about the CUDA-enabled GPU that will perform the actual parallel computations.
The device executes the code specified in the CUDA kernels, which are functions written to run on the GPU.
It handles the intensive computational tasks that have been offloaded from the CPU, utilizing its massively parallel architecture to process data more efficiently for specific types of tasks.
#3) Kernel
A kernel in CUDA is a function written in CUDA C/C++ that runs on the GPU. This is the core piece of code that is executed in parallel by multiple threads on the CUDA device.
When a kernel is launched, the GPU executes it across many threads in parallel.
Each thread executes an instance of the kernel and operates on different data elements. The kernel defines the compute operations each thread will perform, making it the primary means of parallel computation in CUDA.
Execution Workflow
So, to recap, here’s what this process looks like:
- Preparation on the host: The host CPU executes the main part of the CUDA program, setting up data in its own memory, and preparing instructions.
- Data transfer: Before the GPU can begin processing, the necessary data must be transferred from the host’s memory to the device’s memory.
- Kernel launch: The host directs the device to execute a kernel, and the GPU schedules and runs the kernel across its many threads.
- Post-processing: After the GPU has finished executing the kernel, the results are typically transferred back to the host for further processing or output, completing the compute cycle.
Threads, Blocks and Grids
When it comes to GPU computing, the key advantage is its ability to execute many operations (specified in the kernel) in parallel.
Thus, instead of executing the kernel just once and iterating through the computations one by one, we execute it $N$ times in parallel.
However, this parallel execution is not just about blasting multiple instances of the same operation on the GPU.
Instead, it’s about structuring the entire computation in a way that maximizes the GPU's architectural strengths—mainly, its capacity to handle a vast number of simultaneous threads.
We achieve this using the hierarchical organization of GPU computation, called threads, blocks, and grids.
Threads
A thread is the smallest unit of execution. Each thread executes the set of instructions specified in the kernel that are specific to the thread that is invoking the kernel.

Also, each thread is mapped to a single CUDA core for execution:
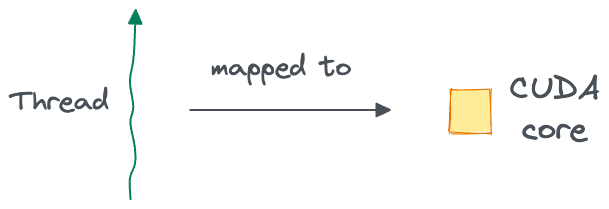
Blocks
A block is a group of threads that execute the same kernel and can cooperate by sharing data and synchronizing their execution.
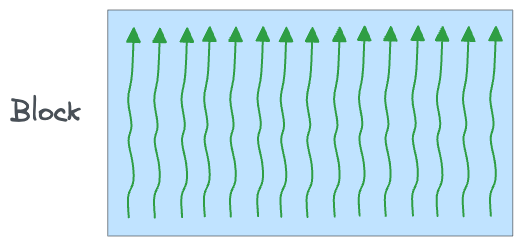
Blocks are, in essence, a way to organize threads into manageable, cooperative groups that can efficiently execute part of a larger problem. Typically, a single block can contain up to 1024 threads, but this may vary depending on the computing capability of the GPU.
Each block is mapped to a corresponding CUDA core for execution:
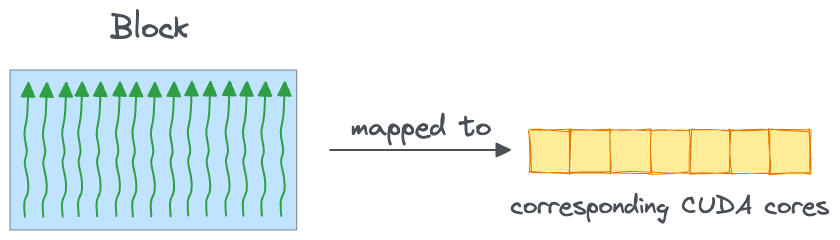
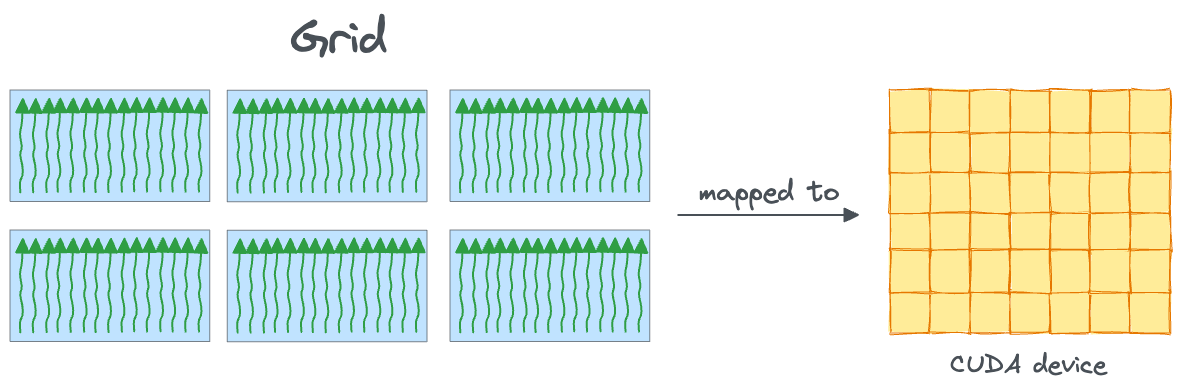
Grid
A grid is the highest level of thread organization in CUDA. The blocks within a grid can operate independently, meaning they do not share data directly nor synchronize with each other.
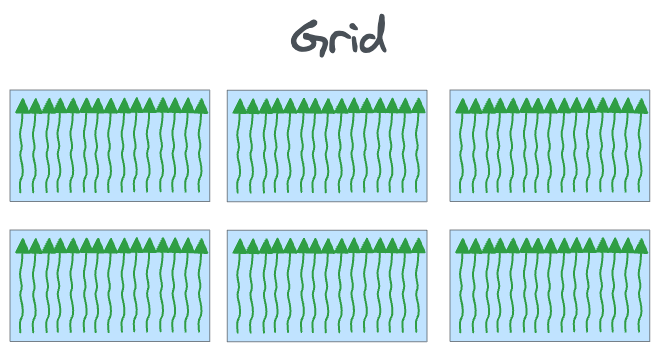
The entire kernel launched is executed as one grid, which is mapped onto the entire device:
CUDA variables
Moving on...
Structurally speaking, Threads inside a Block can be organized in up to three dimensions, as depicted below:
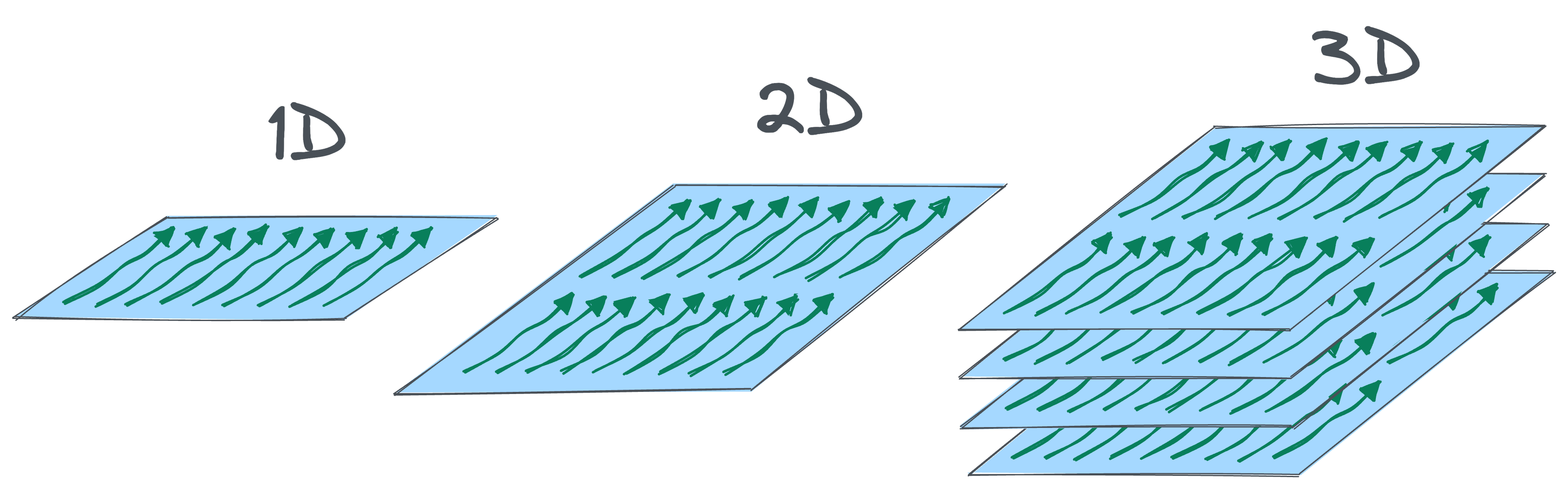
Consider the 1D case shown above, where Threads are arranged in a single dimension.
Furthermore, as there is a limit on the number of Threads a block can hold, we can have many blocks, which, for simplicity, may also arranged in a single dimension inside the entire grid:
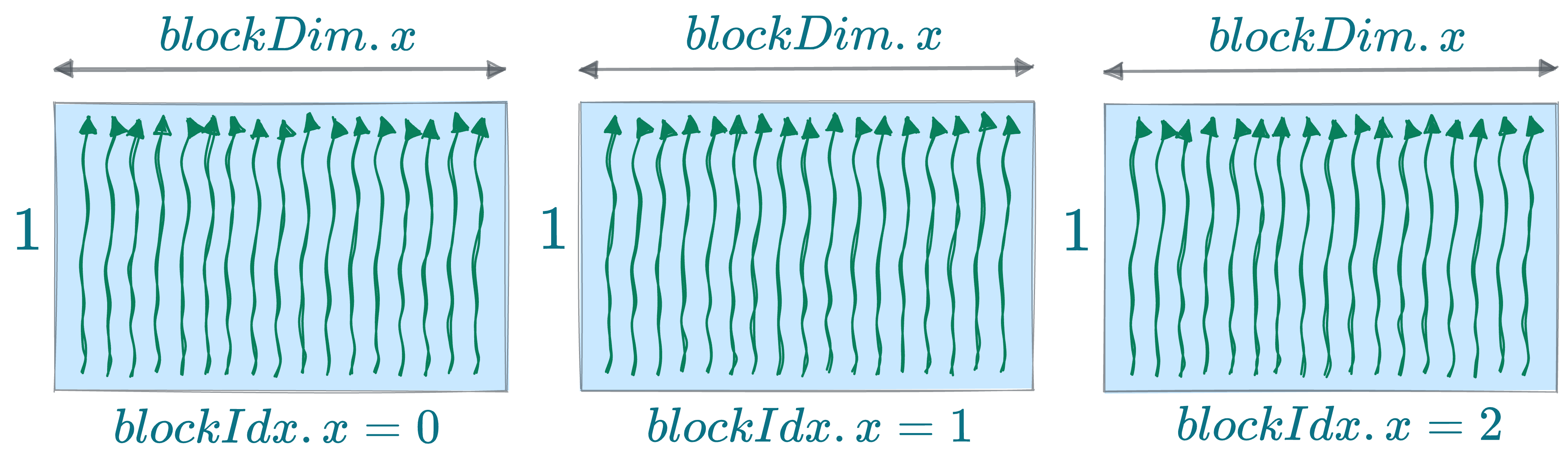
Here are the parameters associated with this configuration, which we shall reference later in the kernel function:
- Every block has a width variable of
blockDim.- We can obtain the width along the x-axis using
blockDim.xvariable. - We can obtain the width along the y-axis using
blockDim.yvariable (which will be1in the above case).
- We can obtain the width along the x-axis using