You Cannot Build Large Data Projects Until You Learn Data Version Control!
The underappreciated, yet critical, skill that most data scientists overlook.
Recap
In a recent deep dive into model deployment, we discussed the importance of version-controlling deployments in machine learning (ML) projects:
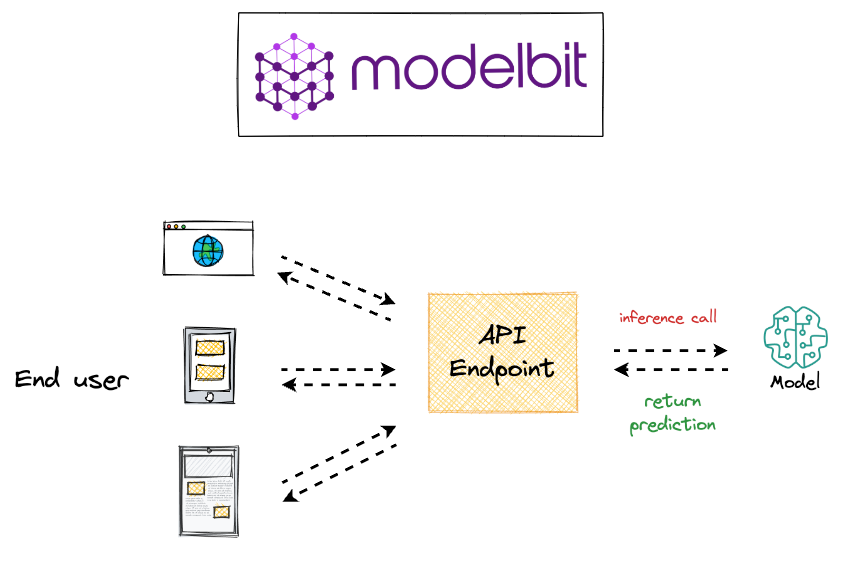
More specifically, we looked at techniques to version control:
- Our deployment code, and
- Our deployed model.
Moving on, we also looked at various advantages of version-controlling model deployments.
Let’s recap those.
Benefits of version control
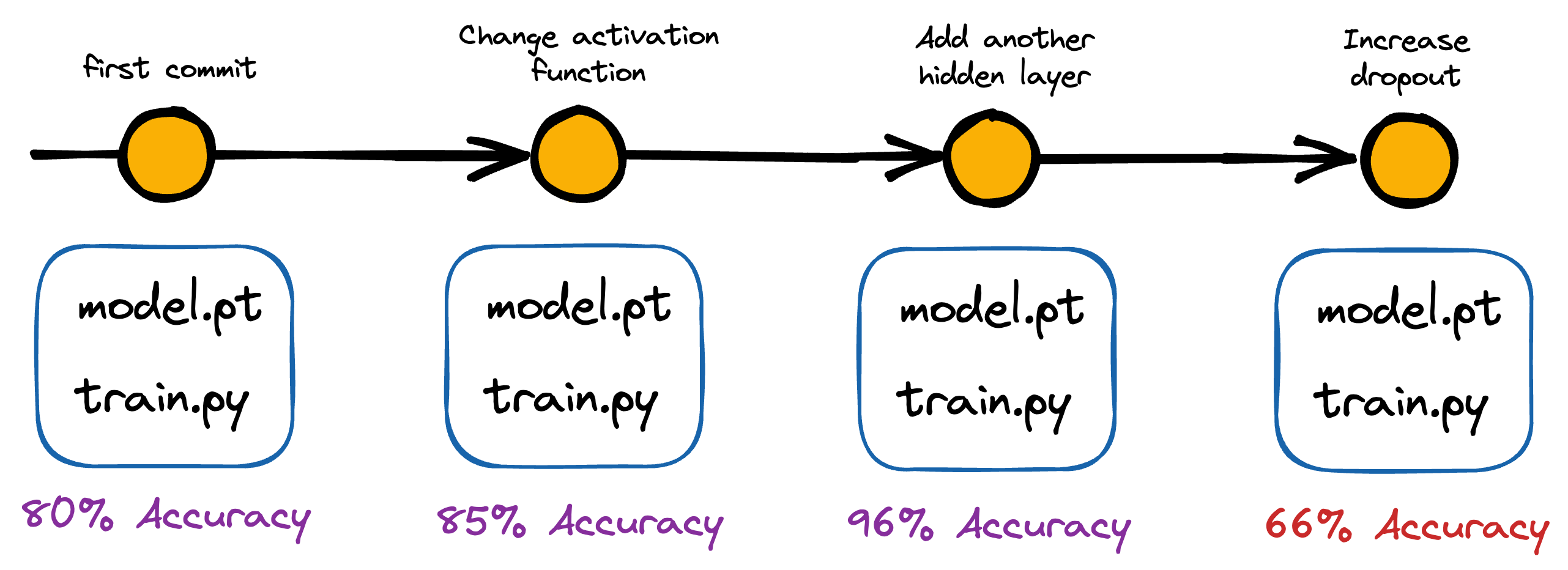
For instance, with version control, one can precisely identify what changed, when it changed, and who changed it — which is crucial information when trying to diagnose and fix issues that arise during the deployment process or if models start underperforming post-deployment.
Another advantage of version control is effective collaboration.
For instance, someone in the team might be working on identifying better features for the model, and someone else might be responsible for fine-tuning hyperparameters or optimizing the deployment infrastructure.
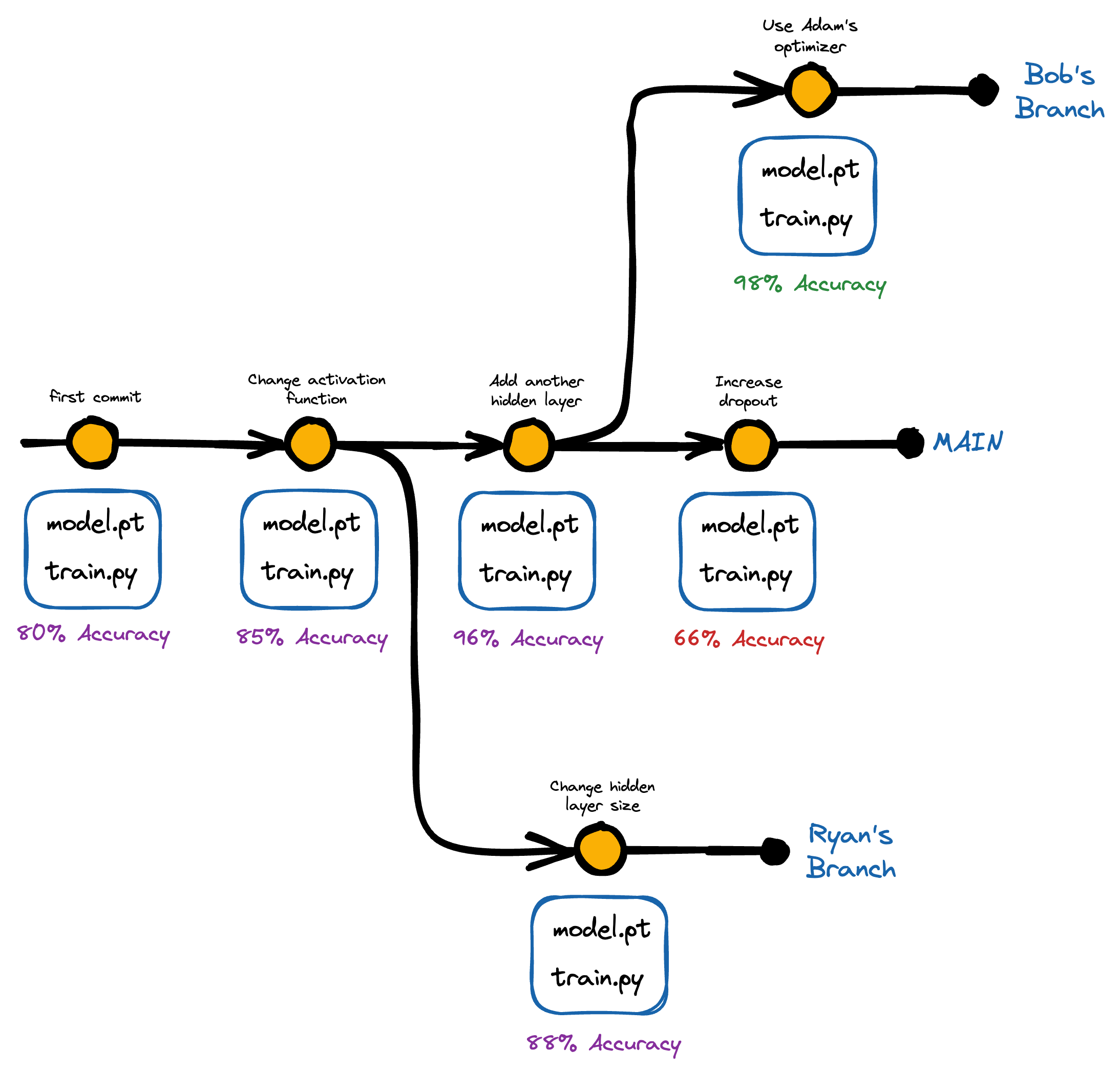
And it is well known that with version control, teams can work on the same codebase/data and improve the same models without interfering with each other’s work.
Moreover, one can easily track changes, review each other’s work, and resolve conflicts (if any).
Lastly, version control also helps in the reproducibility of an experiment.
It ensures that results can be replicated and validated by others, which improves the overall credibility of our work.
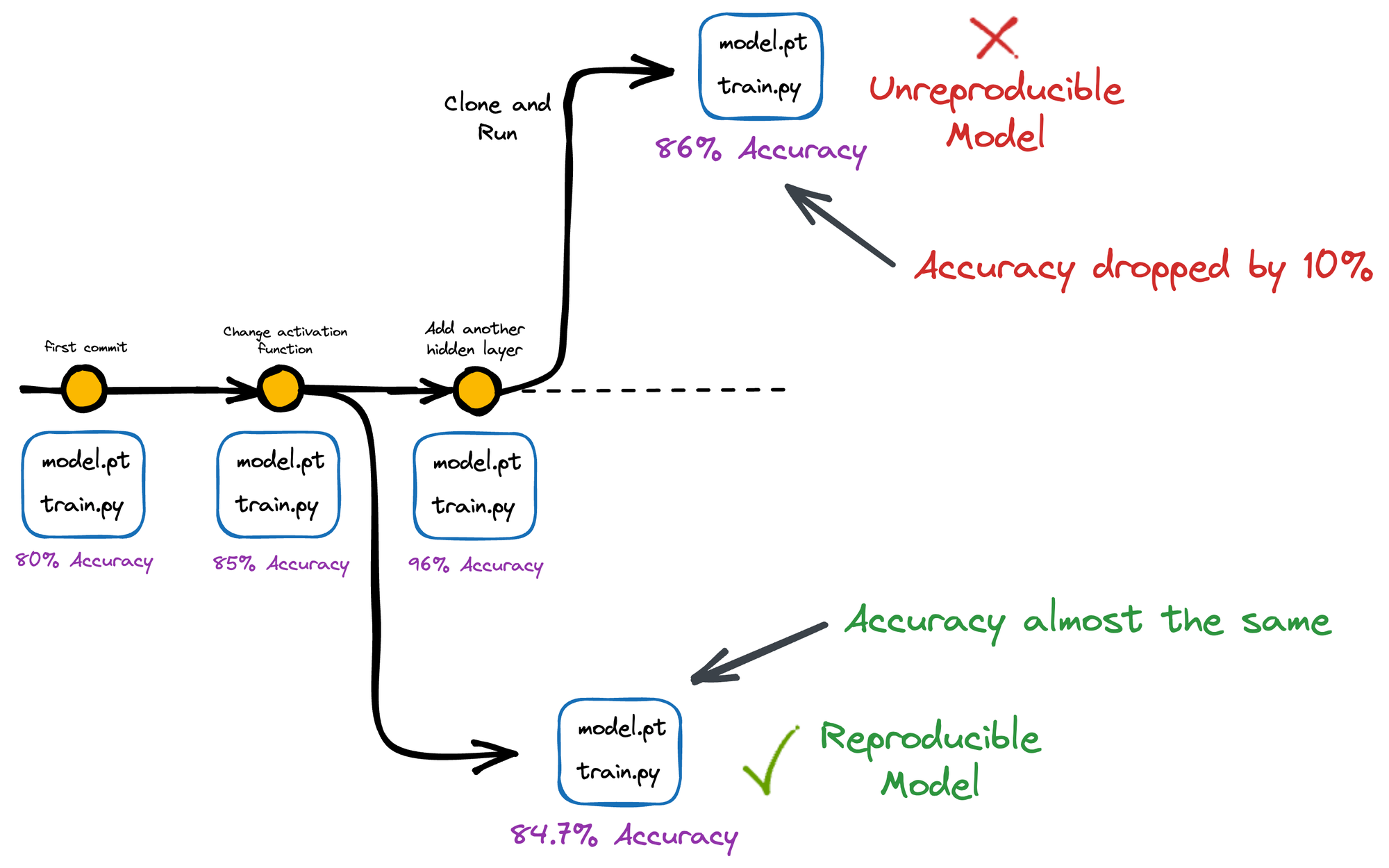
Version control allows us to track the exact code version and configurations used to produce a particular result, making it easier to reproduce results in the future.
This becomes especially useful for open-source data projects that many programmers may use.
HOWEVER!
Pillars of model reproducibility
Let me ask you something:
Purely from a reproducibility perspective, do you think model and code versioning are sufficient?
In other words, are these the only requirements to ensure model reproducibility?
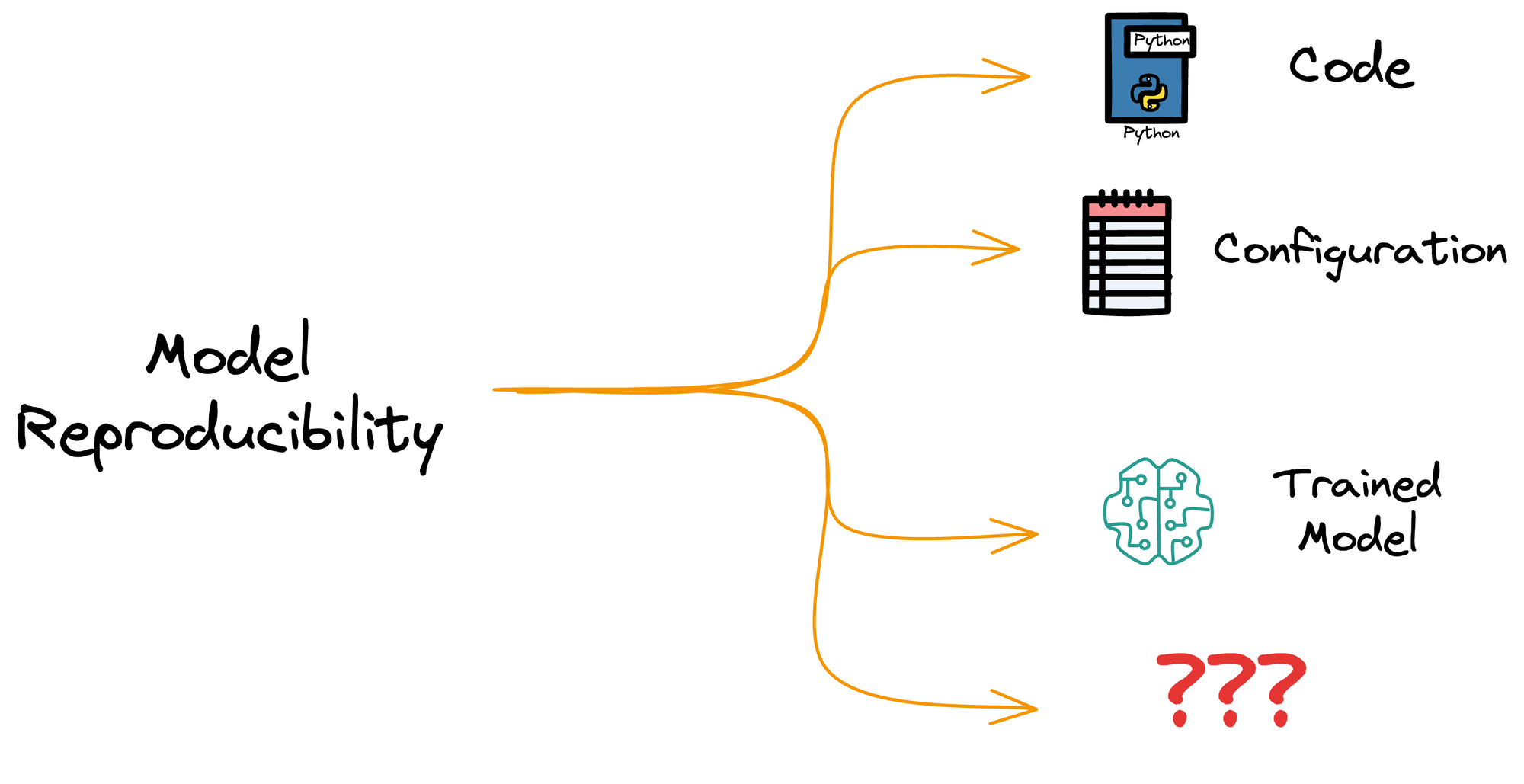
See, when we want to reproduce a model:
- First, we need the exact version of the code which was used to train the model.

- We have access to the code through code versioning.
- Next, we need the exact configuration the model was trained with:

- This may include the random seed used in the model, the learning rate, the optimizer, etc.
- Typically, configurations are a part of the code, so we know the configuration as well through code versioning.
- Finally, we need the trained model to compare its performance with the reproduced model.

- We have access to the model as well through model versioning.
But how would we train the model without having access to the exact dataset that was originally used?

In fact, across model updates, our data can largely vary as well.
Thus, it becomes important to track the exact version of the dataset that was used in a specific stage of model development and deployment.
This is precisely what data version control is all about.
Motivation for data version control
The motivation for maintaining a data version control system in place is quite intuitive and straightforward.
Typically, all real-world machine learning models are trained using large datasets.
Before training a model and even during its development, many transformations are regularly applied to the dataset.
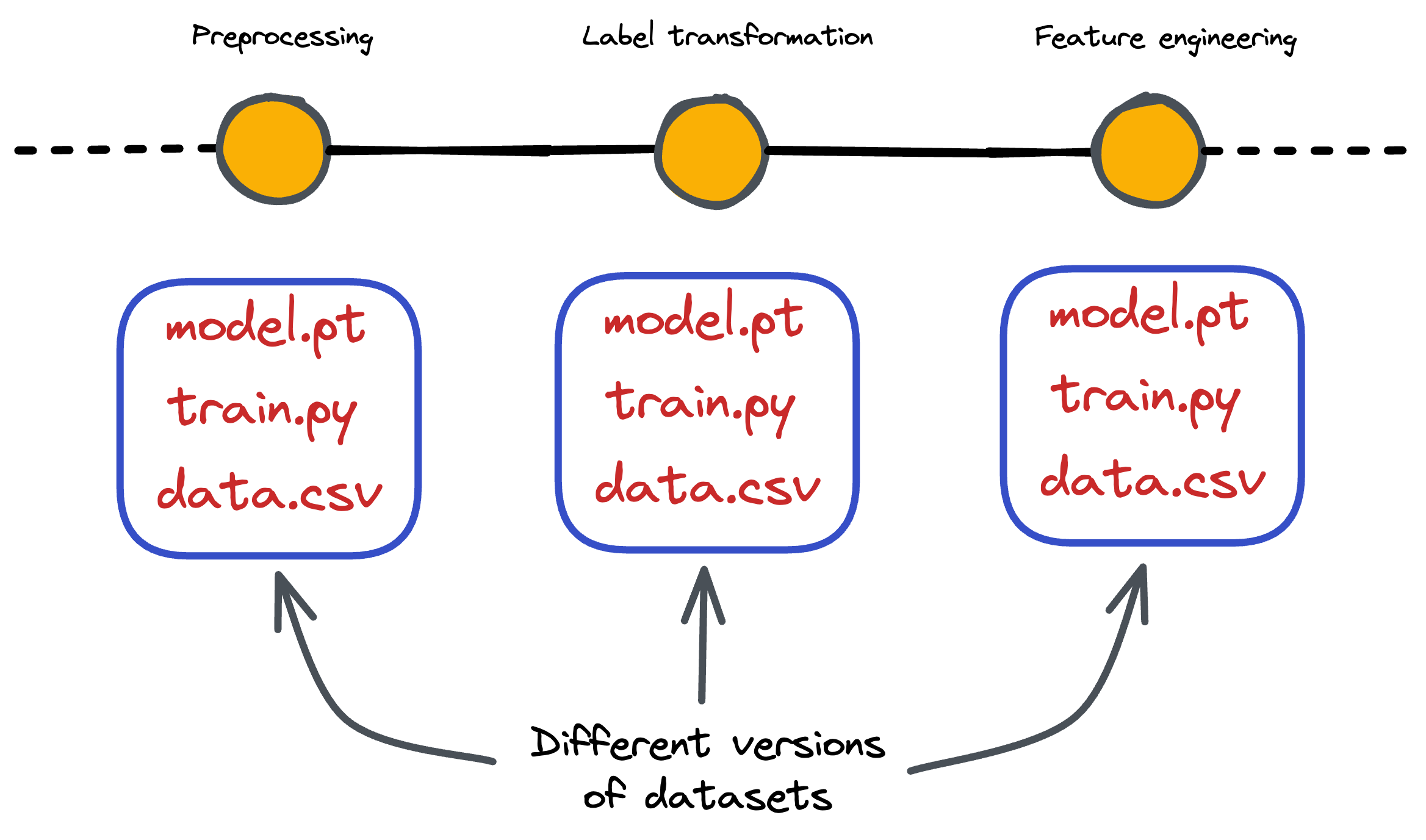
This may include:
- Preprocessing
- Transformation
- Feature engineering
- Tokenization, and many more.
As the number of model updates (or iterations) increases, it can get quite difficult to track which specific version of the dataset was used to train the machine learning model.
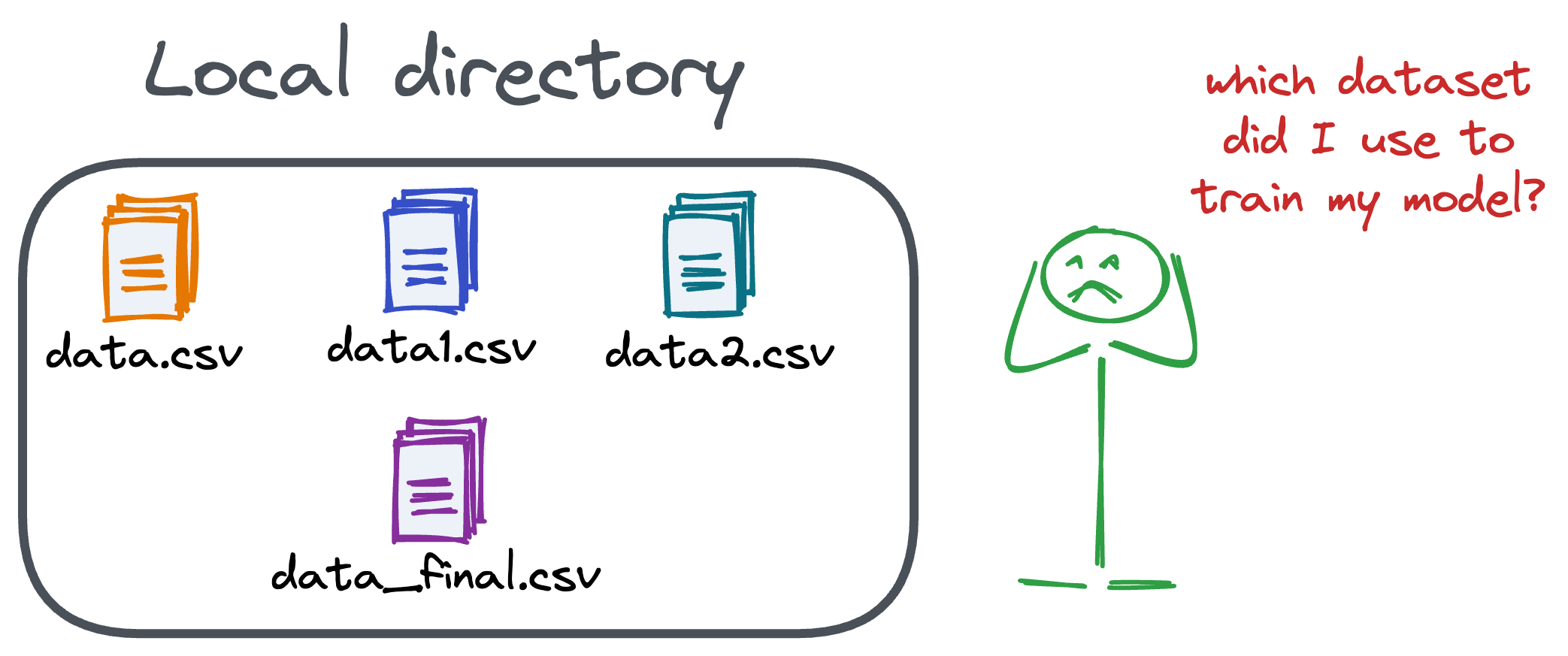
If that is clear, then the motivation for having a data version control system in place becomes quite intuitive and simple, as it addresses many data-specific challenges:
#1) Reproducibility
With a data version control system, we can precisely reproduce the same training dataset for any given version of our machine learning model.
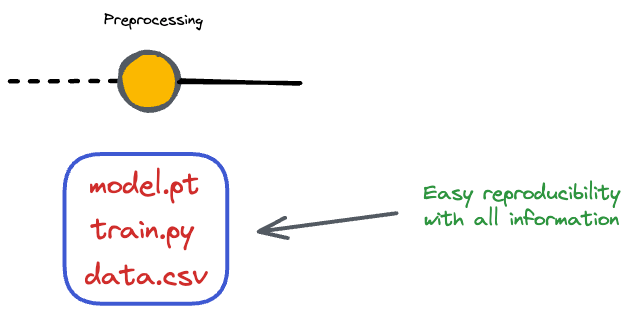
By tracking and linking each dataset version to a specific model version, we can easily recreate the exact conditions under which a model was trained, making it possible to replicate results.
#2) Traceability
Like codebase traceability, data version control enables traceability by documenting the history of dataset changes.
It offers a clear lineage of how the dataset has evolved over time, including information about who made changes, when those changes occurred, and the reasons behind those modifications.
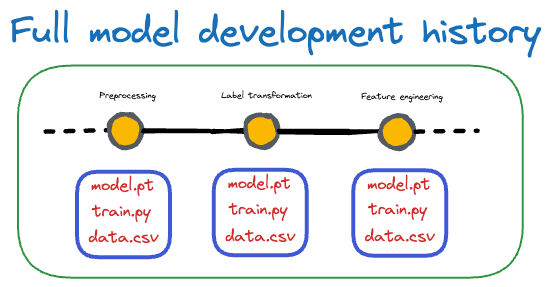
This traceability is crucial for understanding the data's quality and history, ensuring transparency and accountability in our ML pipeline.
#3) Collaboration and data sharing
In collaborative machine learning projects, team members need to work on the same data, apply transformations, and access shared dataset versions.
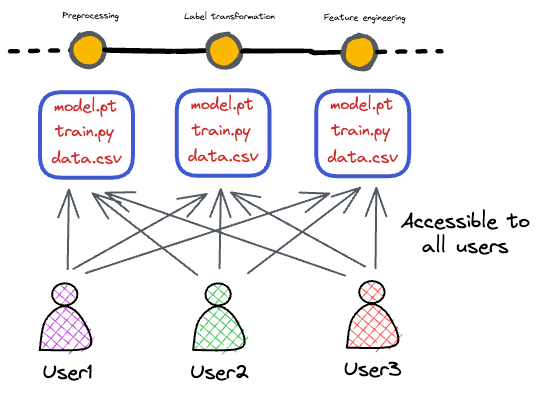
Data version control simplifies data sharing and collaboration by providing a centralized repository for datasets.
Team members can easily access and sync with the latest data versions, ensuring that everyone is on the same page.
#4) Efficiency
As we would see ahead in the practical demo, data version control systems help in optimizing storage and bandwidth usage by employing techniques such as:
- data deduplication
- data caching
This ensures that we do not waste resources on storing redundant copies of large datasets, making the storage and transfer of data more efficient.
#5) Data quality control
It’s common for datasets to undergo quality checks and transformations during their preparation.
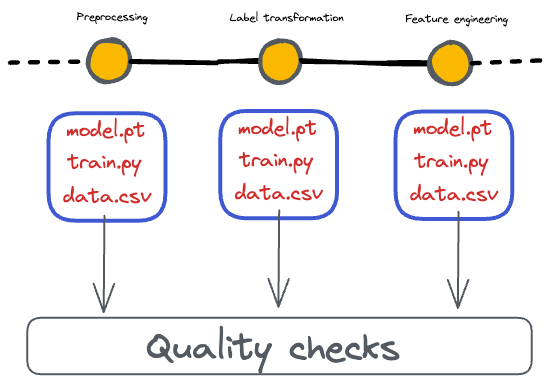
Data version control can help identify issues or discrepancies in the dataset as it evolves over time.
By comparing different dataset versions, we can spot unexpected changes and revert to previous versions if necessary.
#6) Data governance and compliance
Many industries and organizations have stringent data governance and compliance requirements.
Data version control supports these needs by providing a well-documented history of data changes, which can be crucial for audits and regulatory compliance.
#7) Easy rollback
In situations where a newer model version performs worse or encounters unexpected issues in production, having access to previous dataset versions allows for easy rollback to a more reliable dataset.
This can be a lifesaver in many situations.
Here, you might be wondering, why data rollback might be of any relevance to us when it’s the model that must be rolled back.
You are right.
But there are situations where data rollback is useful.
For instance, assume that your deployed machine learning model is a k-nearest neighbor (kNN) model.
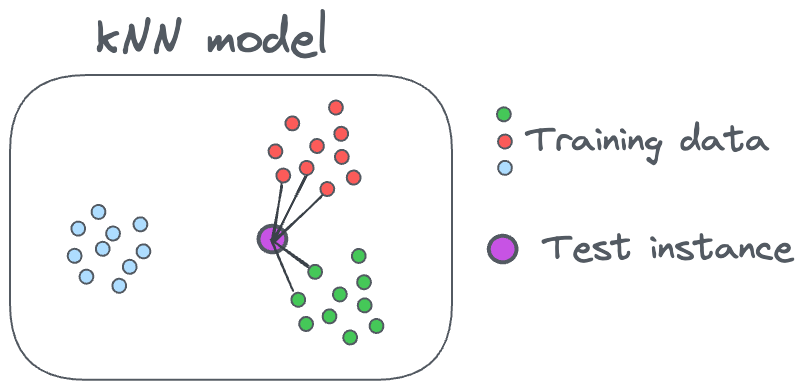
The thing is that we never train a kNN.
In fact, there are no explicitly trained weights in the case of a kNN. Instead, there’s only the training dataset that is used for inference purposes.
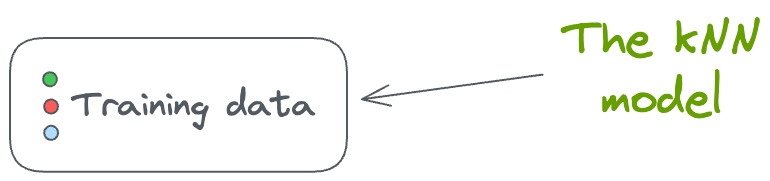
The model is effectively the training data, and predictions are made based on the similarity of new data points to the stored instances.
If anything goes wrong with this dataset during production, having a data version control system in place can help us quickly roll back to a previous reliable dataset.
What could go wrong, you may wonder?
- Maybe the data engineering team has stopped collecting a specific feature due to a compliance issue.
- Maybe there were some human errors, like accidental data deletions. This will make the kNN void.
- Maybe there was data corruption — Data files or records became corrupted due to a hardware failure, network issues, or software bugs. This will make the kNN void.
The benefit of data version control is that if anything goes wrong with this dataset during production, having a data version control system in place can help us quickly roll back to a previous reliable dataset.
In the meantime, we can work in the development environment to investigate the issue and decide on the next steps.
Considerations for Data Version Control
Now that we have understood the motivation for having a data version control system, let’s look at some considerations for a data version control system.
Why is Git not an ideal solution for data version control?
We know that Git can manage the versioning of any type of file in a Git repository. These can be code, models, datasets, config files, etc.
These can be hosted on remote repositories like GitHub with a few commands.
So for someone using GitHub to host codebases, they might be tempted to extend the same to version datasets:
- They may manage different versions of the dataset with Git locally.
- They may host the repository on GitHub (or other services) for collaboration and stuff.
The rationale behind this idea could be that Git can do data version control as elegantly as version control codebases.
Sounds like a fair thing to do, right?
Well, it’s not!
Recall our objective again.
In the previous section, we discussed using data version control for production systems.
As production systems are much more complex and involve collaboration, the codebase is typically hosted in a remote repository, like on GitHub.
But the problem is that Github repositories (or other similar hosting tools like GitLab) always have an upper limit on the file size we can push to these remote repositories.
In other words, GitHub is only designed for lightweight code scripts. However, it is not particularly well-suited for version controlling large datasets that exceed just a few MBs in size.
Typically, in machine learning projects, the dataset size can be in the order of GBs. Thus, it is impossible to execute data version control with Github.
In fact, we can also verify this experimentally.
Consider we have the following project directory:
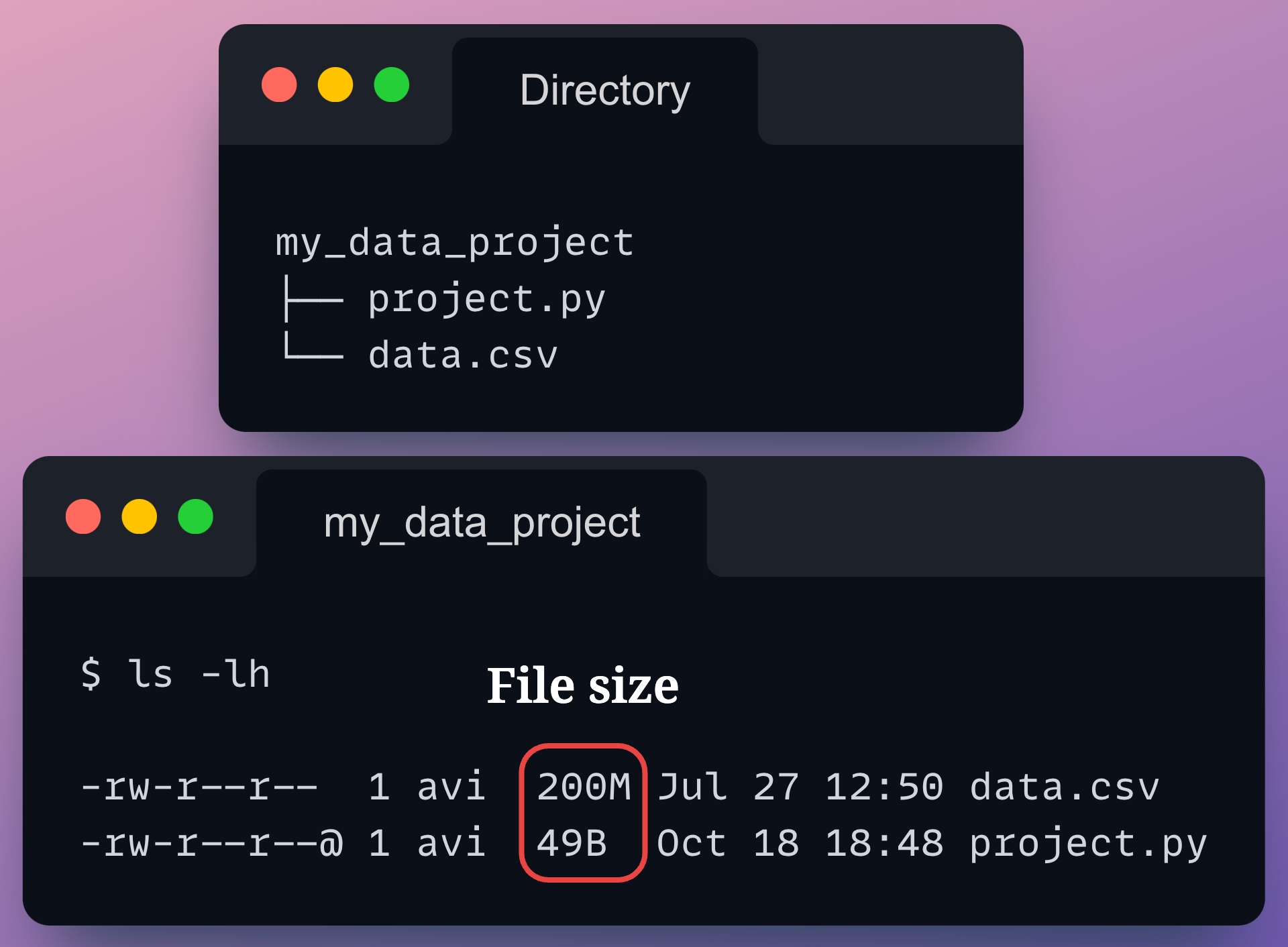
As shown above, the data.csv file takes about 200 MBs of space.
Let’s create a local Git repository first before pushing the files to a remote repository hosted on GitHub.
To create a local Git repository:
- First, we shall initialize a git repository with
git init. - Next, we will add the files to the staging area with
git add. - Finally, we will use
git committo commit to the local repo.
This is demonstrated below:
project.py file as well.All good so far. The changes have been committed successfully to the local git repo.
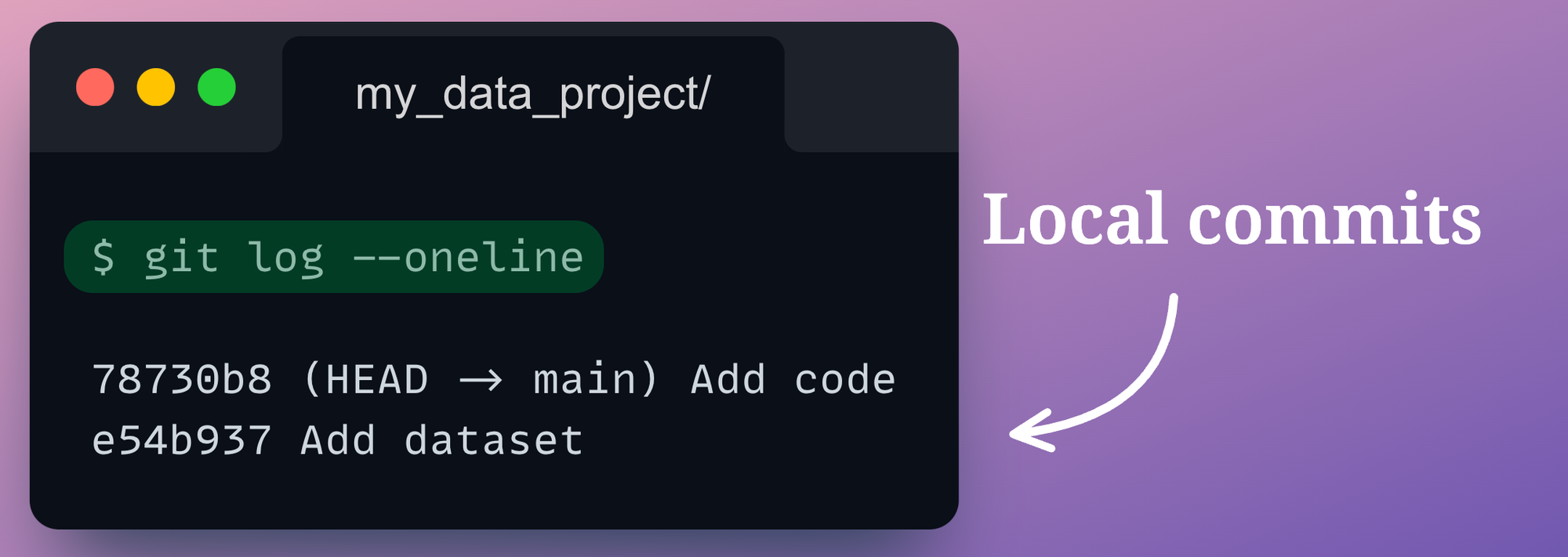
We can verify this by reviewing the commit history of the local git repo with git log command.
Next, let’s try to push these changes to a remote GitHub repository. To do this, we have created a new repository on GitHub – dvc_project.
Before pushing the files to the remote repository, let’s also verify whether the local git repository has any uncommitted changes using the git status command:
git status command is used to check the status of your git repository. It shows the state of your working directory and helps you see all the files that are untracked by Git, staged, or unstaged,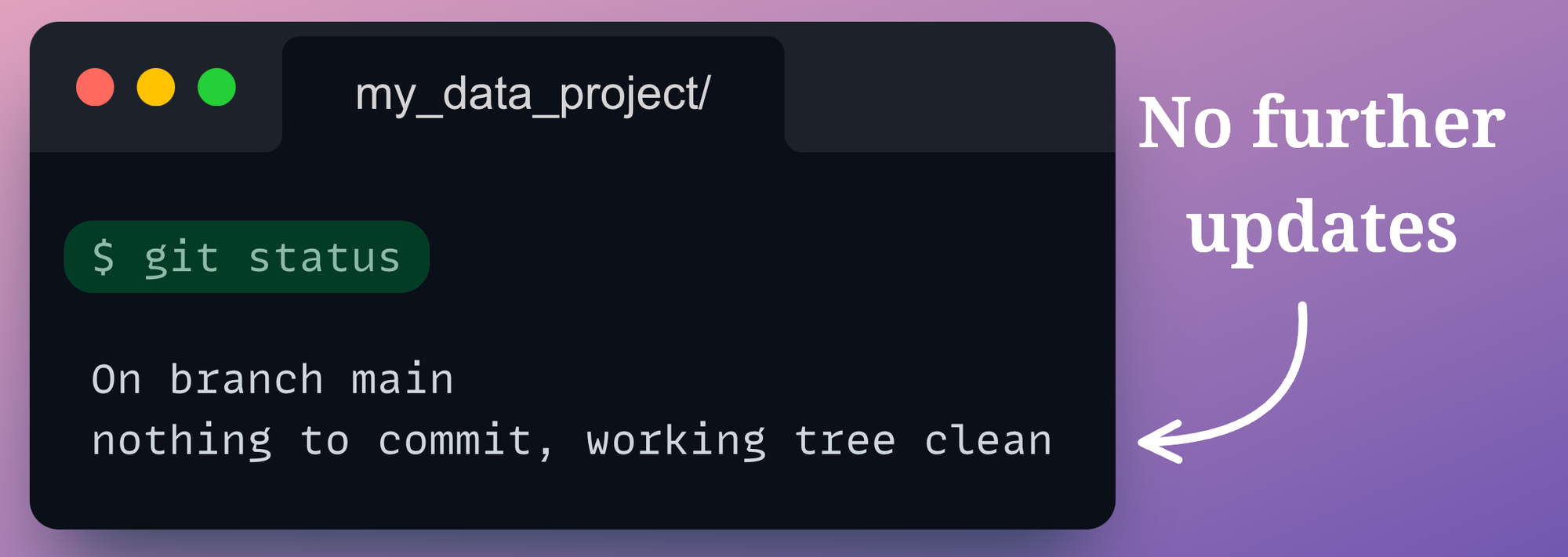
The output says that the working tree is clean.
Thus, we can commit these changes to the remote GitHub repository created above as follows:
As discussed earlier, Github repositories always have an upper limit on the file size we can push to these remote repositories. This is precisely what the above error message says.
For this reason, we can only use the typical GitHub repositories for data version control as long as the dataset size is below a few MBs, which is rarely the case.
Thus, we need a better version control system, especially for large files, that does not have the above limitations.
Ideal requirements for a data version control system
An ideal data version control system must fulfill the following requirements:
- It should allow us to track all data changes like Git does with files.
- As soon as we make any change (adding, deleting, or altering files) in a git-initialized repository, git can always identify those changes.
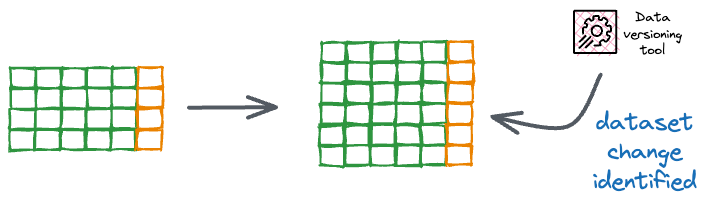
- The same should be true for our data version control system.
- It should not be limited to tracking datasets.
- See, as we discussed above, GitHub sets an upper limit on the file size we can push to these remote repositories.
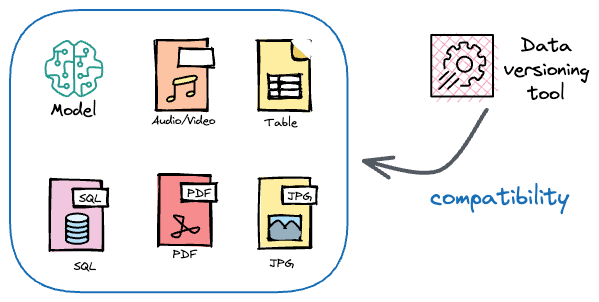
- But large files may not not necessarily be limited to datasets. In fact, models can also be large, and pushing model pickles to GitHub repositories can be difficult.
- It must have support for branching and committing.
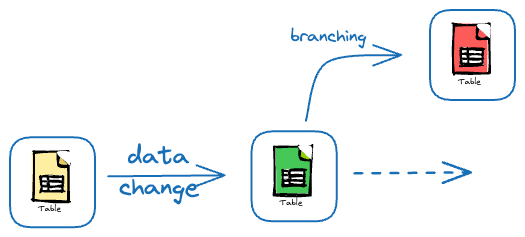
- Like Git, this data version control system must provide support for creating branches and commits.
- Its syntax must be similar to Git.
- Of course, this is optional but good to have.
- Having a data version control system that has a similar syntax to git can simplify its learning curve.
- It must be compatible with Git.
- In any data-driven project, data, code, and model always work together.
- After using the data version control system, it must not happen that we are tracking code with Git and then managing models/datasets with an entirely non-compatible tool.
- They must work seamlessly integrated to avoid any unnecessary friction.
- It must have collaborative functionalities like Git
- Like git makes it extremely simple for teams to collaborate and work together by sharing their code, the data version control must also promote collaboration.
So what can we do here?