PyTorch Models Are Not Deployment-Friendly! Supercharge Them With TorchScript.
Eliminating the dependence of PyTorch models on Python.
Introduction
In an earlier deep dive on model compression techniques (linked below), we understood various ways to reduce the model size, which is extremely useful for optimizing inference and deployment processes and improving operational metrics.
This is important because when it comes to deploying ML models in production (or user-facing) systems, the focus shifts from raw accuracy to considerations such as efficiency, speed, and resource consumption.
Thus, in most cases, when we deploy any model to production, the specific model that gets shipped to production is NOT solely determined based on performance.
Instead, we must consider several operational metrics that are not ML-related and typically, they are not considered during the prototyping phase of the model.
These include factors like:
- Inference latency: The time it takes for a model to process a single input and generate a prediction.
- Throughput: The number of inference requests a model can handle in a given time period.
- Model size: The amount of memory a model occupies when loaded for inference purposes.
- and more.
In that article, we talked about four techniques that help us reduce model size while almost preserving the model’s accuracy:
They attempt to strike a balance between model size and accuracy, making it relatively easier to deploy models in user-facing products.
What’s more, as the models are relatively quite smaller now, one can expect much faster inference runtime. This is desired because we can never expect end users to wait for, say, a minute for the model to run and generate predictions.
Now, even if we have fairly compressed the model, there’s one more caveat that still exists, which can affect the model’s performance in production systems.
Let’s understand this in more detail.
Standard PyTorch design
PyTorch is the go-to choice for researchers and practitioners for building deep learning models due to its flexibility, intuitive Pythonic API design, and ease of use.
It takes a programmer just three steps to create a deep learning model in PyTorch:
- First, we define a model class inherited from PyTorch’s
nn.Moduleclass

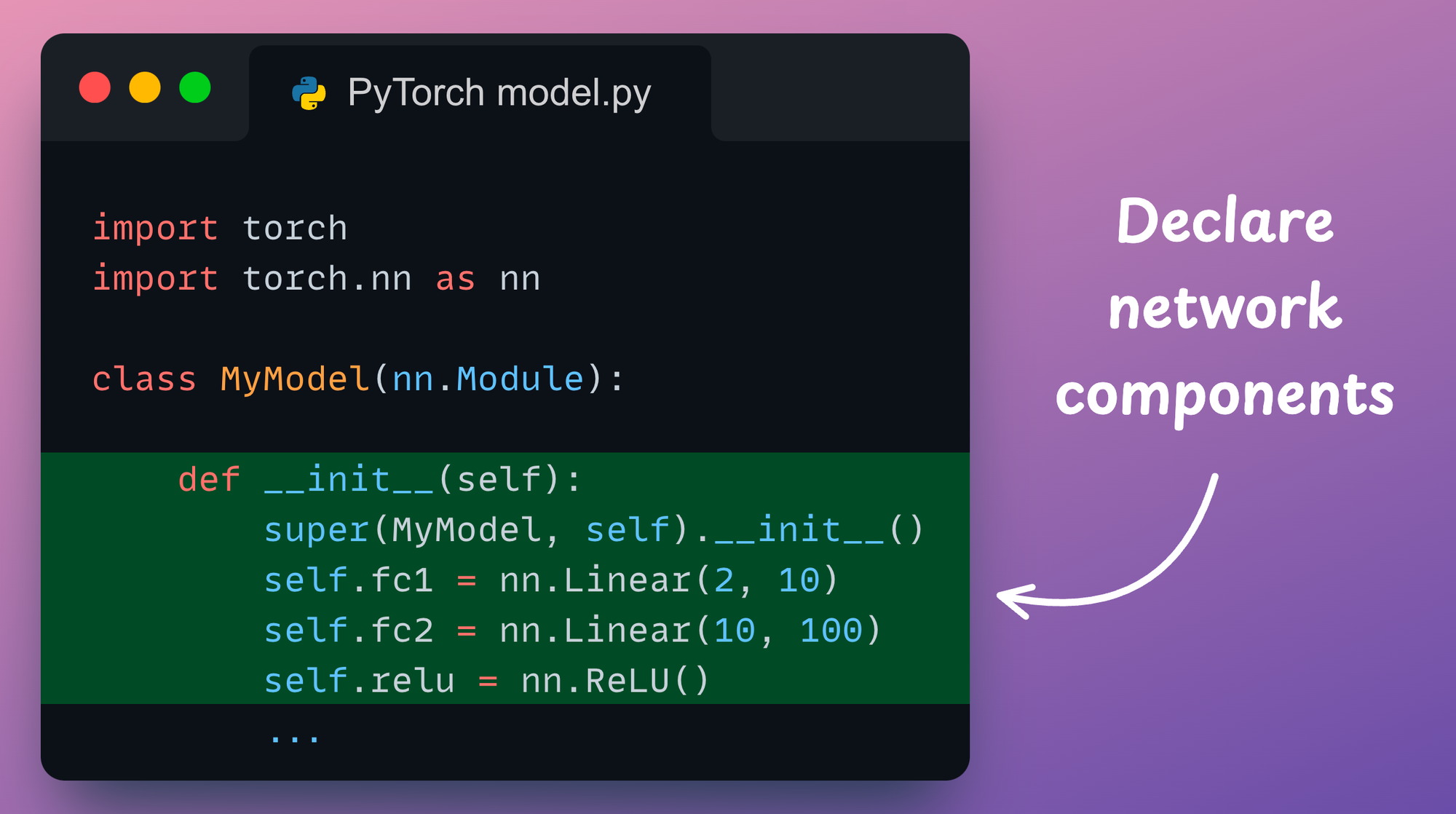
- Moving on, we declare all the network components (layers, dropout, batch norm, etc.) in the
__init__()method:
- Finally, we define the forward pass of the neural network in the
forward()method:
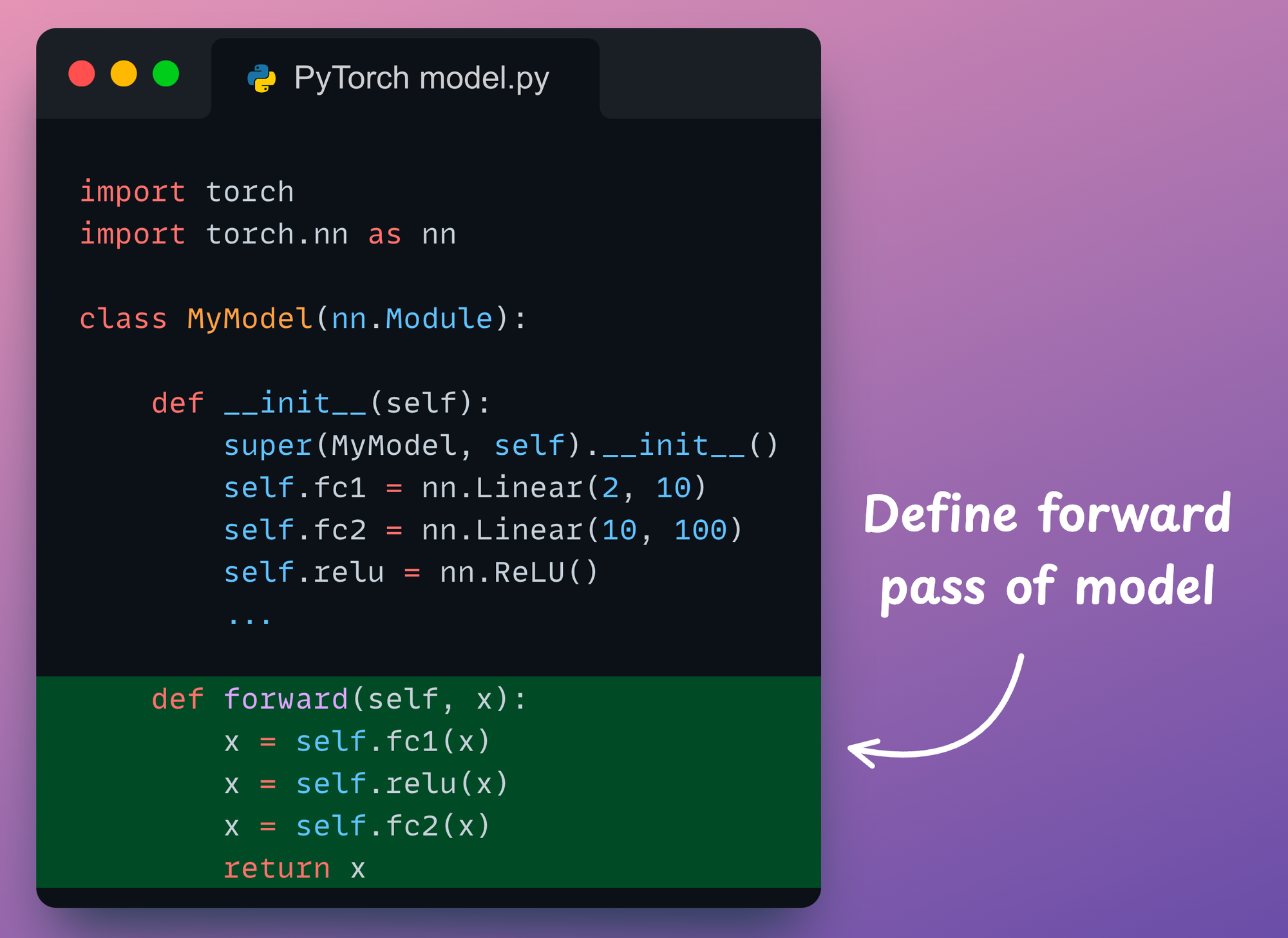
That’s it!
Issues with PyTorch
As we saw above, defining the network was so simple and elegant, wasn’t it?
Once we have defined the network, one can proceed with training the model by declaring the optimizer, loss function, etc., without having to define the backward pass explicitly.
However, when it comes to deploying these models in production systems, PyTorch's standard and well-adopted design encounters certain limitations, specific to scale and performance.
Let’s understand!
PyTorch limitations and typical production system requirements
One significant constraint of PyTorch is its predominant reliance on Python.

While Python offers simplicity, versatility, and readability, it is well known for being relatively slower compared to languages like C++ or Java.
More technically speaking, the Python-centric nature of PyTorch brings concerns related to the Global Interpreter Lock (GIL), a mechanism in CPython (the default Python interpreter) that hinders true parallelism in multi-threaded applications.
This limitation poses challenges in scenarios where low-latency and high-throughput requirements are crucial, such as real-time applications and services.
In fact, typical production systems demand model interoperability across various frameworks and systems.
It's possible that the server we intend to deploy our model on might be leveraging any other language except Python, like C++, Java, and more.
Thus, the models we build MUST BE portable to various environments which are designed to handle concurrent requests at scale.

However, the Python-centric nature of PyTorch can limit its integration with systems or platforms that require interoperability with languages beyond Python.
In other words, in scenarios where deployment involves a diverse technology stack, this restriction can become a hindrance.
This limitation can impact the model's ability to efficiently utilize hardware resources, further influencing factors like inference latency and throughput, which are immensely critical in business applications.
Historical PyTorch design
Historically, all PyTorch models were tightly coupled with the Python run-time.
This design choice reflected the framework's emphasis on dynamic computation graphs and ease of use for researchers and developers working on experimental projects.
More specifically, PyTorch's dynamic nature allowed for intuitive model building, easy debugging, and seamless integration with Python's scientific computing ecosystem.
This is also called the eager mode of PyTorch, which, as the name suggests, was specifically built for faster prototyping, training, and experimenting.
However, as the demand for deploying PyTorch models in production environments grew, the limitations of this design became more apparent.
The Python-centric nature of PyTorch, while advantageous during development, introduced challenges for production deployments where performance, scalability, and interoperability were paramount.
Of course, PyTorch inherently leveraged all sources of optimizations it possibly could like parallelism, integrating hardware accelerators, and more.
Nonetheless, its over-dependence on Python still left ample room for improvement, especially in scenarios demanding efficient deployment and execution of deep learning models at scale.
Of course, one solution might be to use entirely different frameworks for building deep learning models, like PyTorch, and then replicating the obtained model to another environment-agnostic framework.

However, this approach of building models in one framework and then replicating them in another environment-agnostic framework introduces its own set of challenges and complexities.
First and foremost, it requires expertise in both frameworks, increasing the learning curve for developers and potentially slowing down the development process.
In fact, no matter how much we criticize Python for its slowness, every developer loves the Pythonic experience and its flexibility.
Moreover, translating models between frameworks may not always be straightforward. Each deep learning framework has its own unique syntax, conventions, and quirks, making the migration of models a non-trivial task.

The differences in how frameworks handle operations, memory management, and optimization techniques can lead to subtle discrepancies in the behavior of the model, potentially affecting its performance and accuracy.
In fact, any updates to the developed model would have to be extended again to yet another framework, creating redundancy and resulting in a loss of productivity.
In other words, maintaining consistency across different frameworks also becomes an ongoing challenge.

As models evolve and updates are made, ensuring that the replicated version in the environment-agnostic framework stays in sync with the original PyTorch model becomes a manual and error-prone process.
To address these limitations, PyTorch developed the script mode, which is specifically designed for production use cases.
PyTorch’s script mode has two components: