LLMs
4 Strategies for Multi-GPU Training
...explained visually.

Avi Chawla
...explained visually.

TODAY'S ISSUE
By default, deep learning models only utilize a single GPU for training, even if multiple GPUs are available.
An ideal way to train models is to distribute the training workload across multiple GPUs.
The graphic below depicts four common strategies for multi-GPU training:
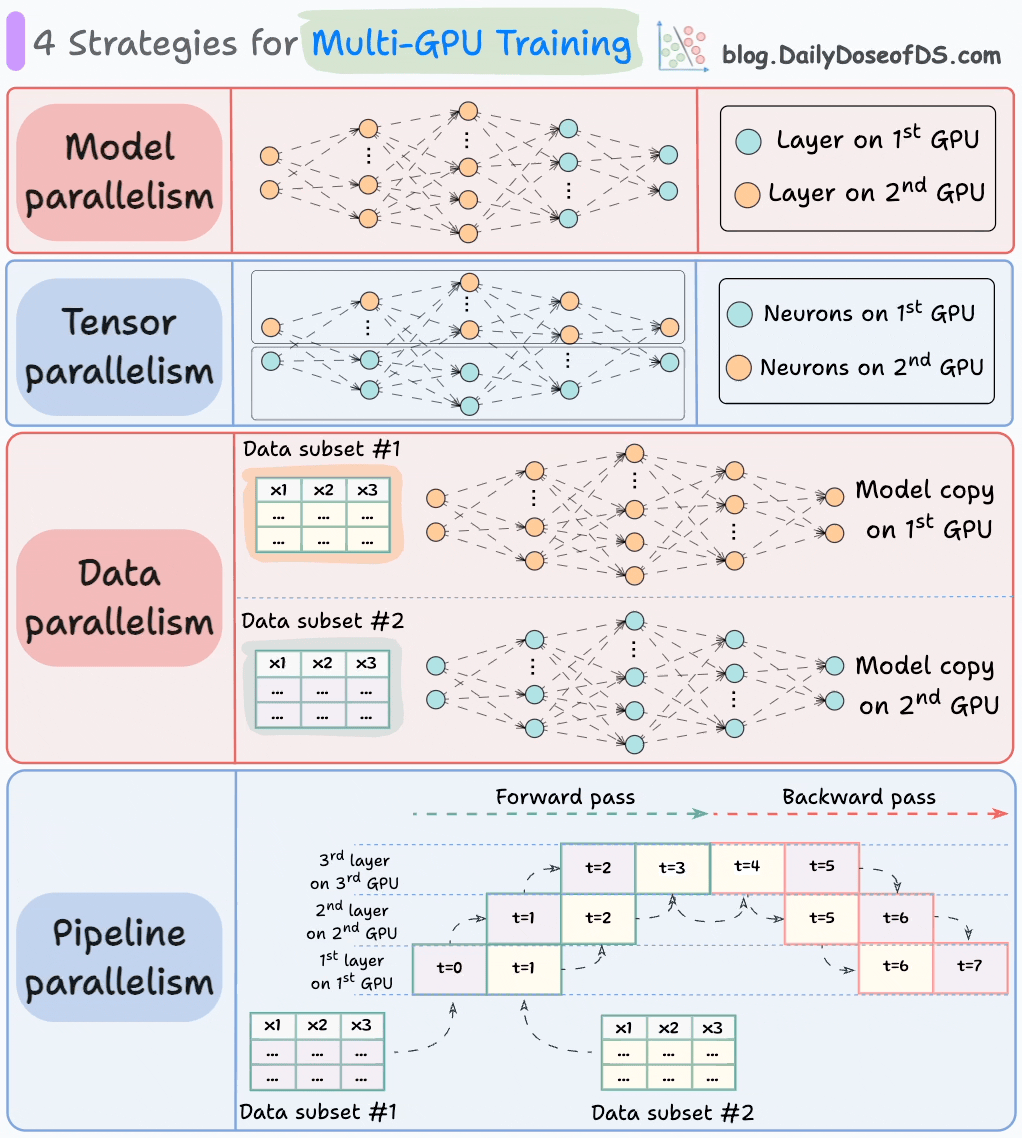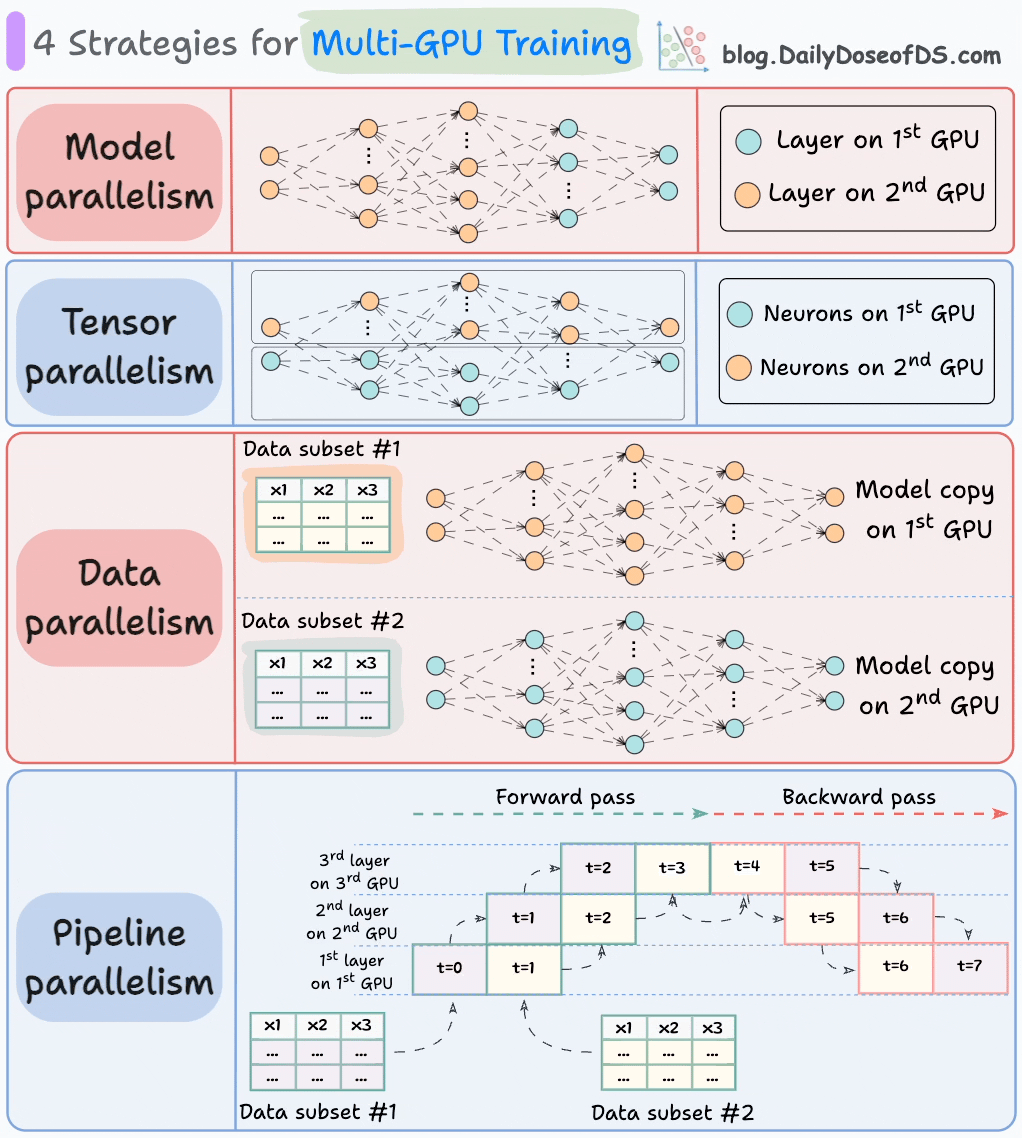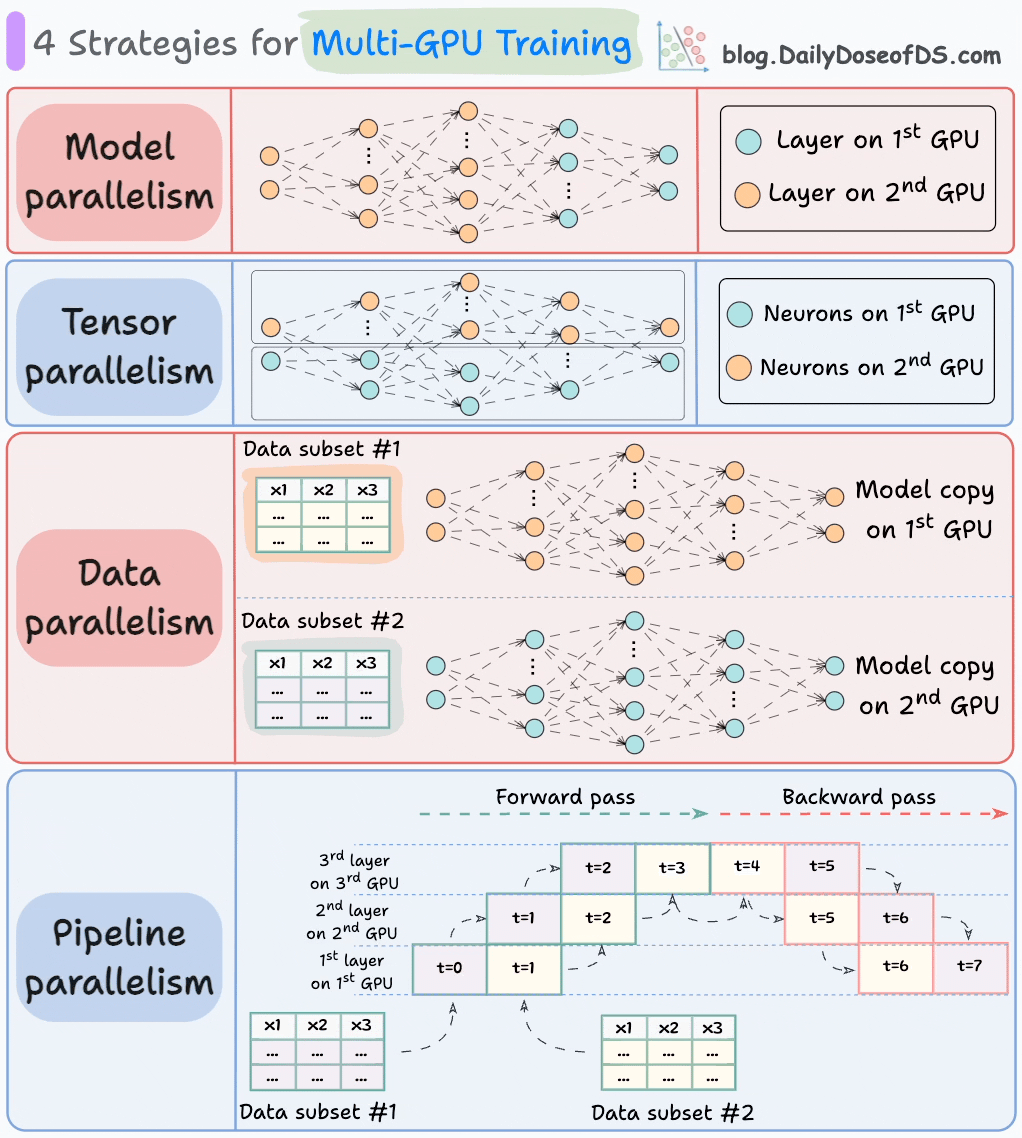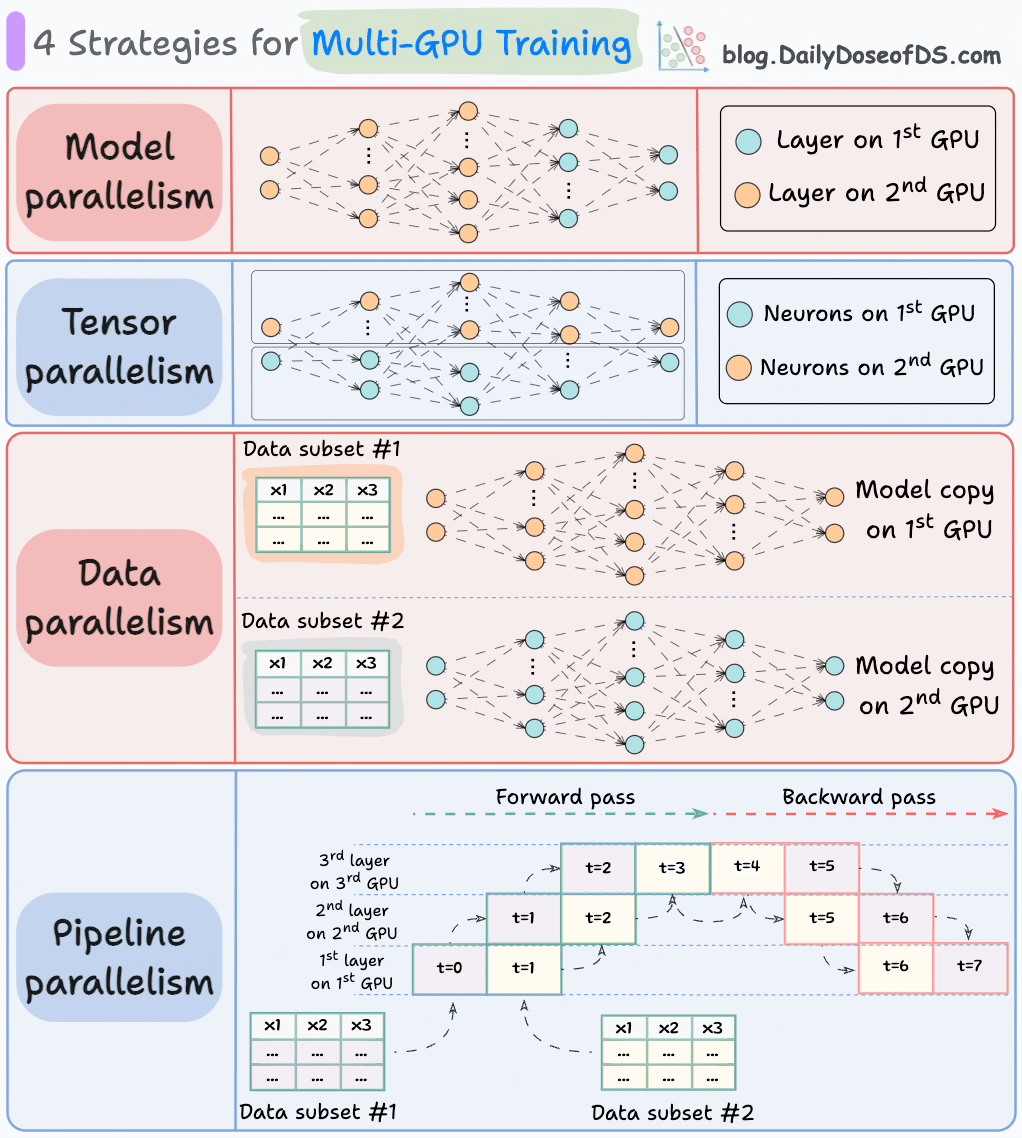
We covered multi-GPU training in detail with implementation here: A Beginner-friendly Guide to Multi-GPU Model Training.
Let’s discuss these four strategies below:


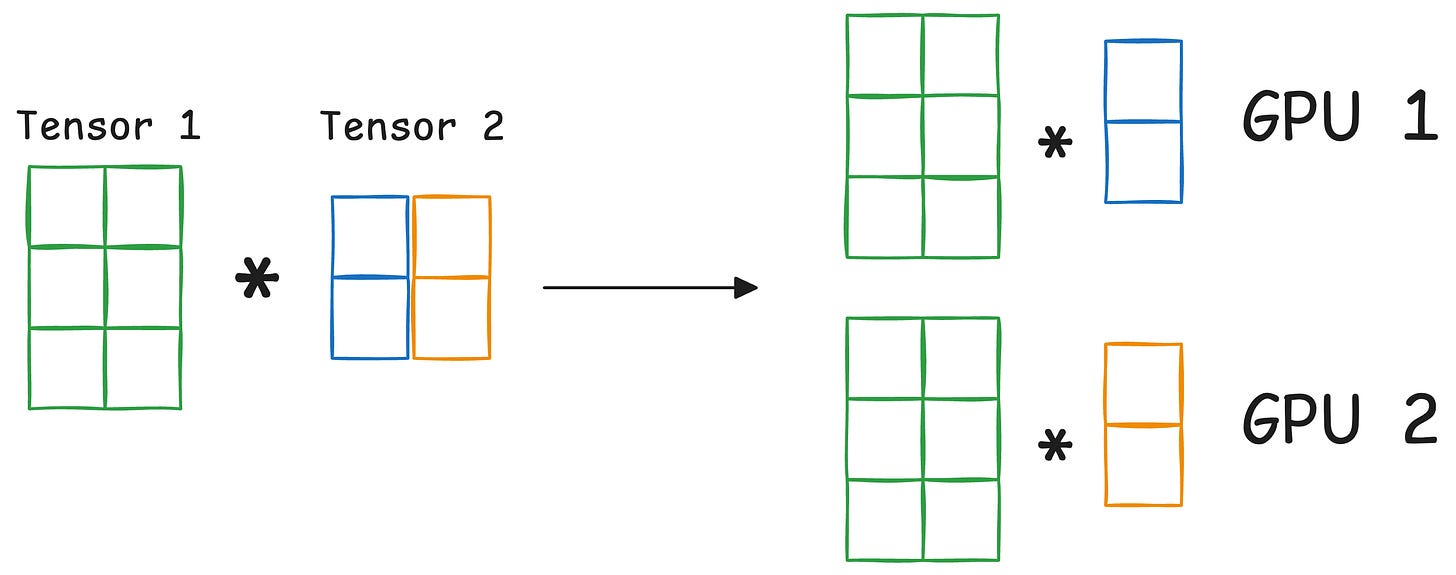
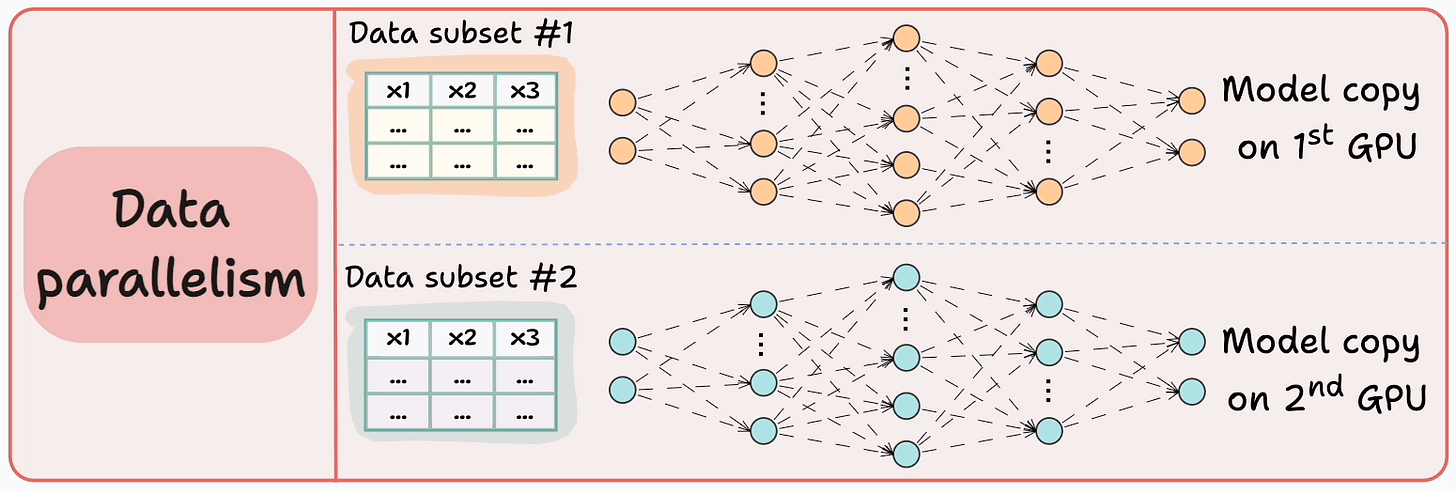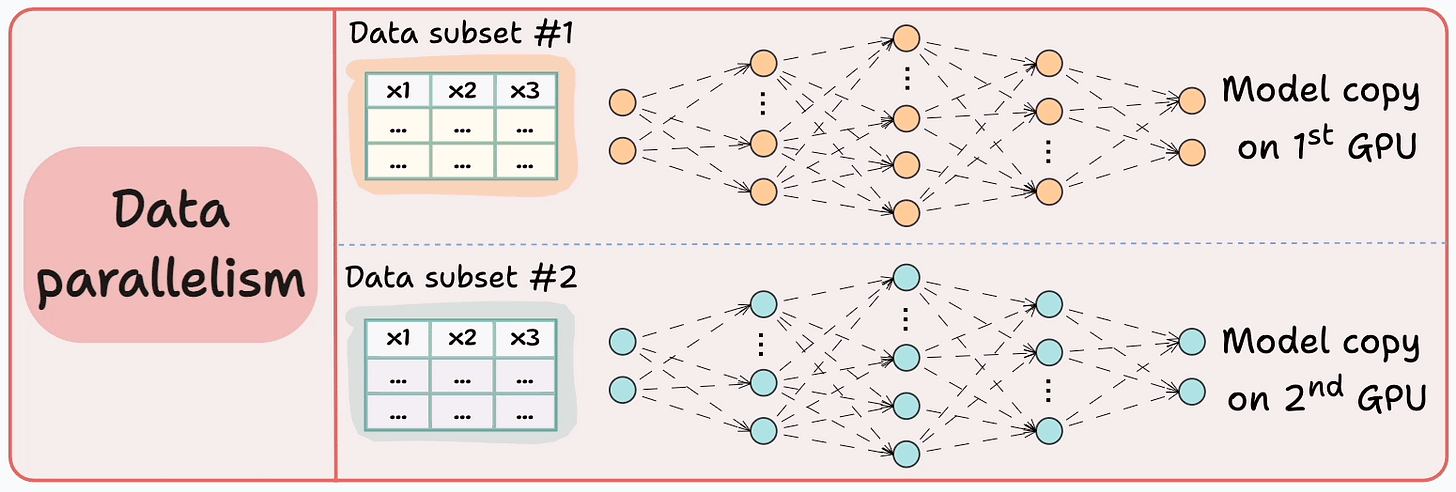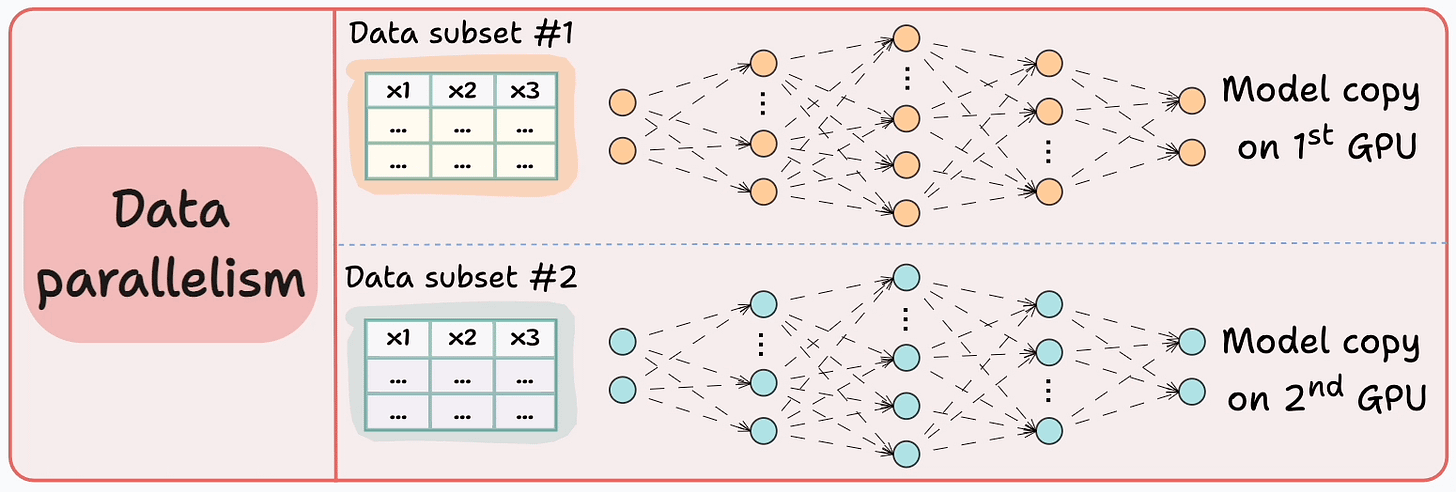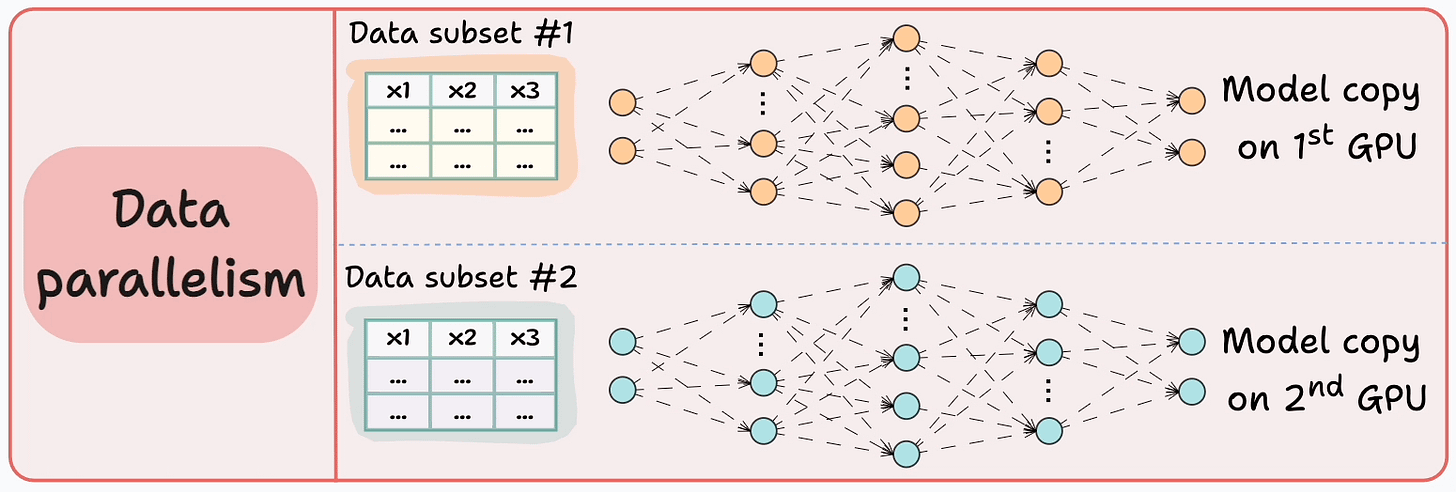
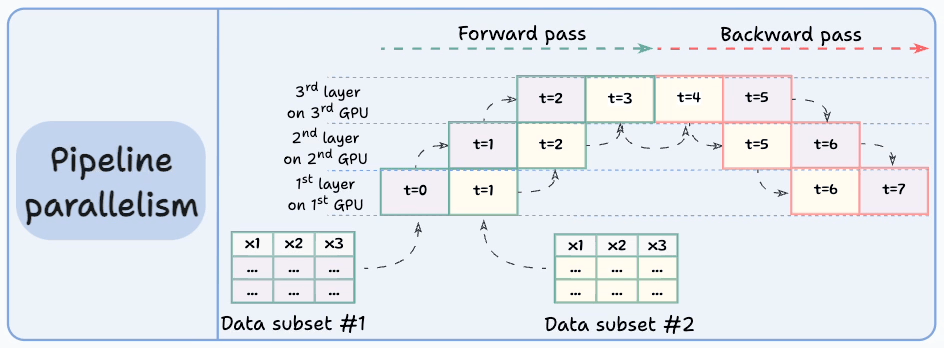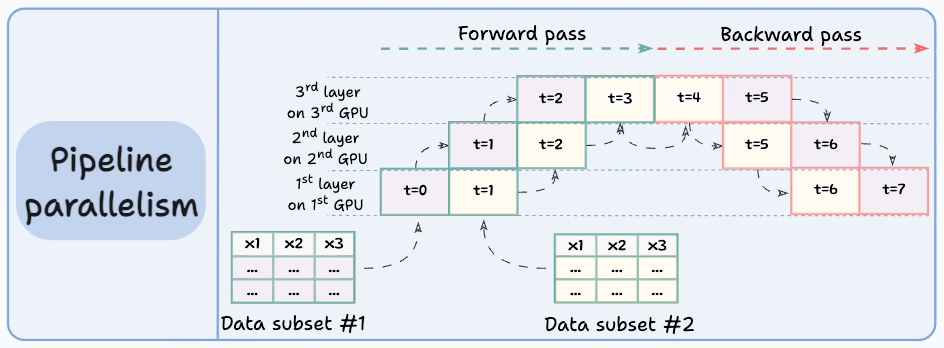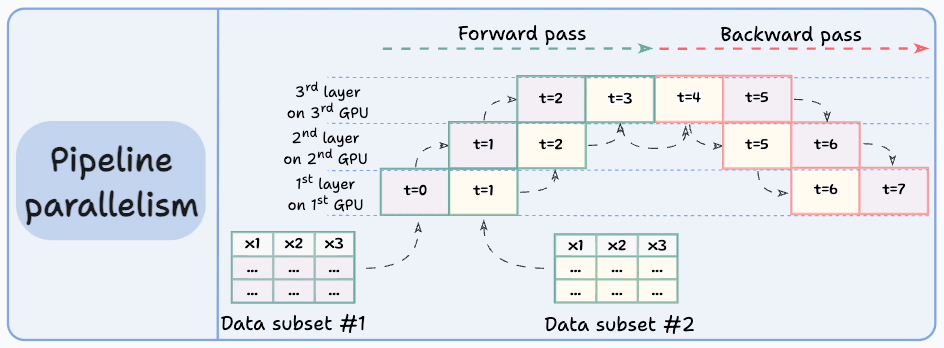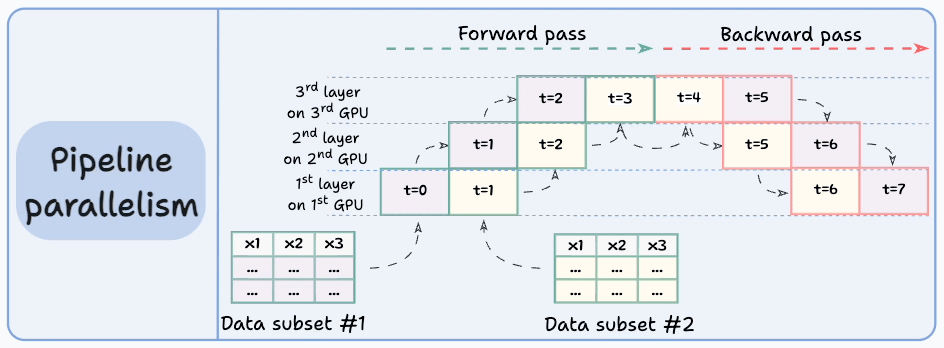

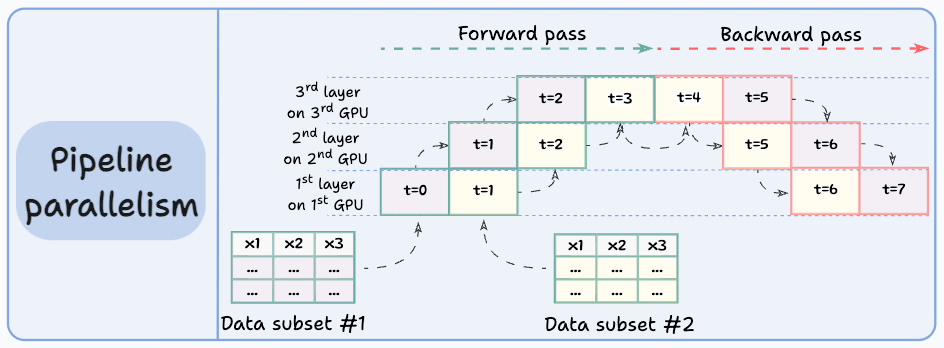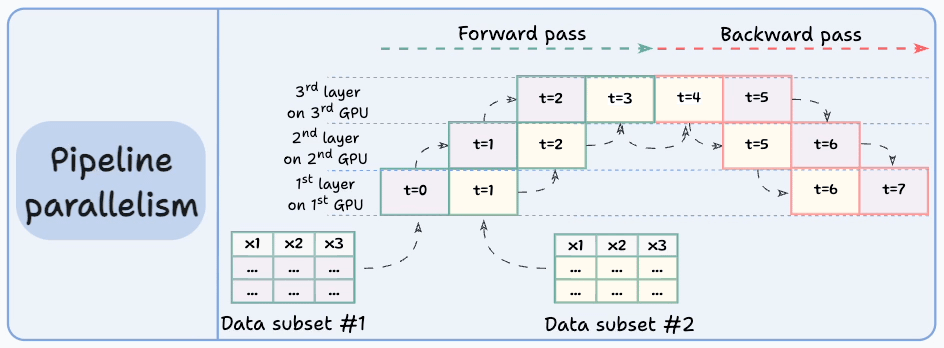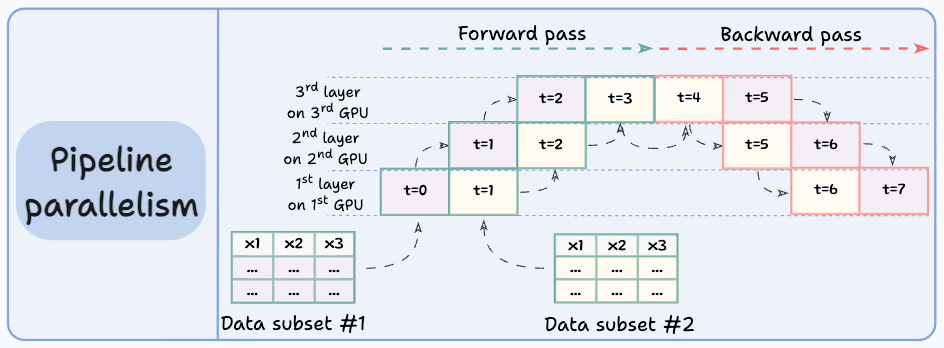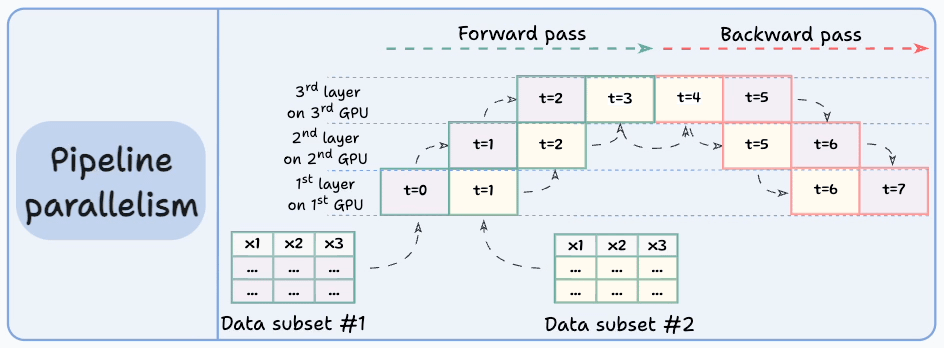
Those were four common strategies for multi-GPU training.
To get into more details about multi-GPU training and implementation, read this article: A Beginner-friendly Guide to Multi-GPU Model Training.
Also, we covered 15 ways to optimize neural network training here (with implementation).
👉 Over to you: What are some other strategies for multi-GPU training?
Thanks for reading!
A low temperature value produces identical responses from the LLM (shown below):

But a high temperature value produces gibberish.

What exactly is temperature in LLMs?
RAG has some issues:
Agentic RAG attempts to solve this.
The following visual depicts how it differs from traditional RAG.
The core idea is to introduce agentic behaviors at each stage of RAG.
Steps 1-2) An agent rewrites the query (removing spelling mistakes, etc.)
Step 3-8) An agent decides if it needs more context.
Step 9) We get a response.
Step 10-12) An agent checks if the answer is relevant.
This continues for a few iterations until we get a response or the system admits it cannot answer the query.
This makes RAG more robust since agents ensure individual outcomes are aligned with the goal.
That said, the diagram shows one of the many blueprints an agentic RAG system may possess.
You can adapt it according to your specific use case.
Soon, we shall cover Agentic RAG and many more related techniques to building robust RAG systems.
In the meantime, make sure you are fully equipped with everything we have covered so far like: