A Practical Guide to Scaling ML Model Training
GPUs - GPU Clusters - Distributed Training.
Over the last few weeks, we covered several details around scaling ML models using techniques like multi-GPU training, DDP, understanding the underlying details of CUDA programming, and more.

Today, we shall continue learning in this direction, and I'm excited to bring you a special guest post by Damien Benveniste. He is the author of The AiEdge newsletter and was a Machine Learning Tech Lead at Meta.

In today’s machine learning deep dive, he will provide a detailed discussion on scaling ML models using more advanced techniques. He shall also do a recap of what we have already discussed in the previous deep dive on multi-GPU training, and conclude with a practical demo.
Every section of the deep dive is also accompanied by a video if you prefer that.
Over to Damien.
Introduction
More than ever, we need efficient hardware to accelerate the training process. So, we are going to look at the differences between CPU, GPU, and TPUs. We are going to look at the typical GPU architecture. We also need to explore the strategy to distribute training computations across multiple GPUs for different parallelism strategies. In the end, I am going to show you how we can use the accelerate package by Hugging face to train a model with data parallelism on AWS Sagemaker.
- CPU vs GPU vs TPU
- The GPU Architecture
- Distributed Training
- Data Parallelism
- Model Parallelism
- Zero Redundancy Optimizer Strategy
- Distributing Training with the Accelerate Package on AWS Sagemaker
CPU vs GPU vs TPU
There used to be a time when TPUs were much faster than GPUs (“Benchmarking TPU, GPU, and CPU Platforms for Deep Learning”), but the gap is closing with the latest GPUs. TPUs are only effective for large Deep Learning models and long model training time (weeks or months) that require ONLY matrix multiplications (Matrix multiplication means highly parallelizable).
So why do we prefer GPUs or TPUs for deep learning training? A CPU processes instructions on scalar data in an iterative fashion with minimal parallelizable capabilities.
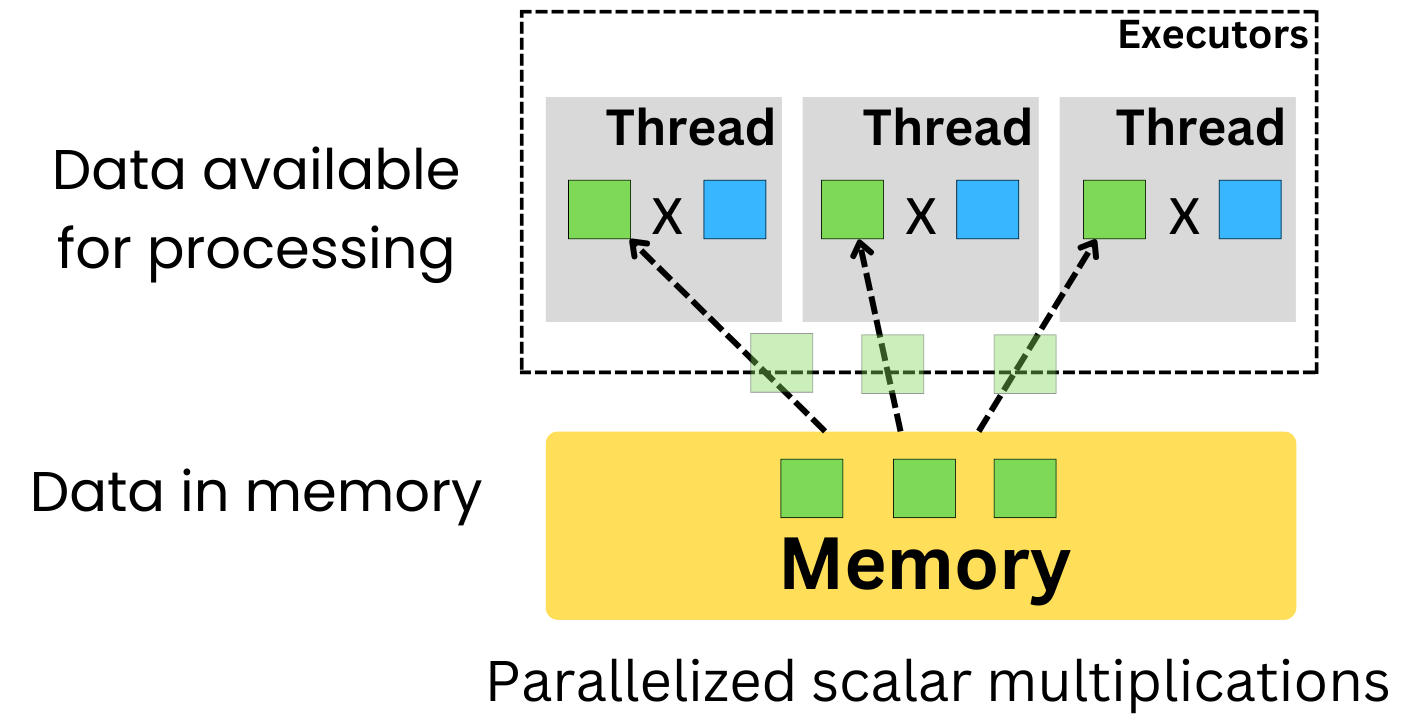
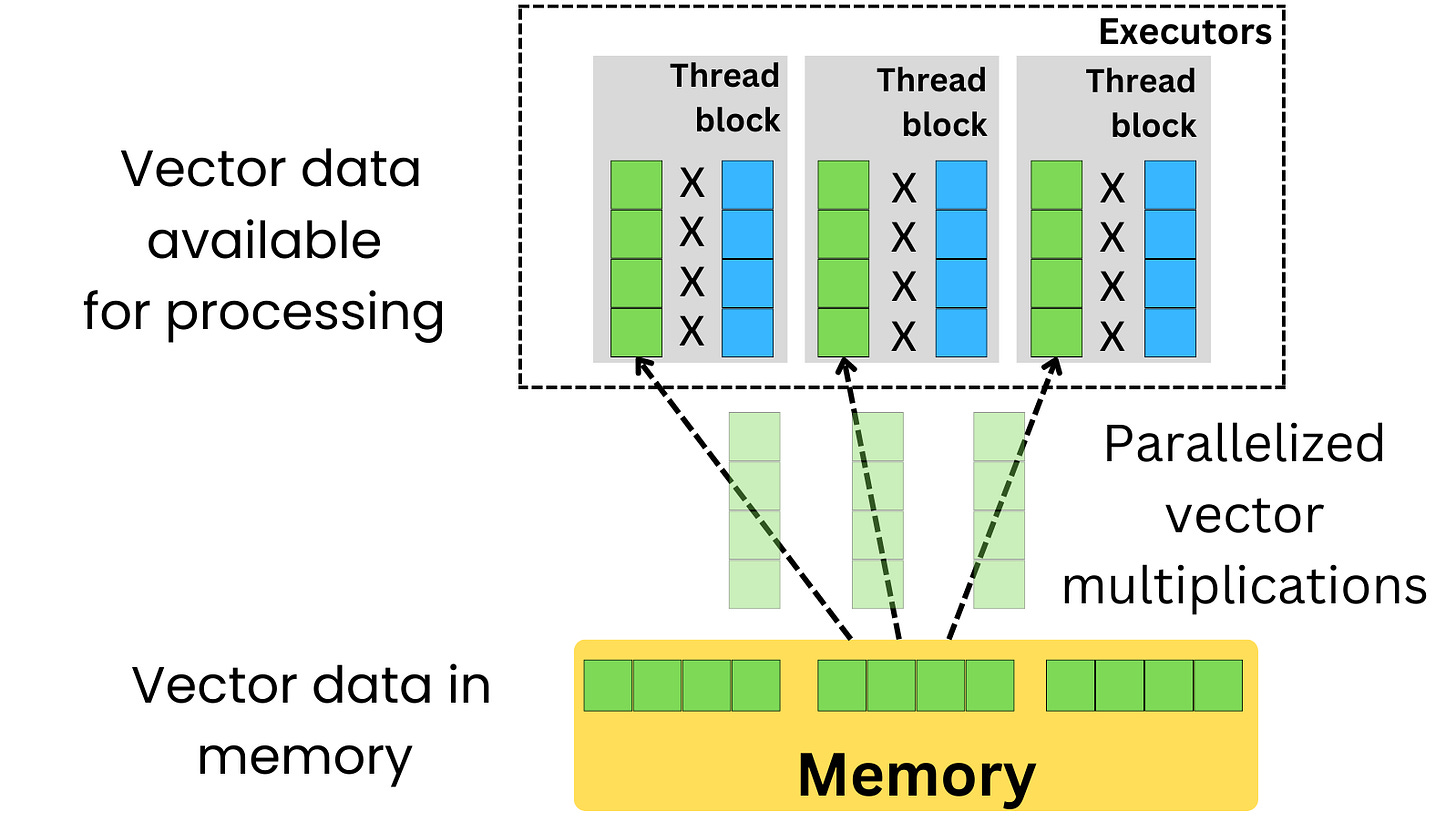
GPU is very good at dealing with vector data structures and can fully parallelize the computation of a dot product between 2 vectors. Matrix multiplication can be expressed as a series of vector dot products, so a GPU is much faster than a CPU at computing matrix multiplication.
A TPU uses a Matrix-Multiply Unit (MMU) that, as opposed to a GPU, reuses vectors that go through dot-products multiple times in matrix multiplication, effectively parallelizing matrix multiplications much more efficiently than a GPU. More recent GPUs are also using matrix multiply-accumulate units but to a lesser extent than TPUs.
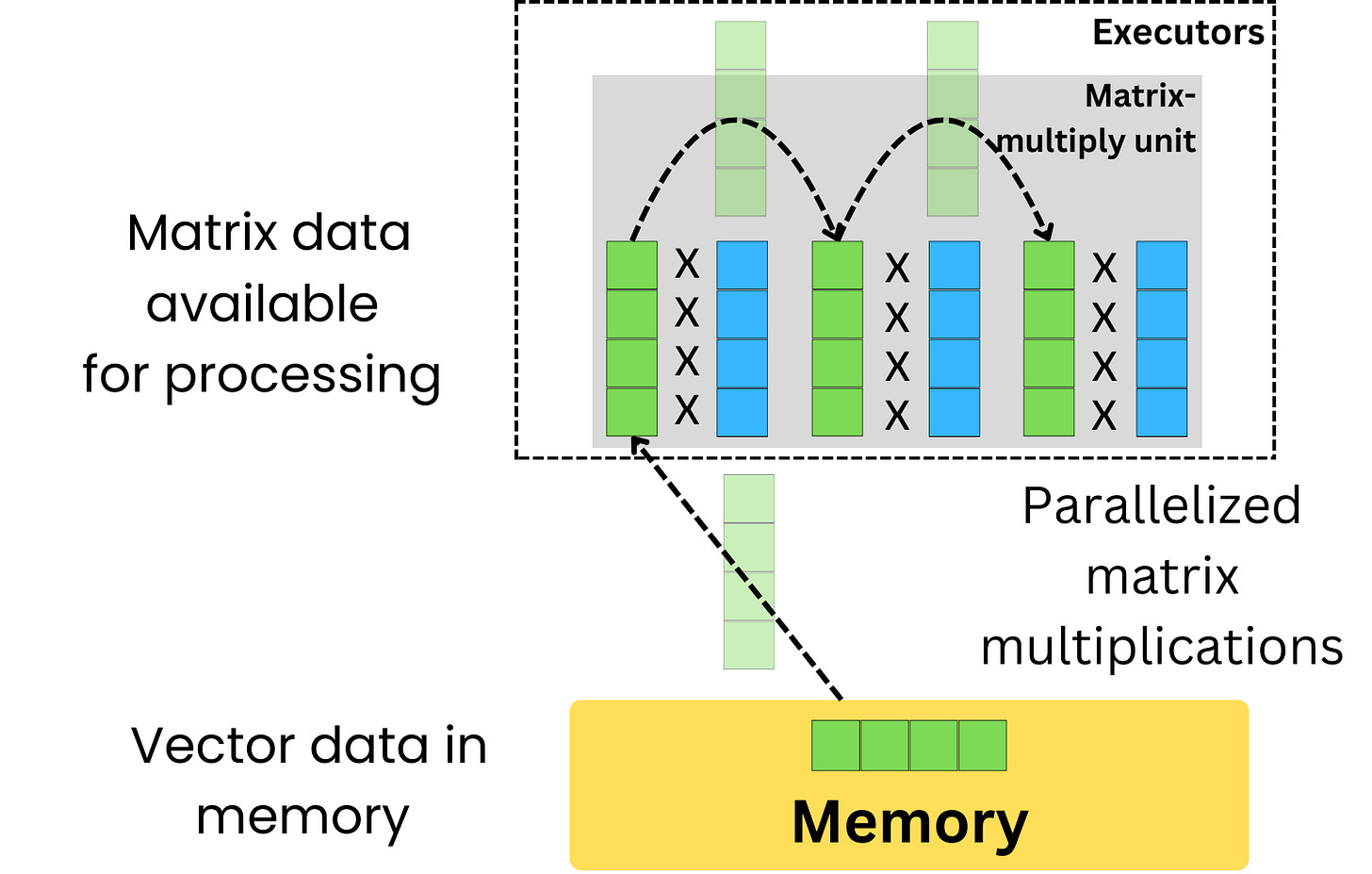
Only deep learning models can really utilize the parallelizable power of TPUs as most ML models are not using matrix multiplications as the underlying algorithmic implementation (Random Forest, GBM, KNN, …).