A Beginner-friendly Guide to Multi-GPU Model Training
Models are becoming bigger and bigger. Learn how to scale models using distributed training.
In an earlier article on PyTorch Lightning, we did not discuss multi-GPU training.
I mentioned that it will require you to know more background details about how it works, the strategies we use, how multiple GPUs remain in sync with one another during model training in a distributed setting, considerations, and more.

So today, we are continuing with that topic and will be understanding some of the core technicalities behind multi-GPU training, how it works under the hood, and implementation-specific details.
We shall also look at the key considerations for multi-GPU (or distributed) training, which, if not addressed appropriately, may lead to suboptimal performance, slow training, or even instability in training.
Let’s begin!
Motivation for multi-GPU training
By default, deep learning models built with PyTorch are only trained on a single GPU, even if you have multiple GPUs available.
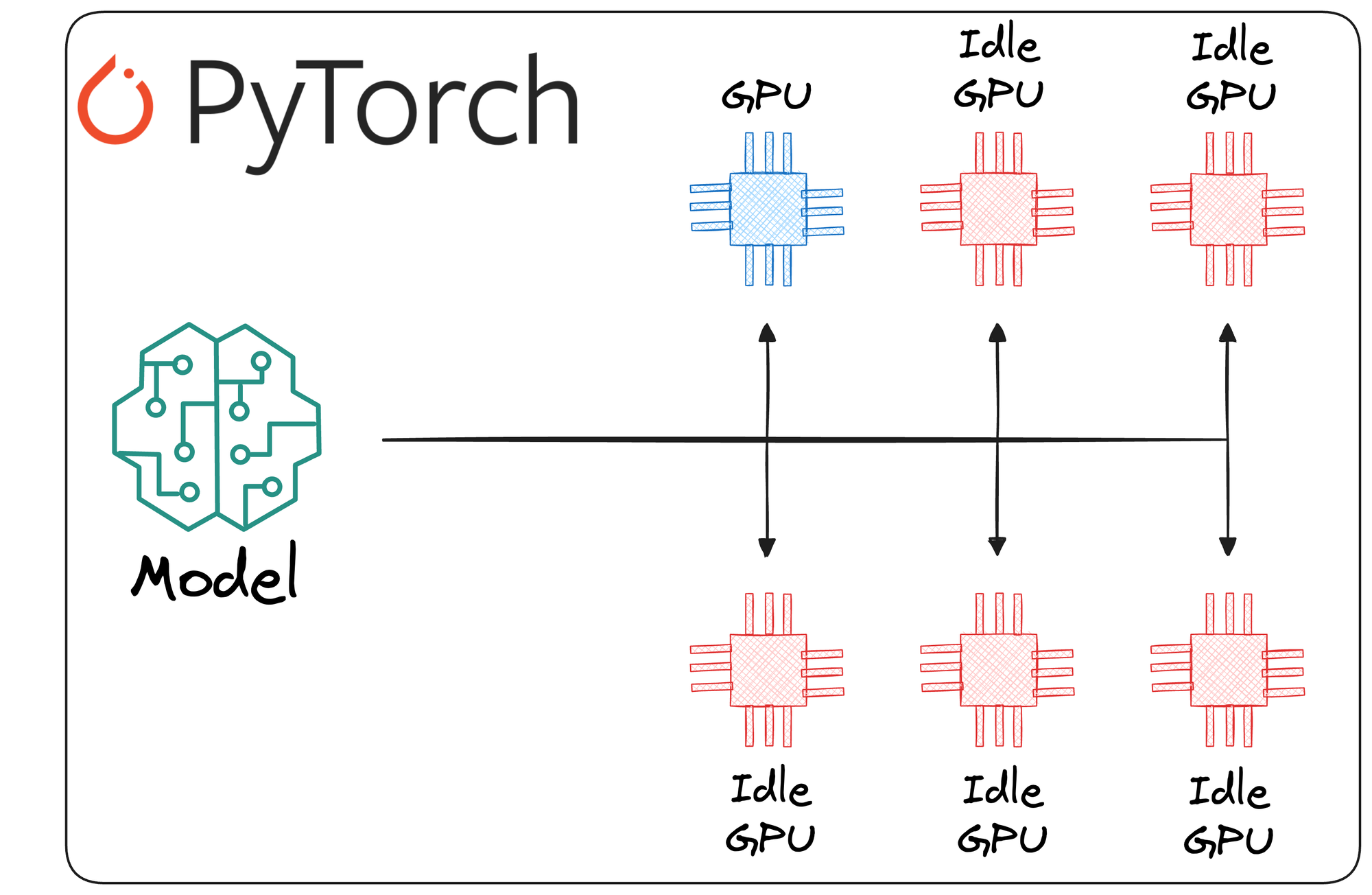
This does mean that we cannot do multi-GPU training with PyTorch. We can do that. However, it does require us to explicitly utilize PyTorch's parallel processing capabilities.
Moreover, even if we were to utilize multiple GPUs with PyTorch, typical training procedures would always be restricted to a single machine. This limitation arises because PyTorch's default behavior is to use a single machine for model training.
Therefore, it becomes a severe bottleneck when working with larger datasets that require more computational power than what a single machine can provide.
However, acknowledging that we are restricted to a single machine for model training makes us realize that there is ample scope for further run-time optimization.
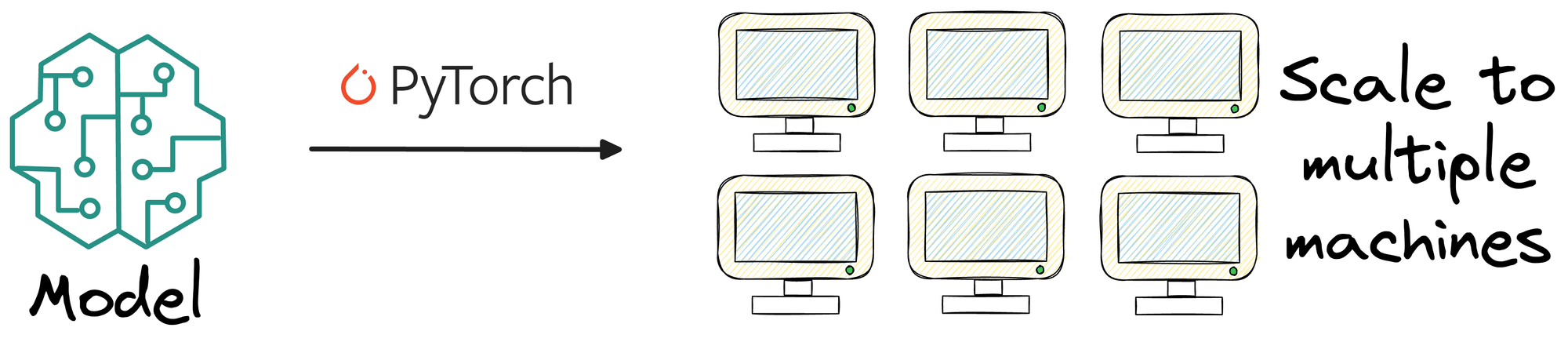
Multi-GPU training solves this.
In a gist (and as the name suggests), multi-GPU training enables us to distribute the workload of model training across multiple GPUs and even multiple machines if necessary.
This significantly reduces the training time for large datasets and complex models by leveraging the combined computational power of the available hardware.
While there are many ways (strategies) to achieve multi-GPU training, one of the most common ways is to let each GPU or machine process a portion of the input data independently.
This is also called data parallelism.
Data parallelism
In data parallelism, the idea is to divide the available data into smaller batches, and each batch is processed by a separate GPU.
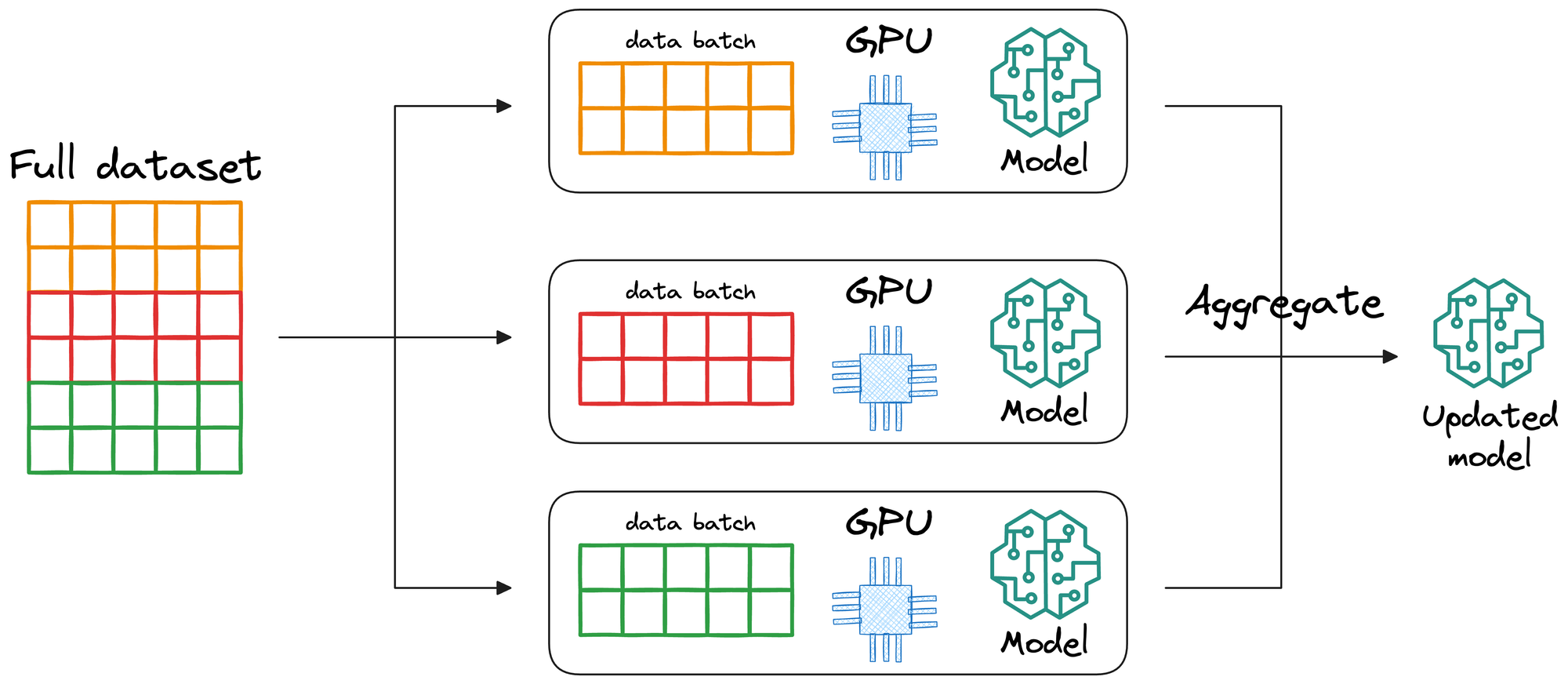
Finally, the updates from each GPU are then aggregated and used to update the model parameters.
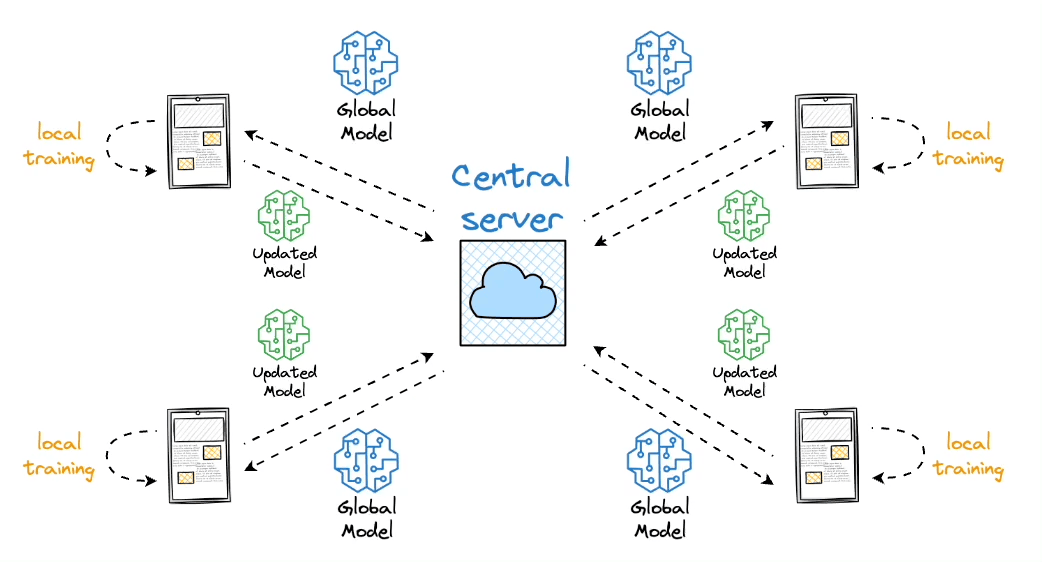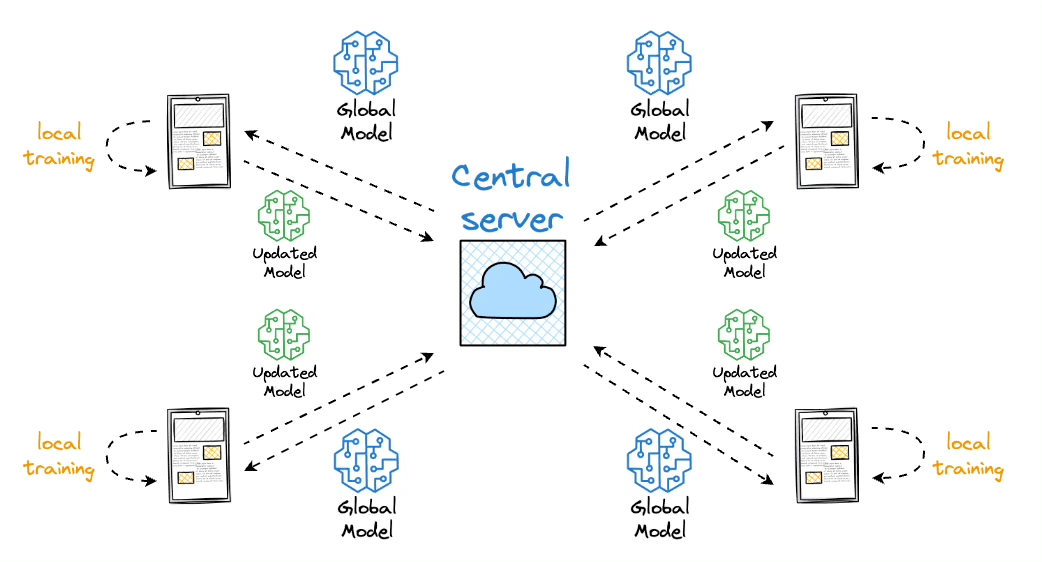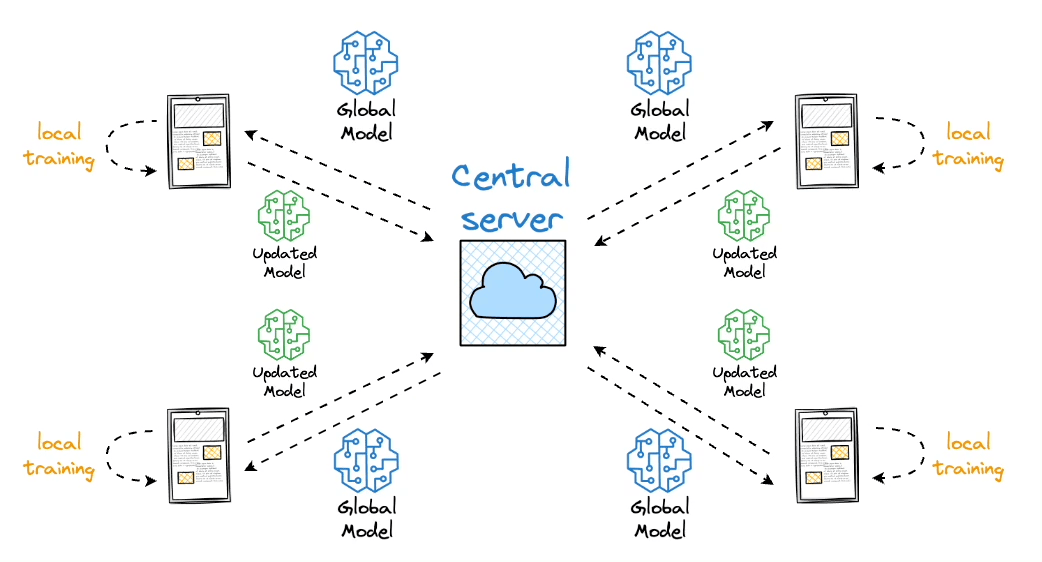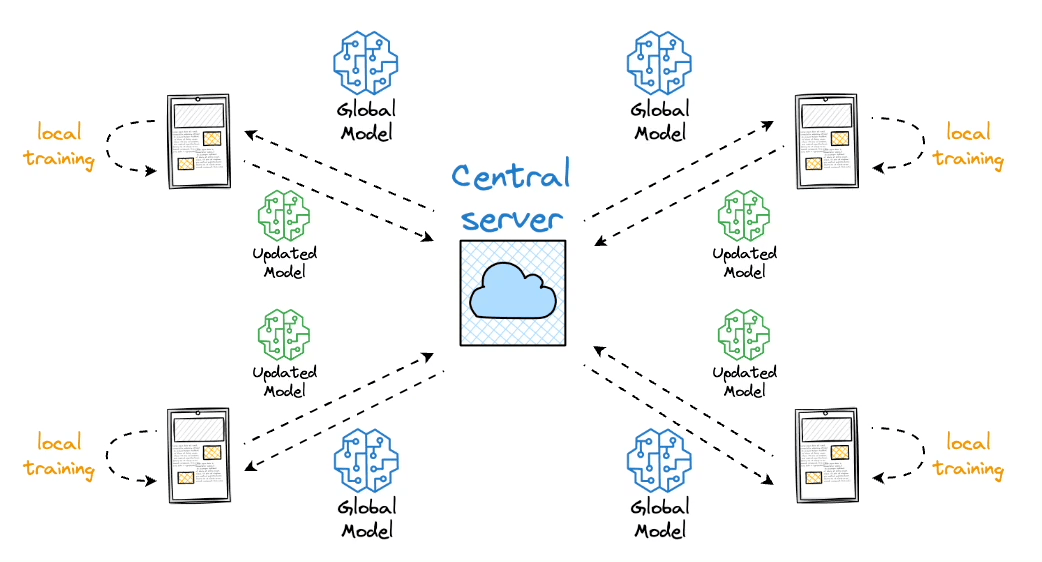
If you recall the deep dive on federated learning, the idea might appear very similar to what we discussed back then:
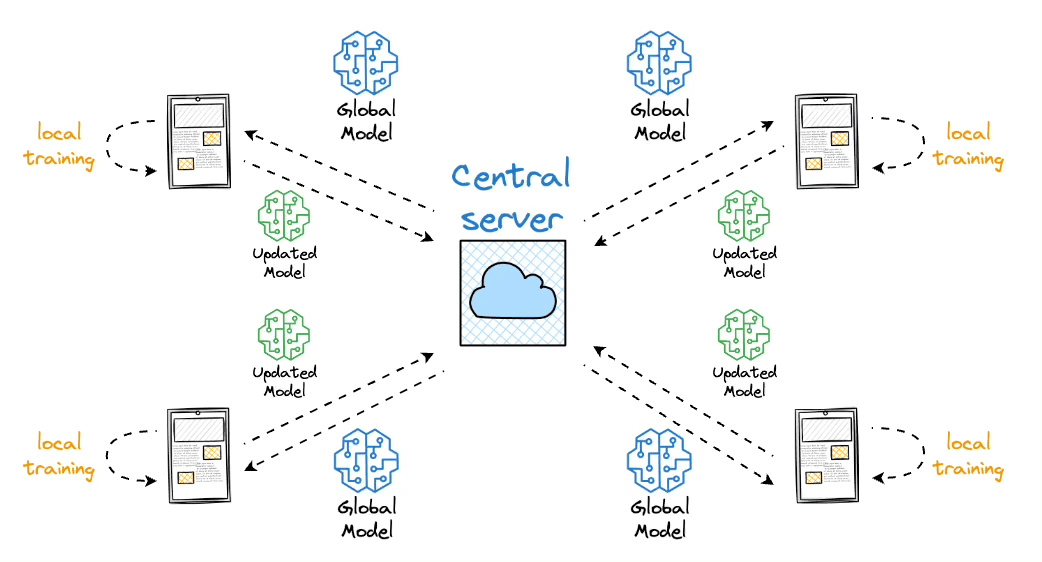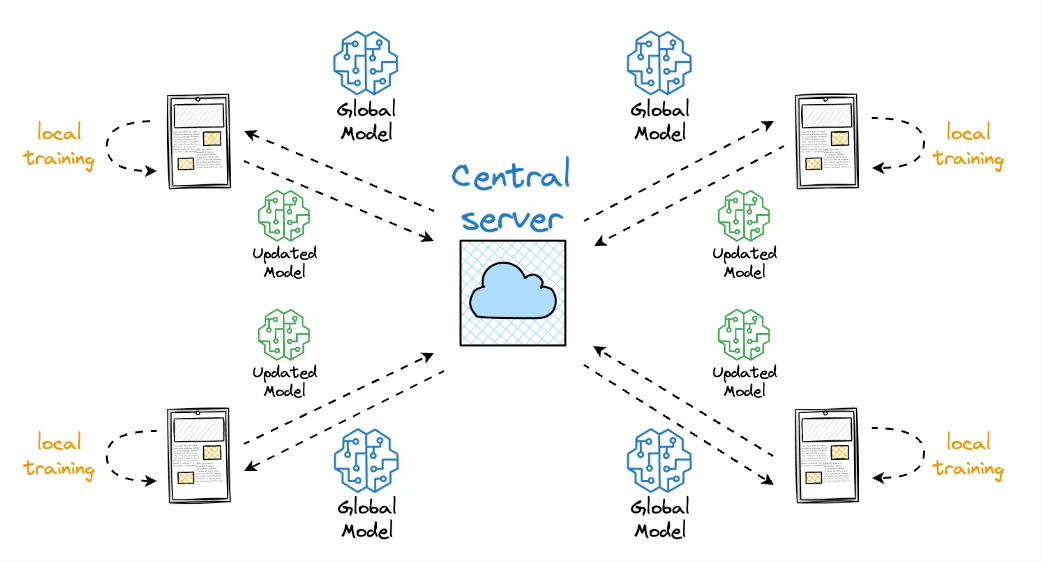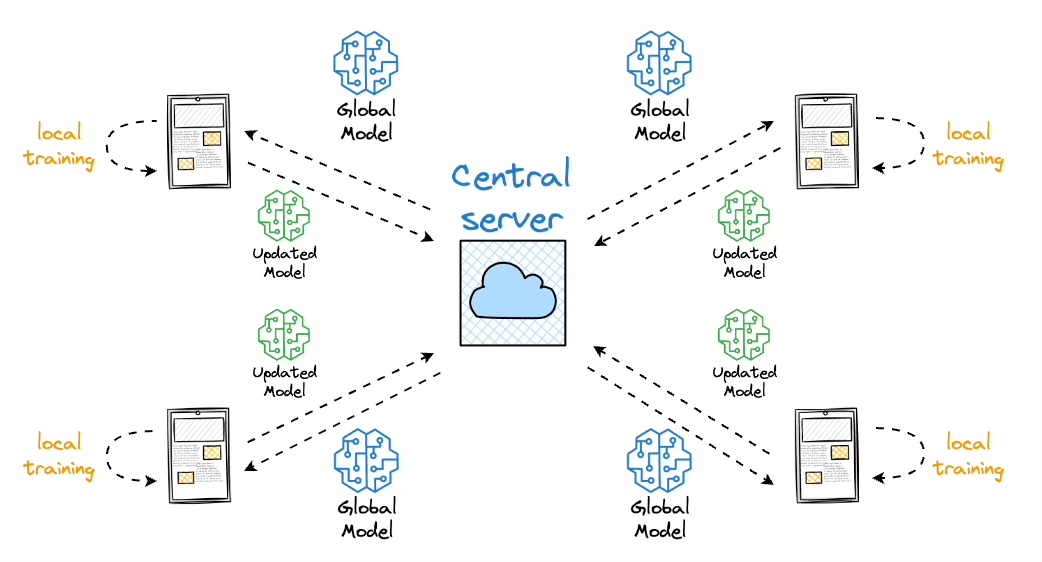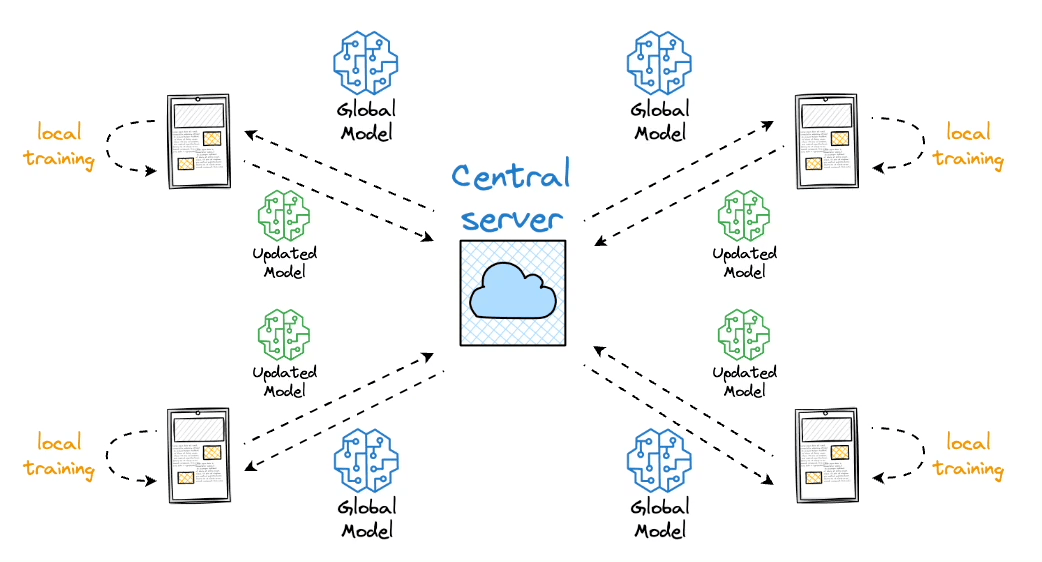
In federated learning, instead of a single centralized server processing all the data, the model is trained across multiple decentralized edge devices, each with its own data. The updates from these edge devices are then aggregated to improve the global model.
Similarly, in data parallelism, each GPU acts as a "mini-server," processing a portion of the data and updating the model parameters locally.
These local updates are then combined to update the global model. This parallel processing of data not only speeds up the training process but also allows for efficient use of resources in distributed environments.
One major difference is that in federated learning, we do not have direct access to the local dataset, whereas in data parallelism, the data is directly accessible.
Nonetheless, it is quite obvious to understand that this approach not only improves the efficiency of model training but also allows us to scale our training to handle larger datasets and more complex models than would be possible with a single GPU or machine.
Strategies for data parallelism
As discussed above, data parallelism is a technique used in deep learning to parallelize the training of a model by splitting the data across multiple devices, such as GPUs or machines, and then combining the results.
Quite intuitively, this approach can significantly reduce the training time for large models and datasets by leveraging the computational power of multiple devices.