Quantization: Optimize ML Models to Run Them on Tiny Hardware
A must-know skill for ML engineers to reduce model footprint and inference time.
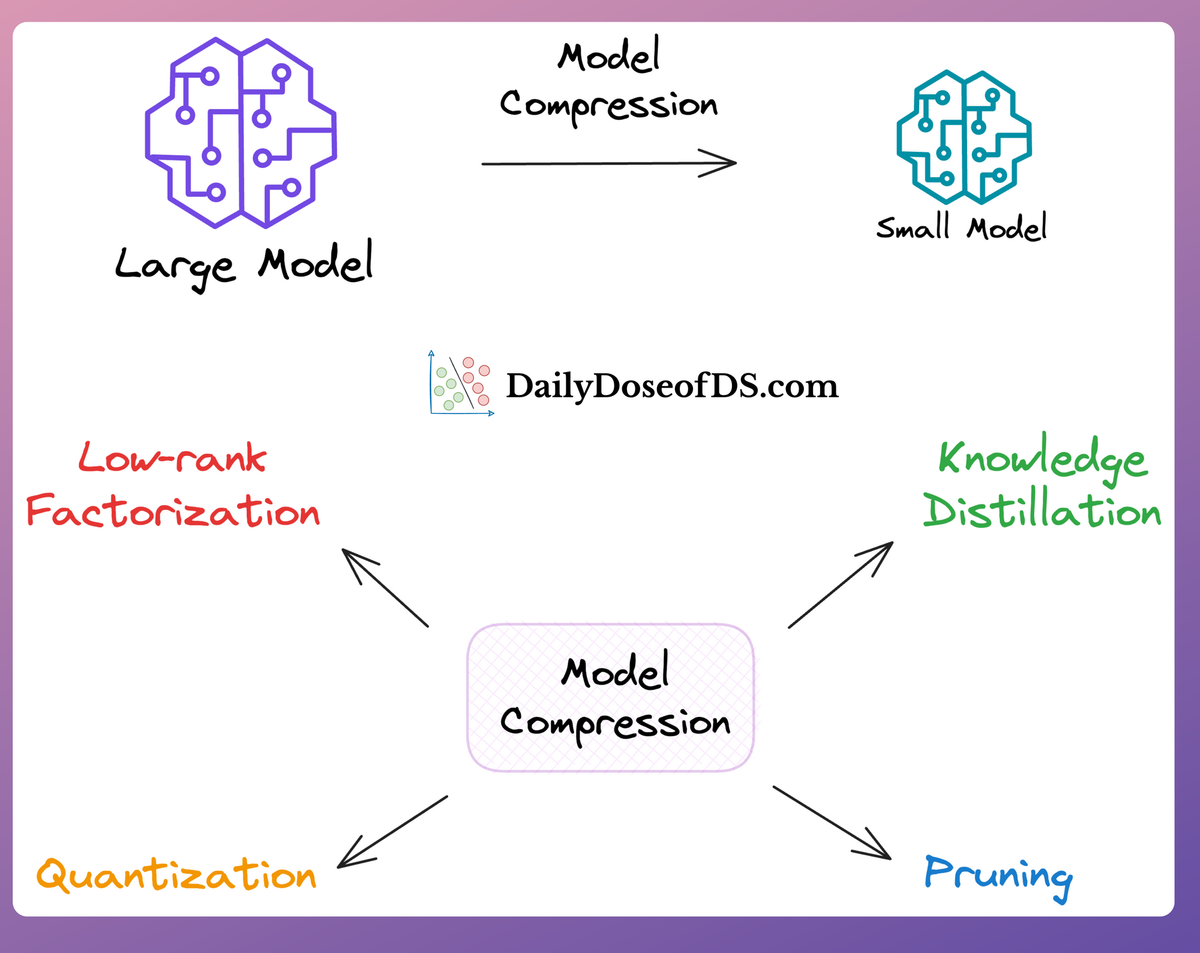
In an earlier deep dive on model compression, we discussed various ways to compress the ML model after training it.
- It could be that you have trained a model, but it's too big to be deployed. Compression techniques can help you do that.
- Or, it could be that you intend to use an open-source model on your local machine and it's too big for your machine to load in memory.
In that article, we discussed various techniques that help us reduce the memory footprint of ML models and make them more accessible/deployable.
One of the techniques we discussed in that article was Quantization, which we discussed in a bit of detail, but not in the exact detail that this topic deserves to be understood by machine learning engineers.
So in this article, we shall dive into the technical details of Quantization, what it is, how it works, why it is promising and is considered one of the most powerful techniques to make use of large models on regular machines.
Let's begin!
Motivation
Typically, the parameters of a neural network (layer weights) are represented using 32-bit floating-point numbers.