A Crash Course on Building RAG Systems – Part 7 (With Implementation)
A deep dive into Graph RAG and how it improves traditional RAG systems (with implementation).
Introduction
If you recall our crash course on graph neural networks, we understood how a significant proportion of our real-world data often exists in the form of graphs, where entities (nodes) are connected by relationships (edges), and these connections carry significant meaning, which, if we knew how to model, can lead to much more robust models.
For instance:
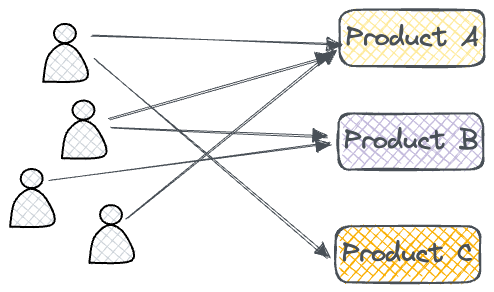
- Instead of representing e-commerce data in a tabular form (this user purchased this product at this time for this amount...), it can be better represented as interactions between users and products in the form of graphs. As a result, we can use this representation to learn from and possibly make more relevant personalized recommendations.
- In social networks, by using a graph to describe the relationship between users and how they are connected and engage with each other (comment, react, messaging, etc.), we can possibly train a model to detect fake accounts and bots. This can become an anomaly detection problem or a simple binary node classification problem — fake, not-fake classification.
That makes intuitive sense as well.
Turns out, similar things can be done in RAG in the form of Graph RAG.
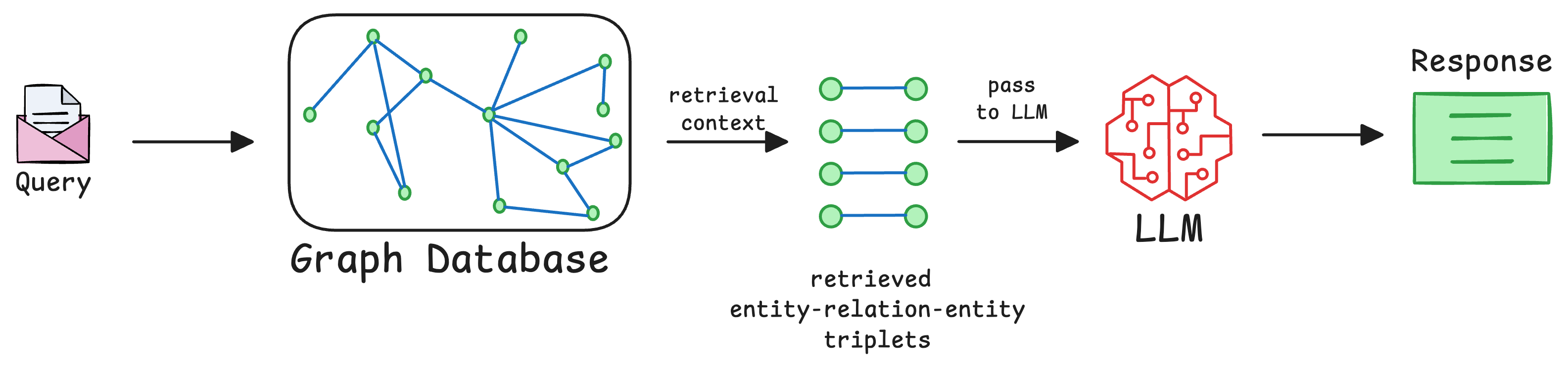
More specifically, traditional RAG systems typically rely on vector-based retrieval to find relevant chunks of information from a database of embeddings.
These embeddings, as we learned in the previous parts of this RAG crash course, represent individual pieces of text, images, or other modalities, but they lack a natural way to incorporate relationships between these pieces of data.
In other words, traditional RAG treats all retrieved chunks as independent, without leveraging how they might be interconnected.
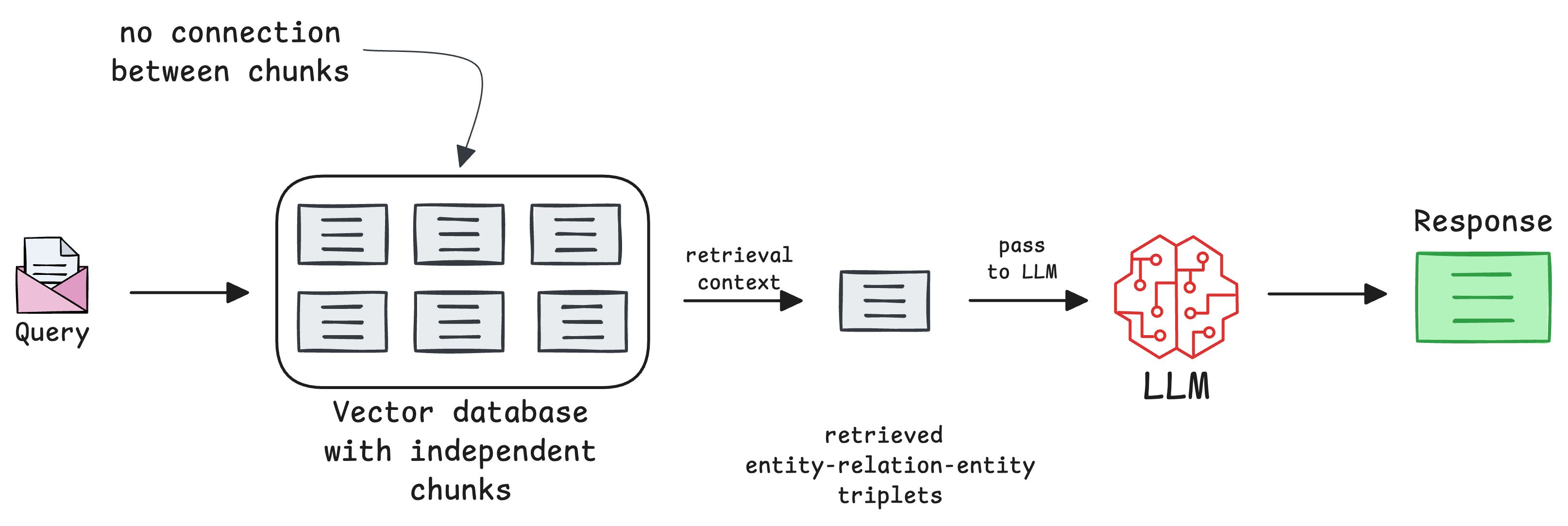
Graph RAG systems address this limitation.
So, in this part of the series, we’ll understand how Graph RAG works, from integrating knowledge graphs to leveraging graph traversal for retrieval and finally feeding the retrieved context into an LLM for generation.
By the end, you’ll understand how Graph RAG works internally. Like always, we'll cover the implementation so that you can start building one yourself.
Let's dive in, but first, let's spend some more time setting up the motivation for following this approach by understanding the limitations of traditional RAG systems and how graph RAG handles them.
Limitations of traditional RAG
As we have seen so far, traditional RAG (Retrieval-Augmented Generation) systems have been incredibly useful in augmenting fresh knowledge so that generative models can generate more reliable answers.
However, their design inherently introduces certain limitations when dealing with complex queries or interrelated data. Let’s explore these limitations in detail to understand why Graph RAG is a more robust alternative.
#1) LLMs love structured data
Large language models (LLMs) are inherently adept at reasoning with structured data because they provide clear relationships between entities.
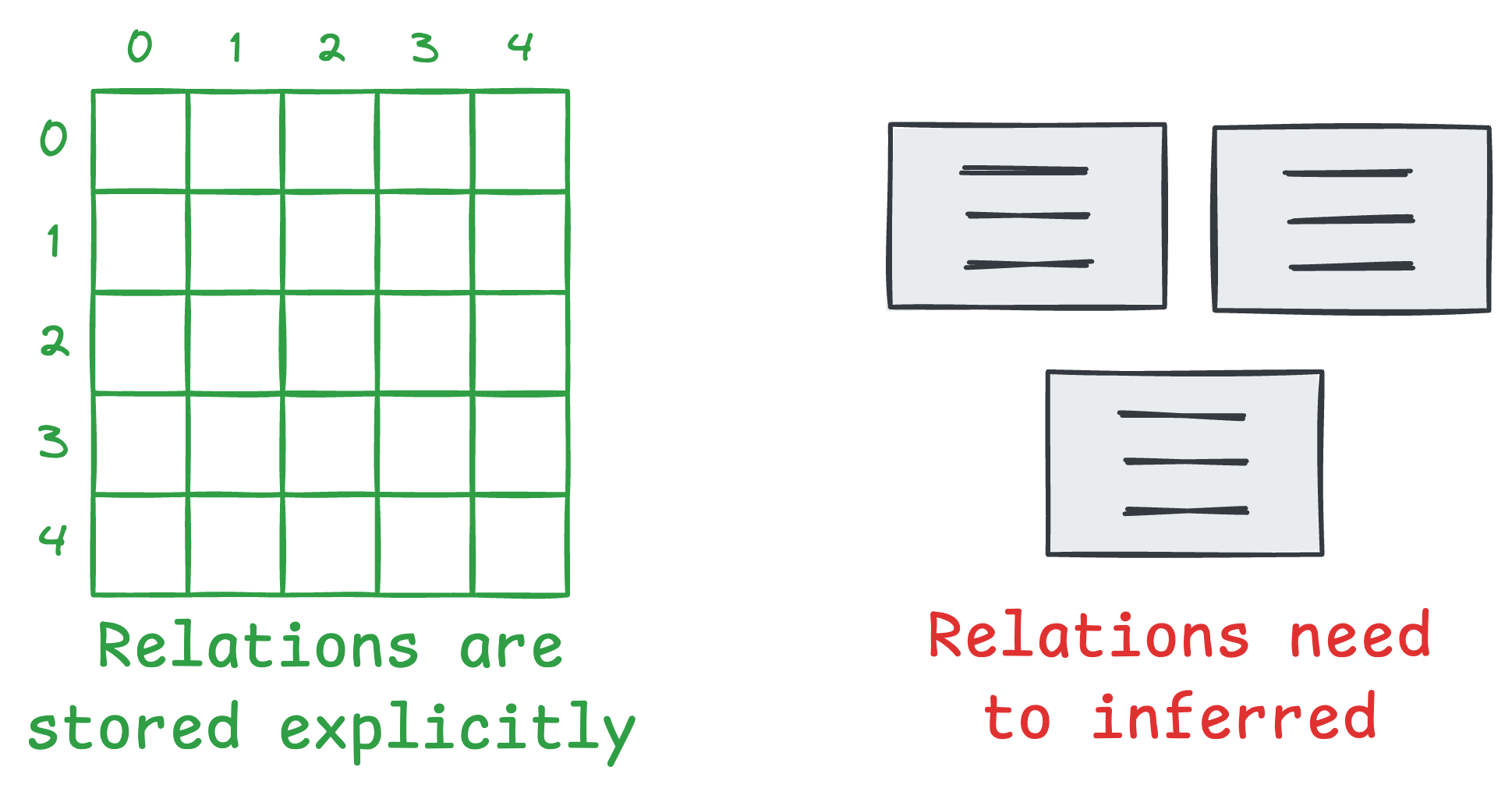
For instance, consider the difference between these two data inputs:
- Unstructured sentence:
- "LinkedIn is a social media network for professionals owned by Microsoft."
- Structured entity-relation-entity triplets:
- (LinkedIn, is, social media network)
- (LinkedIn, isFor, professionals)
- (LinkedIn, ownedBy, Microsoft)
In the first case, while the sentence is small, the model must infer the relationships between all entities. While in this case, it looks straightforward but will longer chunks, this could likely introduce errors or incomplete reasoning.
But the second case immensely lifts off that mental fatigue from the LLM because, in this case, the relationships are explicit, which enables the model to reason much more effectively.
More formally, we know that traditional RAG retrieves unstructured chunks of information without explicitly capturing the relationships between entities. So even if the correct information is retrieved, the model may struggle to connect the dots between seemingly related facts.
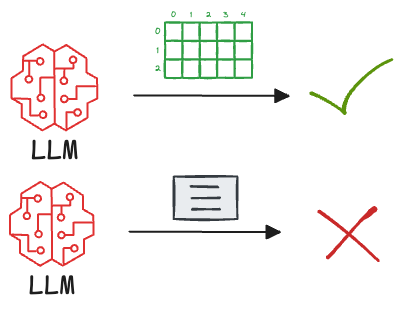
But since Graph RAG integrates knowledge graphs, which naturally encode structured data in the form of nodes and edges, feeding this structured representation into the LLM provides the model with a much more digestible format.
This improves its reasoning and response generation capabilities.
#2) Limited handling of long-term connections across chunks
Consider a scenario where an answer lies in two separate chunks of text which are not explicitly connected during retrieval:
- Chunk 1: "Marie Curie discovered radium and won two Nobel Prizes."
- Chunk 2: "Marie Curie's discovery of radium contributed significantly to cancer treatment."
Since traditional RAG systems retrieve each chunk independently, this can often leave the LLM to infer the connections between them.
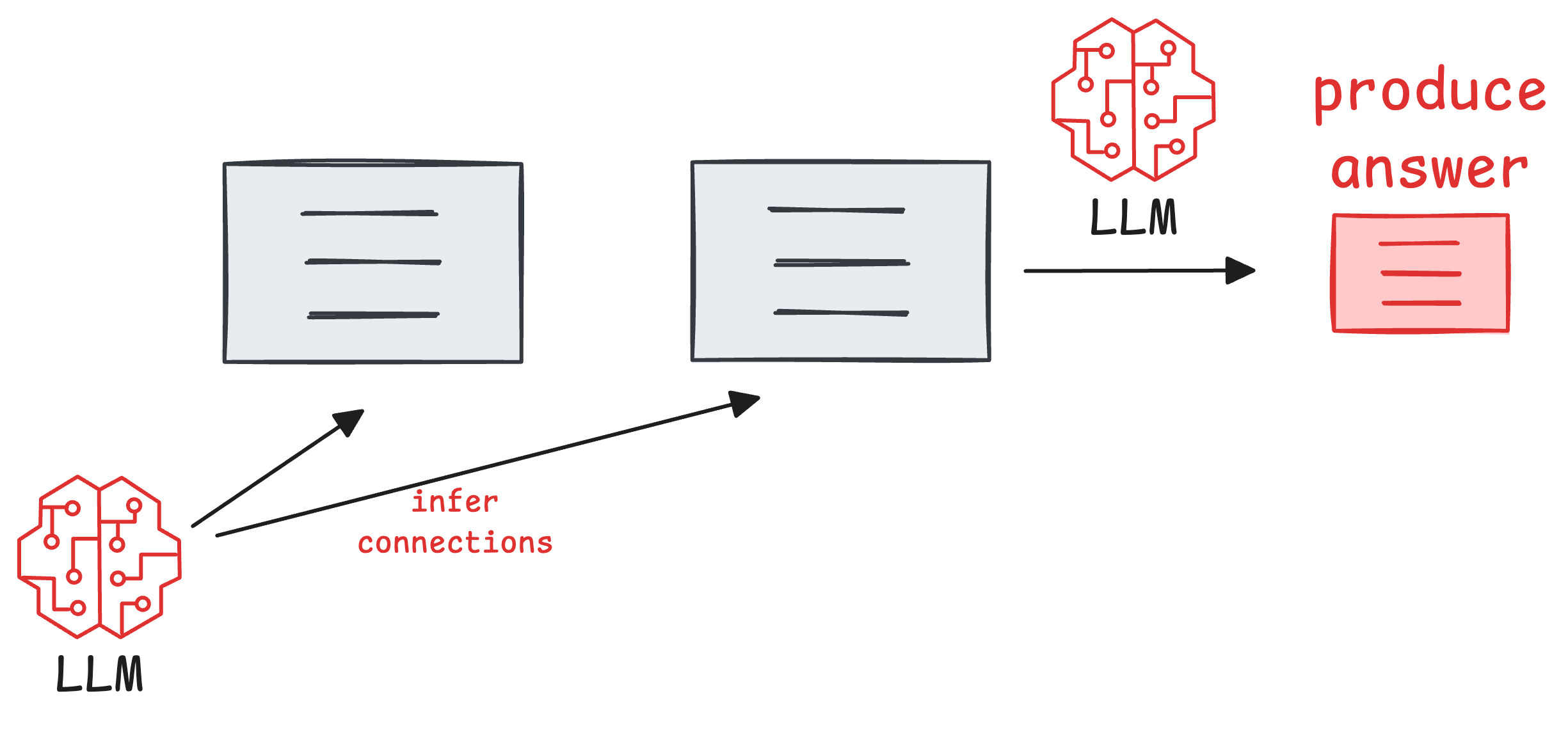
In fact, since the entirety of retrieval depends on the cosine similarity between the chunk and the query, and if an answer can only be produced when both chunks are retrieved, a chunk may be left out due to low cosine similarity in extreme cases.
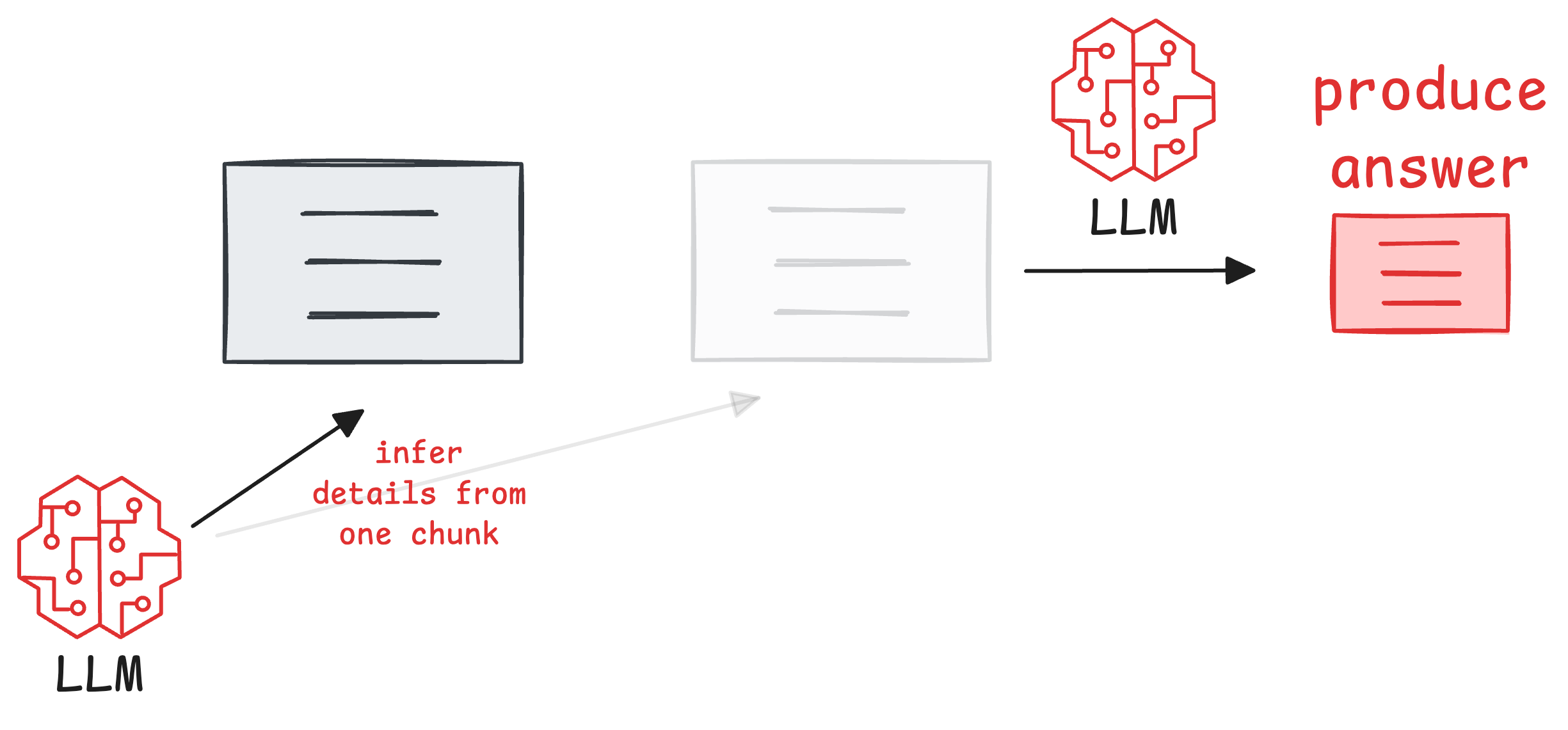
As a result, this will likely produce fragmented or incomplete answers because RAG lacks the appropriate context required to generate an answer.
In fact, even if the two chunks do get retrieved, it could still be difficult to build long-term connections across chunks.
In other words, it's challenging to answer multi-hop queries or infer causality across multiple pieces of information.
Graph RAG solves this problem as well.
In Graph RAG, nodes can represent individual chunks of information, and edges can encode relationships between them.
Here's how.
Going back to the two chunks above:
- Chunk 1: "Marie Curie discovered radium and won two Nobel Prizes."
- Chunk 2: "Marie Curie's discovery of radium contributed significantly to cancer treatment."
This will likely produce the following knowledge graph: