A Crash Course on Building RAG Systems – Part 8 (With Implementation)
A deep dive into ColBERT and ColBERTv2 for improving RAG systems (with implementation).
Recap
In an earlier deep dive, we went into a whole lot of detail around sentence pair similarity scoring in real-world NLP systems, why it matters, and the techniques to build such systems.
More specifically, we understood that so many real-world NLP systems, either implicitly or explicitly, rely on pairwise sentence (or context) scoring in one form or another.
- Retrieval-augment generation (RAG) systems heavily use it, as we have already seen through this crash course.
- Question-answering systems implicitly use it.
- Several information retrieval (IR) systems depend on it.
- Duplicate detection engines assess context similarities, which is often found in community-driven platforms.
To build such systems, we explored two popular approaches to sentence pair similarity tasks: Cross-encoders and Bi-encoders, each with its own strengths and limitations.
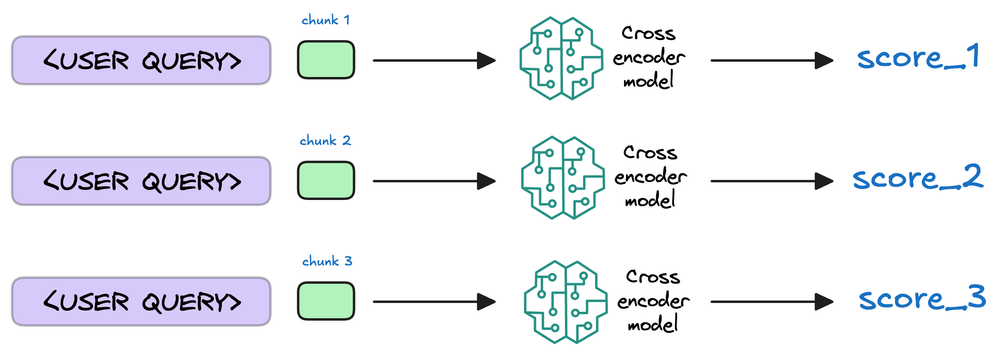
1) Cross-encoders
Cross-encoders are conceptually one of the simplest approaches you can think of for this task.
The way it works is demonstrated below:
- We concatenate the query text and the document text together into one single text.
- We process the concatenated text using BERT and then apply some transformation (which could be a dense layer) to the final representations from the BERT model for more fine-tuning (provided we have some positive and negative query-document pairs).
As it might be evident, since the model attends to both the document and the query simultaneously, it can capture intricate relationships and dependencies between the two, so the representation will most likely be incredibly semantically expressive.
That said, this simply won't scale since we need to encode every document at query time and compute the query-document pair scores.
So, in practice, if we have, say, 1 billion documents, we must do a billion forward passes from the BERT model (one pass per document), determine the similarity scores, and use them for the upcoming task of generation.
So, while everything seems conceptually right for this approach, it's simply infeasible for modern retrieval systems.
2) Bi-encoders
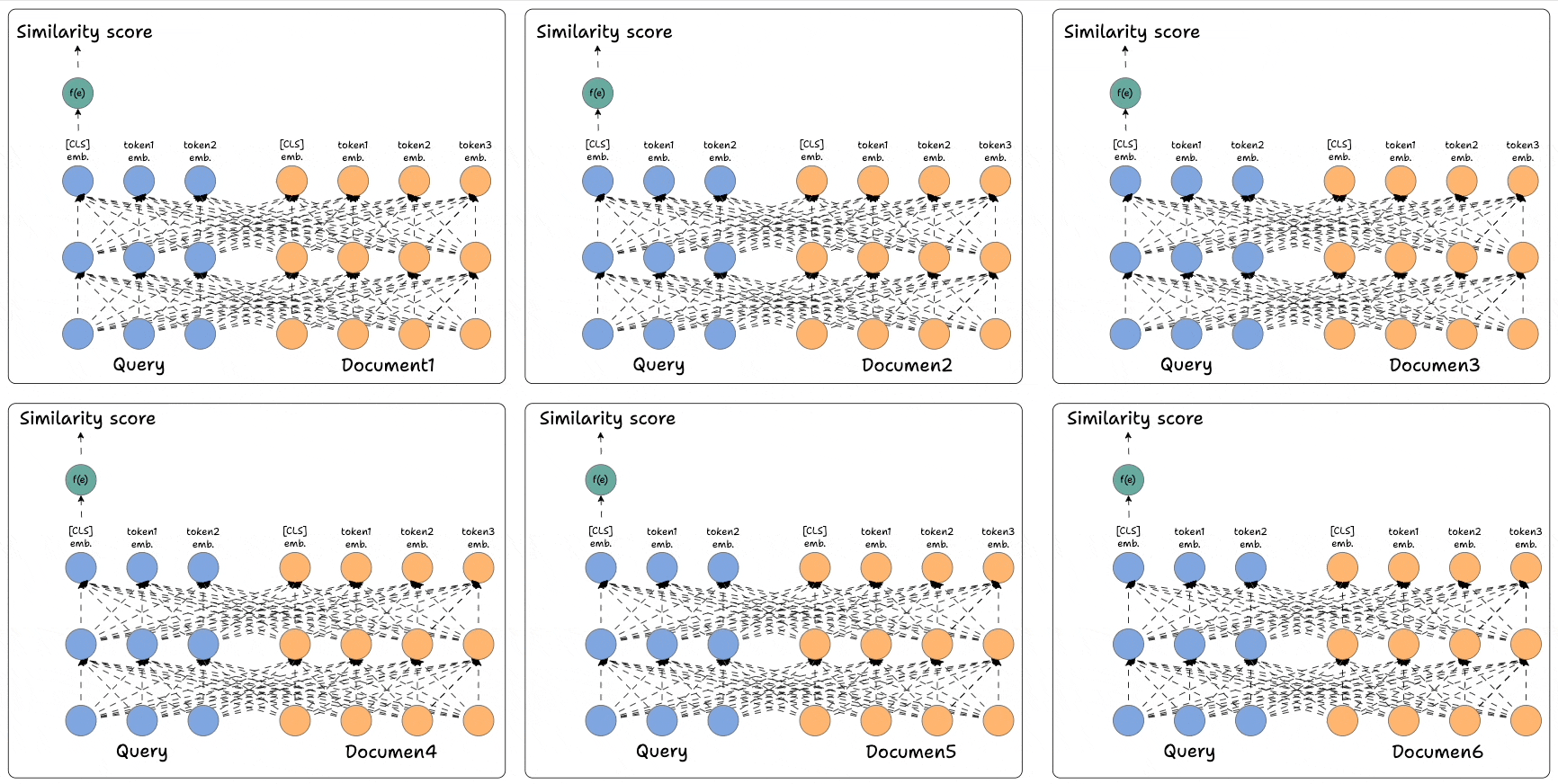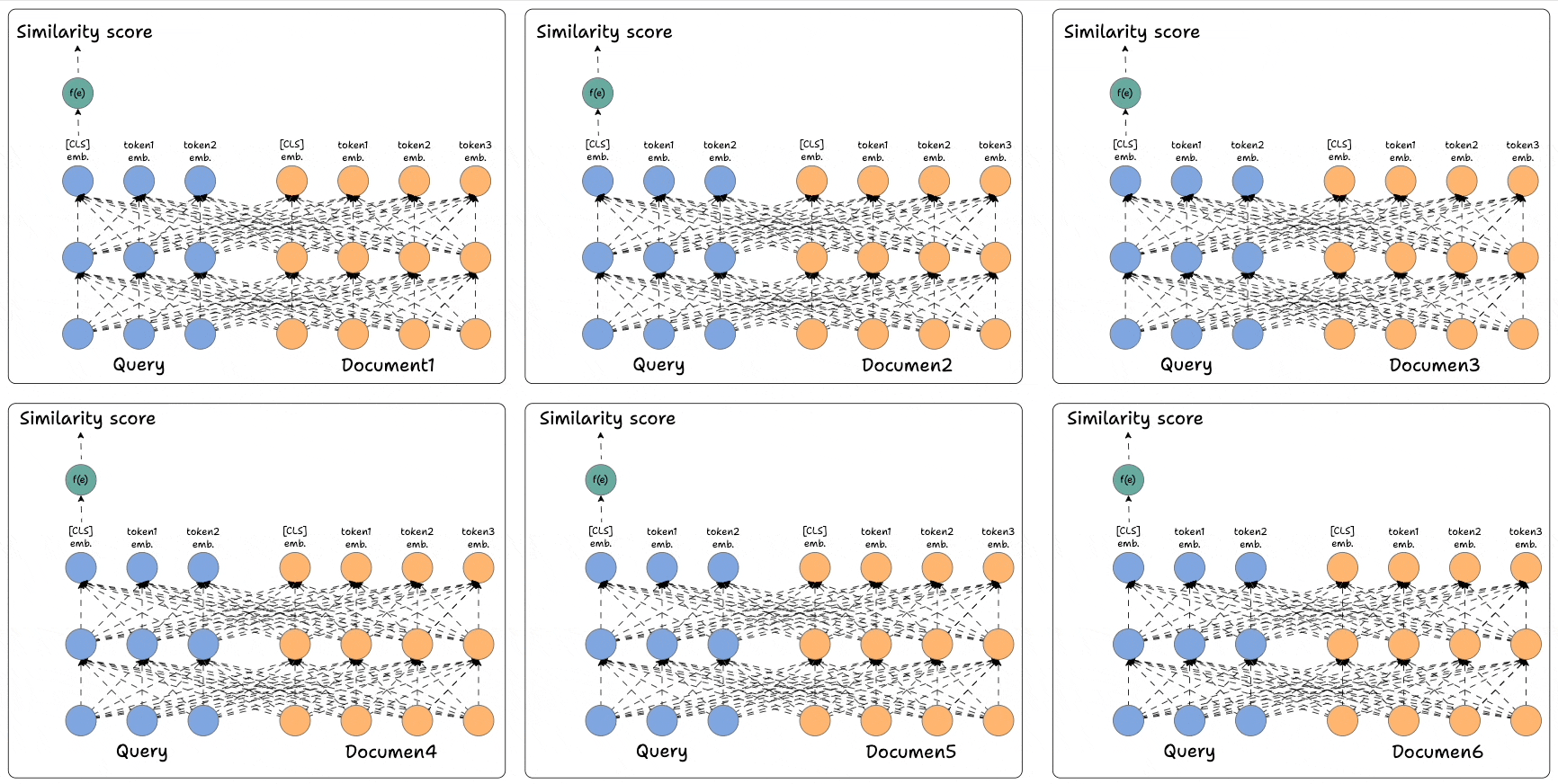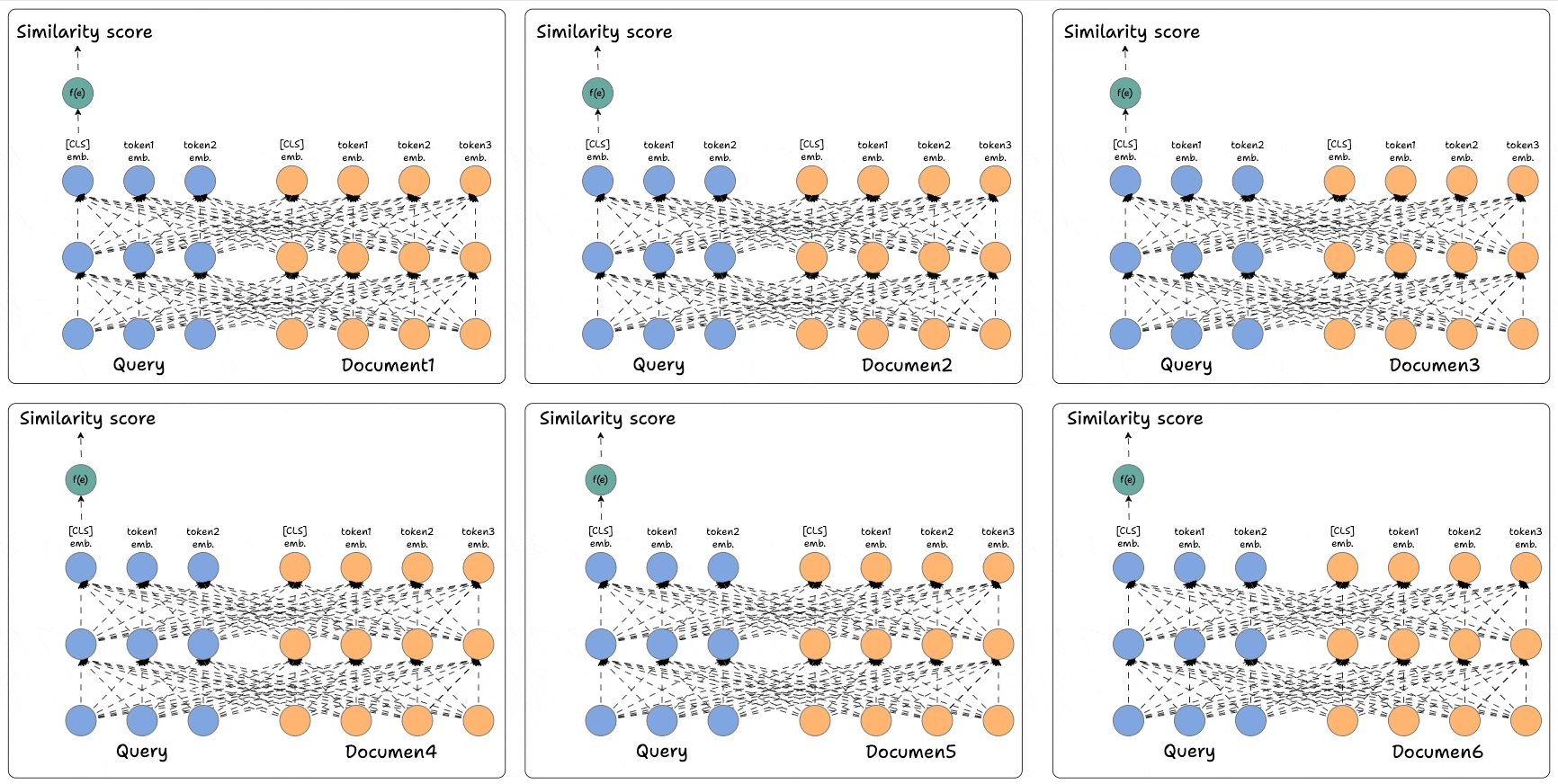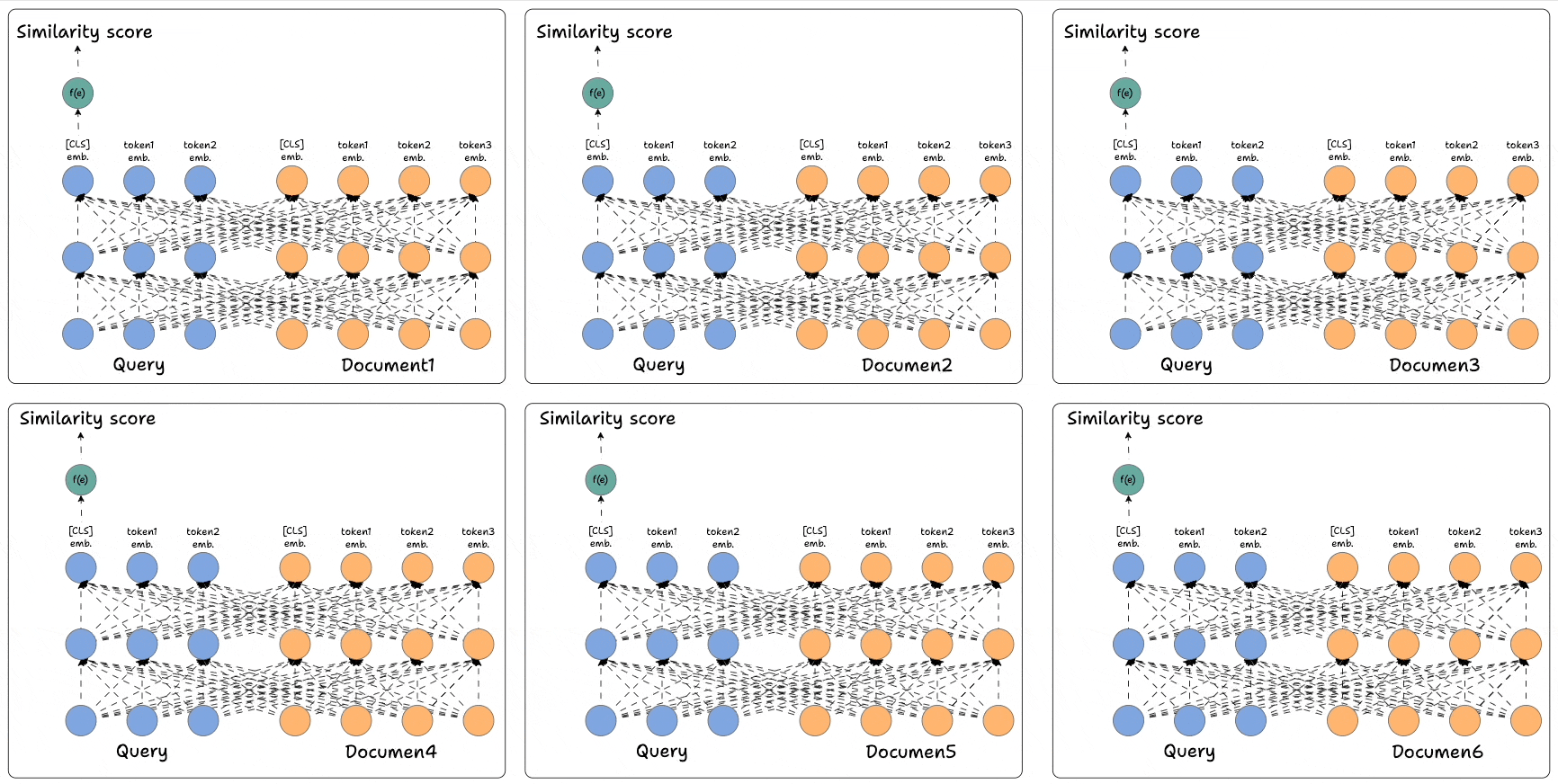
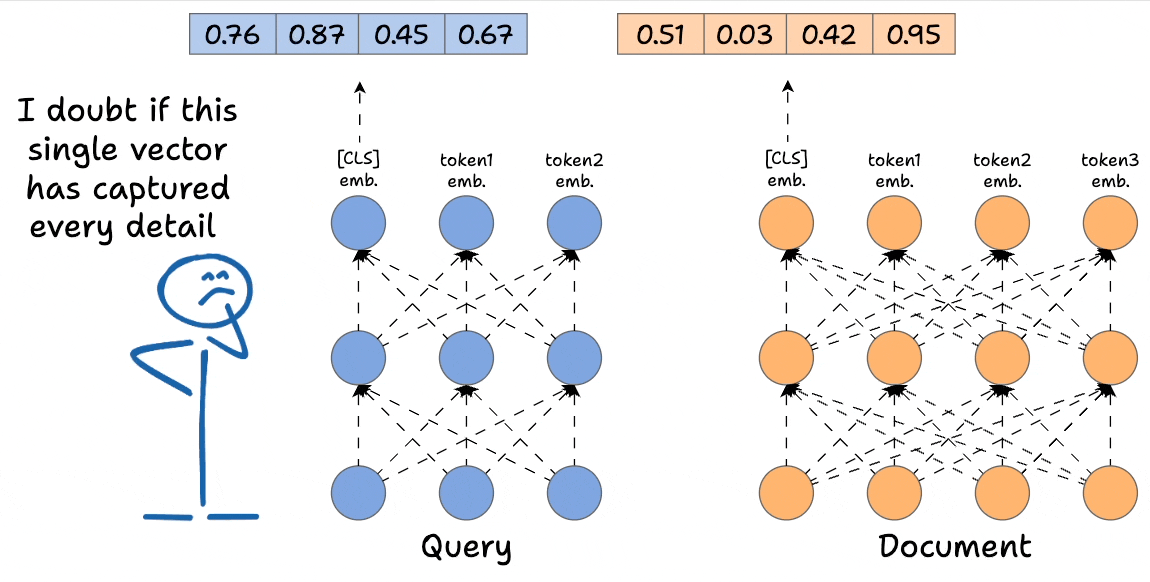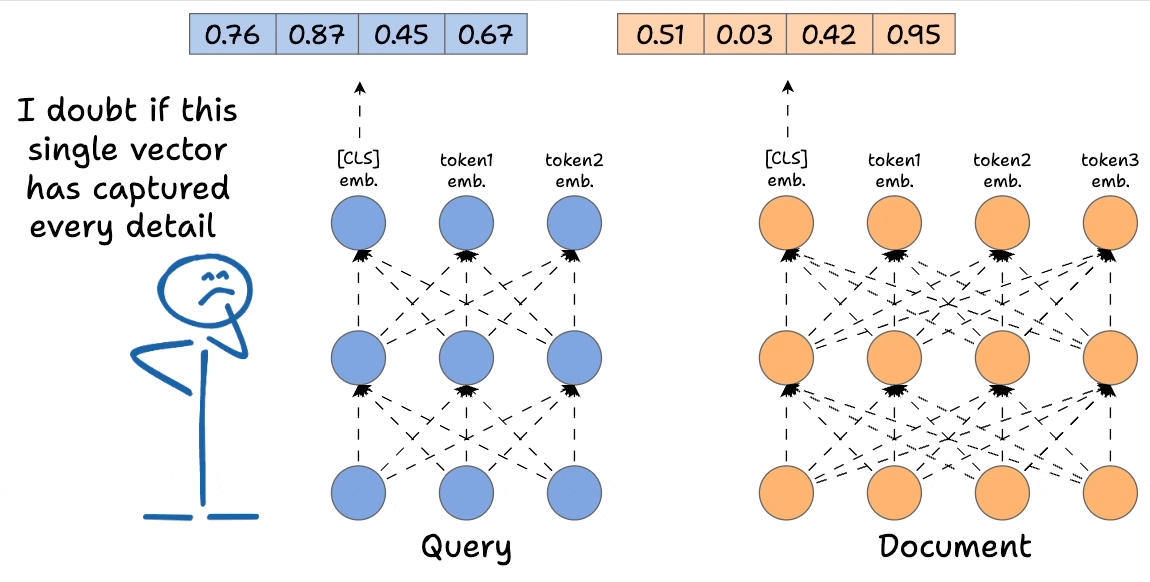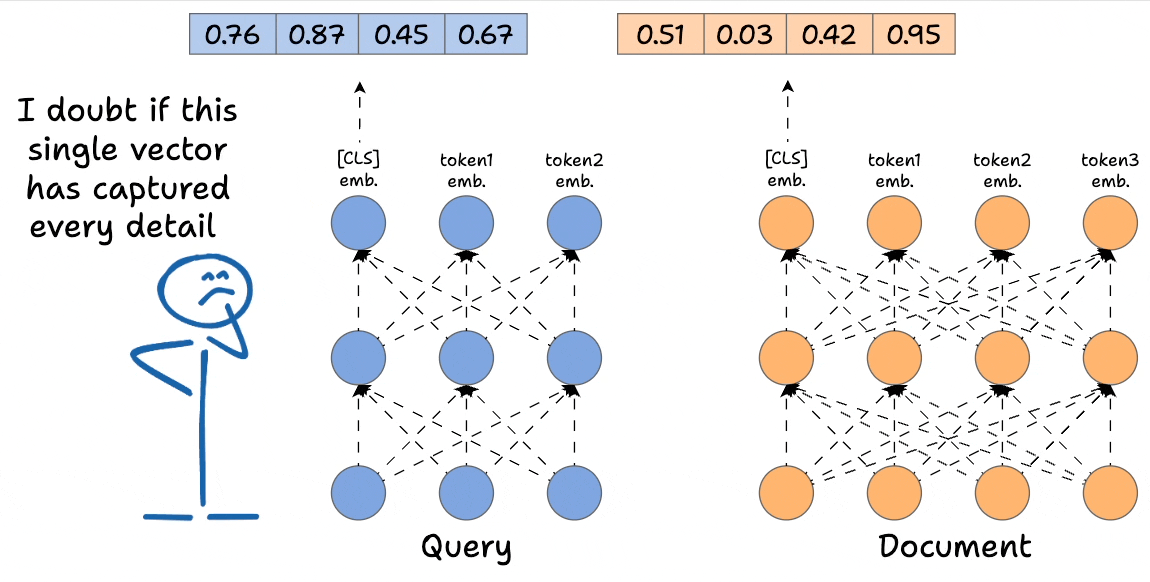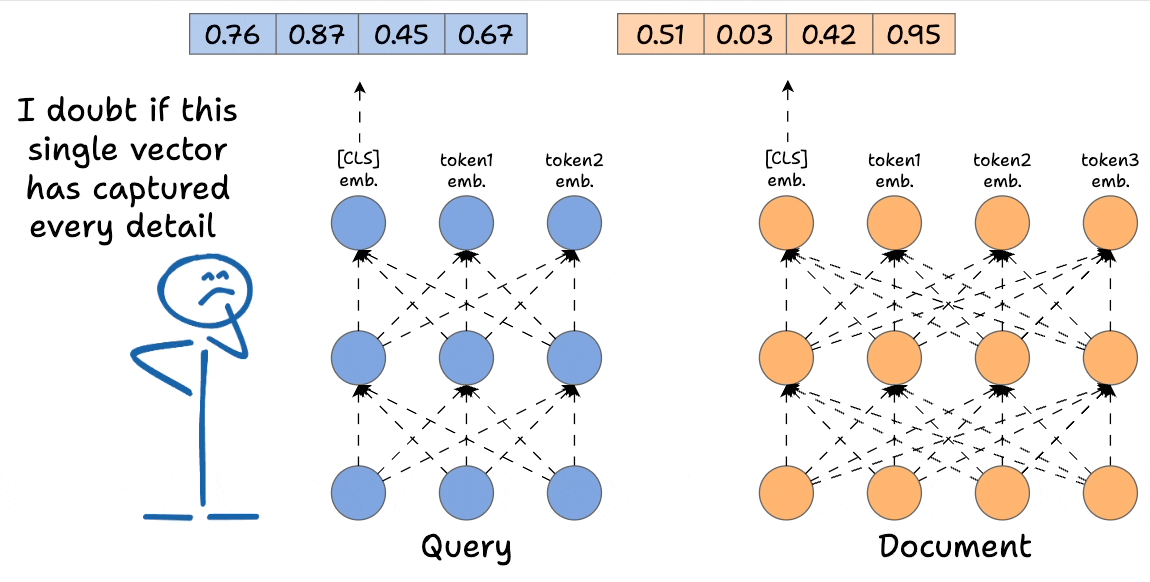
In contrast, Bi-encoders process the query and the document independently. The way it works is demonstrated below:
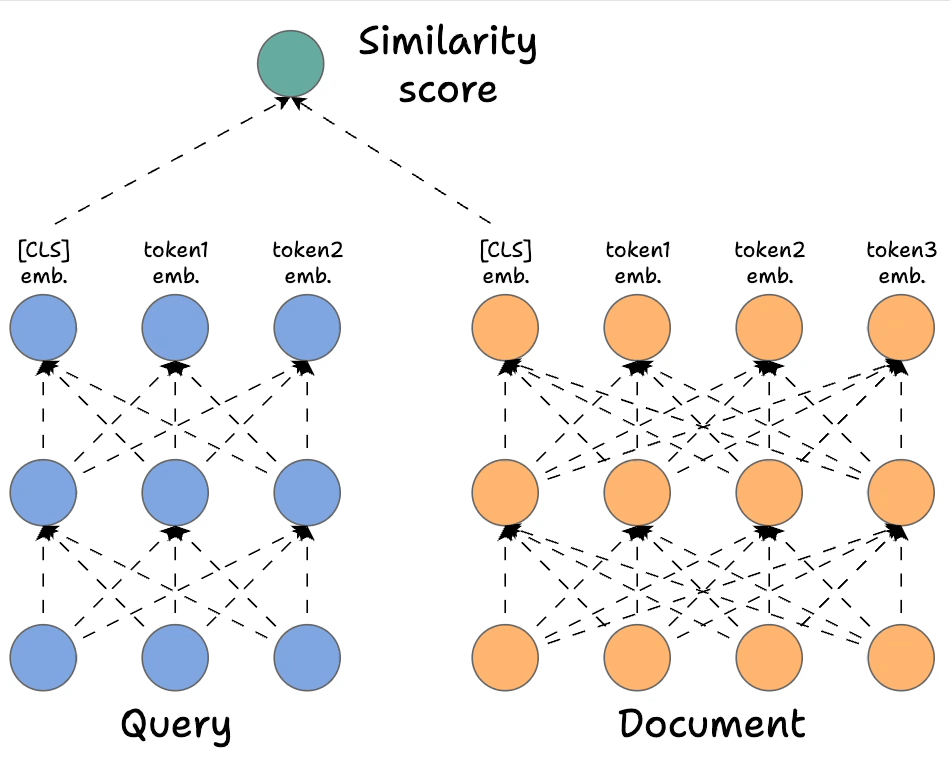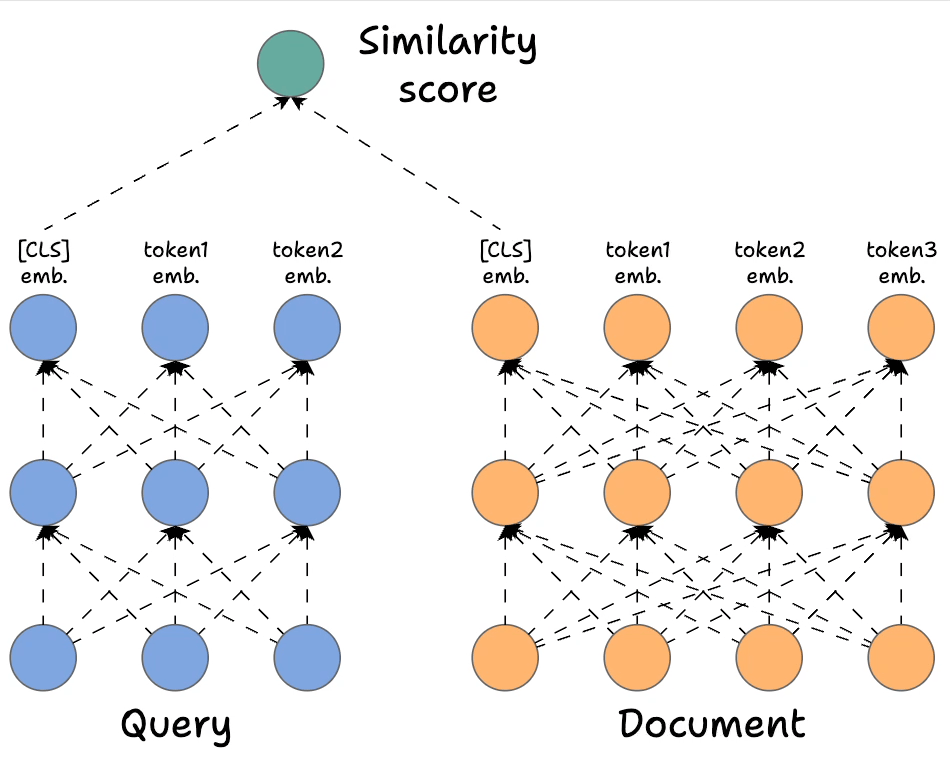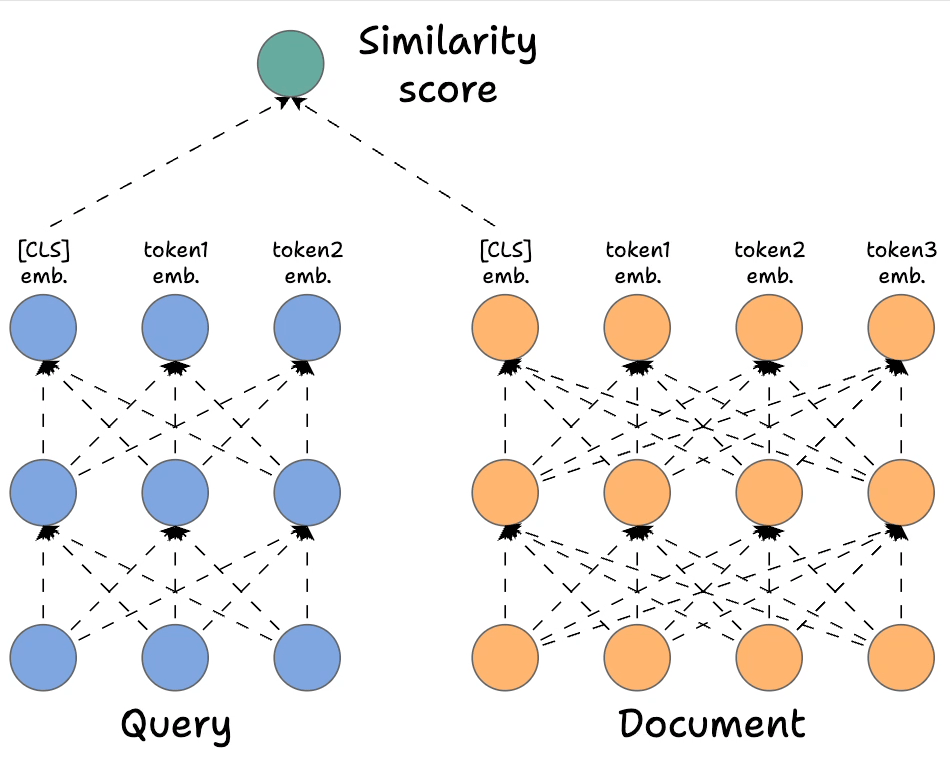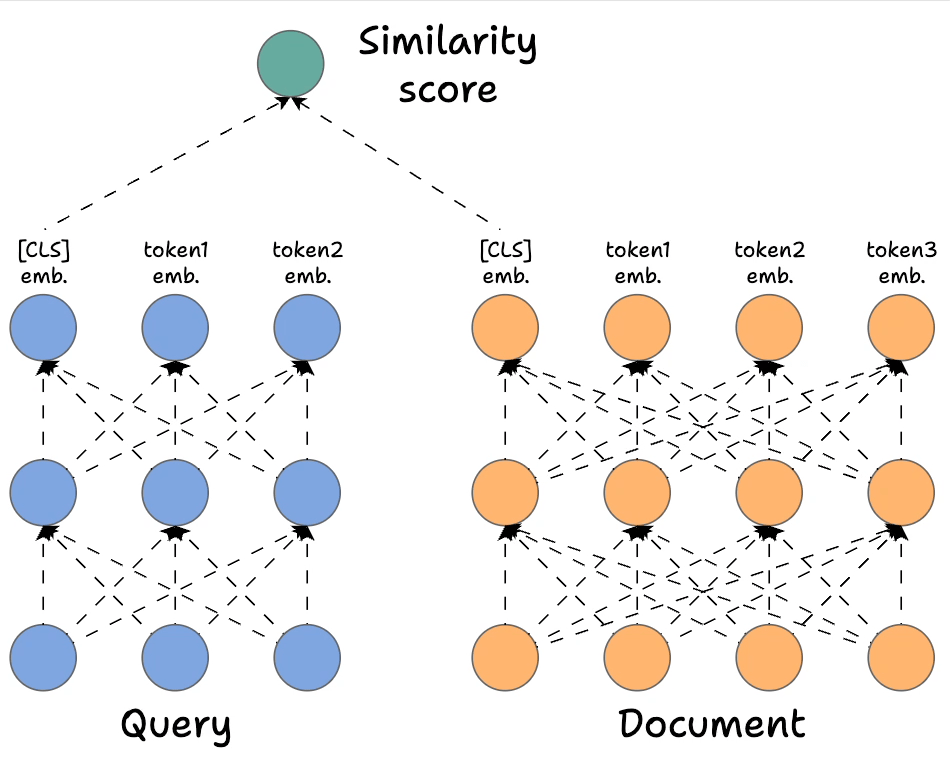
- We separately encode the query and the documents. To elaborate, in the network above, we have the query, which is encoded with a BERT-like model, and similarly, we have the document encoded with a BERT-like model. Also, notice how many
- We get rid of all the output states from the document and the query except the first one (which is also called the
[CLS]token). - Next, we generate the score using the DOT product of the above two vectors.
Of course, this approach will be highly scalable since we can now encode all the documents offline. During query time, we only need to generate one single query vector to get the final representation above the [CLS] token. Next, we can do a dot product with all documents.
However, it's extremely limited in terms of the query document interactions that cross-encoders provide since we do not have any token-level interactions left like with cross-encoders.
More specifically, we simply hope that the entire information about the query and the document is well summarized in our single vector representations corresponding to the [CLS] token, and in practice, this will result in a significant loss of expressivity for the model.
We covered these two architectures in much more detail below (with implementation), so if you haven't read it yet, I would highly recommend it.
That said, both methods have their place in NLP tasks, but the trade-off between efficiency and accuracy remains a challenge.
An ideal approach would be to combine the accuracy of Cross-encoders with the efficiency of Bi-encoders.
This is precisely what ColBERT aims to achieve, which is the focus of this article.
In this article, we’ll introduce ColBERT, a (somewhat) hybrid approach that tries to mimic the behavior of cross-encoders while also ensuring the network is as scalable as the Bi-encoders to quickly and effectively handle inference, leading to a solution that maximizes both performance and scalability.
First, we shall understand how both of these models work, and then we will look at a practical implementation of this strategy in RAG systems, along with some nuances that you need to be careful about when building RAG systems with ColBERT.
Let's begin!
ColBERT
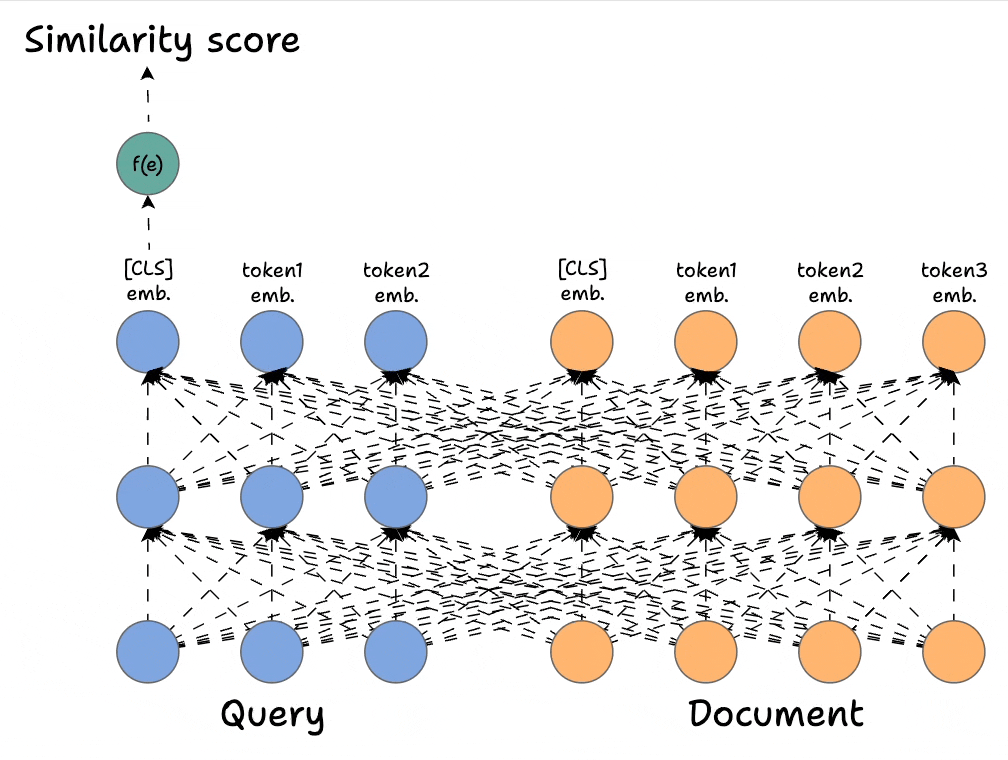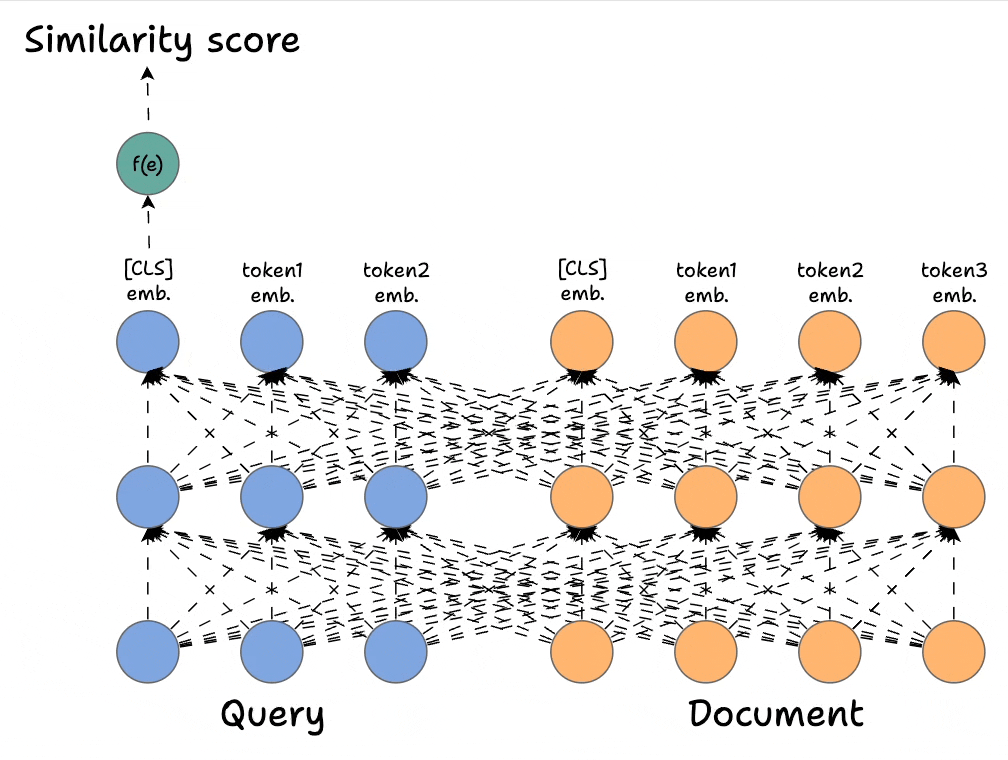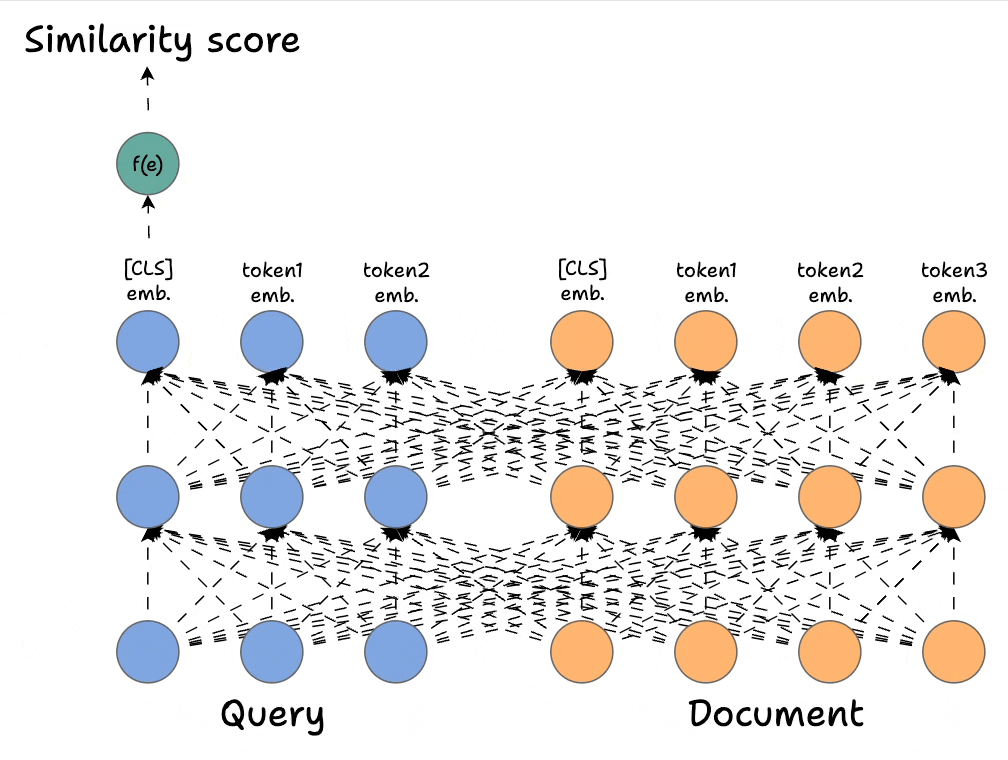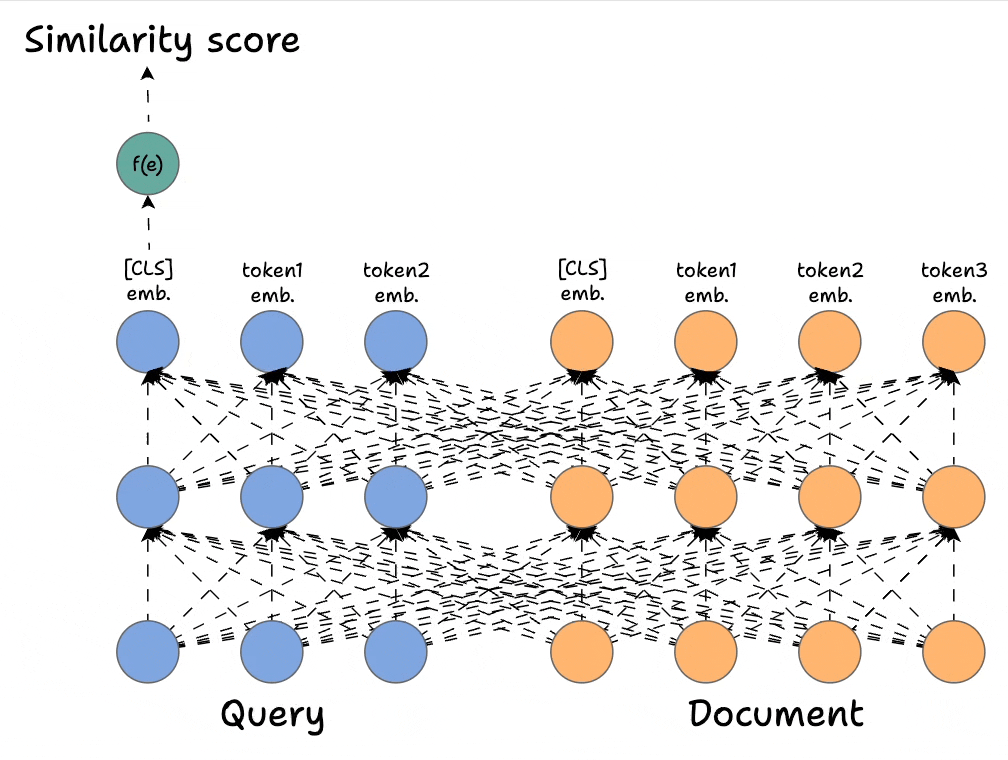
ColBERT stands for Contextualized Late interaction with BERT (ColBERT). The term itself should explain what goes inside this architecture:
- Contextualized → This should mean it retains the contextualized nature of token embeddings.
- Late interaction → There should be some sort of interaction (like in cross-encoders) but one that's happening later in the architecture to avoid the complexity of using cross-encoders.
Internal details
Here's how it works:
- First, we encode the query and the document using Bert (or a similar model), which produces token-level embeddings for the query and document:
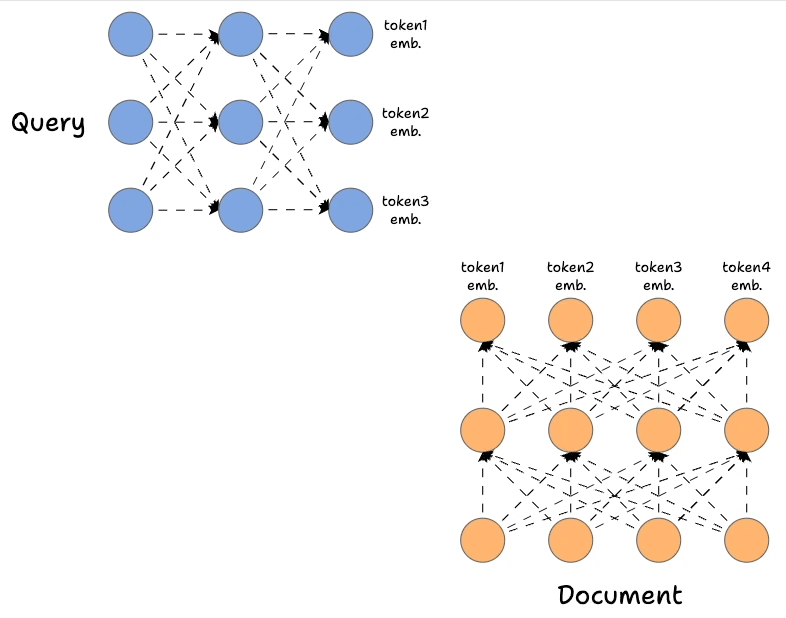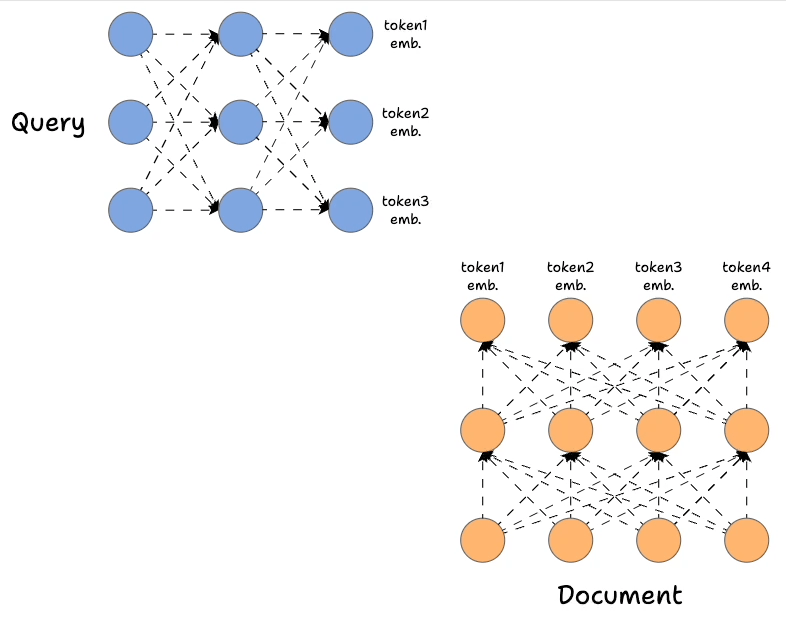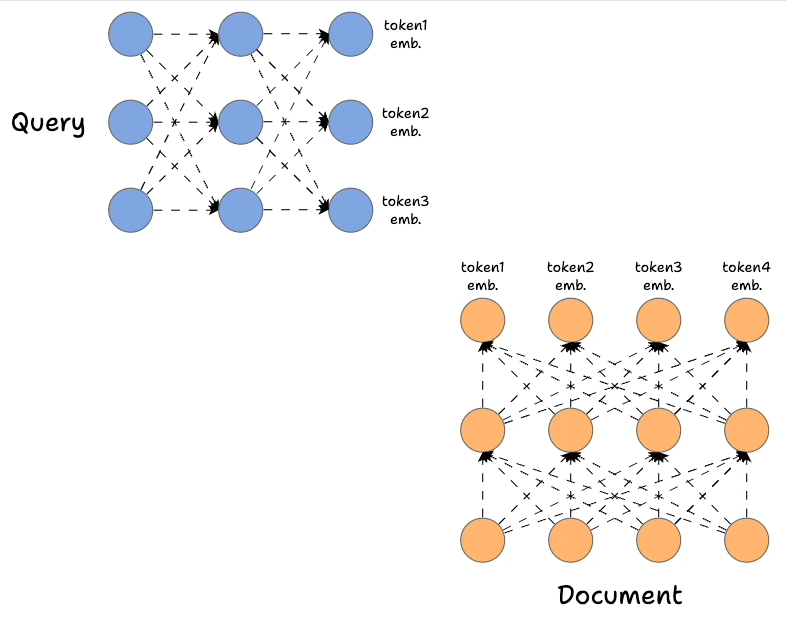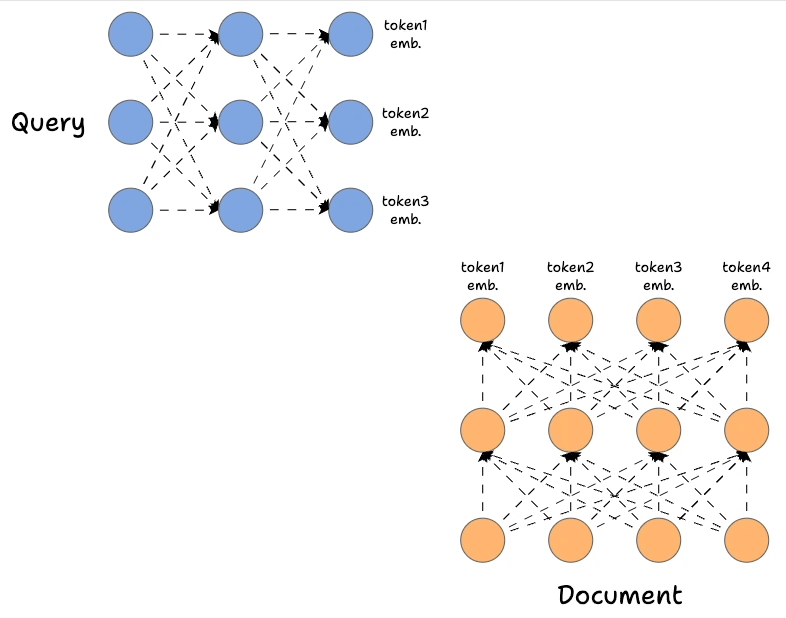
- Earlier, we only used the first output state, but here, we shall utilize all the output states from the encoder networks.