A Crash Course on Building RAG Systems – Part 3 (With Implementation)
A deep dive into making RAG systems faster (with implementations).
Introduction
So far, we have discussed two key aspects of RAG systems in this crash course:
- In Part 1, we covered how to build RAG systems, introducing you to the foundational components that make these systems work.
- In Part 2, we learned how to evaluate RAG systems, exploring essential metrics and methodologies to measure their accuracy and relevance.
But we aren’t done yet.
See, even with a robust vector database and careful evaluation, RAG systems can suffer from latency issues (slow retrieval, to be specific).
Several factors contribute to this slowness, such as the size of the embeddings, the complexity of retrieval operations and the underlying algorithm used (which we discussed in the vector database article), and the computational demands of large-scale vector similarity searches.
Thus, optimizing is a critical consideration if you’re aiming to deploy these systems or even use them for internal purposes.
This is precisely what we’ll discuss in this part (Part 3 of our RAG series)—how to optimize RAG systems for speed and make them practically useful.
More specifically, we need to learn techniques to reduce the memory footprint and computational load of the system, which can deliver faster retrieval and inference without compromising too much on accuracy.
Let's dive in!
Traditional RAG
The RAG implementations we have done in Part 1 and Part 2 primarily used a functional approach.
This time, let’s take a modular approach (object-oriented programming based) to build our RAG system by encapsulating different components of RAG (retrieval, and generation) into classes.
First, we shall start with a small dataset (about 18k vectors) so that you can try it hands-on, even on your personal computers.
Dataset preparation
Before diving into building the RAG system, we need to prepare a dataset.
For this tutorial, we’ll use the SQuAD dataset (Stanford Question Answering Dataset), which contains questions, contexts, and answers.
While the full dataset includes tens of thousands of entries, we’ll only gather the contexts, embed them, and store them in our vector database since the context is the only thing we have to rely on as a "knowledge base” we need to fetch answers from.
Here’s the code to load and preprocess this dataset:
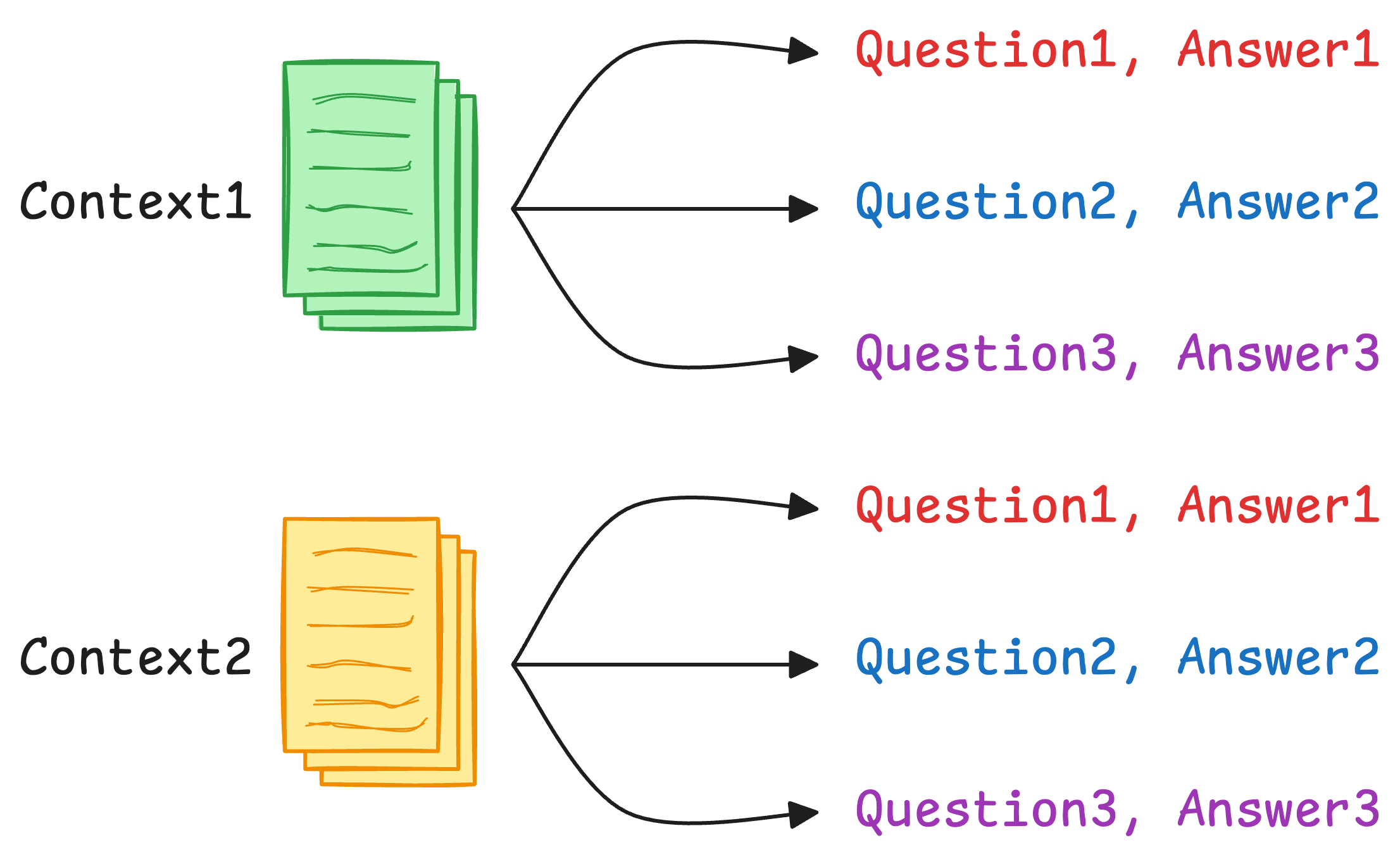
- First, we download the dataset using the
datasetslibrary (make sure it is installed—pip install datasets). - In this dataset, each context has multiple different question and answer pairs. That is why our
dataobject will have repeated contexts. Thus, we only extract uniquecontextfields. These individual contexts will later be embedded and stored in a vector database.
Printing one of the elements of the texts list, we get:
Embed dataset
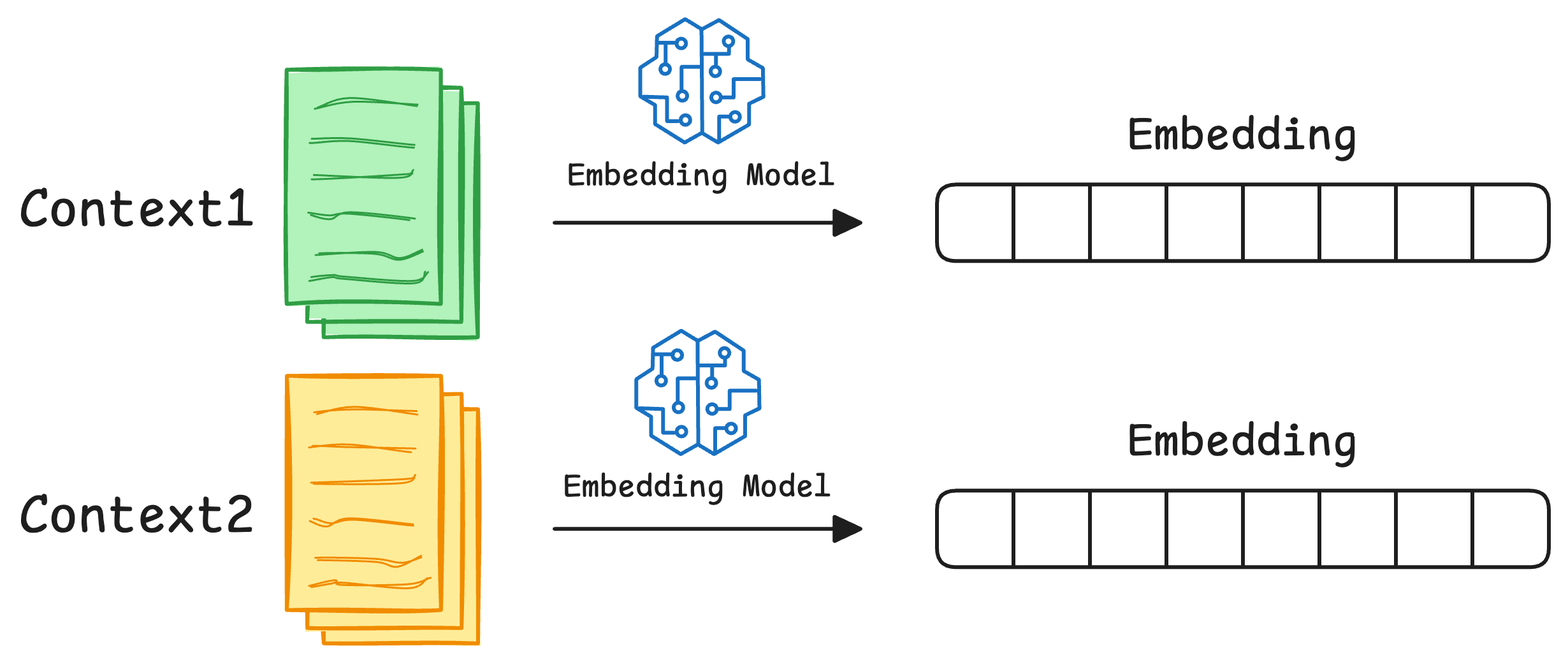
Now that we have our dataset, we need to create its embeddings. So in this case, we shall define an embedding on context-level, i.e., each element of the above texts list will be embedded into a single vector.
We’ll encapsulate this functionality in an EmbedData class. This class will:
- Handle the loading of an embedding model.
- Provide methods to batch-process the dataset for efficient embedding generation.
- Store the generated embeddings for use in the retrieval system.
First, let's define the EmbedData class and the __init__ method with all the necessary instance-level attributes.
In the above code:
self.embed_model_namestores the embedding model's name for reference.self.embed_modelwill store the embedding model returned by a method we shall define shortly that will load the embedding model and return it.self.batch_sizespecifies the size of each batch for embedding.self.embeddingsis a list to store the generated embeddings.
Next, let's define the method to load the embedding model:
While the above part is intuitive and self-explanatory, cache_folder='./hf_cache' specifies a local folder to cache the model for future use so that we don't have to redownload it later.
Next, we need a method to actually use the above embedding model and generate embeddings for a batch of data. The generate_embedding method defined below does that:
The context parameter here is a list of passages we saw earlier.
The method accepts the list and returns a list of embeddings using the get_text_embedding_batch method of the embedding model.
Finally, we have an embed method that orchestrates the embedding process for all contexts by batching the process and invoking the generate_embedding method for each batch.
- First, we store the full list of
contextsas an attribute (self.contexts). - Next, we iterate through the
contextslist in batches using thebatch_iteratefunction. For each batch- We invoke the
generate_embeddingto create embeddings. - We append the generated embeddings to the
self.embeddingslist.
- We invoke the
- After the process completes,
self.embeddingscontains vector representations of all input contexts.
Almost done!
Finally, we instantiate this class as follows and generate embeddings:
The above process will take some time, but once it's done, you can move to the next step.
That said, if you want to save some time, you can download the pickle file below, place it in your current directory, and run the following code instead of the above code: