A Crash Course on Building RAG Systems – Part 9 (With Implementation)
A deep dive into ColPali for building vision-driven RAG systems (with implementation).
Introduction
Coming into Part 9, we have almost all the boxes checked to build powerful RAG systems:
- We understand how to build typical text-only RAG systems (covered in Part 1) and their limitations.
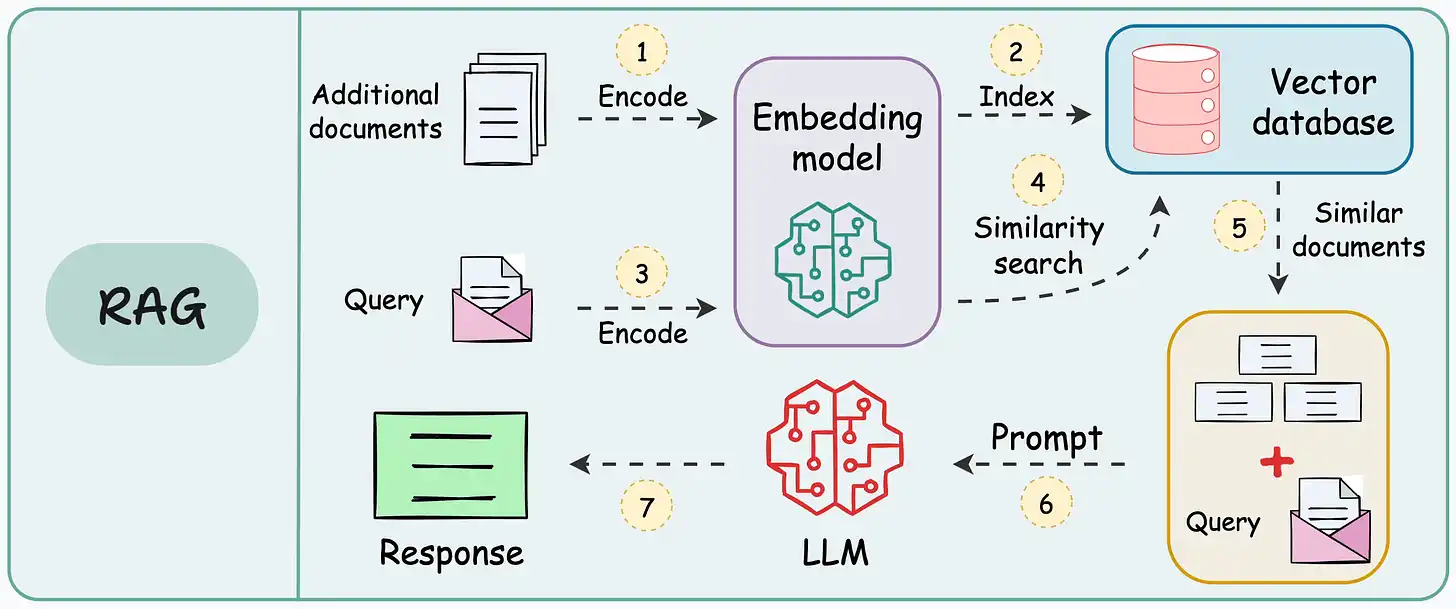
- We understand the principles of RAG evaluation and optimization (Parts 2 and 3), ensuring our systems are fast, accurate, and scalable.
- We explored multimodal RAG systems (in Parts 4, 5, and 6) that integrate text, images, and even structured data to handle real-world complexity.
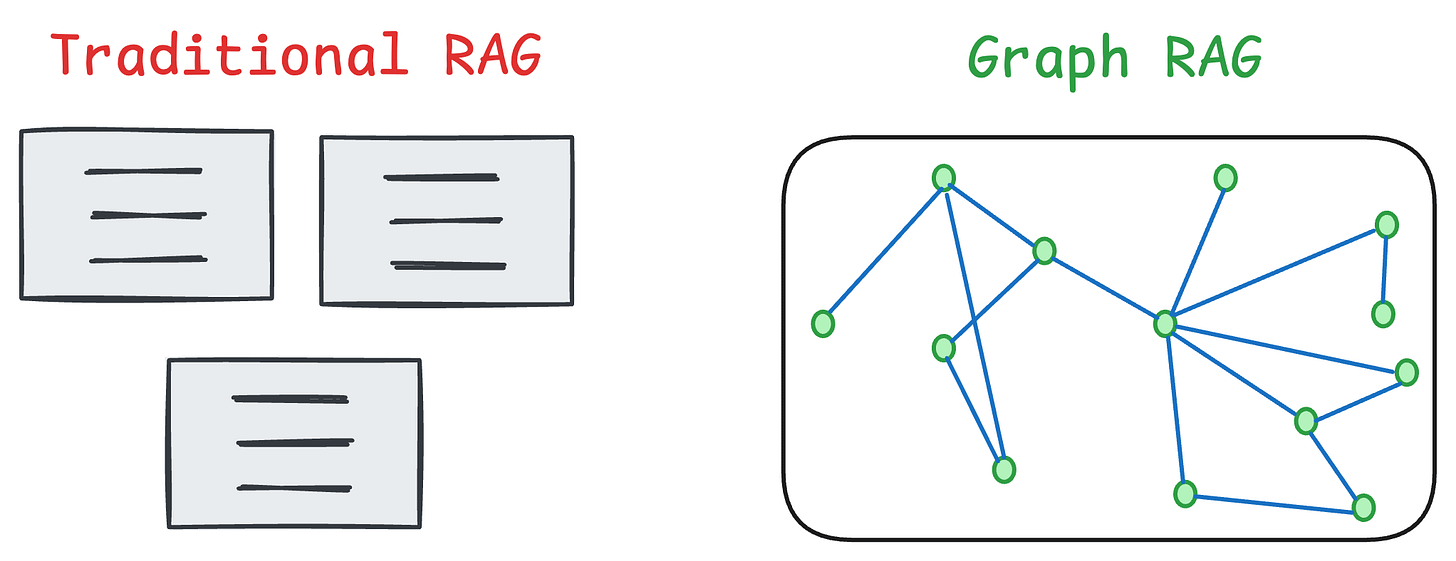
- We know how to build Graph RAG systems to improve RAG systems by providing them structured data (in Part 7).
- And most recently, in Part 8, we dived deep into ColBERT, which introduced the concept of late interaction to enhance retrieval and reranking accuracy over typical systems like bi-encoders and cross-encoders.
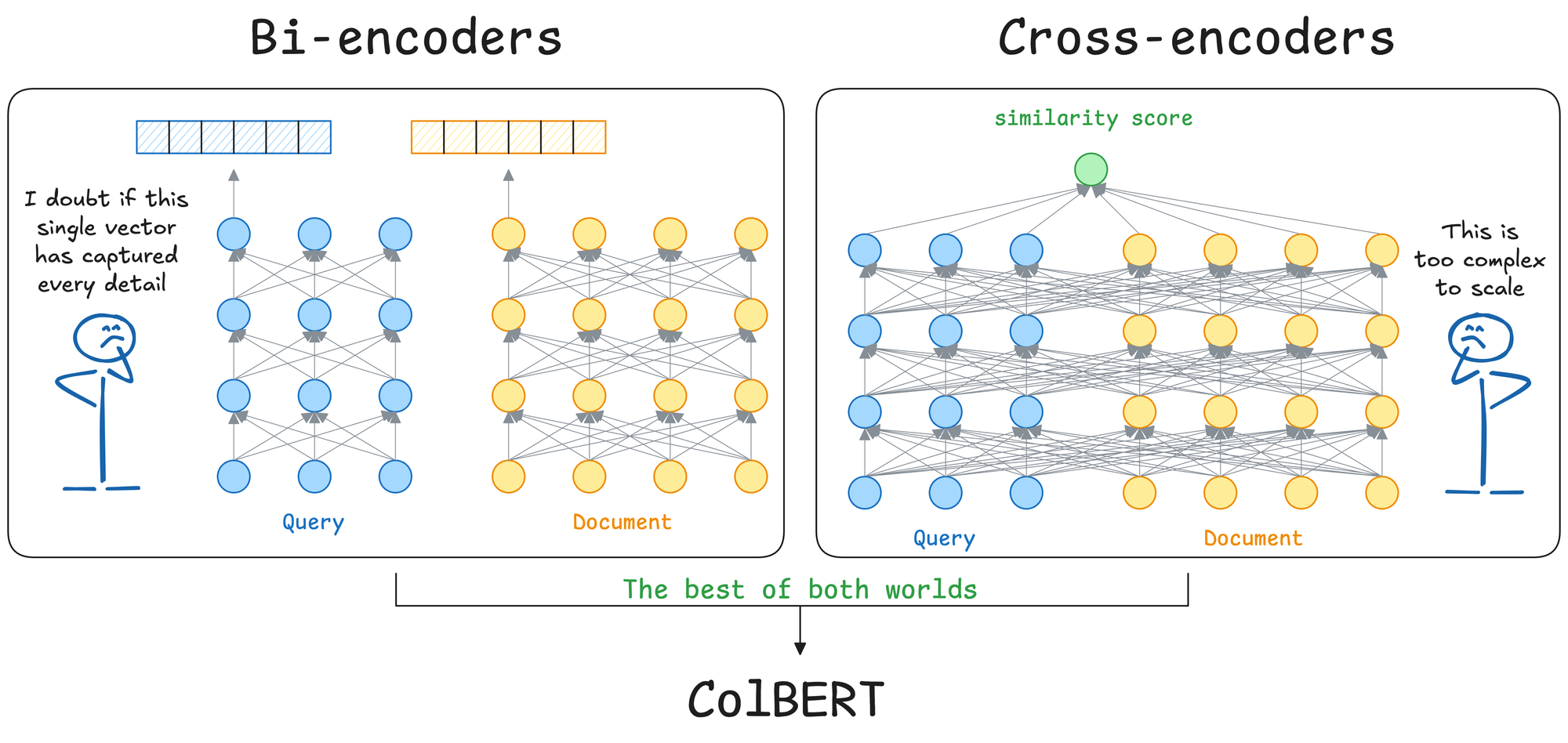
In Part 9, it’s time to bring together all of that knowledge (except Graph RAG) to build an extremely powerful RAG system that is powered by ColPali.
More specifically:
- We'll understand the motivation for ColPali and how it addresses the limitations of systems we have built in previous parts.
- Next, we'll do an architectural breakdown of ColPali.
- Moving on, we'll implement a ColPali-driven RAG system on complex multimodal use cases.
- Finally, we shall also optimize the above system to make retrieval much faster using binary quantization.
Like all previous parts, this will again be an extremely practical and intuitive deep dive so let's dive in.
Motivation
To understand the motivation behind ColPali, let's consider a real-life analogy.
Real-life analogy
Imagine you (as a human) were tasked to perform retrieval-augmented generation (RAG) manually. Someone hands you a query, and your job is to find the relevant information from a corpus (say, the "Attention is All You Need" paper) to produce a coherent answer.

Before reading ahead, think about the steps you would take to solve this.
Now, here’s how your thought process might look:
Step 1) Understand the document
First and foremost, you will build an understanding of the overall document, and what it is talking about and then prepare some mental representation of the sections of this document.

This will happen by visually scanning and reading the document, and comprehending text, tables, and images.
Also, since you are using your vision capabilities, you will also break down the layout of the document. For instance, if there are multiple columns in the document, your inherent vision capabilities will help you decipher that as well.
Step 2) Understand the query context
Next, you'd break down the query, figure out its key components, and determine what type of information is needed.
For example, if the query is: “Query: What are the components of Transformer architecture?.”

Looking at this query, you'd try to connect the words to the relevant parts of the documents to figure out the area in the document that answers this query.
Step 3) Search across the document
Next, you’d look (visually, again) at the text from the original paper, accompanying diagrams, and perhaps some simplified blog explanations or structured summaries.
These sources may span modalities like text, images (e.g., diagrams of the transformer architecture), and structured data (tables or bullet points).
Step 4) Link related pieces of information
After identifying relevant chunks of information from the document, you'd begin forming connections between them.
For instance, you may find a section of the paper that lists the core components of the transformer: “The transformer architecture consists of an encoder and decoder, each built with self-attention mechanisms and feedforward neural networks.”

Next, you locate a diagram that visually illustrates the flow between the encoder and decoder, showing layers like multi-head attention, positional encoding, and residual connections.