Reinforcement Learning Course
RLHF: Aligning Language Models with Human Feedback
Part 9: From human preferences to a trained reward signal, and the four-model PPO pipeline.

401 posts published
Part 9: From human preferences to a trained reward signal, and the four-model PPO pipeline.
RL Part 8: Trust regions, the clipped surrogate, and the workhorse of modern RL.
RL Part 7: Learning the policy directly, from REINFORCE to actor-critic.
RL Part 6: From linear features to neural networks, and the engineering choices that makes deep value-based RL possible.
RL Part 5: From tables to parameterized value functions.
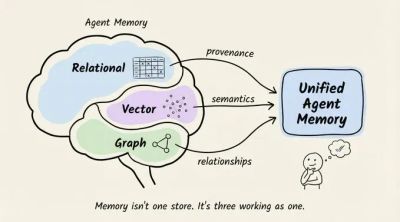
A deep dive on building production-grade memory for Agents.
RL Part 4: Learning value functions and policies without a model. Monte Carlo methods, TD(0), SARSA, Q-learning, and the bias-variance bridge between them.
Everything you need to understand and customize Hermes Agent.
...explained with code and tradeoffs.
RL Part 3: Bellman expectation and optimality equations, policy iteration, value iteration, and why dynamic programming needs a model.
RL Part 2: Markov decision processes, returns, policies, and value functions.
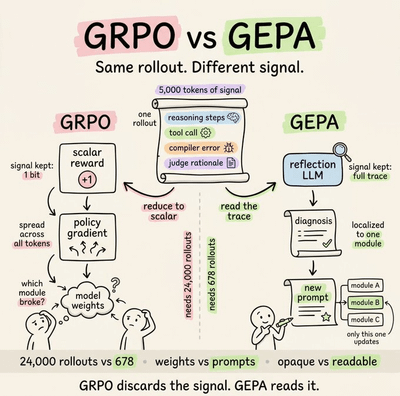
Berkeley beat GRPO by 10 points with 35× fewer rollouts and no GPU training,
The era of not writing custom reward functions.
RL Part 1: Agents, environments, rewards, and why RL is different from supervised learning.
...using Karpathy's context engineering principles!
Diffusion LLMs Part 2: How dLLMs scale to 100B parameters, the inference stack that makes them fast, hands-on code, and when to actually use them.
...explained with usage.
...explained with exact prompts and usage!
A first-principles walk through agent memory (open-source).
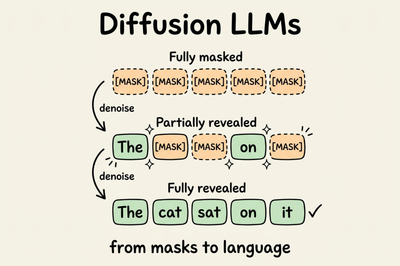
Diffusion LLMs Part 1: Understanding how diffusion language models work from first principles, the math behind masked diffusion, and why they represent a fundamentally different approach to text generation.
Reduce token costs and improve performance...and how to use it with Claude!
A deep dive into what Anthropic, OpenAI, Perplexity and LangChain are actually building.
An exploration of real-world MLOps and LLMOps case studies, examining the importance of reliable ML and AI engineering and their significance for business outcomes.
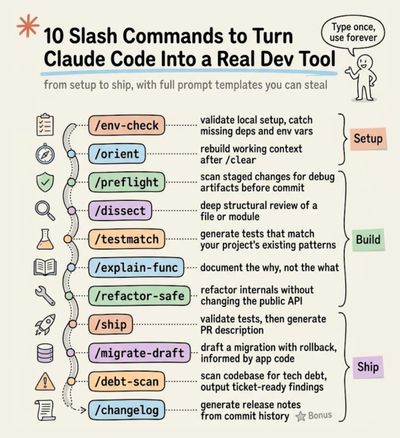
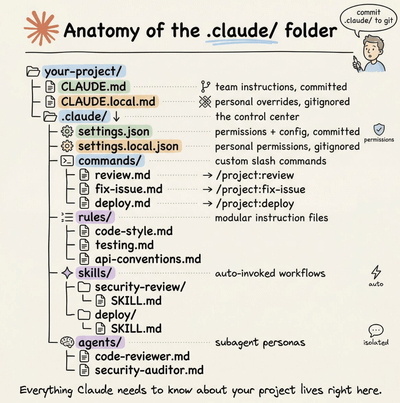
A complete guide to CLAUDE.md, custom commands, skills, agents, and permissions, and how to set them up properly.
LLMOps Part 14: An overview of the fundamentals of LLM serving, including API-based access, inference with vLLM, and practical decisions.
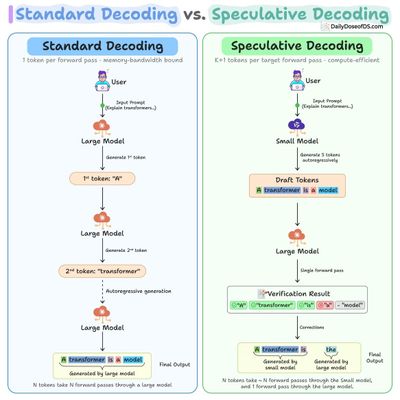
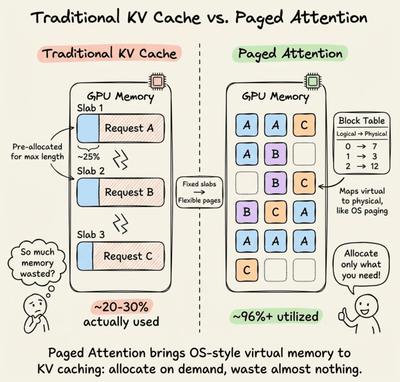
LLMOps Part 13: Exploring the mechanics of LLM inference, from prefill and decode phases to KV caching, batching, and optimization techniques that improve latency and throughput.
...explained visually.
LLMOps Part 12: Understanding LLM fine-tuning, parameter-efficient methods like LoRA and QLoRA, and alignment techniques such as RLHF, DPO, and GRPO.
...explained visually!
![[Hands-on] Agent memory is only as good as its schema](https://storage.ghost.io/c/3f/df/3fdf6ed2-17ac-4b12-a693-8078bd13e748/content/images/size/w400/2026/06/990fe7c9-7c72-49c9-8fb4-ea0b9cc8e01b.jpg)