LLMs
What is Temperature in LLMs?
Predictable ↔ Random.

Avi Chawla
Predictable ↔ Random.

TODAY'S ISSUE
AI systems love neatly formatted data—Markdowns, Structured data, HTML etc.
And now it is easier than ever to produce LLM-digestible data!
Firecrawl is an open-source framework that takes a URL, crawls it, and converts it into a clean markdown or structured format. Star the repo below:
Why Firecrawl?
If you prefer FireCrawl's managed service, you can use the code "DDODS" for a 10% discount code here →
Thanks to Firecrawl for partnering with us today.
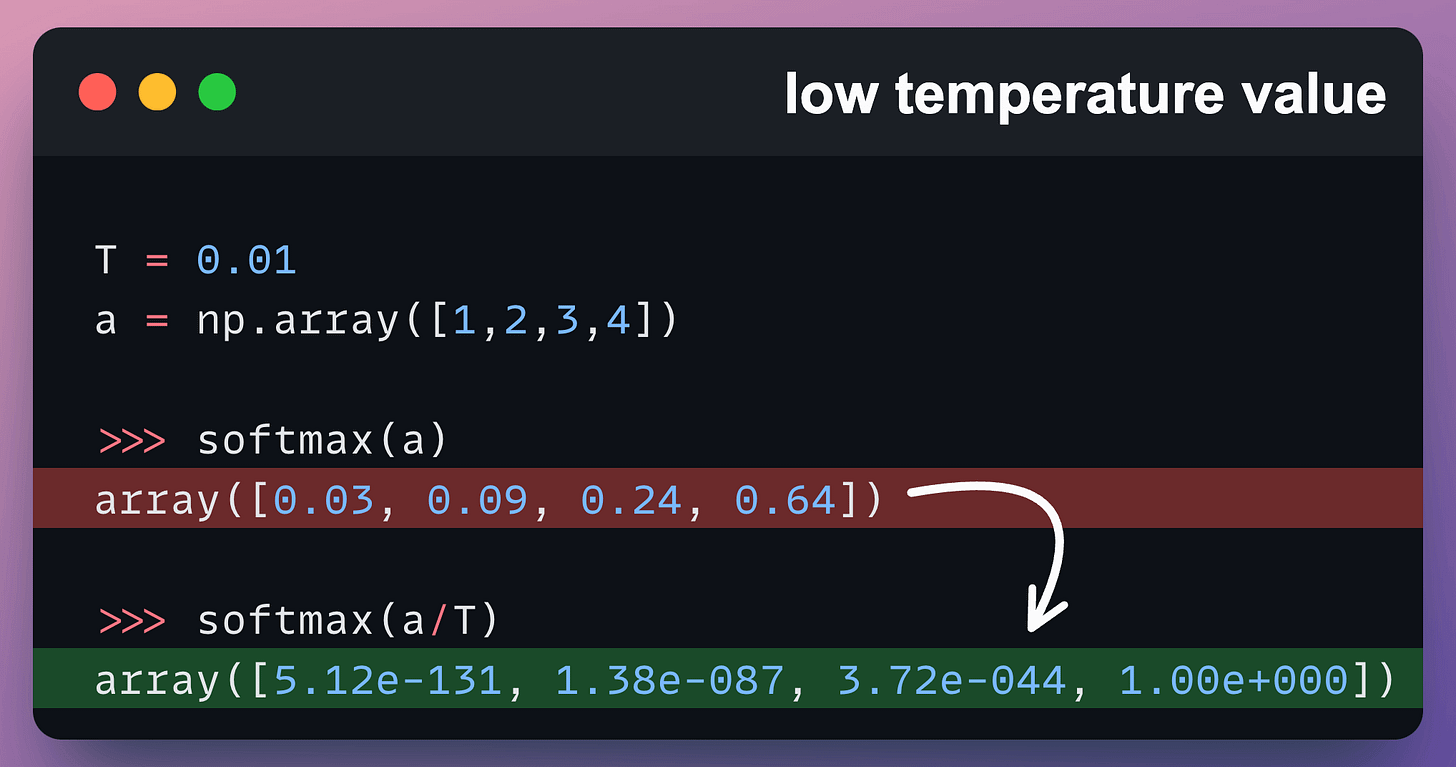
A low temperate value produces identical responses from the LLM (shown below):

But a high temperate value produces gibberish.

What exactly is temperature in LLMs?
Let’s understand this today!
Traditional classification models use softmax to generate the final prediction from logits over all classes. In LLMs, the output layer spans the entire vocabulary.

The difference is that a traditional classification model predicts the class with the highest softmax score, which makes it deterministic.
But LLMs sample the prediction from these softmax probabilities:
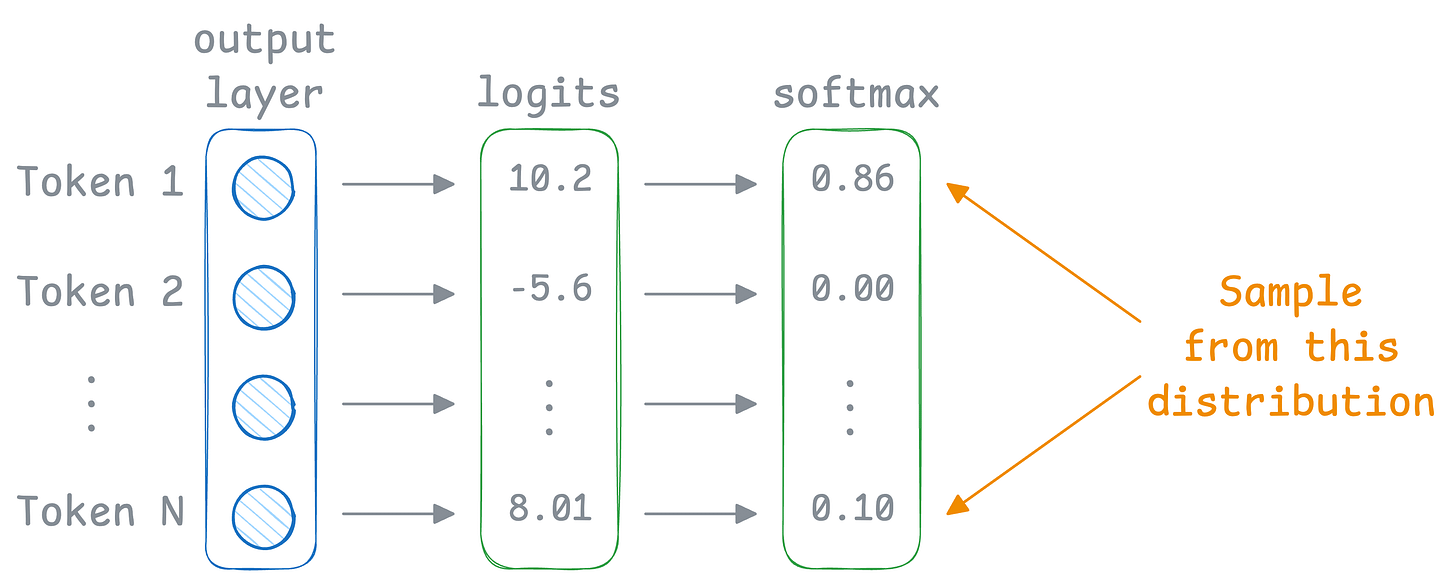
Thus, even though “Token 1” has the highest probability of being selected (0.86), it may not be chosen as the next token since we are sampling.
Temperature introduces the following tweak in the softmax function, which, in turn, influences the sampling process:
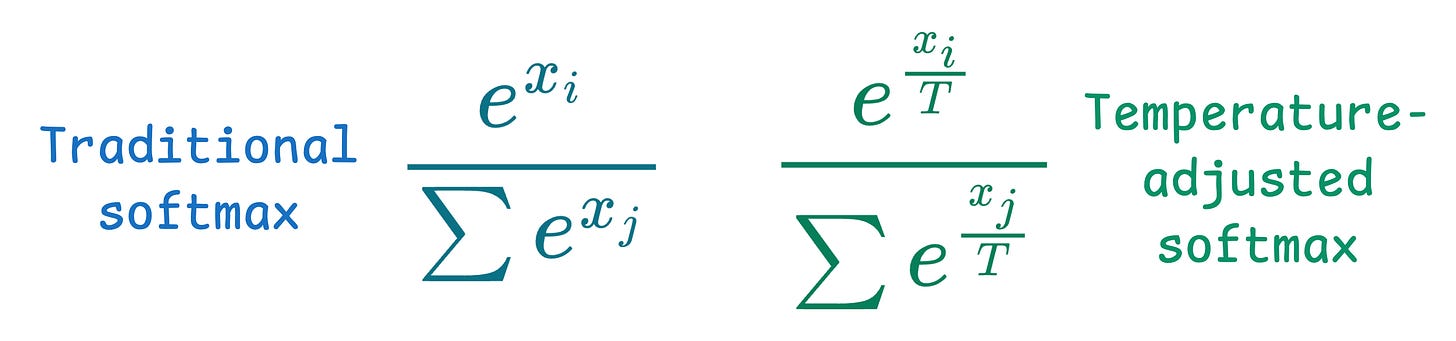
1) If the temperature is low, the probabilities look more like a max value instead of a “soft-max” value.
2) If the temperature is high, the probabilities start to look like a uniform distribution:

A quick note: In practice, the model can generate different outputs even if temperature=0. This is because there are still several other sources of randomness, such as race conditions in multithreaded code.
Here are some best practices for using temperature:
And this explains the objective behind temperature in LLMs.
That said, any AI system will only be as good as the data going in.
FireCrawl helps you ensure that your AI systems always receive neatly formatted data—Markdowns, Structured data, HTML, etc.
If you prefer FireCrawl's managed service, you can use the code “DDODS” for a 10% discount code here →
👉 Over to you: How do you determine an ideal value of temperature?
RAG is a key NLP system that got massive attention due to one of the key challenges it solved around LLMs.
More specifically, if you know how to build a reliable RAG system, you can bypass the challenge and cost of fine-tuning LLMs.
That’s a considerable cost saving for enterprises.
And at the end of the day, all businesses care about impact. That’s it!
Thus, the objective of this crash course is to help you implement reliable RAG systems, understand the underlying challenges, and develop expertise in building RAG apps on LLMs, which every industry cares about now.
Of course, if you have never worked with LLMs, that’s okay. We cover everything in a practical and beginner-friendly way.