LLMs
RAG vs Graph RAG
...explained visually.

Avi Chawla
...explained visually.

TODAY'S ISSUE
We created the following visual which illustrates the difference between traditional and Graph RAG.
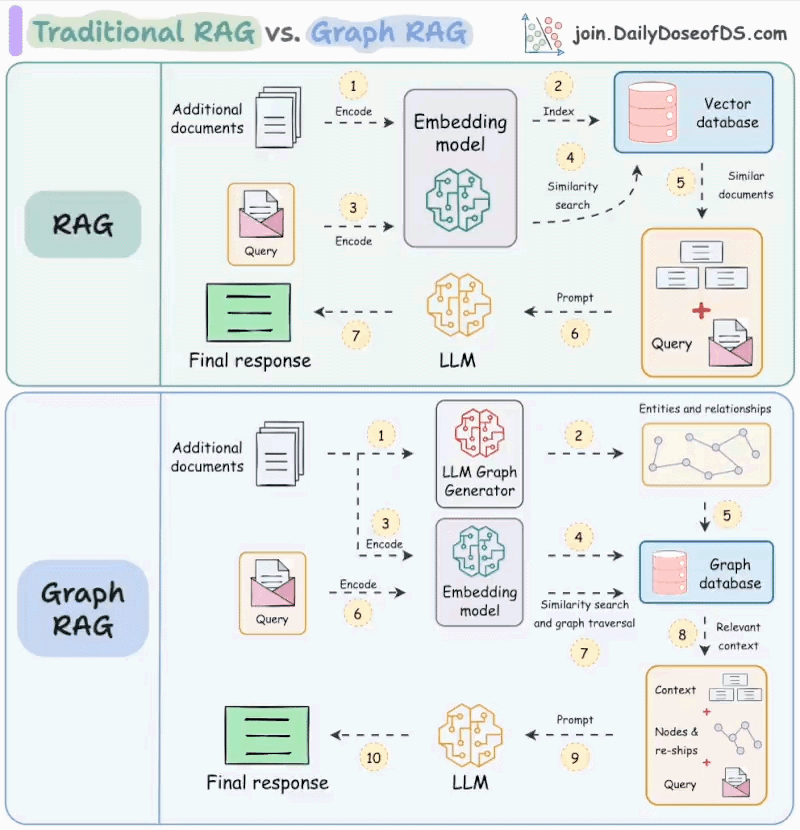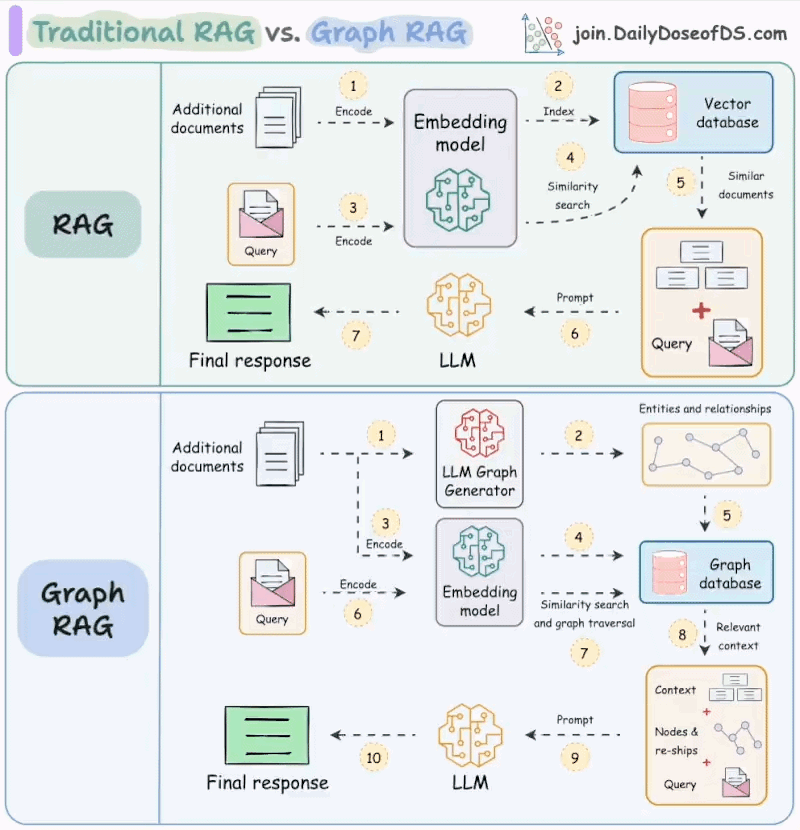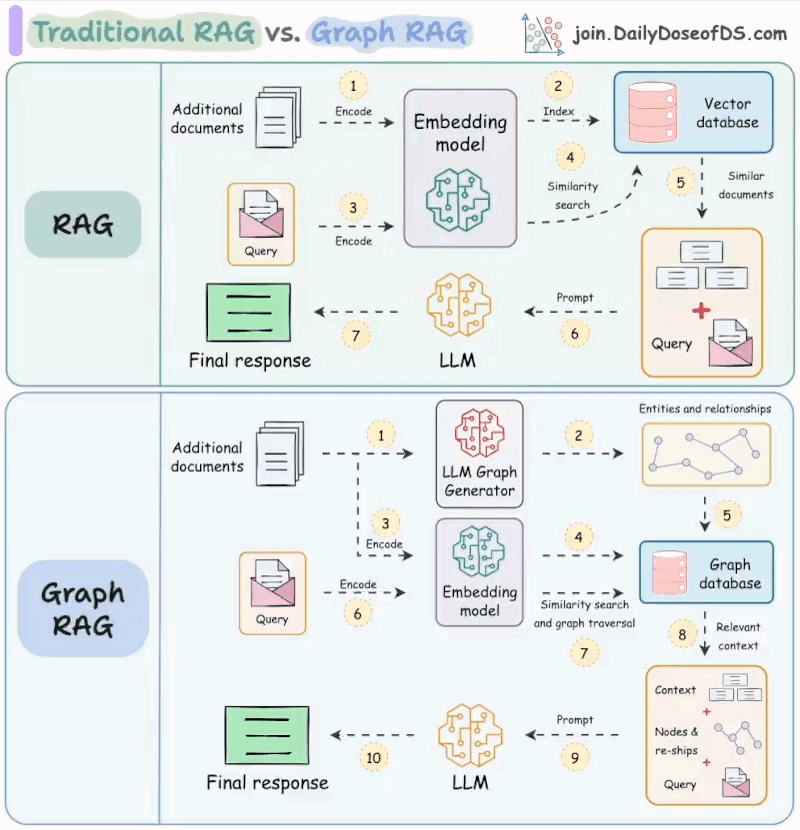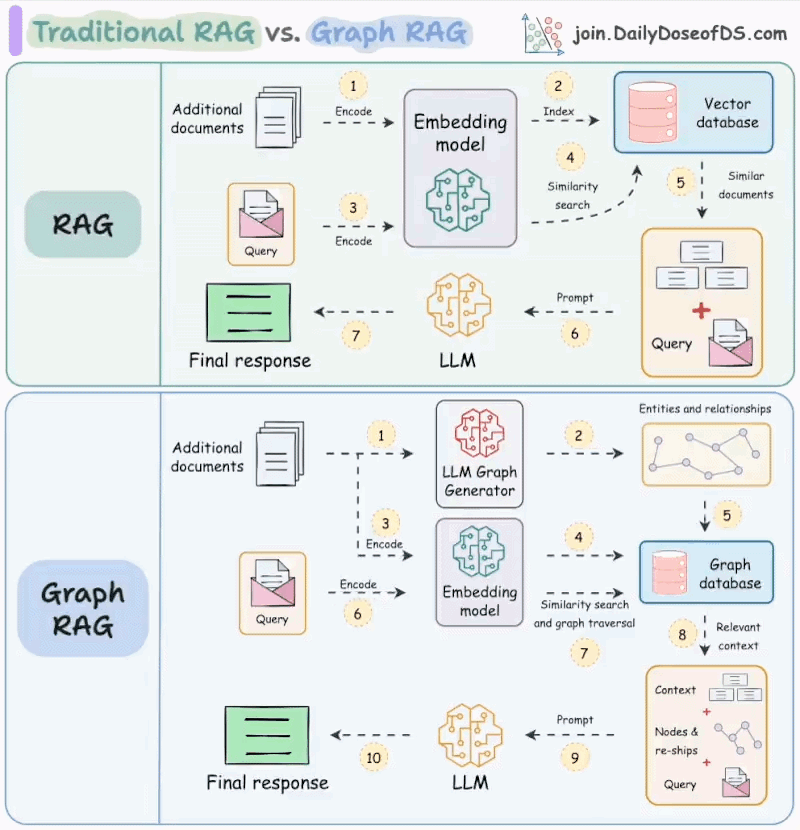
Today let’s understand how it works.
On as side note, we’ve already covered Graph RAG in much more detail with implementation in our Part 7 of our RAG crash course, read it here: Graph RAG deep dive
Imagine you have a lengthy document, such as a biography of an individual (X), where each chapter discusses one of his accomplishments, among other details.
For example:
Now, I want you to understand the next part carefully!
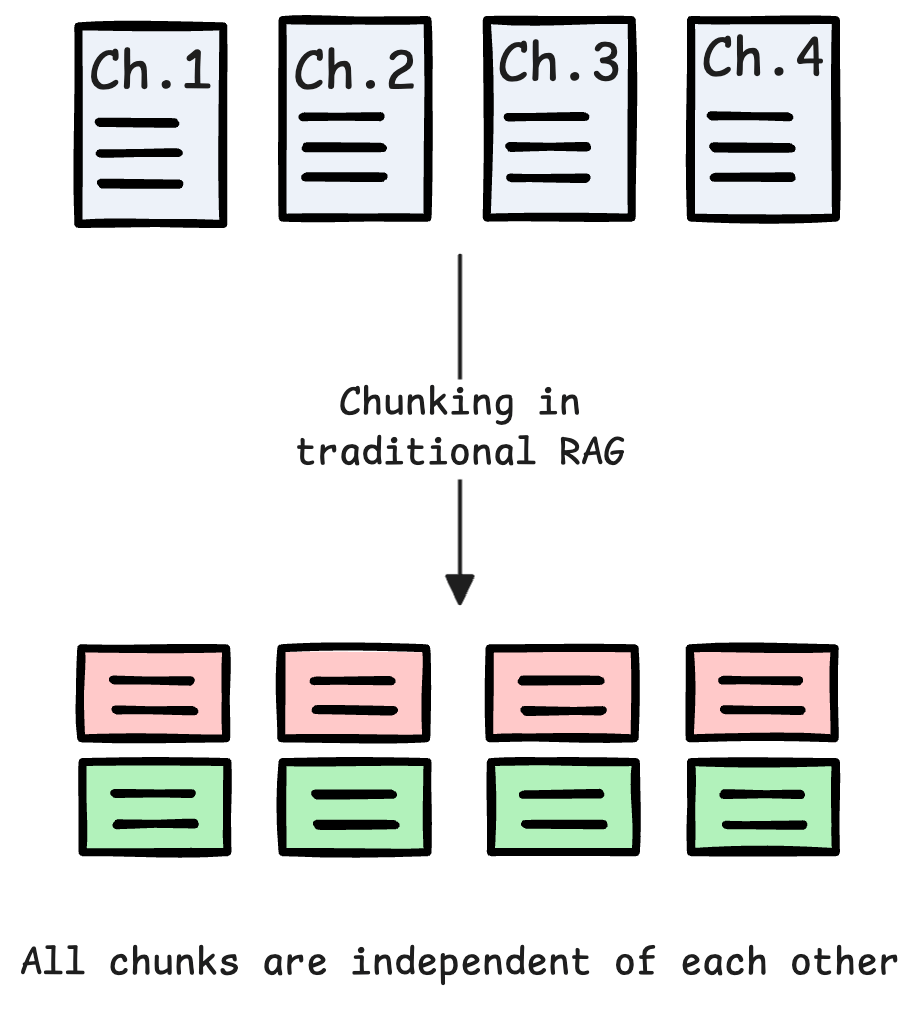
Lets say you've created a traditional RAG over this document and use it to summarise all these accomplishments.
This might not be possible with traditional retrieval as it must requires the entire context...
...but you might only be fetching some top-k relevant chunks from the vector db.
Moreover, since traditional RAG systems retrieve each chunk independently, this can often leave the LLM to infer the connections between these chunks. (provided the chunks are retrieved).
Graph RAG solves this problem.
The idea is to first create a graph (entities & relationships) from the documents and then do traversal over that graph during the retrieval phase.
Lets see how Graph RAG solves the above problems.
First, a system (typically an LLM) will create the graph by understanding the biography (unstructured text).
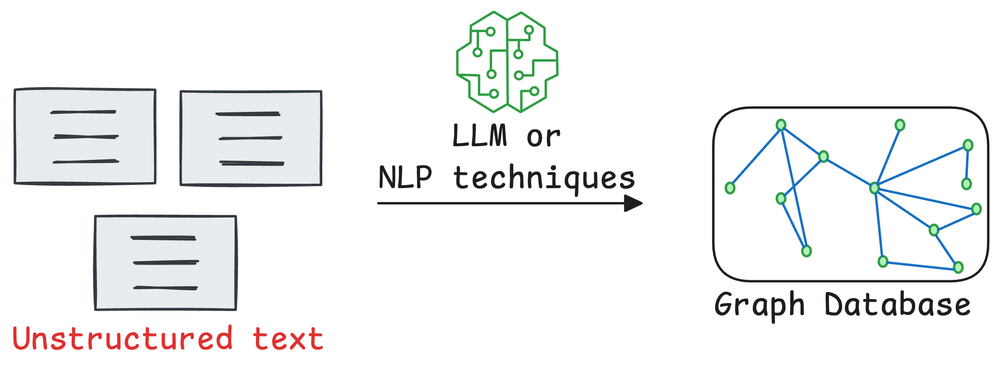
This will produce a full graph of nodes entities & relationships, and a subgraph around accomplishments will look something like this:
When summarizing these accomplishments, the retrieval phase can do a graph traversal to fetch all the relevant context related to X's accomplishments.
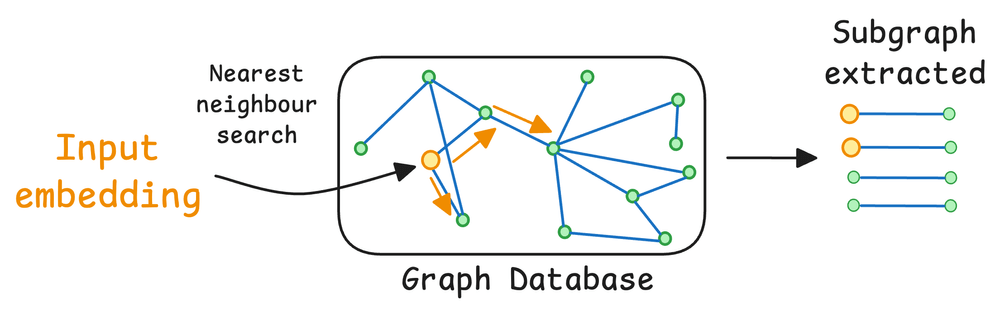
This context, when passed to the LLM, will produce a more coherent and complete answer as opposed to traditional RAG.
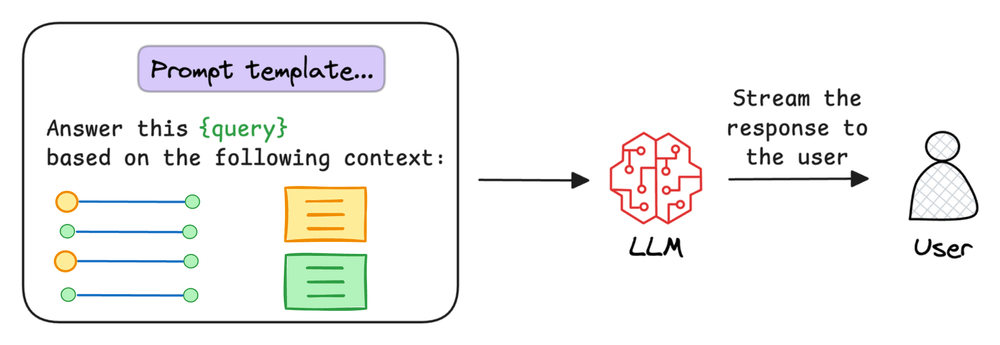
Another reason why Graph RAG systems are so effective is because LLMs are inherently adept at reasoning with structured data.
Graph RAG instills that structure into them with their retrieval mechanism.
On a side note, even search engines now actively use Graph RAG systems due to their high utility.
We’ve already covered Graph RAG in much more detail with implementation in our Part 7 of our RAG crash course, read it here: Graph RAG deep dive.
Moreover, our full RAG crash course discusses RAG from basics to beyond:
Thanks for reading.
If you look at job descriptions for Applied ML or ML engineer roles on LinkedIn, most of them demand skills like the ability to train models on large datasets:
Of course, this is not something new or emerging.
But the reason they explicitly mention “large datasets” is quite simple to understand.
Businesses have more data than ever before.
Traditional single-node model training just doesn’t work because one cannot wait months to train a model.
Distributed (or multi-GPU) training is one of the most essential ways to address this.
Here, we covered the core technicalities behind multi-GPU training, how it works under the hood, and implementation details.
We also look at the key considerations for multi-GPU (or distributed) training, which, if not addressed appropriately, may lead to suboptimal performance or slow training.