A Crash Course on Building RAG Systems – Part 4 (With Implementation)
A deep dive into handling multiple data types in RAG systems (with implementations).
Introduction
So far in this crash course series on building Retrieval-Augmented Generation (RAG) systems, we’ve logically built on the foundations laid in the previous parts, covering several essential details like:
- In Part 1, we explored the foundational components of RAG systems, providing a beginner-friendly guide to building these systems from scratch, complete with implementations.
- In Part 2, we took a deep dive into evaluating RAG systems, discussing the critical metrics and methodologies to assess their accuracy and relevance.
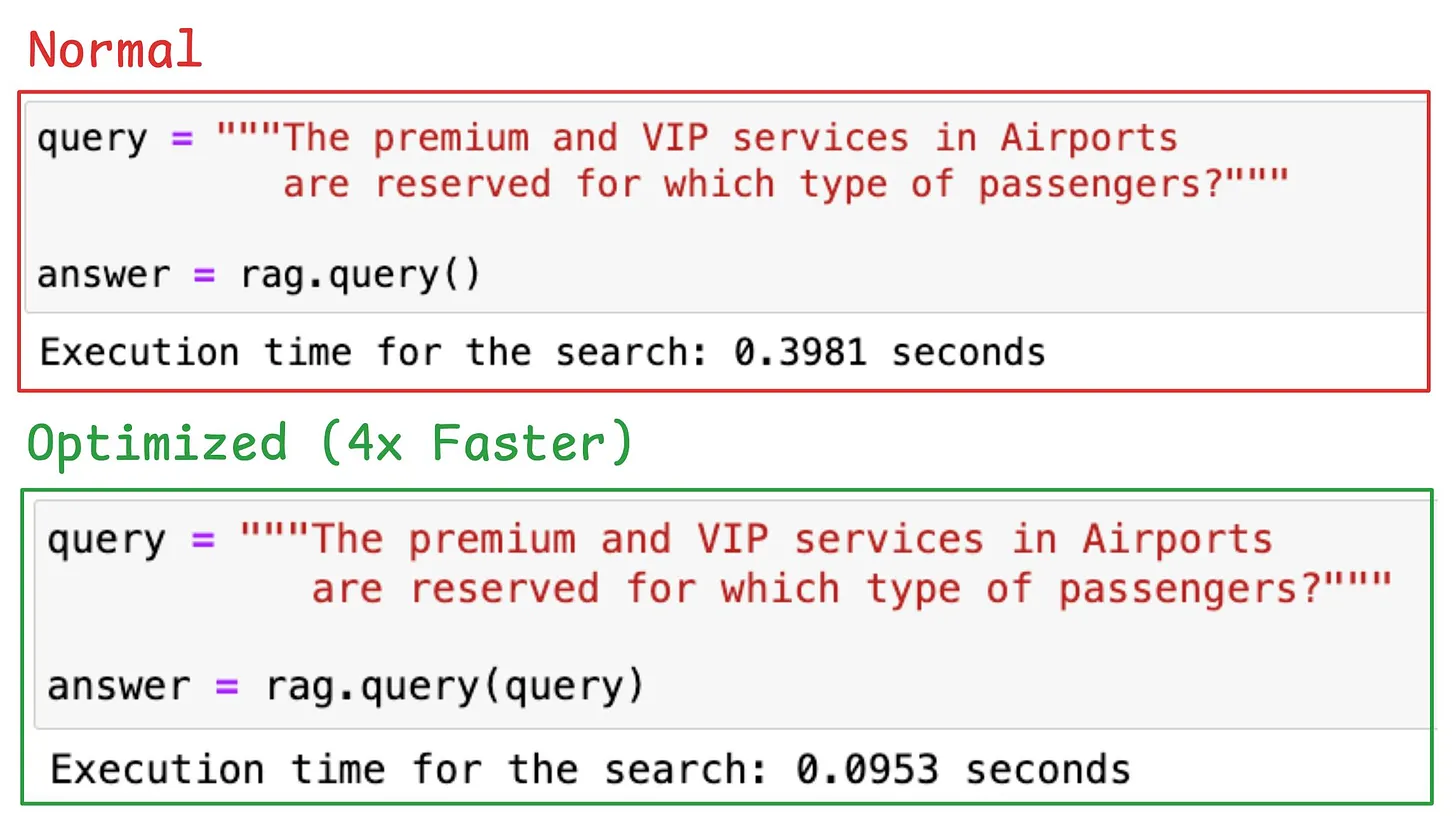
- In Part 3, we tackled one of the most pressing challenges—latency. We discussed how to optimize RAG systems for speed by reducing memory footprints and computational demands, enabling faster retrieval without compromising significantly on accuracy.
This was the final outcome from Part 3:
But there’s still more left to cover.
More specifically, from Part 1 to Part 3, we focused primarily on text-based RAG systems.
But real-world documents often contain more than just plain text. They include images, tables, and other non-textual elements (called multimodal data).

Handling such multimodal data introduces additional challenges in parsing, embedding, and retrieval that we want to cover next.
Thus, in Part 4 of our RAG series (this article), we’ll focus on building RAG systems that can ingest multimodal data, i.e., store multimodal data in the vector database that one can do retrieval over.
Let’s dive in!
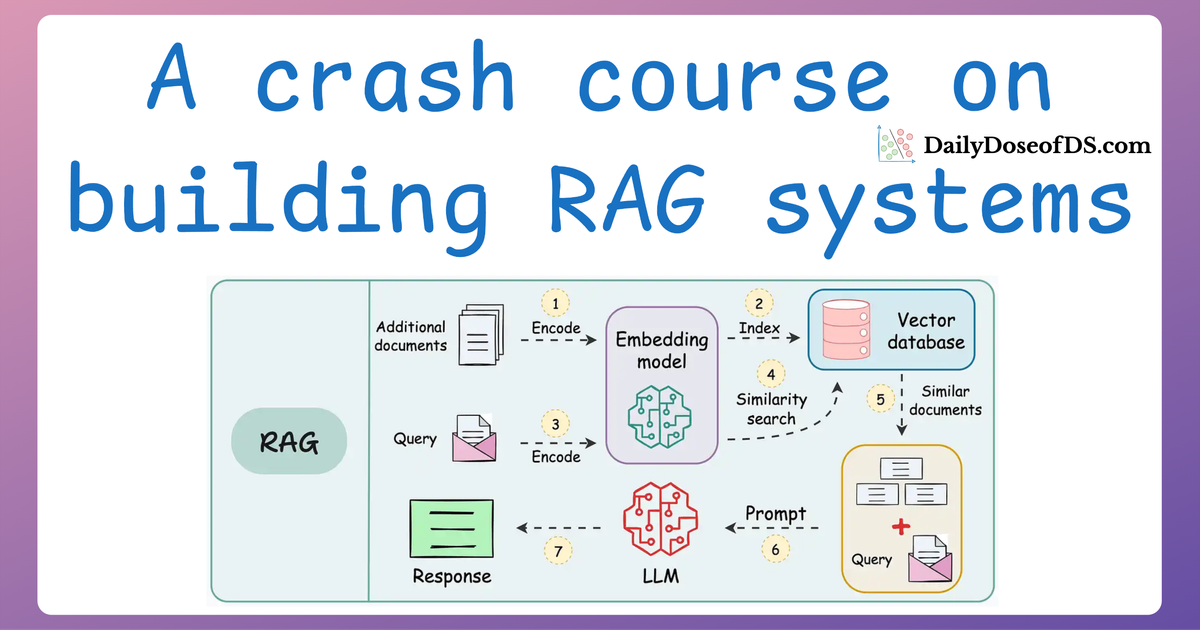
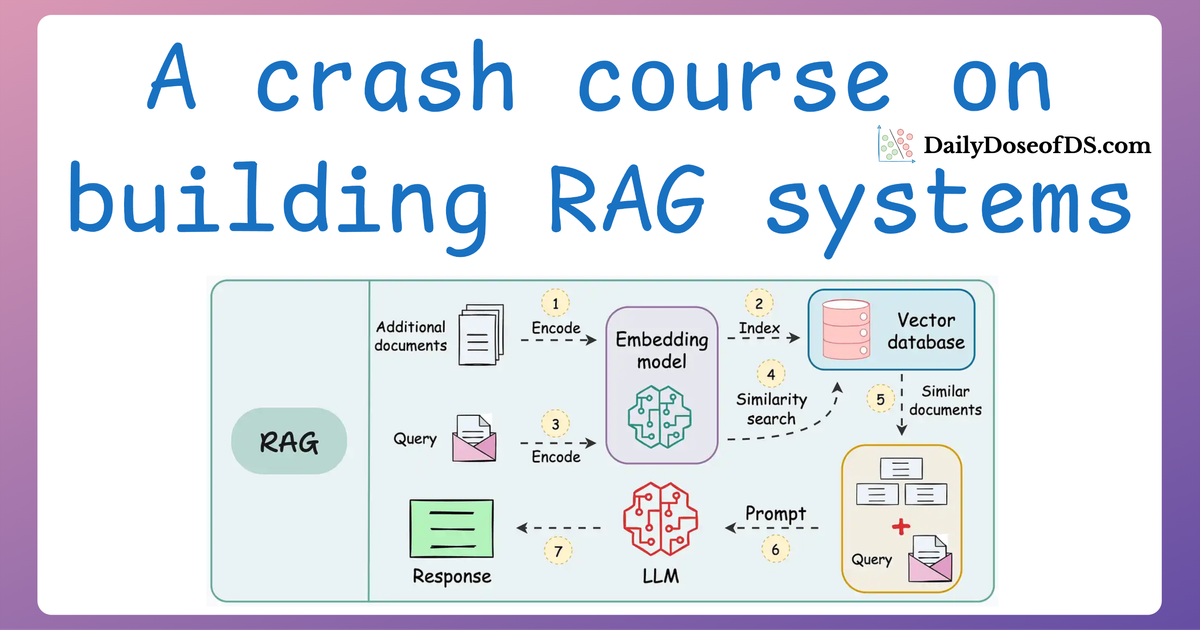
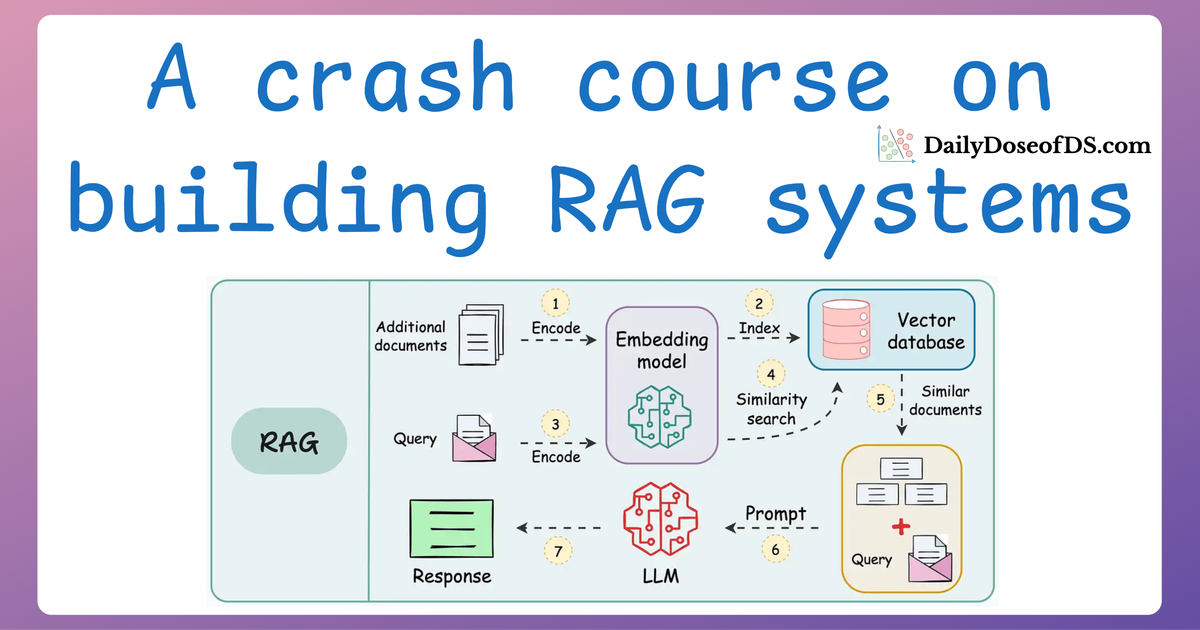
Multimodal RAG workflow
Since this is the first time we are covering multimodality in any form in this RAG crash course, it would be good to lay out a workflow of how we will go about building such a system.
So here's the steps look like:
- First, we will learn how to extract text, tables, and figures from a complex document.
- This will produce an array of images, texts, and tables:
Once done, our next objective would be to figure out how we can store this data as embeddings in a vector database so that we can use it for retrieval.