LLMs
Traditional RAG vs. HyDE
...explained visually.

Avi Chawla
...explained visually.

TODAY'S ISSUE
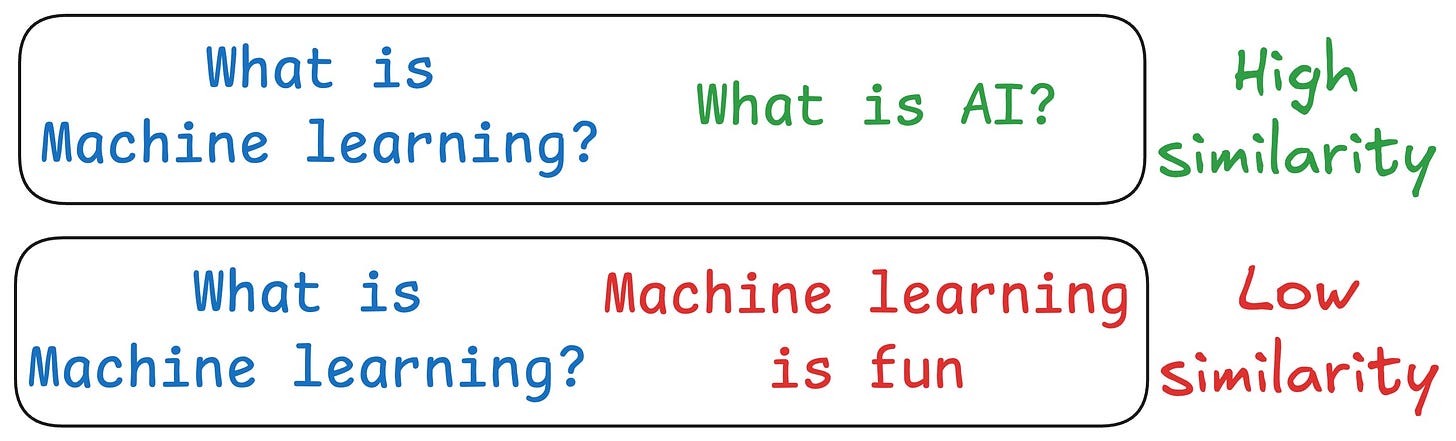
One critical problem with the traditional RAG system is that questions are not semantically similar to their answers.
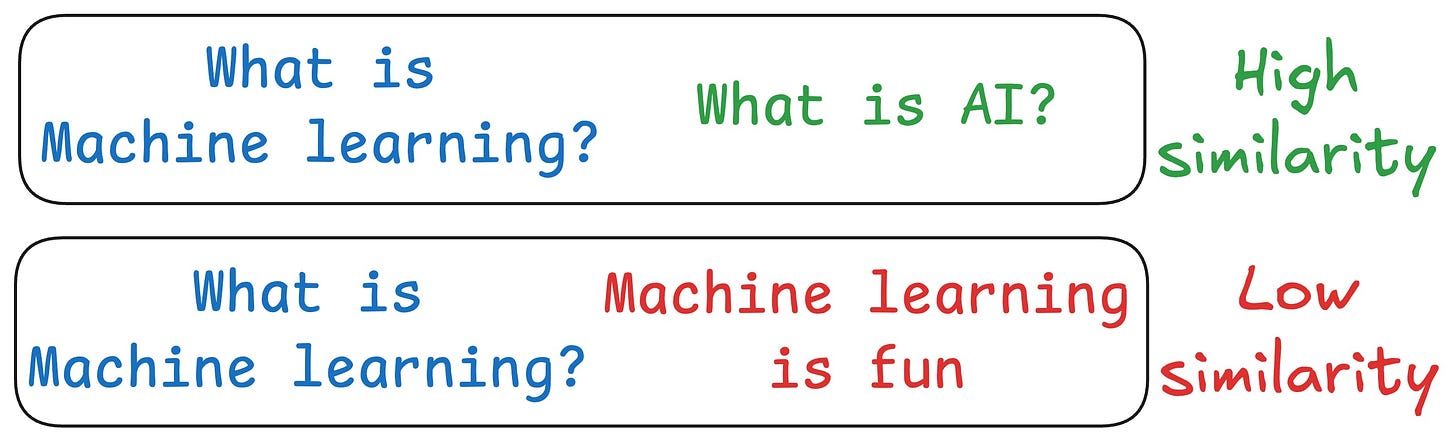
As a result, several irrelevant contexts get retrieved during the retrieval step due to a higher cosine similarity than the documents actually containing the answer.
HyDE solves this.
The following visual depicts how it differs from traditional RAG and HyDE.
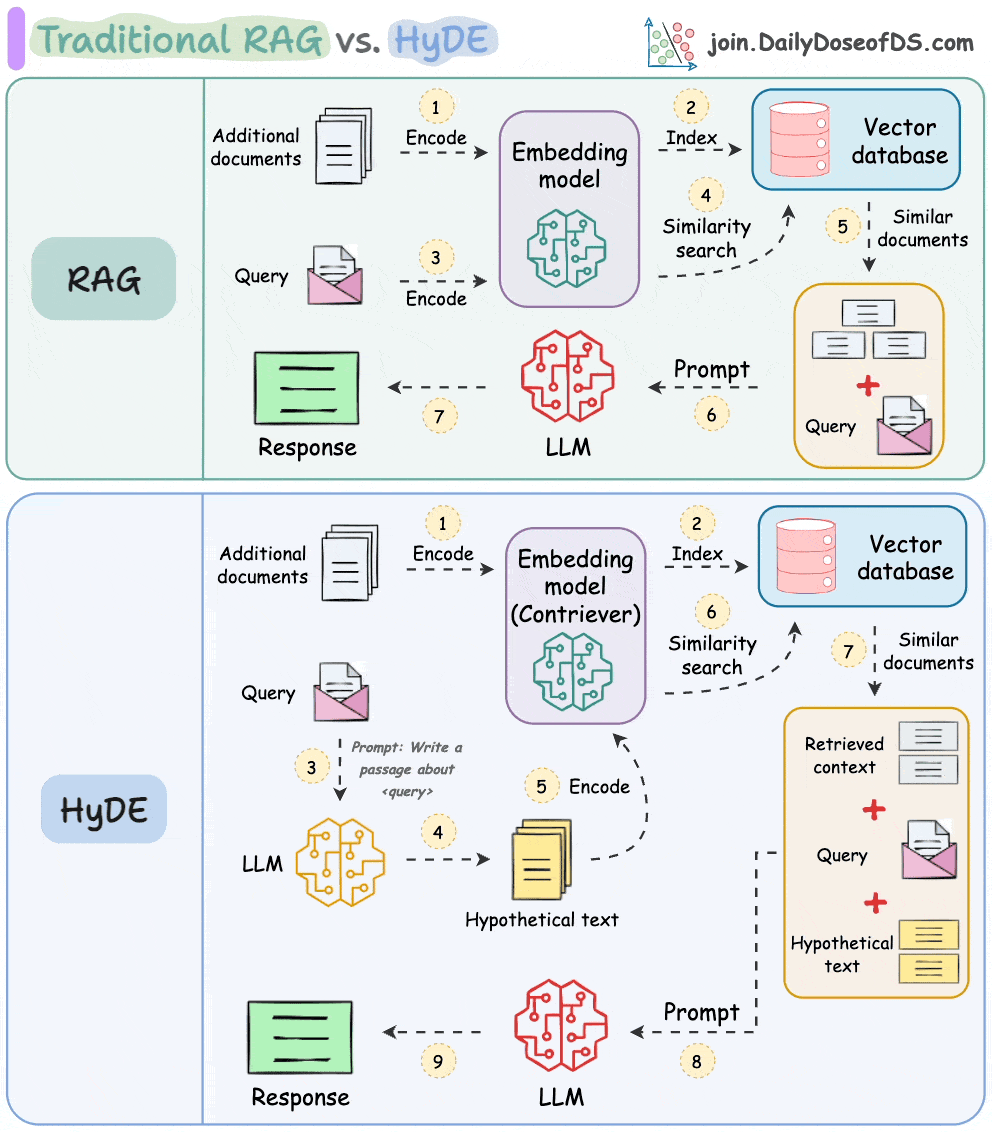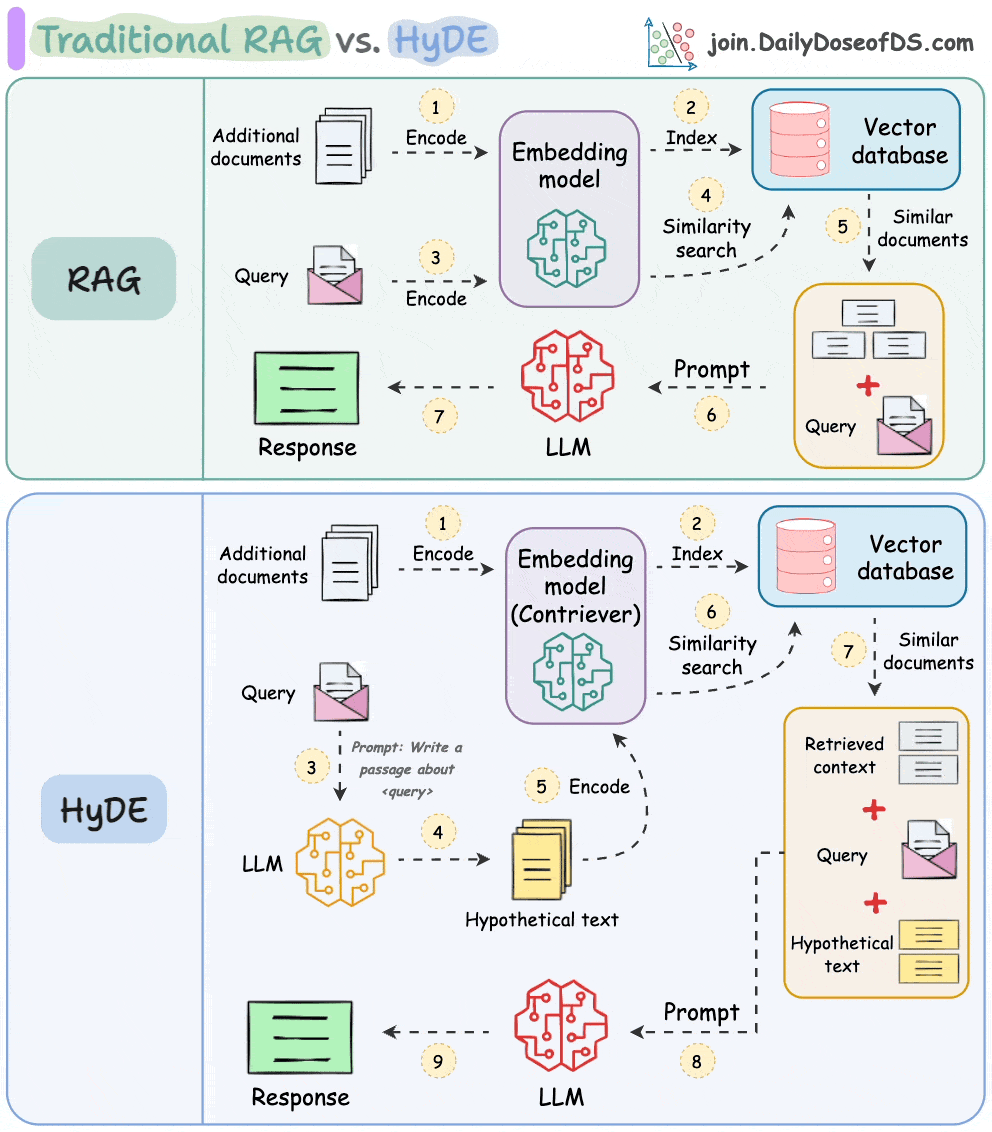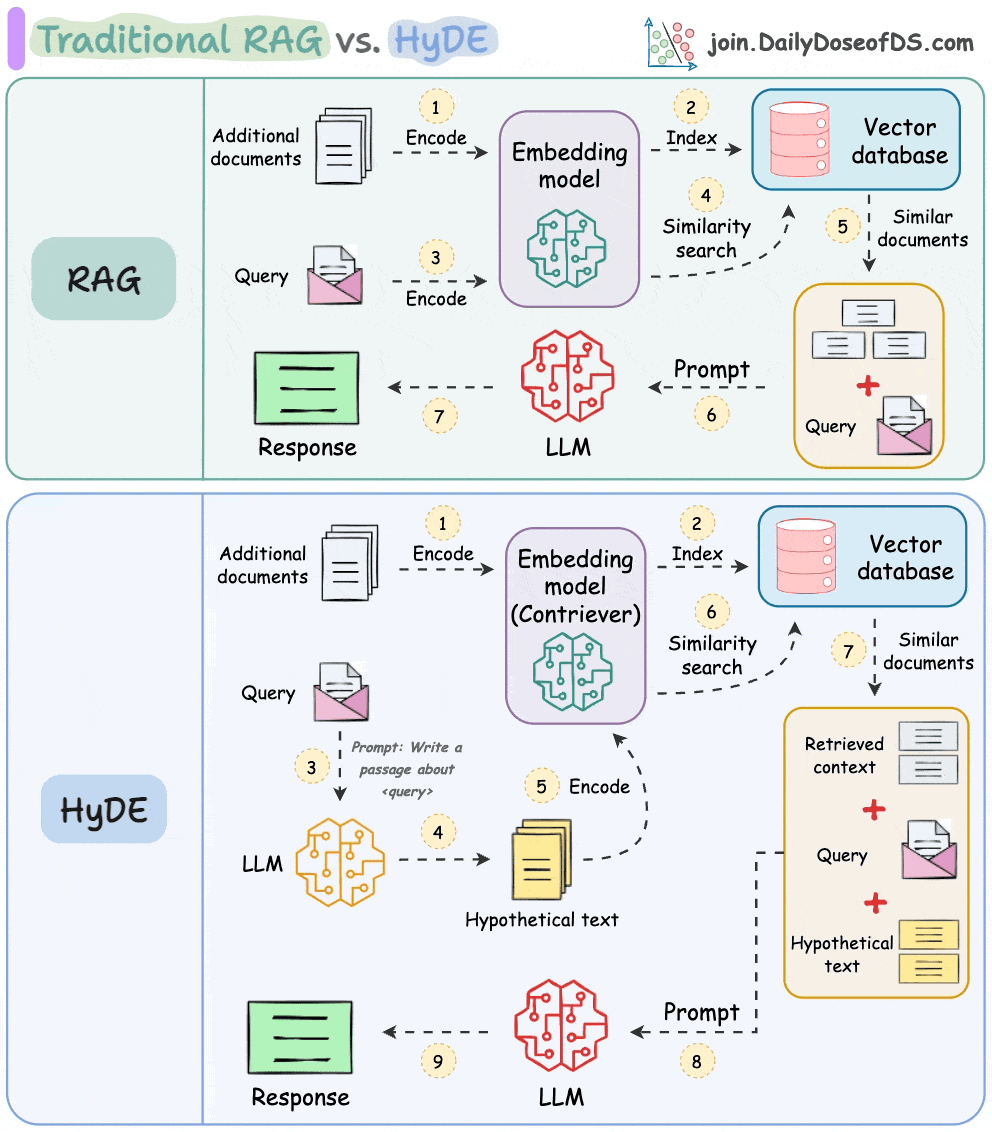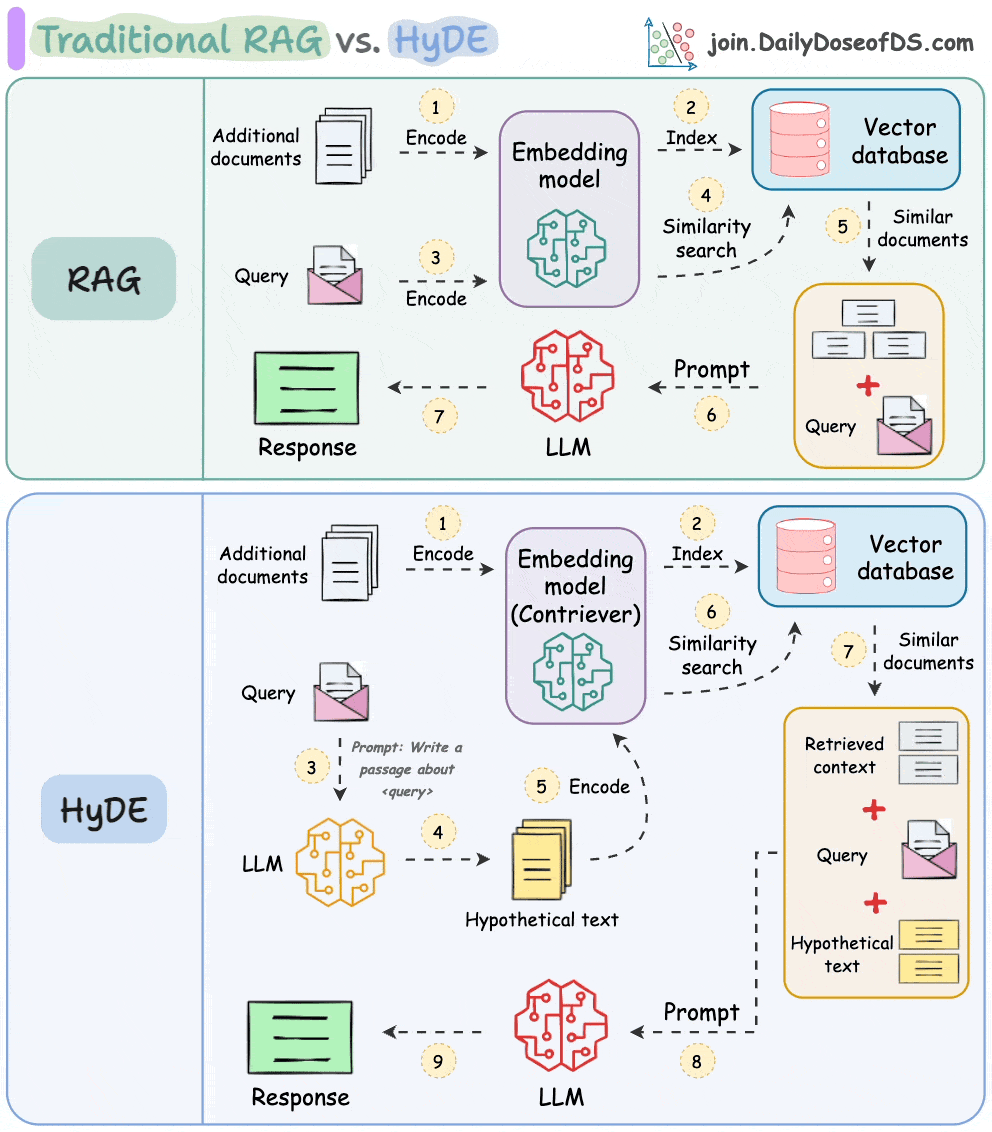
Let's understand this in more detail today.
On a side note, we started a beginner-friendly crash course on RAGs recently with implementations. Read the first three parts here
As mentioned earlier, questions are not semantically similar to their answers, which leads to several irrelevant contexts during retrieval.
HyDE handles this as follows:
H for the query Q (this answer does not have to be entirely correct).E (Bi-encoders are famously used here, which we discussed and built here).E to query the vector database and fetch relevant context (C).H + retrieved-context C + query Q to the LLM to produce an answer.Done!
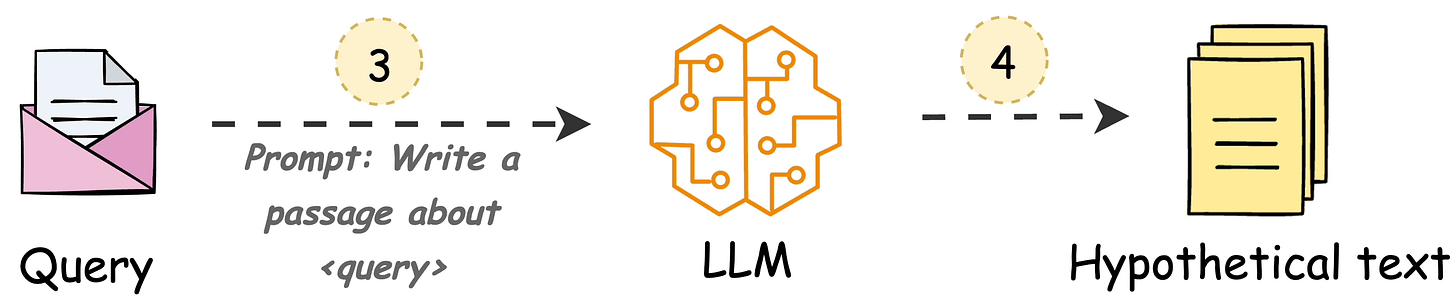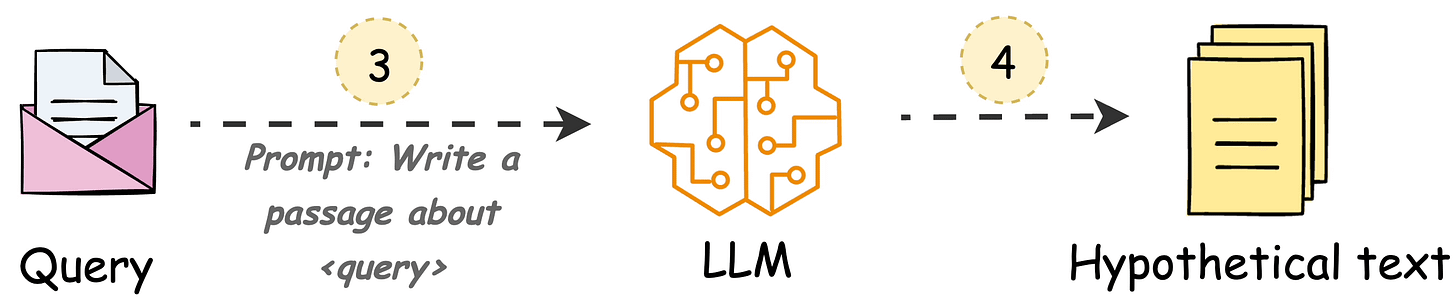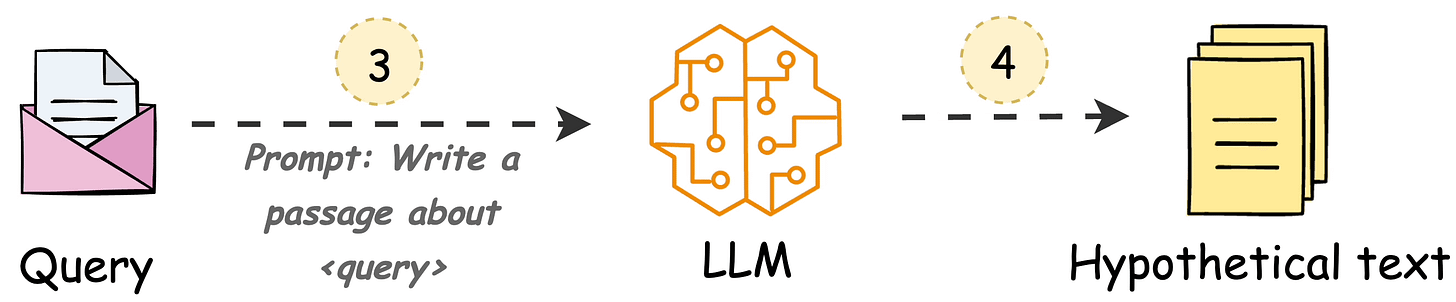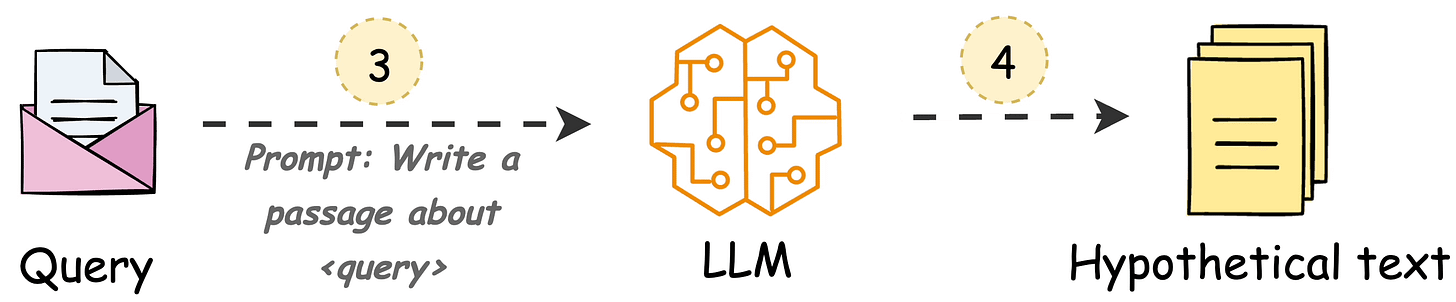
Now, of course, the hypothetical generated will likely contain hallucinated details.
But this does not severely affect the performance due to the contriever model—one which embeds.
More specifically, this model is trained using contrastive learning and it also functions as a near-lossless compressor whose task is to filter out the hallucinated details of the fake document.
This produces a vector embedding that is expected to be more similar to the embeddings of actual documents than the question is to the real documents:

Several studies have shown that HyDE improves the retrieval performance compared to the traditional embedding model.
But this comes at the cost of increased latency and more LLM usage.
We will do a practical demo of HyDE shortly.
In the meantime...
We started a beginner-friendly crash course on building RAG systems. Read the first three parts here:
👉 Over to you: What are some other ways to improve RAG?
If you are building real-world LLM-based apps, it is unlikely you can start using the model right away without adjustments. To maintain high utility, you either need:
The following visual will help you decide which one is best for you:
Read more in-depth insights into Prompting vs. RAG vs. Fine-tuning here →
Once a model has been trained, we move to productionizing and deploying it.
If ideas related to production and deployment intimidate you, here’s a quick roadmap for you to upskill (assuming you know how to train a model):
This roadmap should set you up pretty well, even if you have NEVER deployed a single model before since everything is practical and implementation-driven.