LLMs
[Hands-on] Building a Llama-OCR app
...using Llama-3.2-vision model and Streamlit.

Avi Chawla
...using Llama-3.2-vision model and Streamlit.

TODAY'S ISSUE
Last week, we shared a demo of a Llama-OCR app that someone else built.
This week, we created our own OCR app using the Llama-3.2-vision model, and today, we are sharing how we built it.
You can upload an image, and it converts it into a structured markdown using the Llama-3.2 multimodal model, as shown in the video below.
Here’s what we'll use:
The entire code is available here: Llama OCR Demo GitHub.
Now, let’s build the app.
For simplicity, we are not going to show the Streamlit part. We will just show how the LLM is utilized in this demo.
Also, talking of LLMs, we started a beginner-friendly crash course on RAGs recently with implementations. Read the first four parts below:
Ollama provides a platform to run LLMs locally, giving you control over your data and model usage.
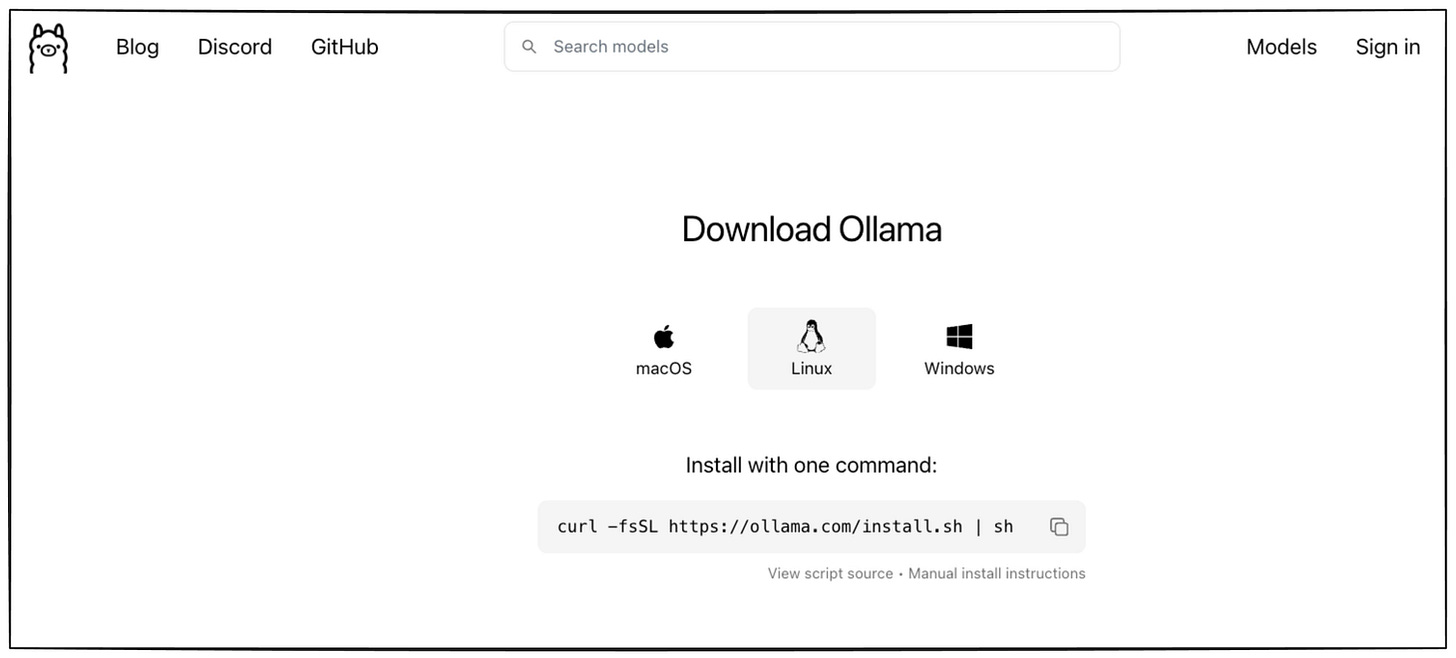
Go to Ollama.com, select your operating system, and follow the instructions.
Llama3.2-vision is a multimodal LLM for visual recognition, image reasoning, captioning, and answering general questions about an image.
Download it as follows:

Finally, install the Ollama Python package as follows:

Almost done!
Finally, prompting Llama3.2-vision with Ollama is as simple as this code:
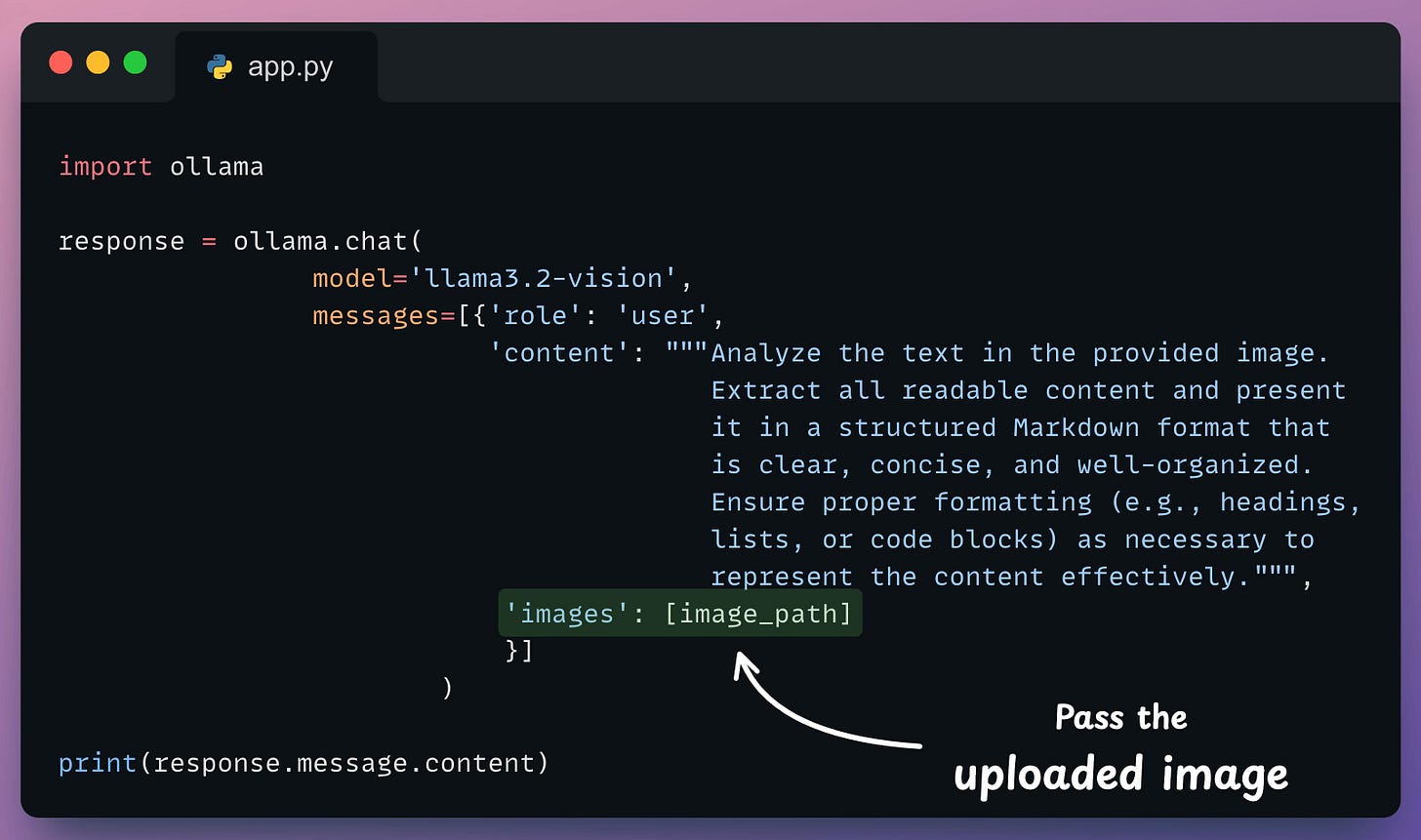
Done!
Of course, the full Streamlit app will require more code to build, but everything is still just 50 lines of code!
Also, as mentioned above, building the full Streamlit app is the focus of today's issue.
Instead, the goal is to demonstrate how simple it is to use frameworks like Ollama to build LLM apps.
In the app we built, you can upload an image, and it converts it into a structured markdown using the Llama-3.2 multimodal model, as shown in this demo:
The entire code (along with the code for Streamlit) is available here: Llama OCR Demo GitHub.
👉 Over to you: What other demos do you want us to cover next?
One critical problem with the traditional RAG system is that questions are not semantically similar to their answers.
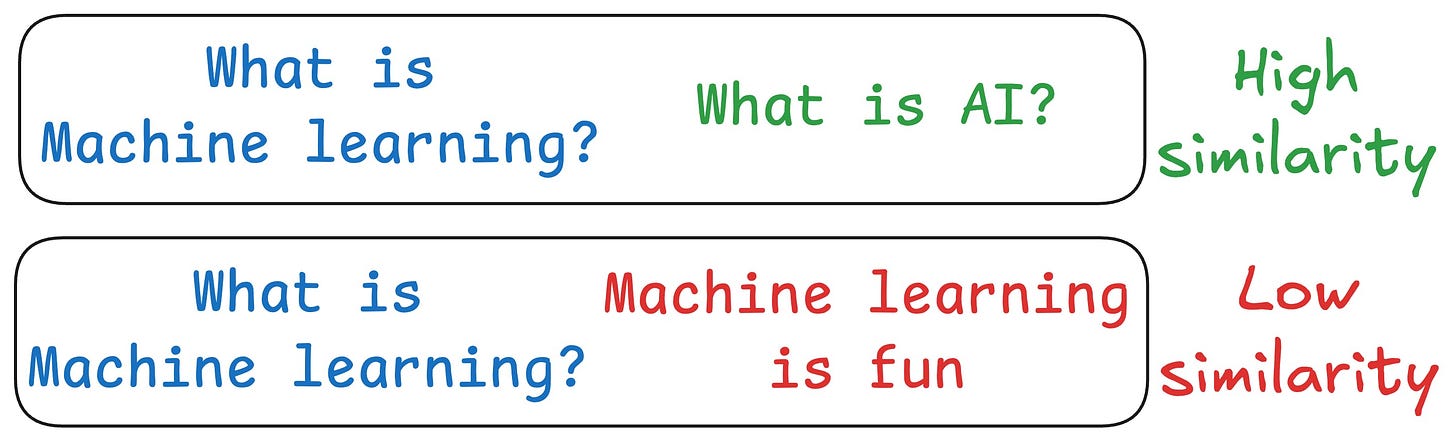
As a result, several irrelevant contexts get retrieved during the retrieval step due to a higher cosine similarity than the documents actually containing the answer.
HyDE solves this.
The following visual depicts how it differs from traditional RAG and HyDE.
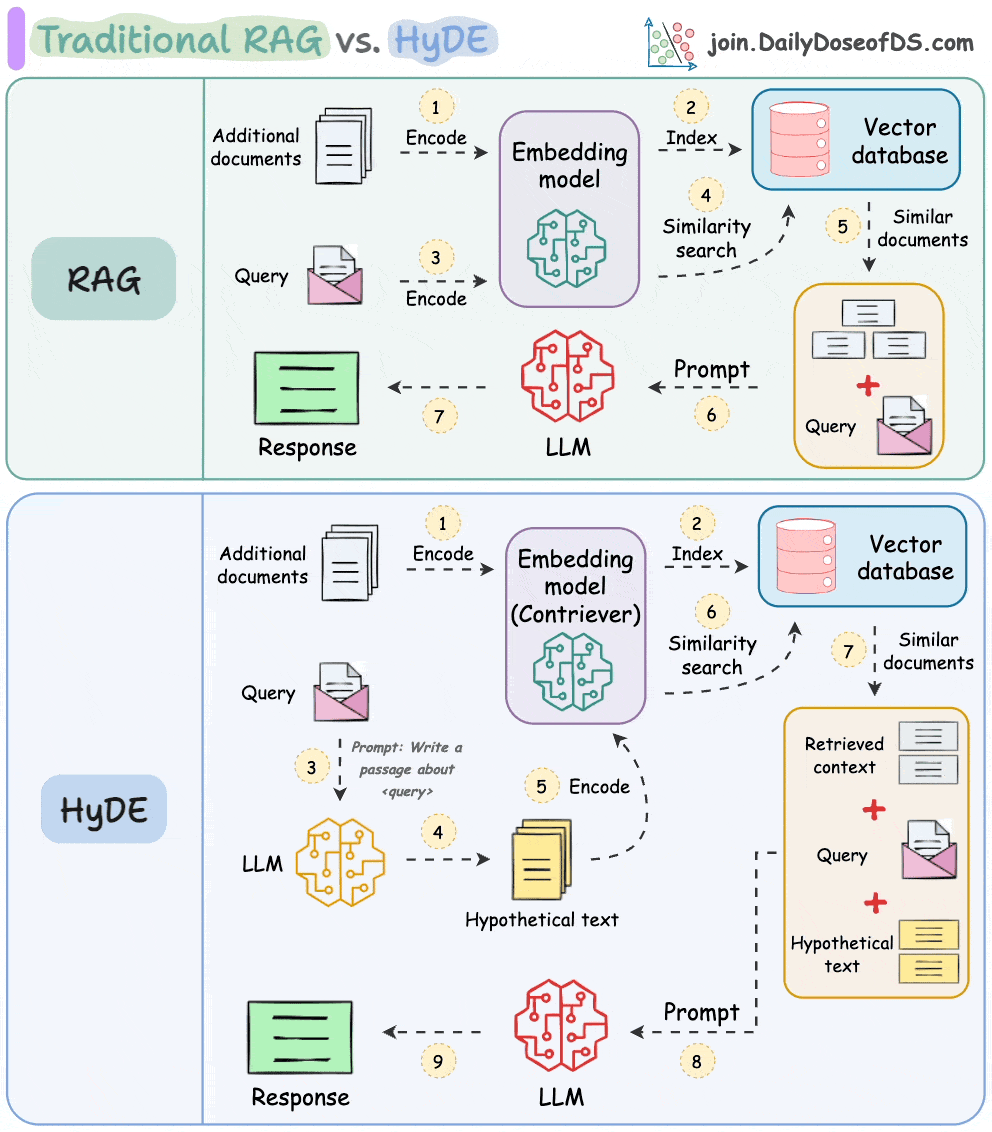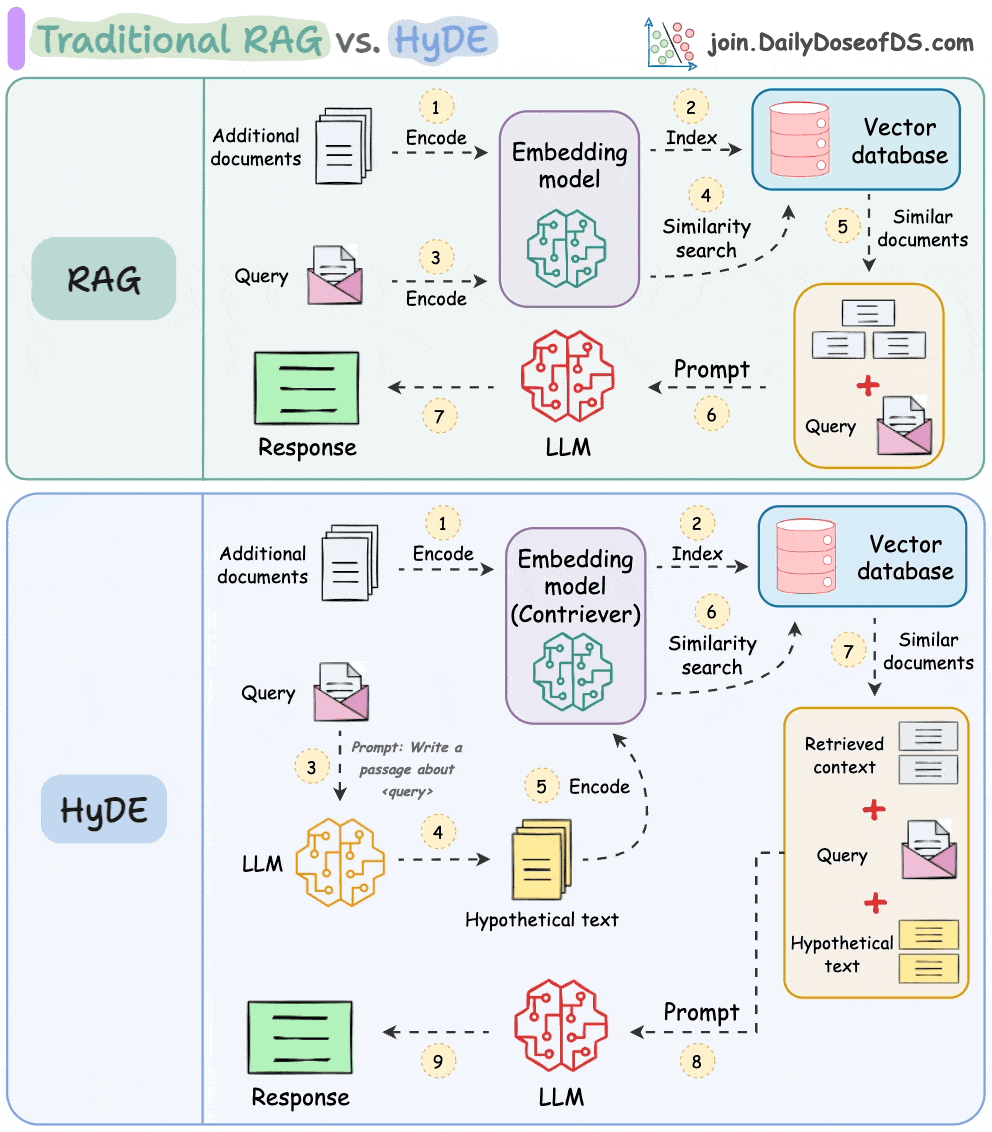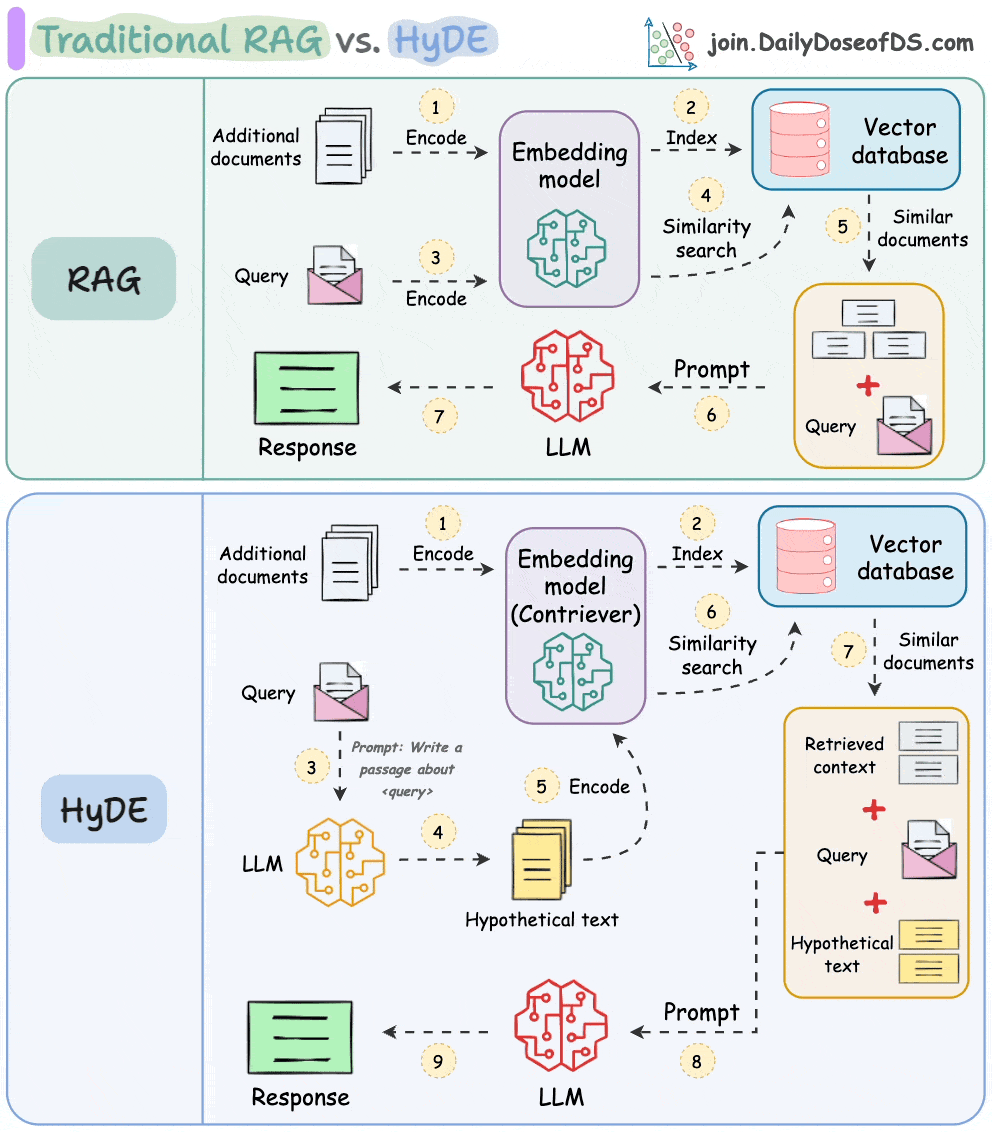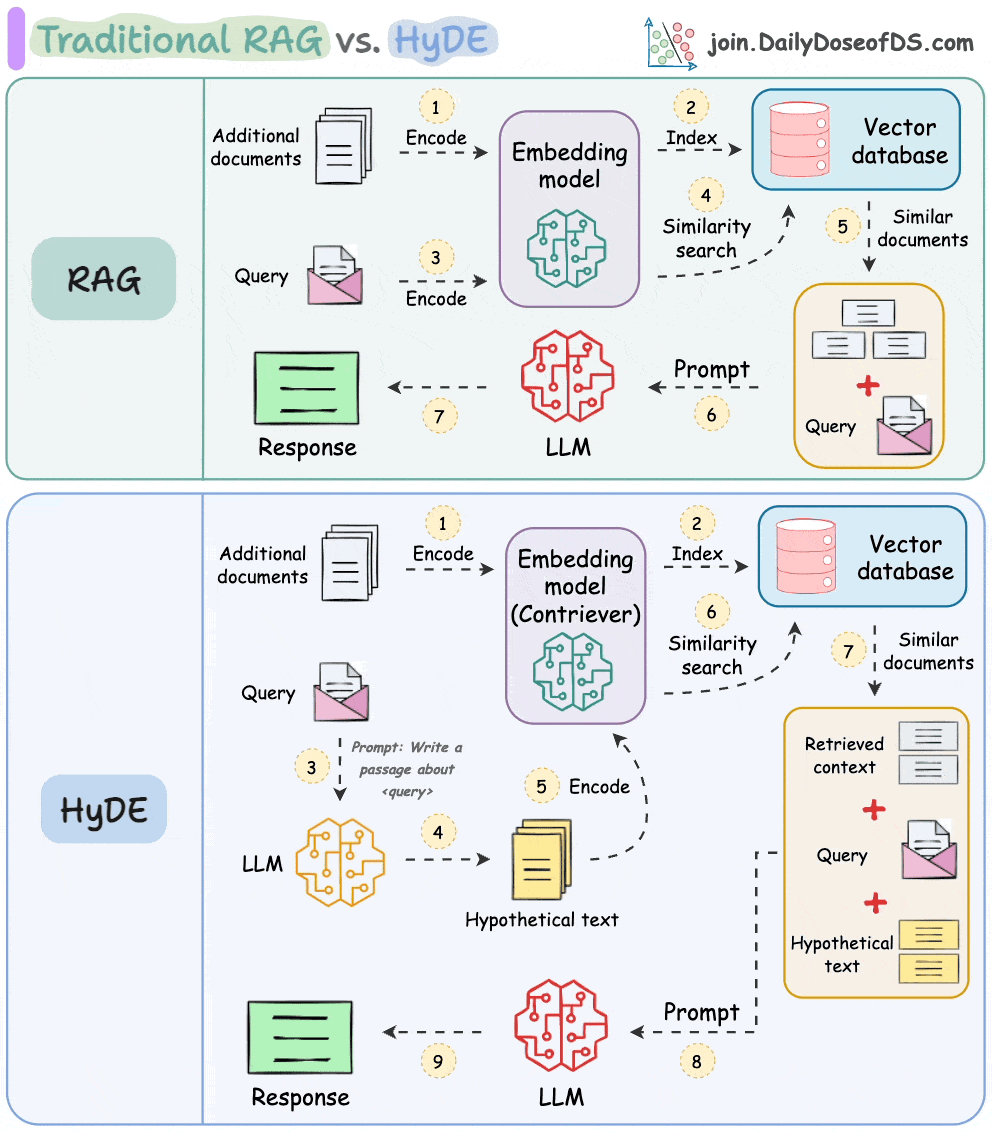
We covered this in detail in a newsletter issue published last week →
Versioning GBs of datasets is practically impossible with GitHub because it imposes an upper limit on the file size we can push to its remote repositories.
That is why Git is best suited for versioning codebase, which is primarily composed of lightweight files.
However, ML projects are not solely driven by code.
Instead, they also involve large data files, and across experiments, these datasets can vastly vary.
To ensure proper reproducibility and experiment traceability, it is also necessary to version datasets.
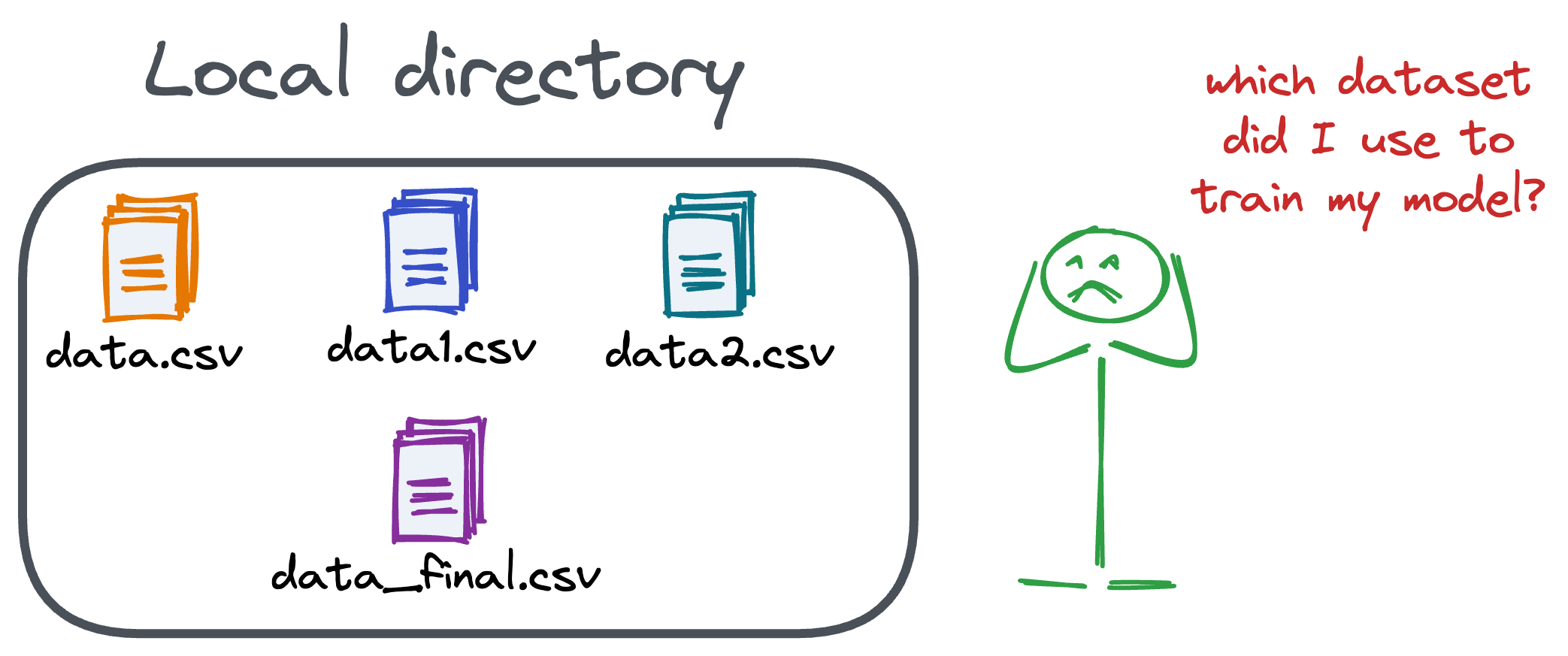
Data version control (DVC) solves this problem.
The core idea is to integrate another version controlling system with Git, specifically used for large files.
Here's everything you need to know (with implementation) about building 100% reproducible ML projects →