LLMs
A Visual Guide to Agent2Agent (A2A) Protocol
(it does not compete with MCPs).

Avi Chawla
(it does not compete with MCPs).

TODAY'S ISSUE
Agentic applications require both A2A and MCP.
Today, let's clearly understand what A2A is and how it can work with MCP.
If you don't know about MCP servers, we covered them recently in the newsletter here:
In a gist:
So using A2A, while two Agents might be talking to each other...they themselves might be communicating to MCP servers.
In that sense, they do not compete with each other.
To explain further, Agent2Agent (A2A) enables multiple AI agents to work together on tasks without directly sharing their internal memory, thoughts, or tools.
Instead, they communicate by exchanging context, task updates, instructions, and data.
Essentially, AI applications can model A2A agents as MCP resources, represented by their AgentCard (more about it shortly).
Using this, AI agents connecting to an MCP server can discover new agents to collaborate with and connect via the A2A protocol.
A2A-supporting Remote Agents must publish a "JSON Agent Card" detailing their capabilities and authentication.
Clients use this to find and communicate with the best agent for a task.
There are several things that make A2A powerful:
Additionally, it can integrate with MCP.
While it's still new, it's good to standardize Agent-to-Agent collaboration, similar to how MCP does for Agent-to-tool interaction.
What are your thoughts?
We shall cover this from an implementation perspective soon.
Stay tuned!
Consider the size difference between BERT-large and GPT-3:
I have fine-tuned BERT-large several times on a single GPU using traditional fine-tuning:
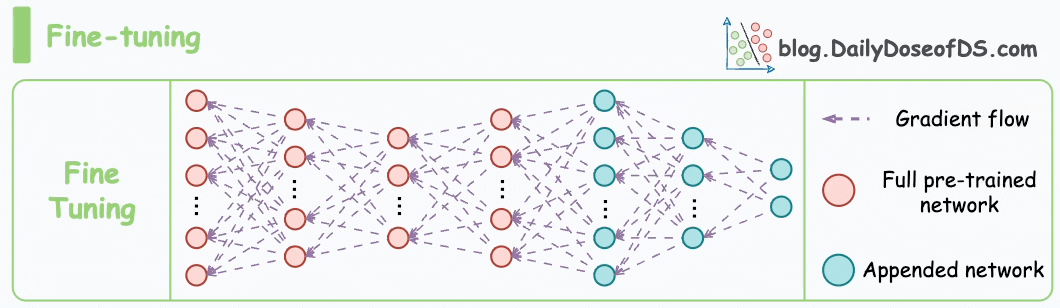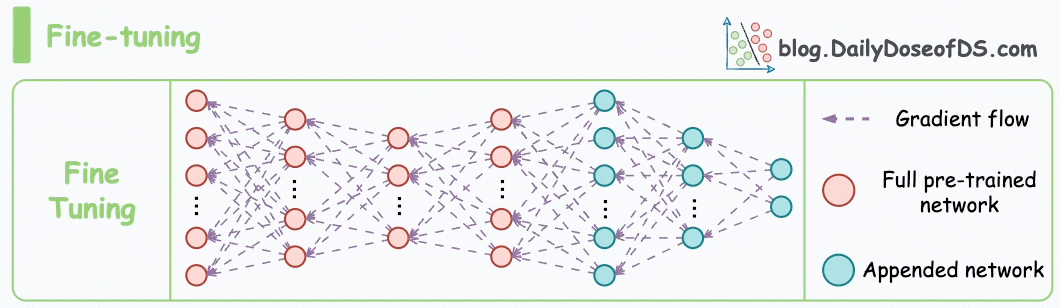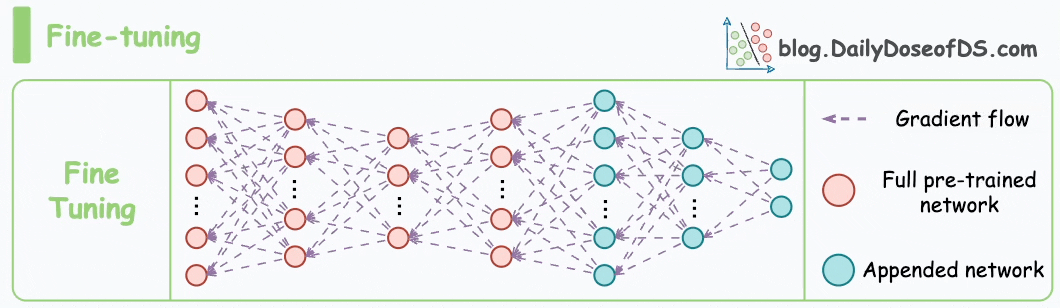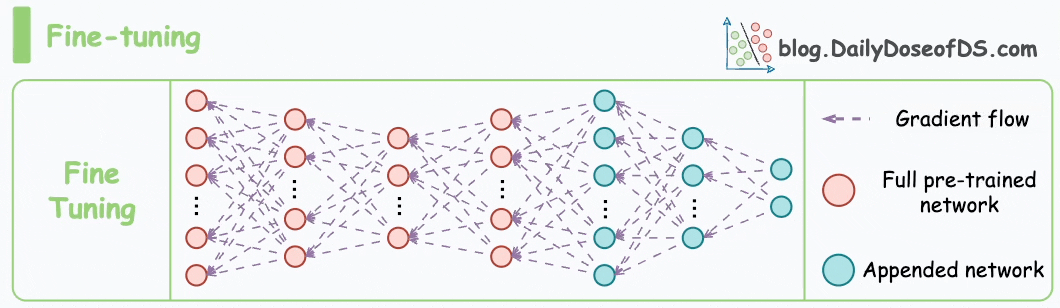
But this is impossible with GPT-3, which has 175B parameters. That's 350GB of memory just to store model weights under float16 precision.
This means that if OpenAI used traditional fine-tuning within its fine-tuning API, it would have to maintain one model copy per user:
And the problems don't end there:
LoRA (+ QLoRA and other variants) neatly solved this critical business problem.
Once a model has been trained, we move to productionizing and deploying it.
If ideas related to production and deployment intimidate you, here’s a quick roadmap for you to upskill (assuming you know how to train a model):
This roadmap should set you up pretty well, even if you have NEVER deployed a single model before since everything is practical and implementation-driven.