LLMs
LoRA/QLoRA—Explained From a Business Lens
From 350 GB to 25 MB.

Avi Chawla
From 350 GB to 25 MB.

TODAY'S ISSUE
Building agent-native apps is challenging, and a lot of it boils down to not having appropriate tooling.
But this is changing!
CoAgents, an open-source framework by CopilotKit, lets you build Agents with human-in-the-loop workflows: CopilotKit GitHub Repo (star the repo).
The latest updates to CoAgents bring together:
Moreover, CoAgents also lets you:
Impressive, right?
Big thanks to CopilotKit for partnering today and showing what's possible with their powerful Agent-development framework.
Consider the size difference between BERT-large and GPT-3:
I have fine-tuned BERT-large several times on a single GPU using traditional fine-tuning:
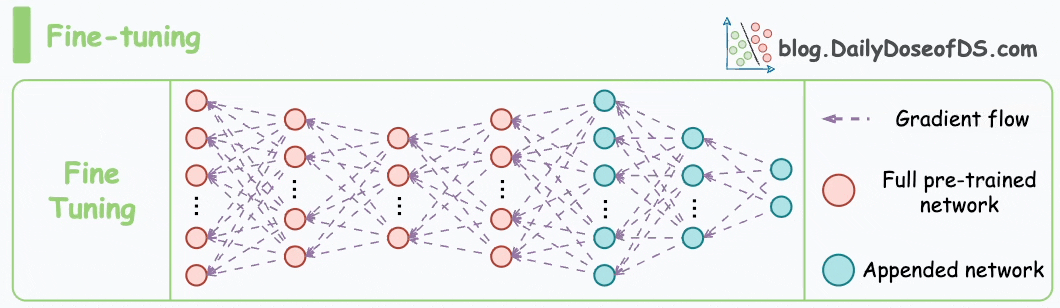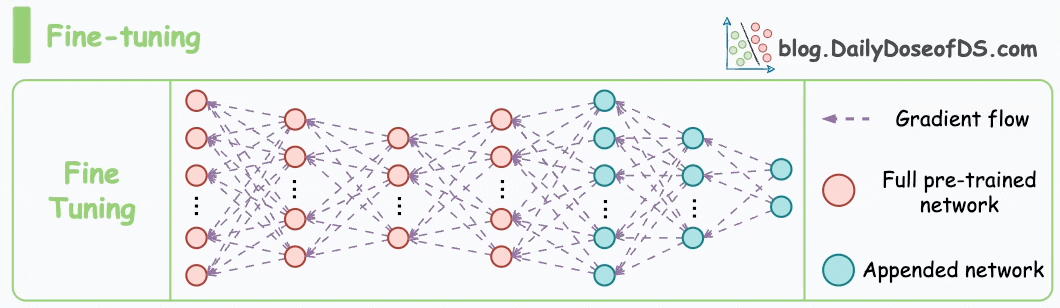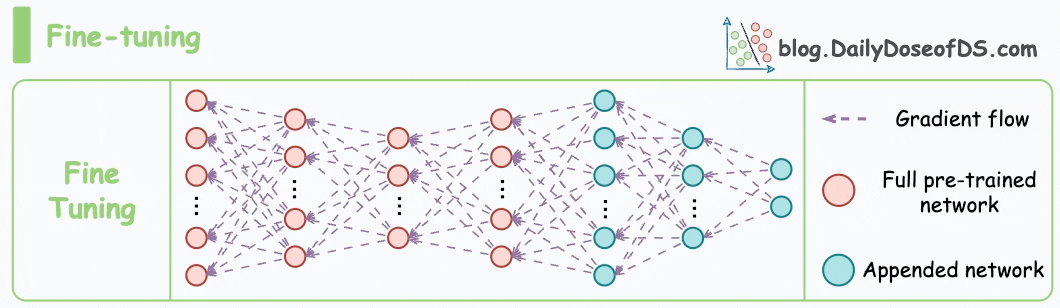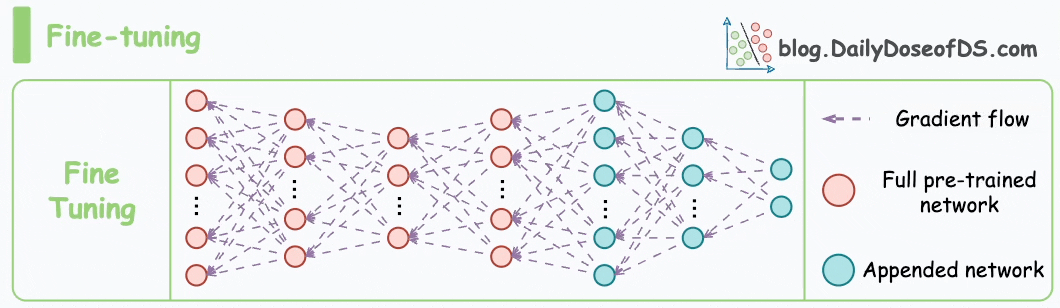
But this is impossible with GPT-3, which has 175B parameters. That's 350GB of memory just to store model weights under float16 precision.
This means that if OpenAI used traditional fine-tuning within its fine-tuning API, it would have to maintain one model copy per user:
And the problems don't end there:
LoRA (+ QLoRA and other variants) neatly solved this critical business problem.
The core idea revolves around training a few parameters compared to the base model.
For instance, if the original model has a weight matrix W (shape d*d), one can define the corresponding LoRA matrices A (d*r) and B (r*d).
↳ where r<<<<d (typically, r is a single-digit number).
During fine-tuning, freeze the weight matrix W and update the weights of the LoRA matrices.
During inference, the product of the LoRA matrices results in a matrix of the same shape as W. So one can obtain the output as follows:
This way, every user gets their LoRA matrices, and OpenAI can maintain just one global/common model.
Another good thing is that LoRA matrices usually do not require more than 20-25 MB of memory per user. This is immensely smaller than what we get from traditional fine-tuning.
Lastly, this also solves the other two problems we mentioned earlier:
We implemented LoRA for fine-tuning LLMs from scratch here →
LoRA has several efficient variants. We covered them here →
Moreover, if you want to develop expertise in “business ML,” we have discussed several other topics (with implementations) that align with it:
Here are some of them:
Why care?
All businesses care about impact. That’s it!
Thus, the ability to make decisions, guide strategy, and build solutions that solve real business problems and have a business impact will separate practitioners from experts.
👉 Over to you: What are some other benefits of LoRA over traditional fine-tuning?