Pandas
15 Pandas ↔ Polars ↔ SQL ↔ PySpark Translations
Become a Quadrilingual Data Scientist.

Avi Chawla
Become a Quadrilingual Data Scientist.

TODAY'S ISSUE
I created the following visual, which depicts the 15 most common tabular operations in Pandas and their corresponding translations in SQL, Polars, and PySpark.
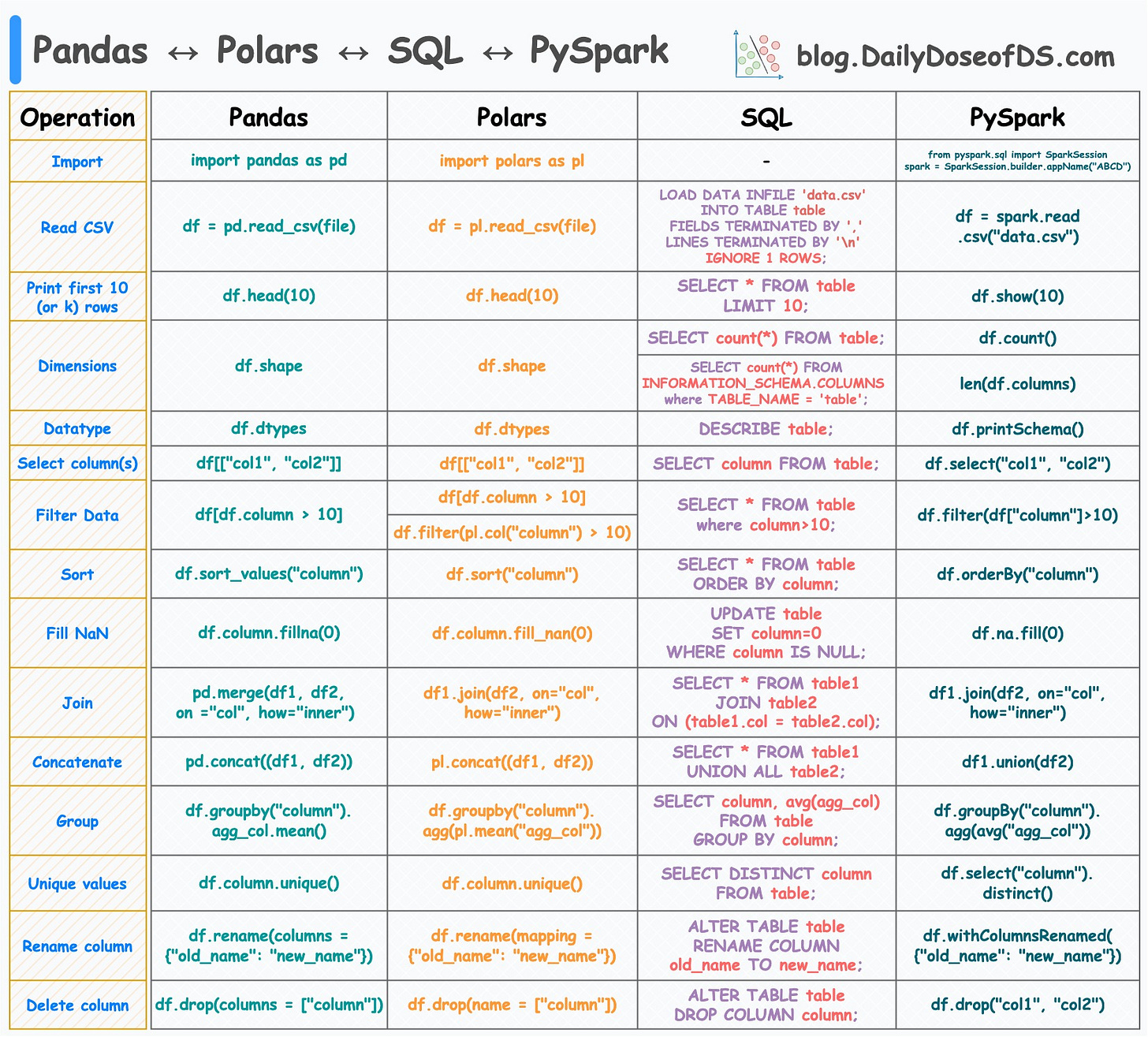
While the motivation for Pandas and SQL is clear and well-known, let me tell you why you should care about Polars and PySpark.
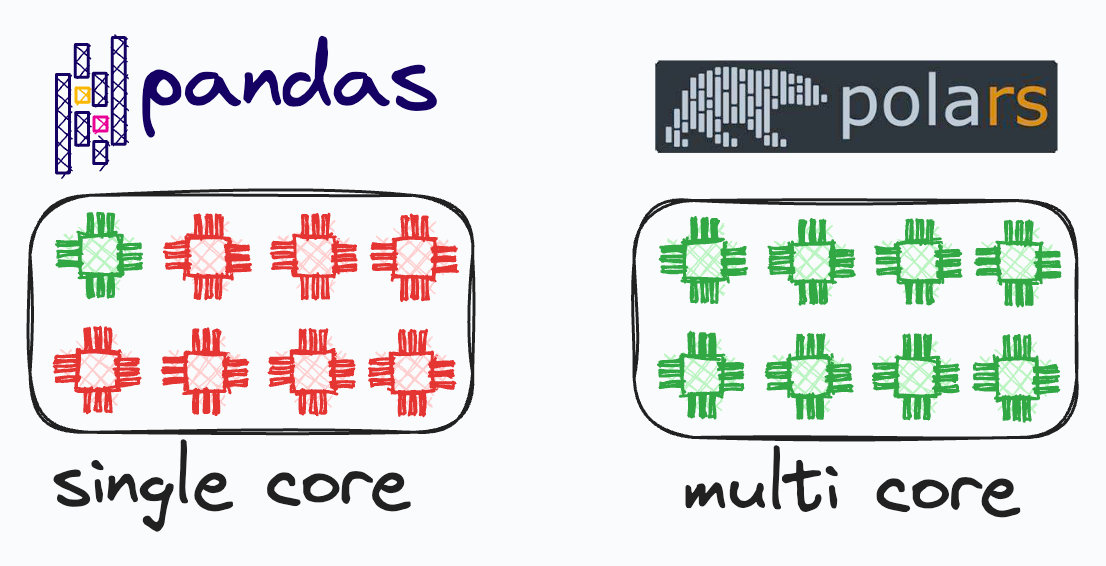
Pandas has many limitations, which Polars addresses, such as:
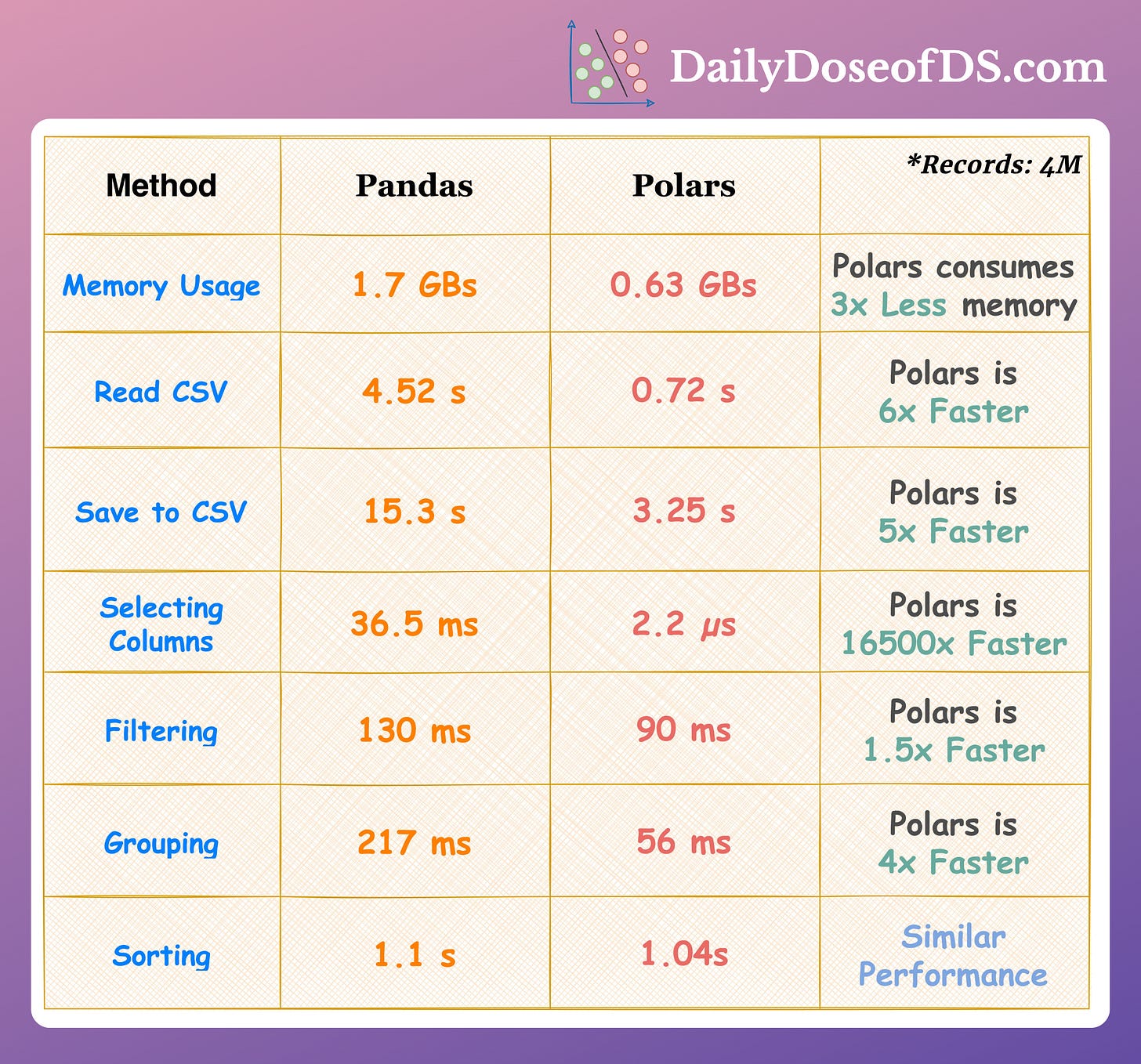
In fact, if we look at the run-time comparison on some common operations, it’s clear that Polars is much more efficient than Pandas:
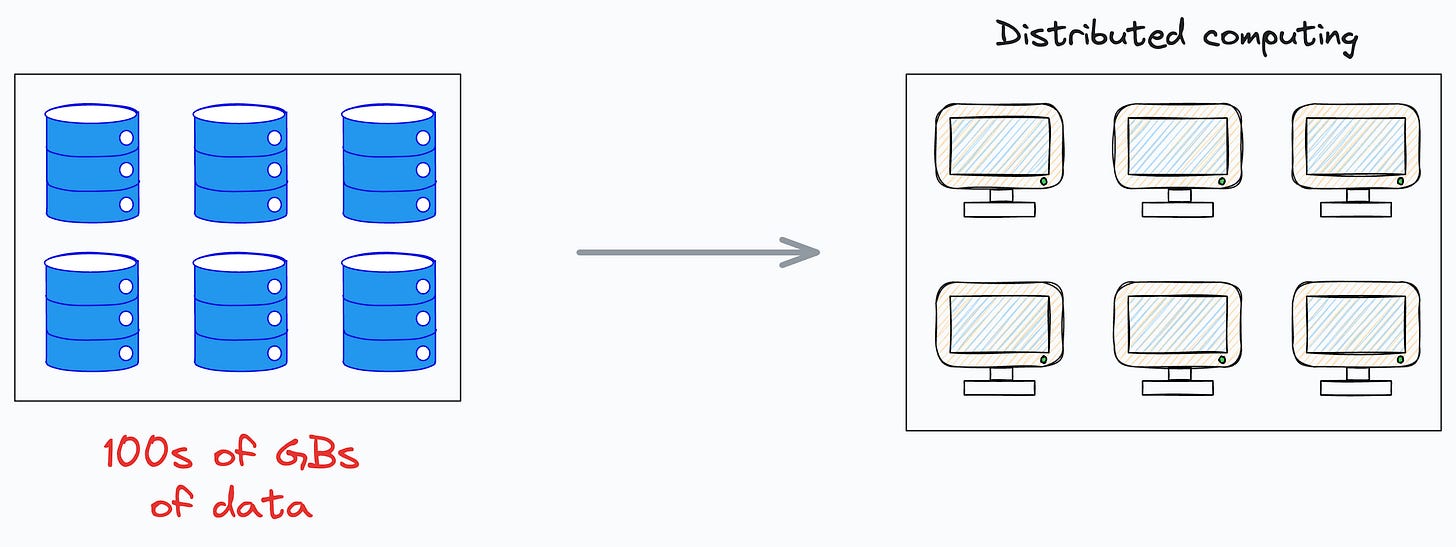
While tabular data space is mainly dominated by Pandas and Sklearn, one can hardly expect any benefit from them beyond some GBs of data due to their single-node processing.
A more practical solution is to use distributed computing instead — a framework that disperses the data across many small computers.
Spark is among the best technologies used to quickly and efficiently analyze, process, and train models on big datasets.
That is why most data science roles at big tech demand proficiency in Spark. It’s that important.
We covered this in detail in a recent deep dive as well: Don’t Stop at Pandas and Sklearn! Get Started with Spark DataFrames and Big Data ML using PySpark.
👉 Over to you: What are some other faster alternatives to Pandas that you are aware of?
Consider the size difference between BERT-large and GPT-3:
I have fine-tuned BERT-large several times on a single GPU using traditional fine-tuning:
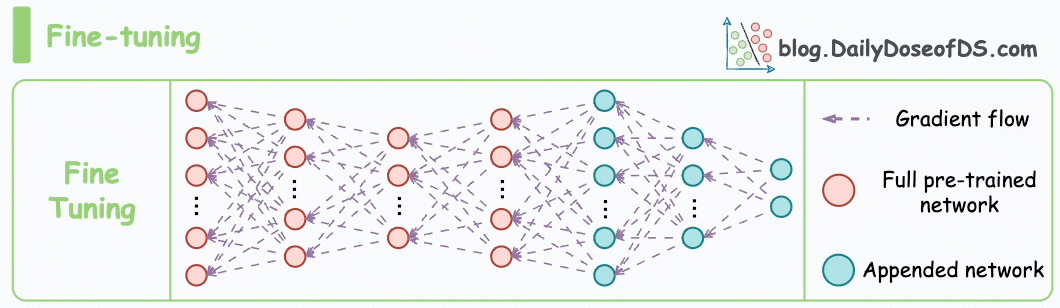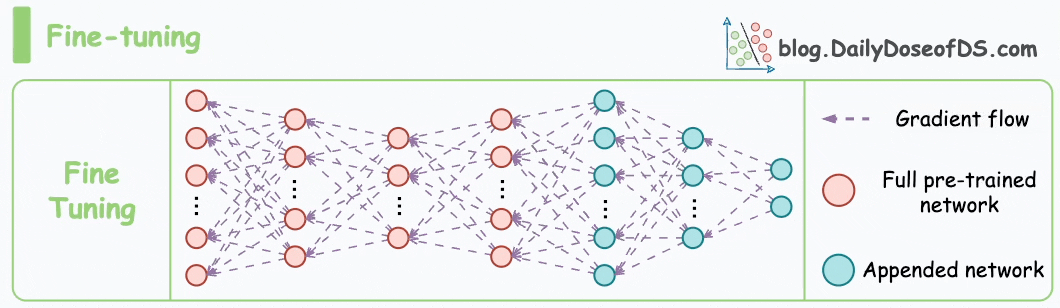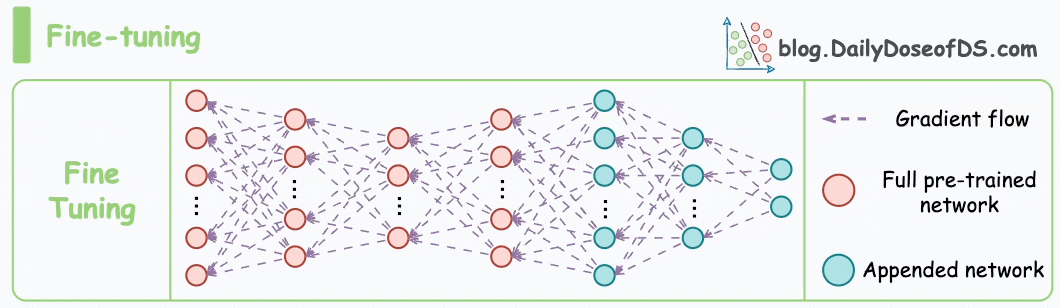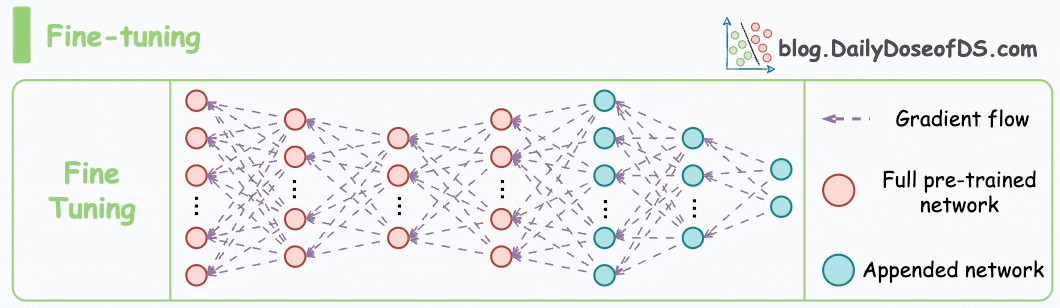
But this is impossible with GPT-3, which has 175B parameters. That's 350GB of memory just to store model weights under float16 precision.
This means that if OpenAI used traditional fine-tuning within its fine-tuning API, it would have to maintain one model copy per user:
And the problems don't end there:
LoRA (+ QLoRA and other variants) neatly solved this critical business problem.
There’s so much data on your mobile phone right now — images, text messages, etc.
And this is just about one user — you.
But applications can have millions of users. The amount of data we can train ML models on is unfathomable.
The problem?
This data is private.
So consolidating this data into a single place to train a model.
The solution?
Federated learning is a smart way to address this challenge.
The core idea is to ship models to devices, train the model on the device, and retrieve the updates:
But this isn't as simple as it sounds.
1) Since the model is trained on the client side, how to reduce its size?
2) How do we aggregate different models received from the client side?
3) [IMPORTANT] Privacy-sensitive datasets are always biased with personal likings and beliefs. For instance, in an image-related task:
Learn how to implement federated learning systems (beginner-friendly) →