MCP-powered Agentic RAG
Hands-on demo.
Next, we are showcasing another demo with MCP, which will be an Agentic RAG.
In the video below, we have an MCP-driven Agentic RAG that searches a vector database and falls back to web search if needed.
To build this, we'll use:
- Bright Data to scrape web at scale.
- Qdrant as the vector DB.
- Cursor as the MCP client.
Here's the workflow:
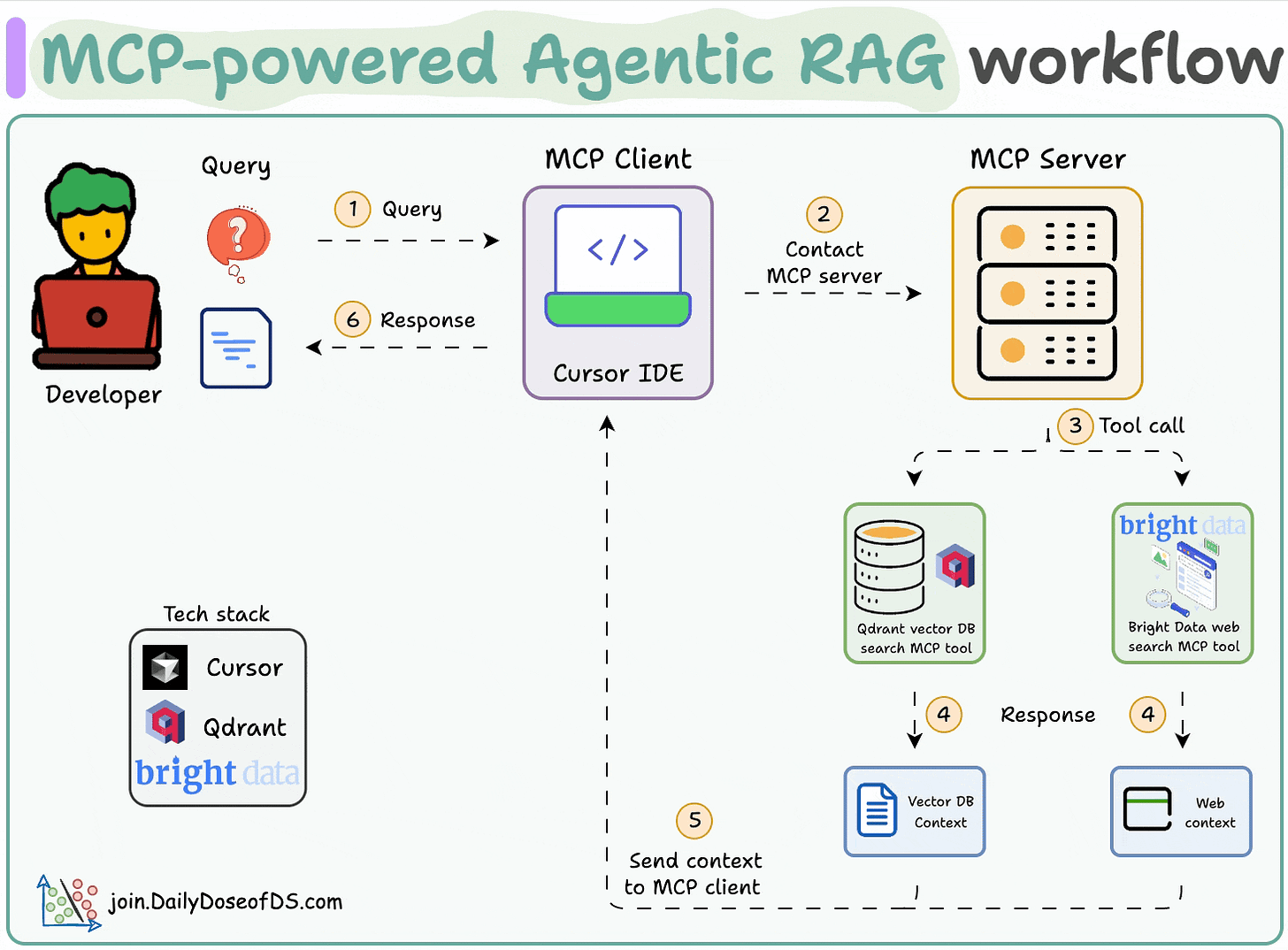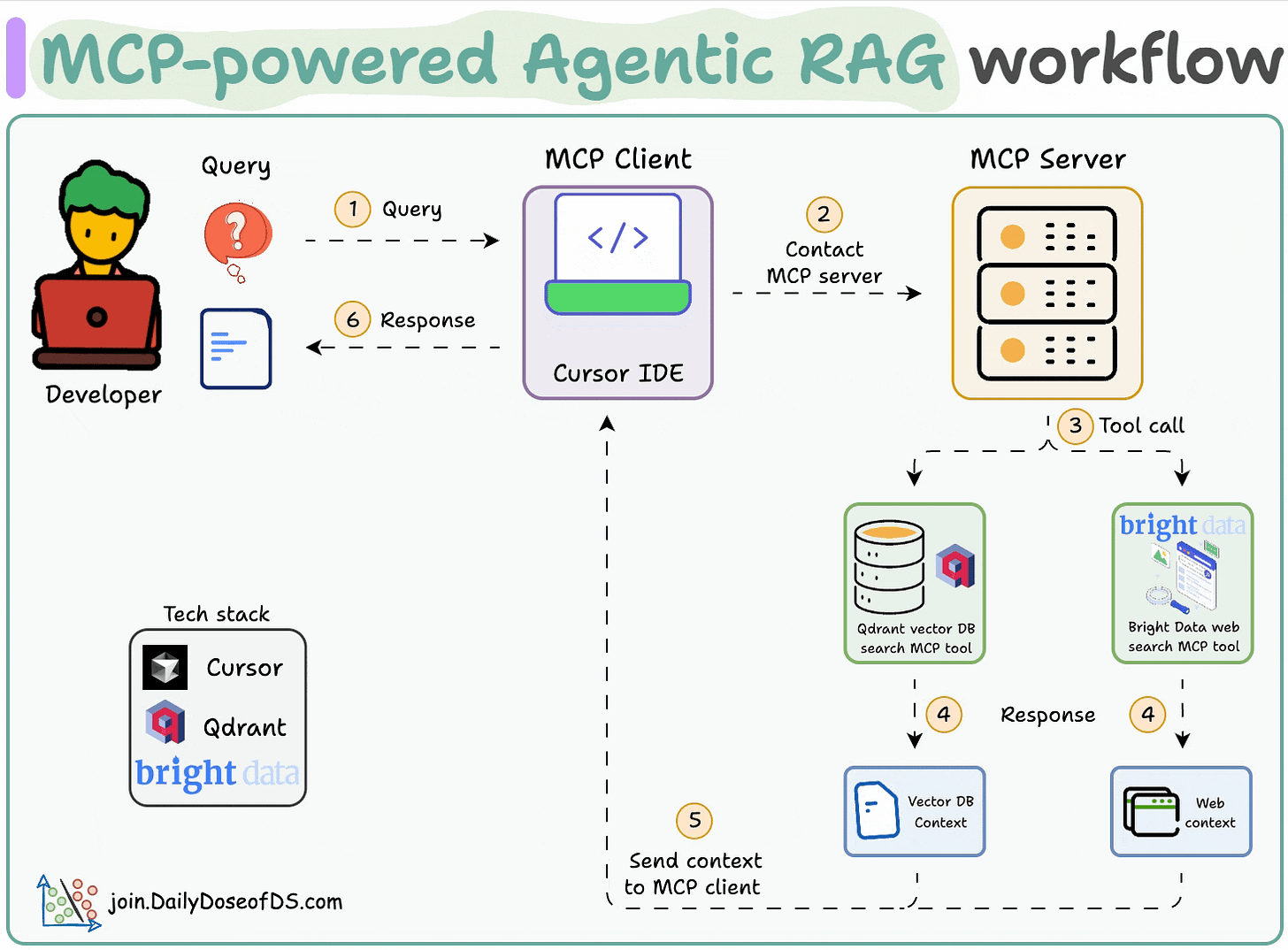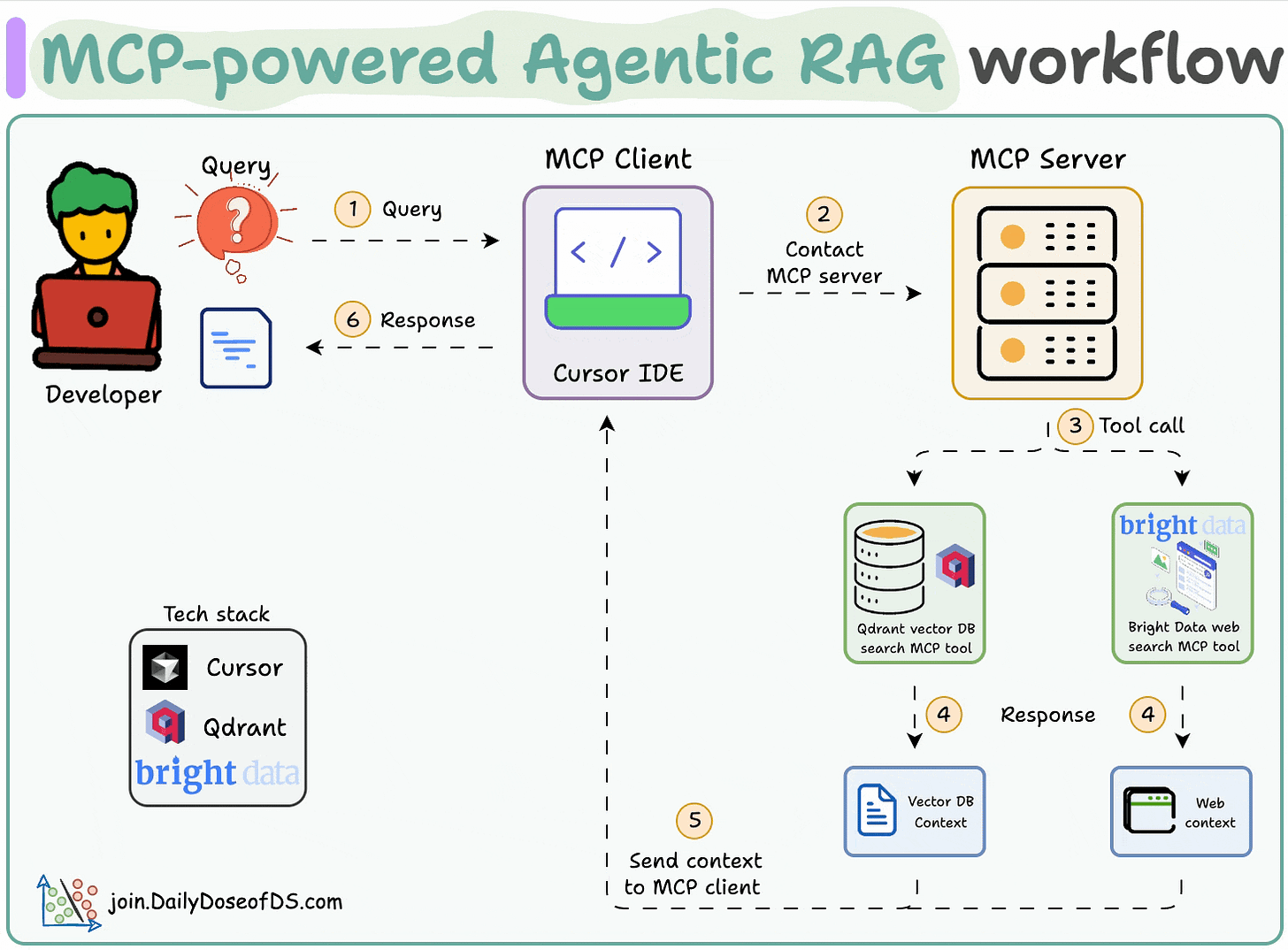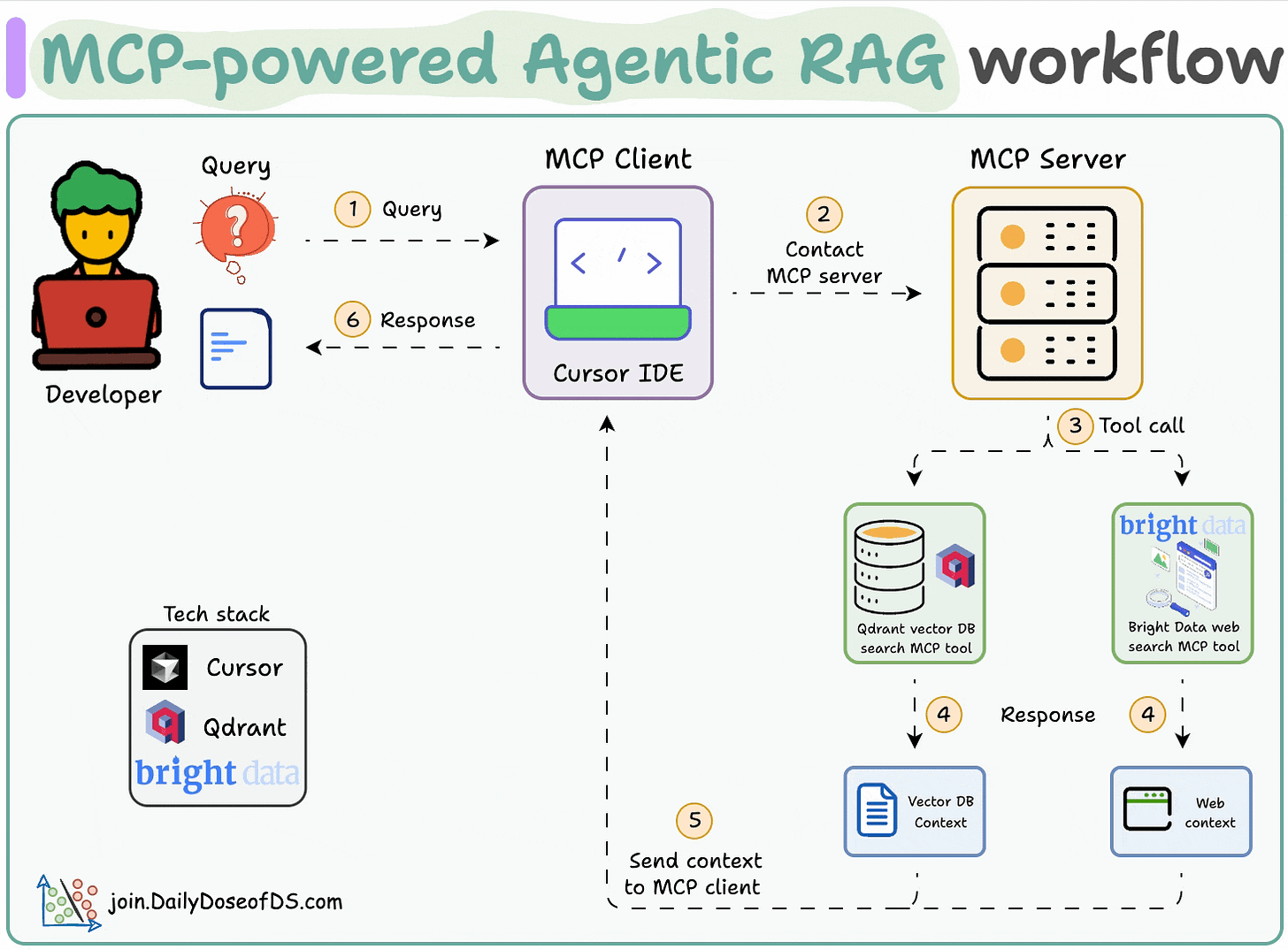
- 1) The user inputs a query through the MCP client (Cursor).
- 2-3) The client contacts the MCP server to select a relevant tool.
- 4-6) The tool output is returned to the client to generate a response.
The code is linked later in the issue.
Let's implement this!
#1) Launch an MCP server
First, we define an MCP server with the host URL and port.

#2) Vector DB MCP tool
A tool exposed through an MCP server has two requirements:
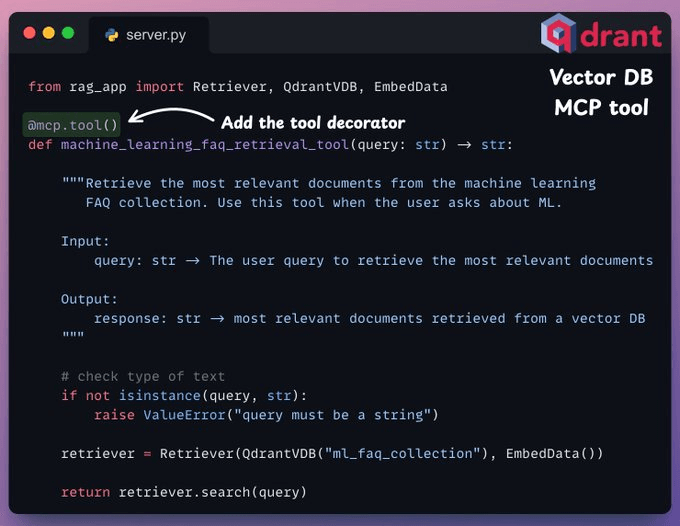
- It must be decorated with the "tool" decorator.
- It must have a clear docstring.
Below, we have an MCP tool to query a vector DB. It stores ML-related FAQs.
#3) Web search MCP tool

If the query is unrelated to ML, we need a fallback mechanism.
Thus, we resort to web search using Bright Data's SERP API to scrape data at scale across several sources to get relevant context.
#4) Integrate MCP server with Cursor
In our setup, Cursor is an MCP host/client that uses the tools exposed by the MCP server.
To integrate the MCP server, go to Settings → MCP → Add new global MCP server.
In the JSON file, add what's shown below👇
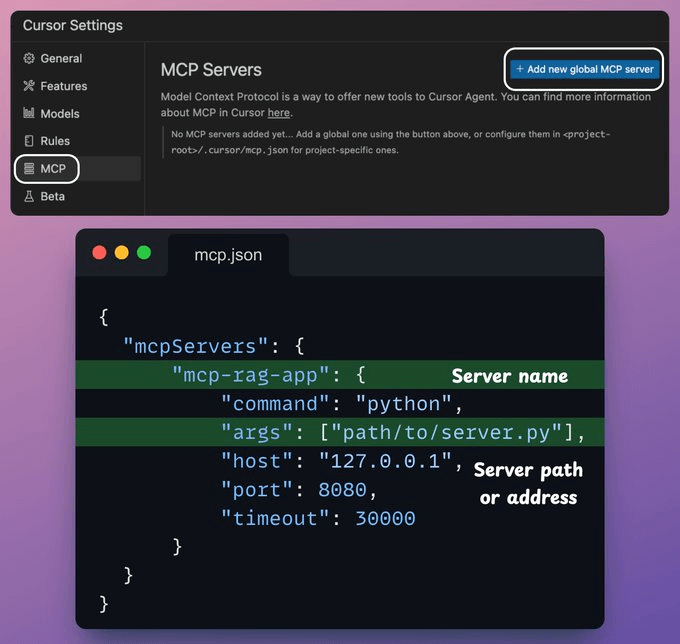
Done! Your local MCP server is live and connected to Cursor 🚀!
It has two MCP tools:

- Bright Data web search tool to scrape data at scale.
- Vector DB search tool to query the relevant documents.
Next, we interact with the MCP server.
- When we ask an ML-related query, it invokes the vector DB tool.
- But when we ask a general query, it invokes the Bright Data web search tool to gather web data at scale from various sources.
When Agents use tools, they run into issues like IP blocks, bot traffic, captcha solvers, etc. This hinders the Agent's execution.
To solve this, we used Bright Data in this demo.
It lets you:
- Scrape data for Agents at scale without getting blocked.
- Simulate user behavior using advanced browser tools.
- Build Agentic apps with real-time and historical web data.
Find the code in this GitHub repo: MCP implementation repo.
Let's move to the next project now!