16 Techniques to Supercharge and Build Real-world RAG Systems (Part 1)
A comprehensive guide with practical tips on building robust RAG solutions.
Introduction
On paper, implementing a RAG system seems simple—connect a vector database, process documents, embed the data, embed the query, query the vector database, and prompt the LLM.
But in practice, turning a prototype into a high-performance application is an entirely different challenge.
Many developers build their first LLM-powered tool in a few weeks but soon realize that scaling it for real-world use is where the real work begins.
Performance bottlenecks, hallucinations, and inefficient retrieval pipelines can turn an initially promising system into an unreliable one.
This guide is for those who have moved past experimentation and are now focused on building production-ready RAG applications.
We'll go beyond the basics and explore 16 practical techniques to refine retrieval, improve response quality, and optimize speed.
But before diving in, let’s revisit the key components of a standard RAG setup to pinpoint where these improvements can be made.
What's required for a production-ready solution?
The rapid advancements in LLMs are impressive, but let’s be honest—the biggest impact on RAG performance doesn’t come from just upgrading to the latest model. Instead, it comes from the fundamentals, which are:
☑ The quality of your data.
☑ How well it’s prepared.
☑ How efficiently it’s processed.
That's it!
Whether during inference or data ingestion, every step—from cleaning and structuring information to retrieving the right context—shapes the final output.
Expecting larger models to magically fix flawed data is not optimal.
In fact, even if we someday reach a point where AI can extract meaning from messy, unstructured data without intervention, the cost and efficiency trade-offs will still make structured workflows the smarter choice.
That’s why RAG (or Agentic RAG, shown below) isn’t just a "trend"—it’s a key approach that will consistently help us build LLM apps that are real-time and knowledge-driven.
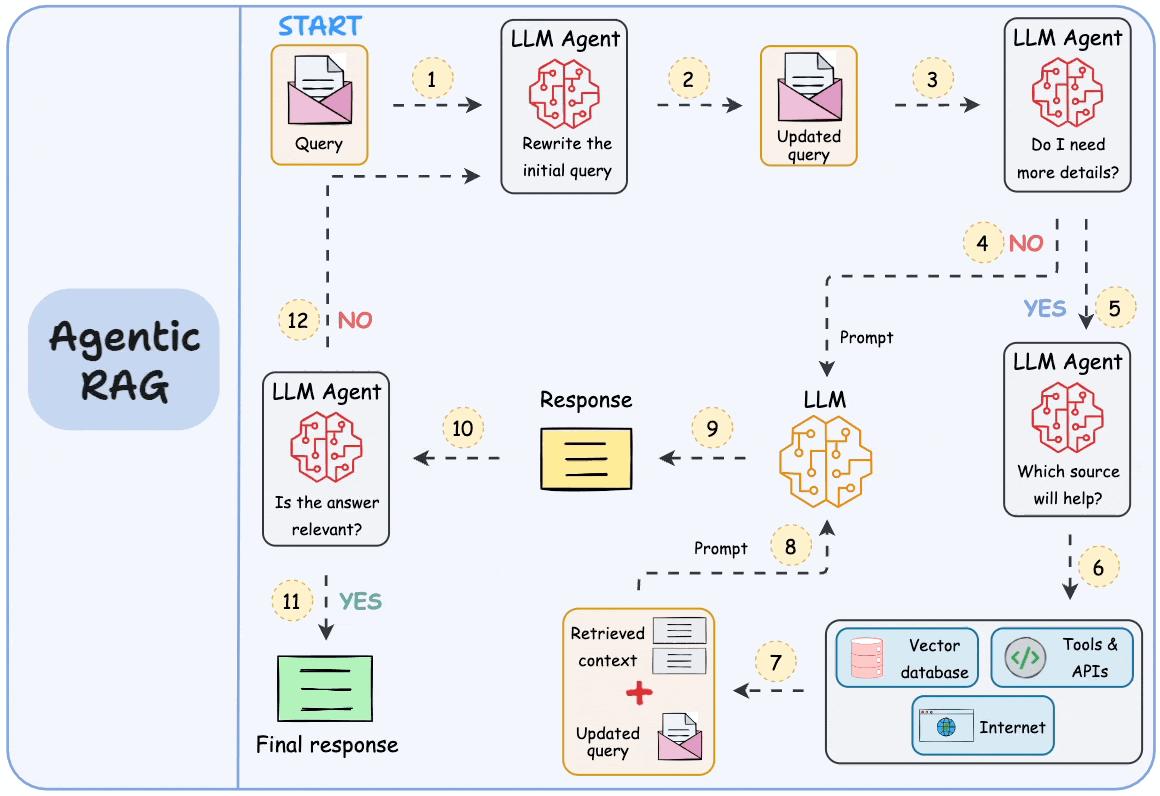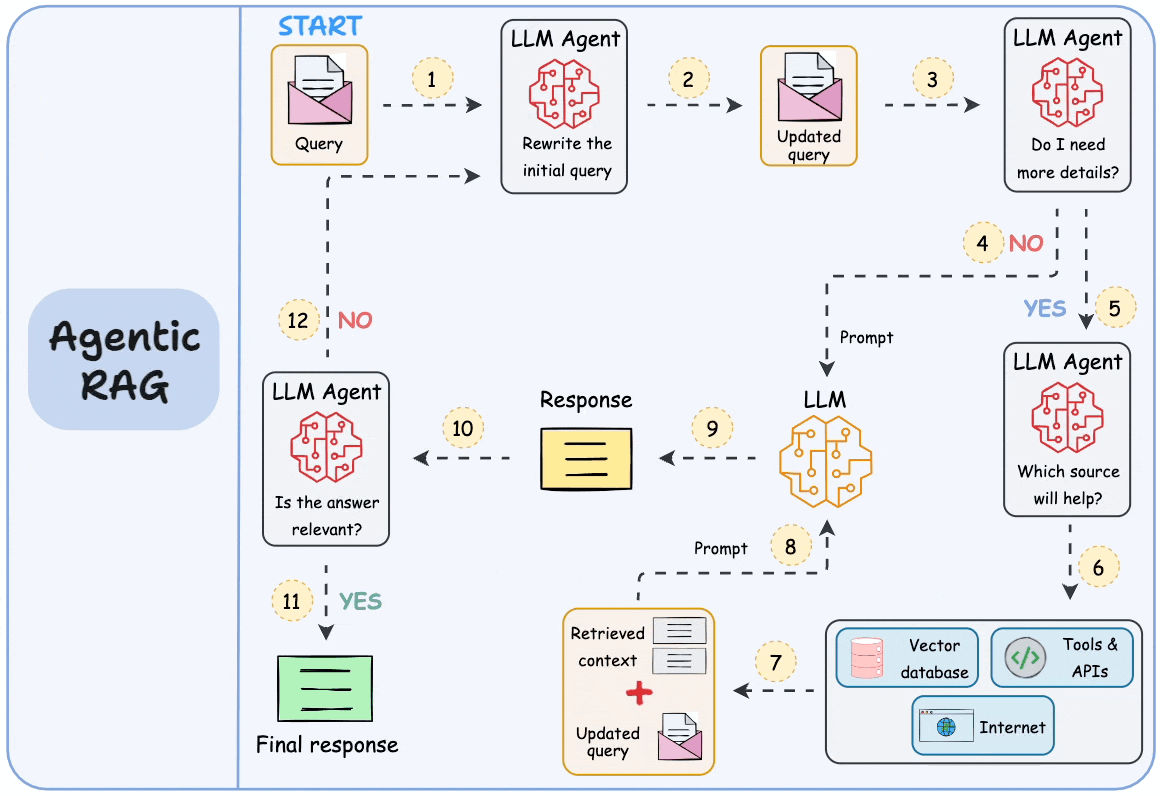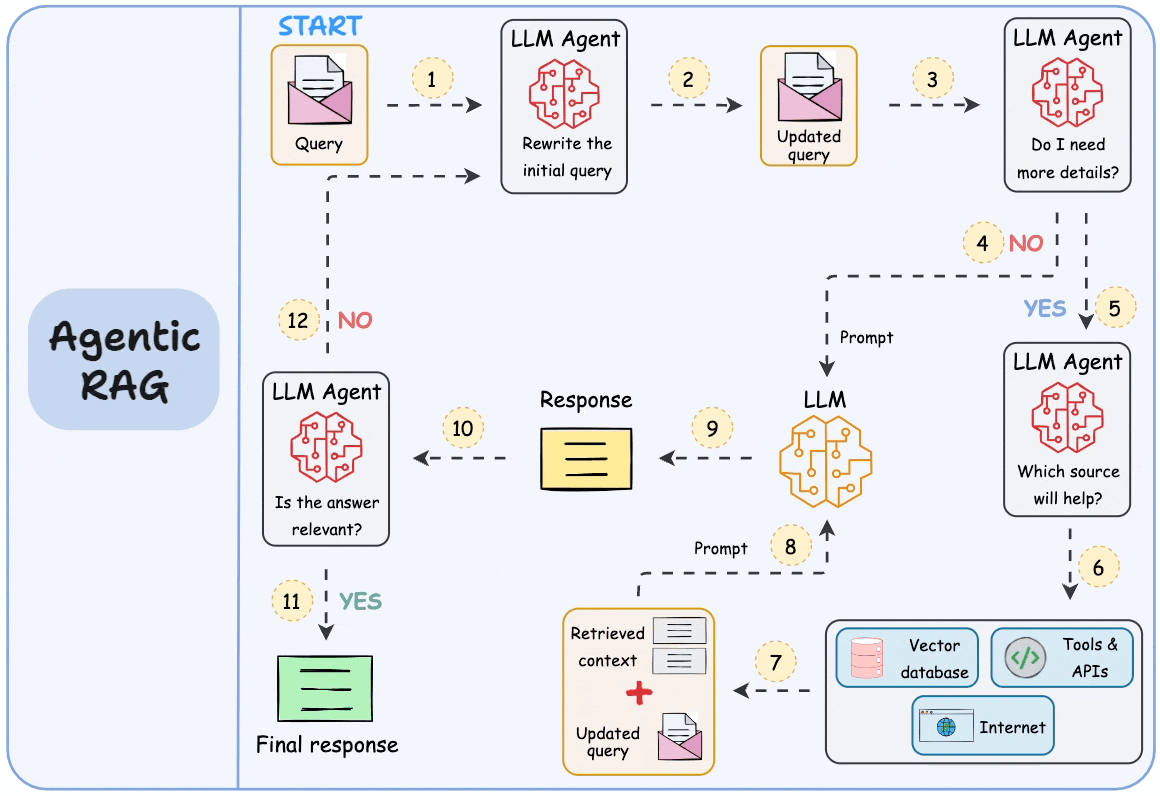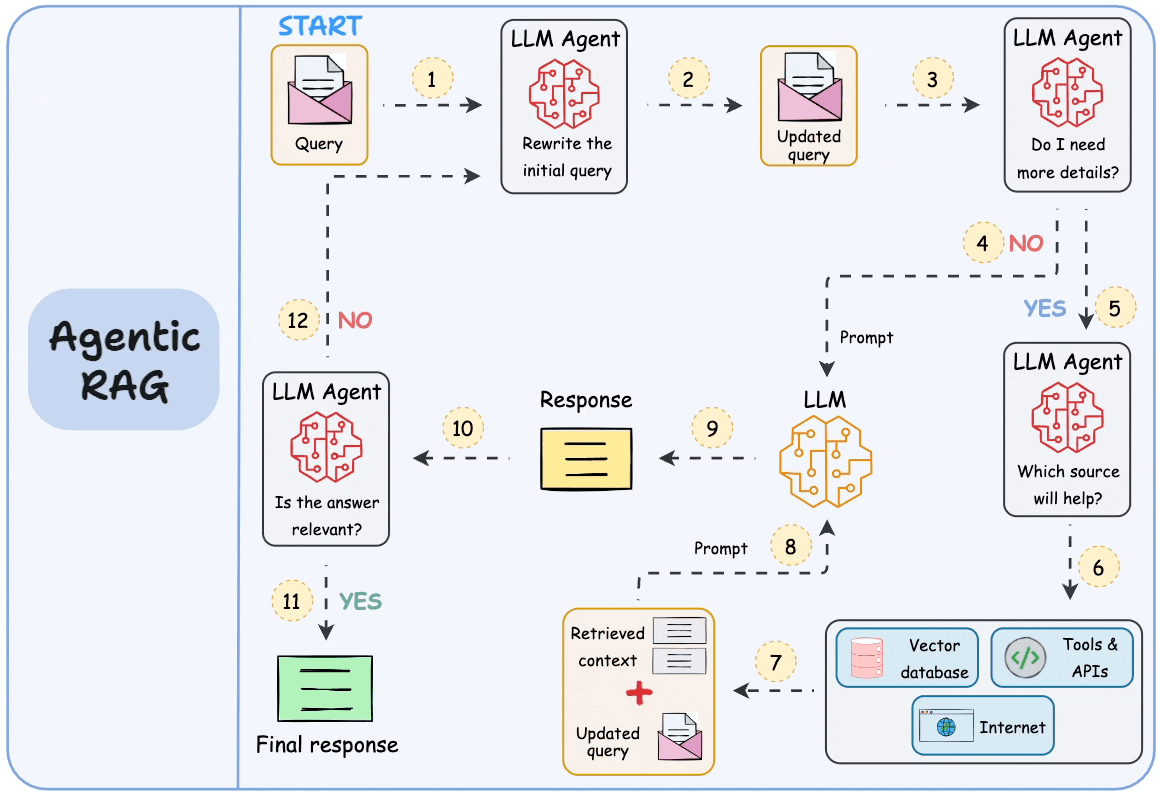
Moreover, while AGI (Artificial General Intelligence) is often seen as the ultimate goal, it’s unlikely that a single, all-knowing model will emerge as the solution.
Instead, the future lies in systems—a combination of LLMs, multimodal models, and supporting tools that work together seamlessly.
If that’s the case, the journey towards AGI is for all of us. We can fill the space between the large models and real-world applications and, step by step, make such a system more intelligent and capable over time.
That means the responsibility to make AI more capable isn’t just on the model creators. It’s on the builders and the practitioners to optimize how these models interact with real-world data.
This article explores practical techniques to increase retrieval accuracy, streamline data preparation, and structure your RAG system for long-term reliability.
These strategies will help answer key questions like:
- How to build robust retrieval mechanisms?
- How can the LLM interpret data effectively?
- Would a chain of LLMs help in refining responses? Is it worth the cost?
- How do we prevent hallucinations while maintaining response diversity?
- What role does embedding quality play in retrieval performance?
- Should document chunking strategies be adapted dynamically?
- How do we integrate multimodal inputs (text, images, tables) into a seamless RAG pipeline?
- What caching strategies help reduce redundant API calls and latency?
- How can retrieval evaluation be automated for continuous improvement?
Before jumping into advanced techniques, let’s first establish a baseline by looking at Naive RAG—the simplest form of a retrieval-augmented system. Understanding its limitations will help us appreciate the optimizations that follow.
If you're already familiar with the standard RAG setup, feel free to skip ahead. Otherwise, let’s quickly lay the groundwork.
A quick recap
Feel free to skip section if you have already read Part 1 and move to the next section instead.
To build a RAG system, it's crucial to understand the foundational components that go into it and how they interact. Thus, in this section, let's explore each element in detail.
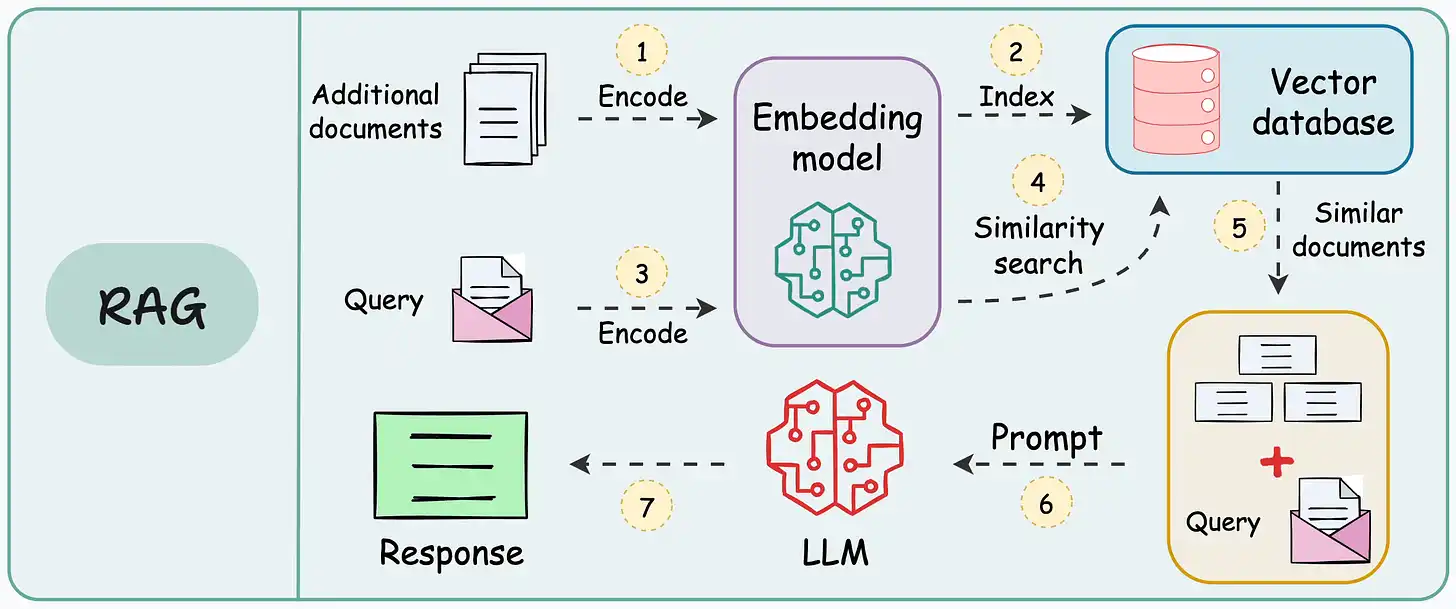
Here's an architecture diagram of a typical RAG setup:
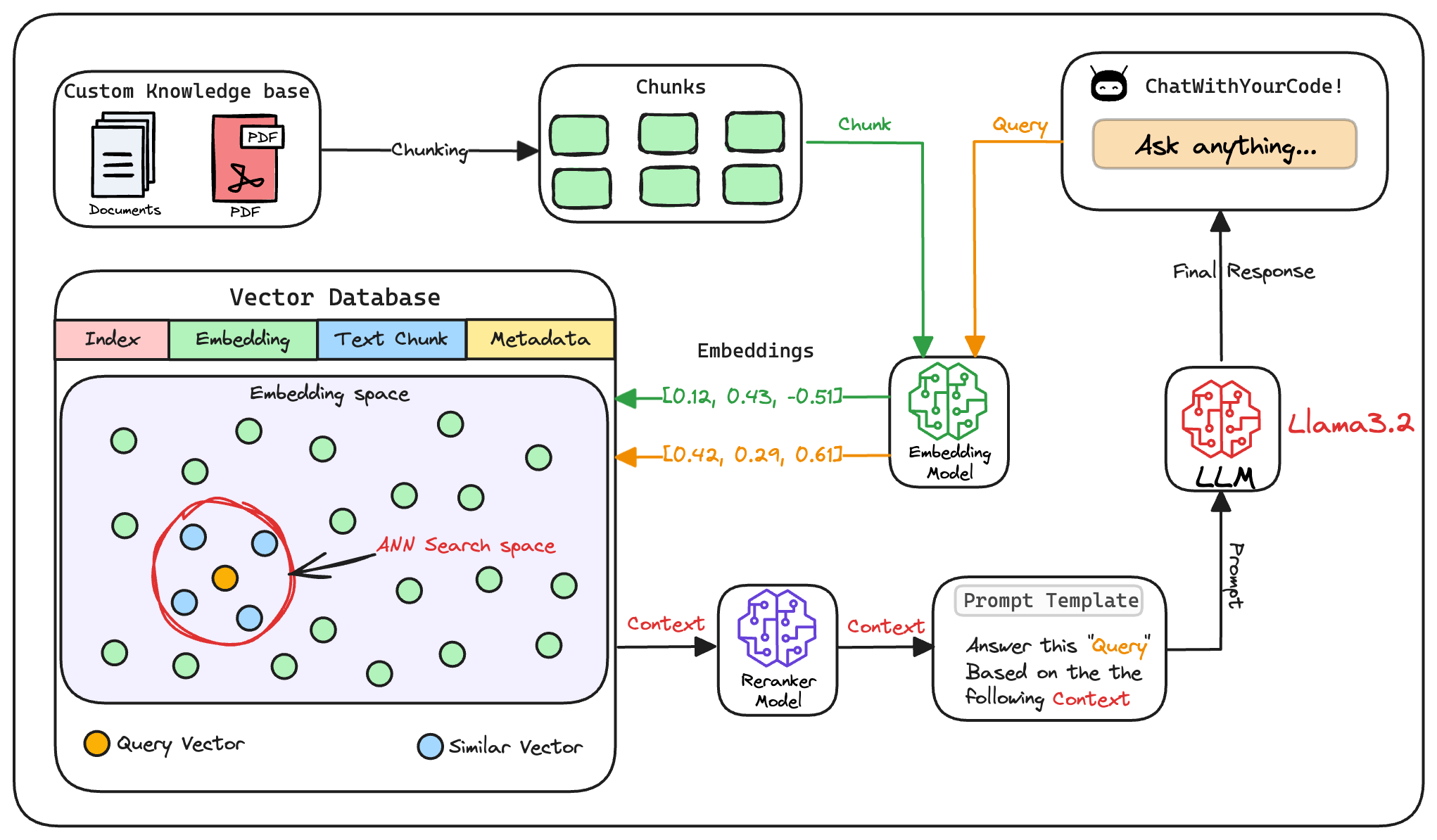
Let's break it down step by step.
We start with some external knowledge that wasn't seen during training, and we want to augment the LLM with:
1) Create chunks
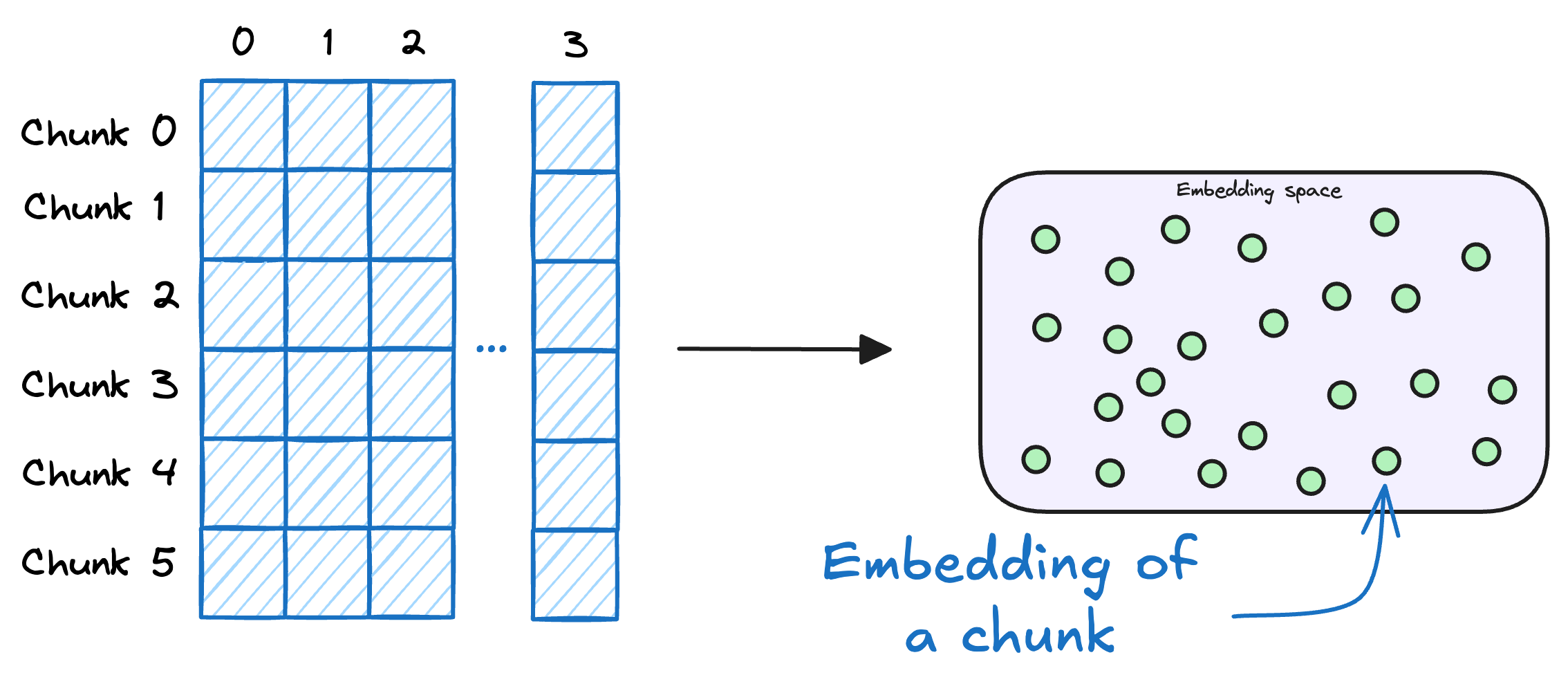
The first step is to break down this additional knowledge into chunks before embedding and storing it in the vector database.
We do this because the additional document(s) can be pretty large. Thus, it is important to ensure that the text fits the input size of the embedding model.
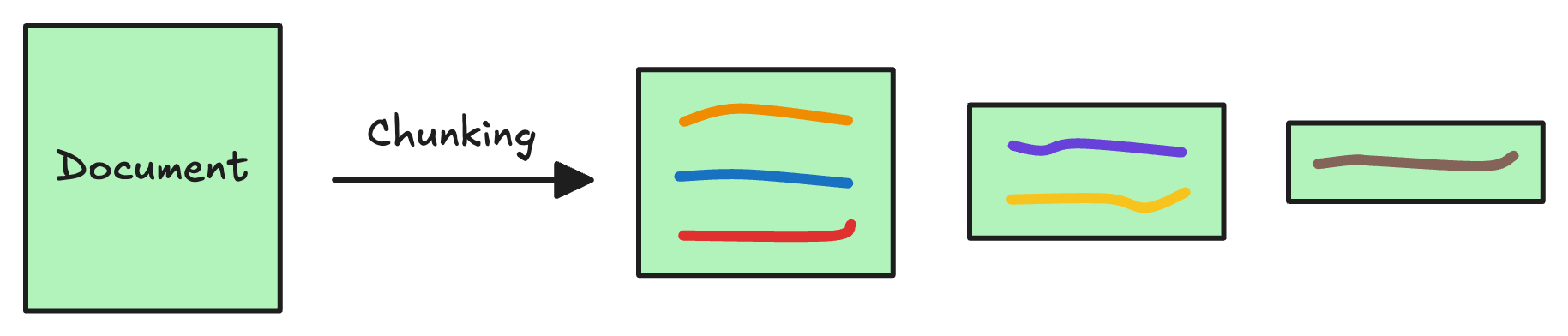
Moreover, if we don't chunk, the entire document will have a single embedding, which won't be of any practical use to retrieve relevant context.
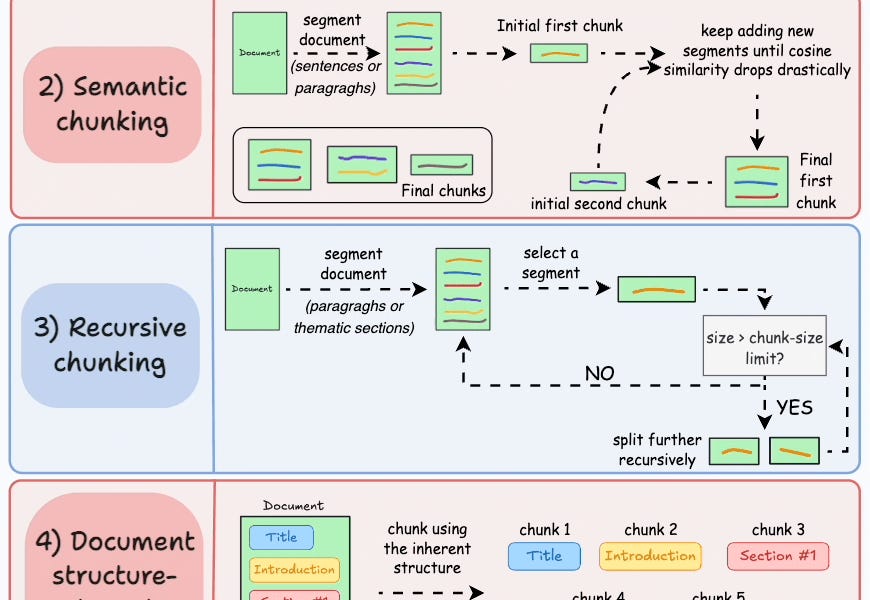
We covered chunking strategies recently in the newsletter here:
2) Generate embeddings
After chunking, we embed the chunks using an embedding model.
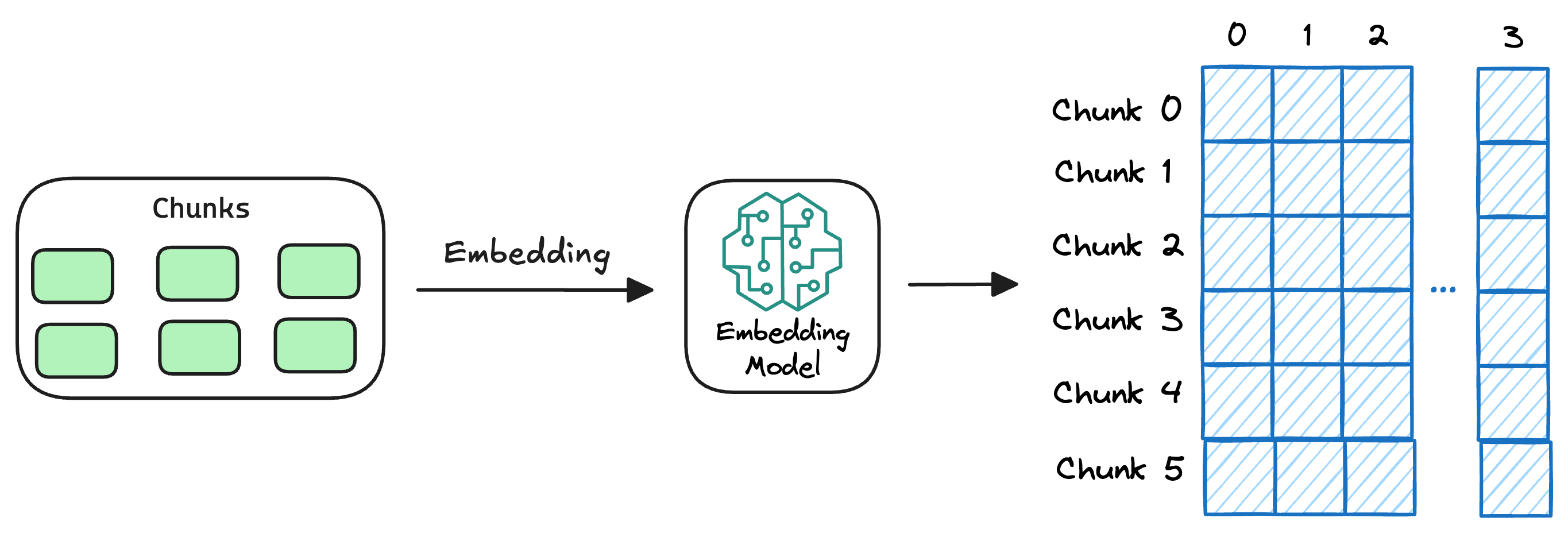
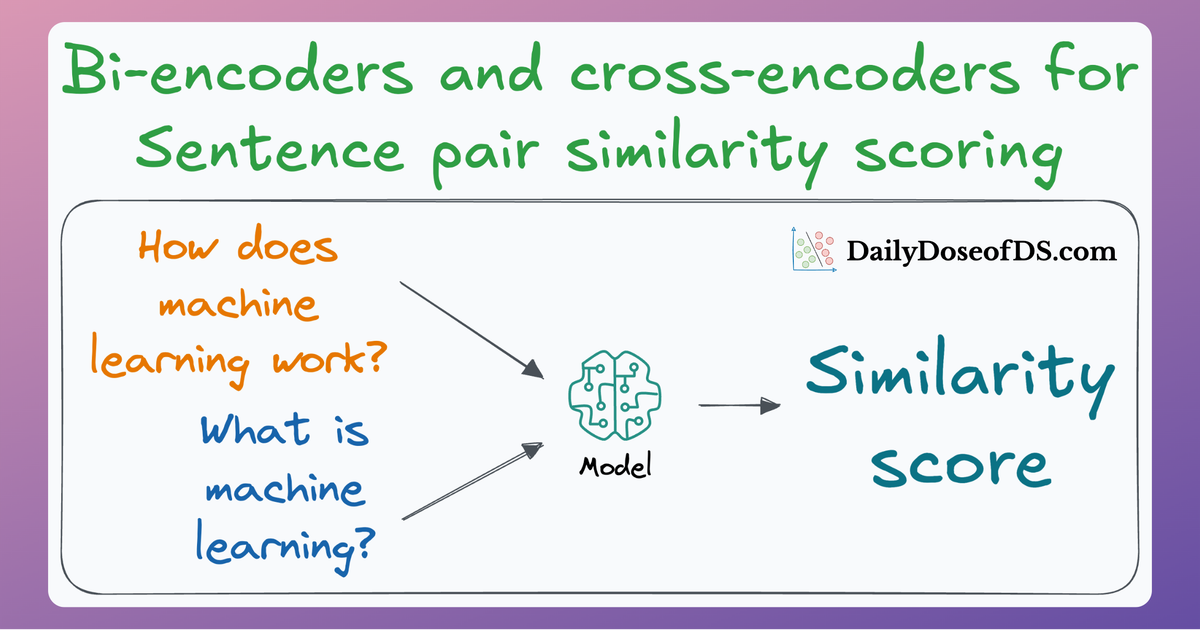
Since these are “context embedding models” (not word embedding models), models like bi-encoders (which we discussed recently) are highly relevant here.
3) Store embeddings in a vector database
These embeddings are then stored in the vector database:
This shows that a vector database acts as a memory for your RAG application since this is precisely where we store all the additional knowledge, using which the user's query will be answered.
With that, our vector databases has been created and information has been added. More information can be added to this if needed.
Now, we move to the query step.
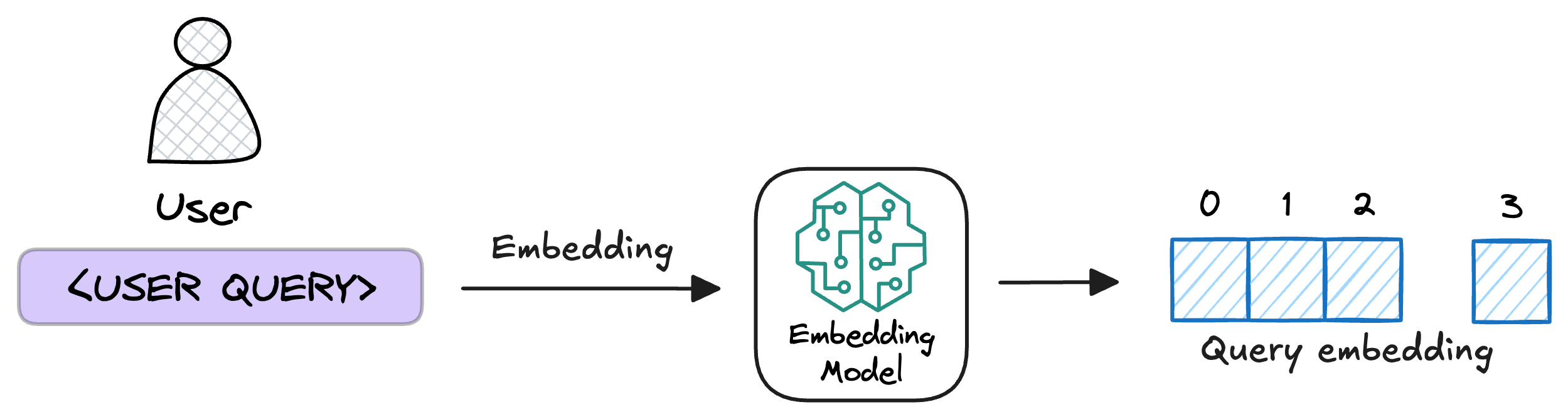
4) User input query
Next, the user inputs a query, a string representing the information they're seeking.
5) Embed the query
This query is transformed into a vector using the same embedding model we used to embed the chunks earlier in Step 2.
6) Retrieve similar chunks
The vectorized query is then compared against our existing vectors in the database to find the most similar information.
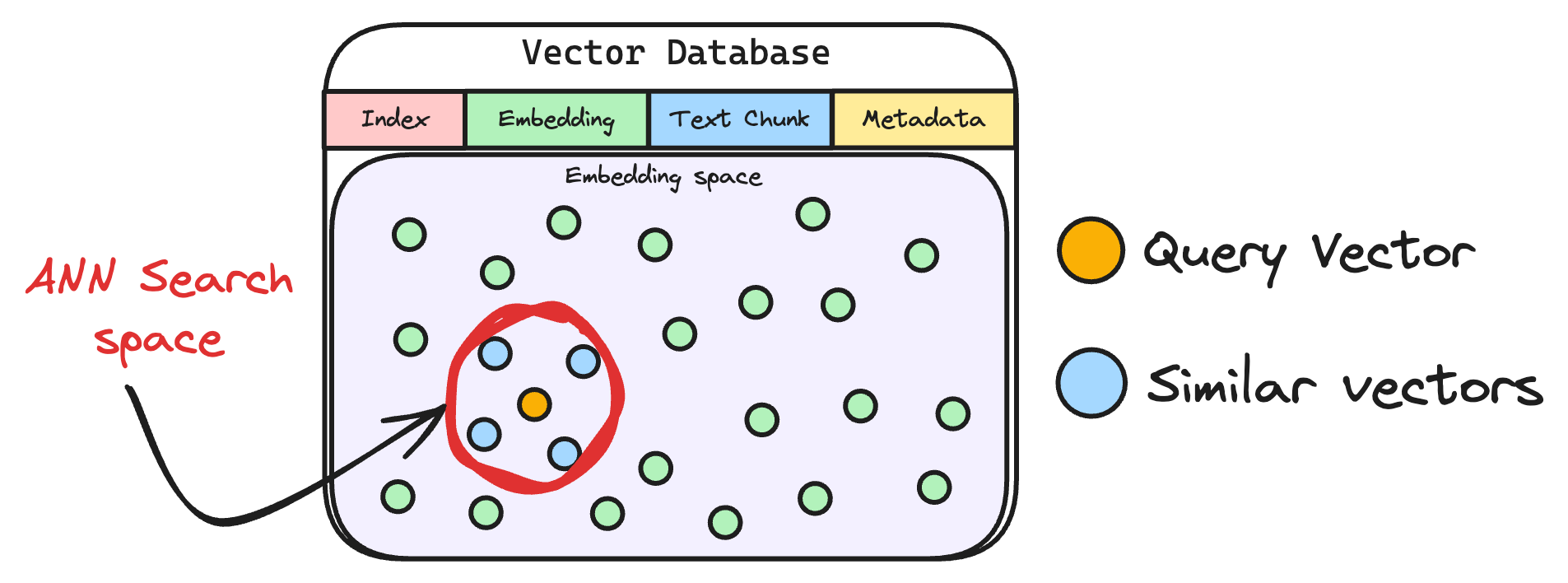
The vector database returns the $k$ (a pre-defined parameter) most similar documents/chunks (using approximate nearest neighbor search).
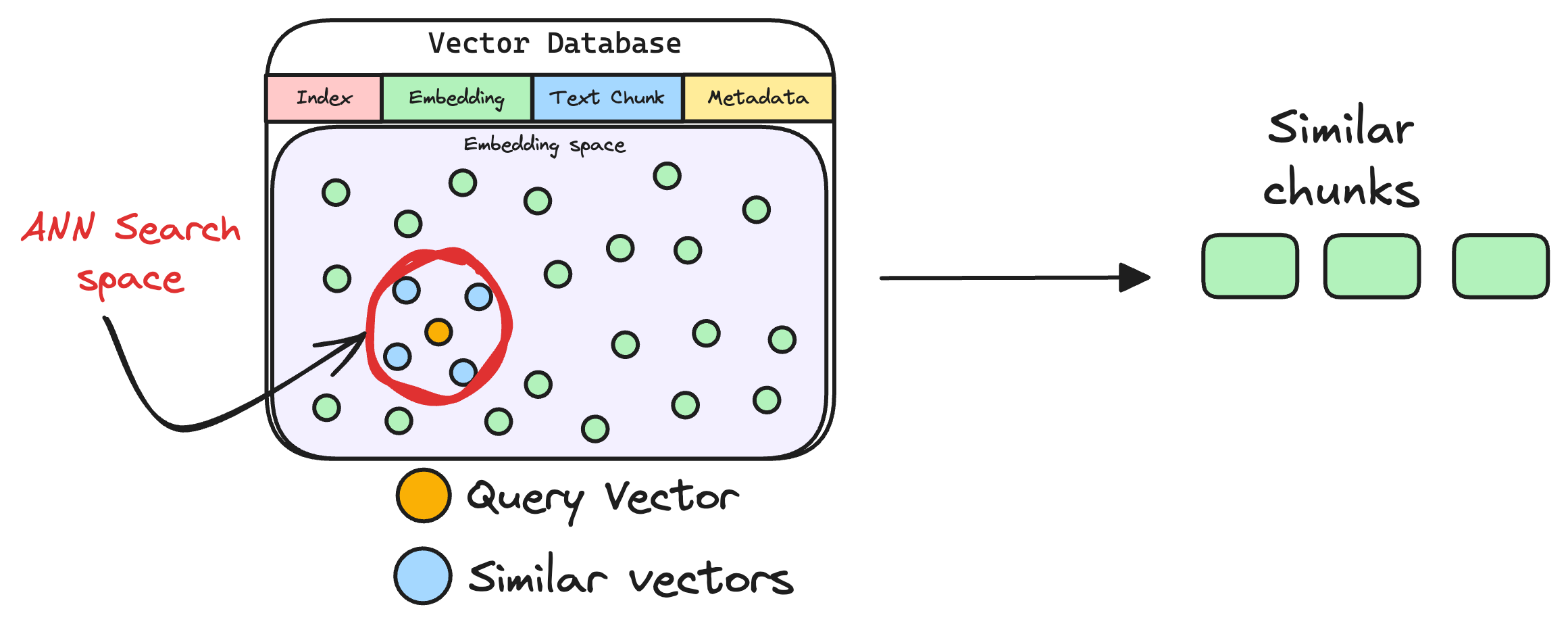
It is expected that these retrieved documents contain information related to the query, providing a basis for the final response generation.
7) Re-rank the chunks
After retrieval, the selected chunks might need further refinement to ensure the most relevant information is prioritized.
In this re-ranking step, a more sophisticated model (often a cross-encoder, which we discussed last week) evaluates the initial list of retrieved chunks alongside the query to assign a relevance score to each chunk.
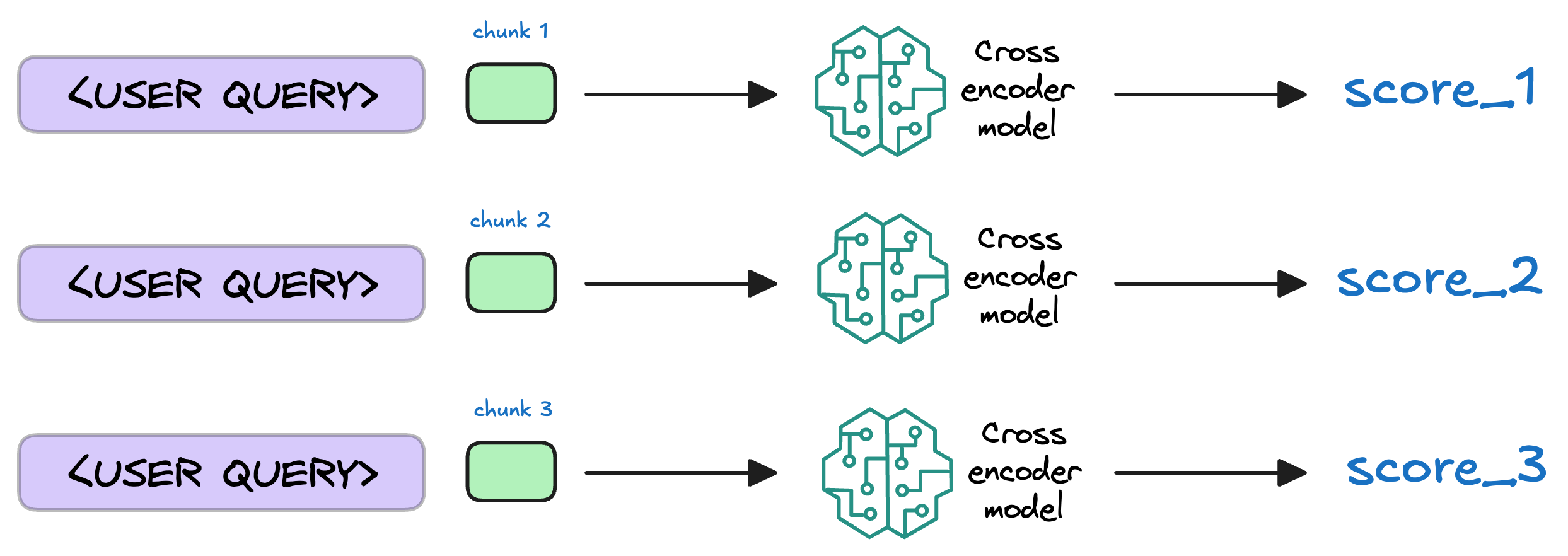
This process rearranges the chunks so that the most relevant ones are prioritized for the response generation.
That said, not every RAG app implements this, and typically, they just rely on the similarity scores obtained in step 6 while retrieving the relevant context from the vector database.
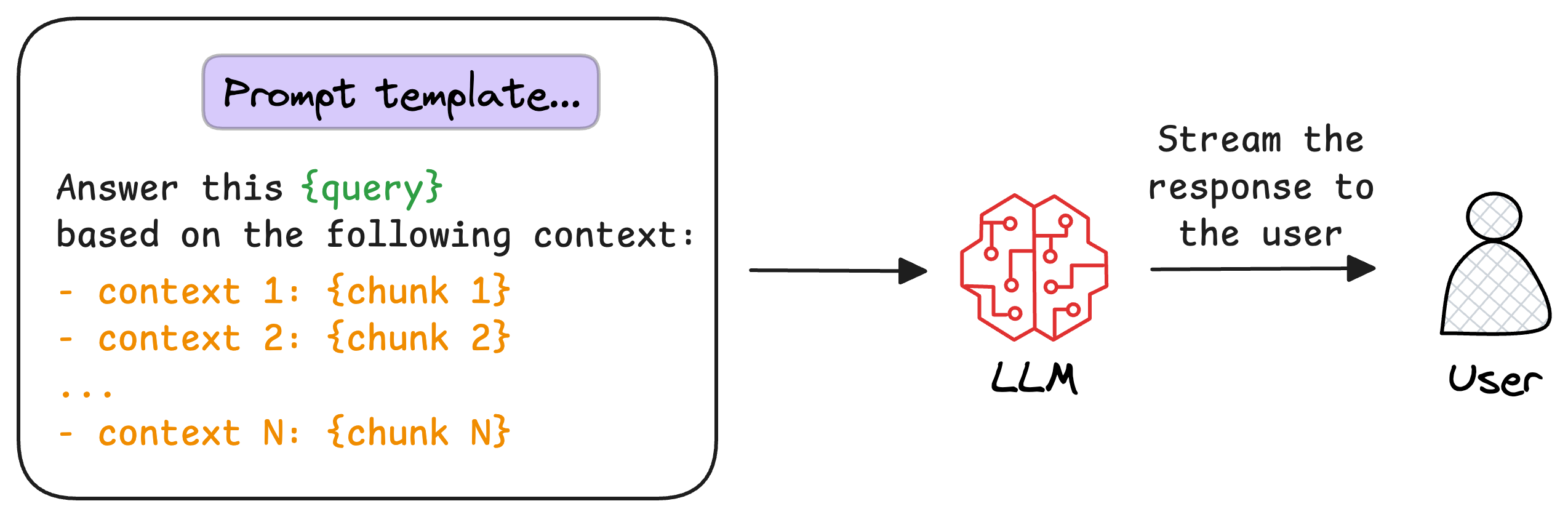
8) Generate the final response
Almost done!
Once the most relevant chunks are re-ranked, they are fed into the LLM.
This model combines the user's original query with the retrieved chunks in a prompt template to generate a response that synthesizes information from the selected documents.
This is depicted below:
Summary
As you can already tell from the above discussion, we use a handful of other components besides an LLM:
- A vector database for semantic search.
- Data preprocessors to process textual data.
- and more.
There's nothing new in these components—all of these components have been around for several years.
The key point is that RAG brings all of these components together to solve a particular problem—Allowing LLMs to act on additional data.
Pitfalls
On paper, implementing a RAG system seems simple—connect a vector database, process documents, embed the data, embed the query, query the vector database, and prompt the LLM.
But in practice, turning a prototype into a high-performance application is an entirely different challenge.
This is because when implementing RAG, we often assume that once relevant content is retrieved, the problem is solved.
However, in reality, several challenges can affect the quality and reliability of the system. Addressing these pitfalls is crucial to moving from a basic implementation to a production-grade solution.
Pitfall 1
A nearest neighbor search will always return something—but how do we know it’s actually useful?
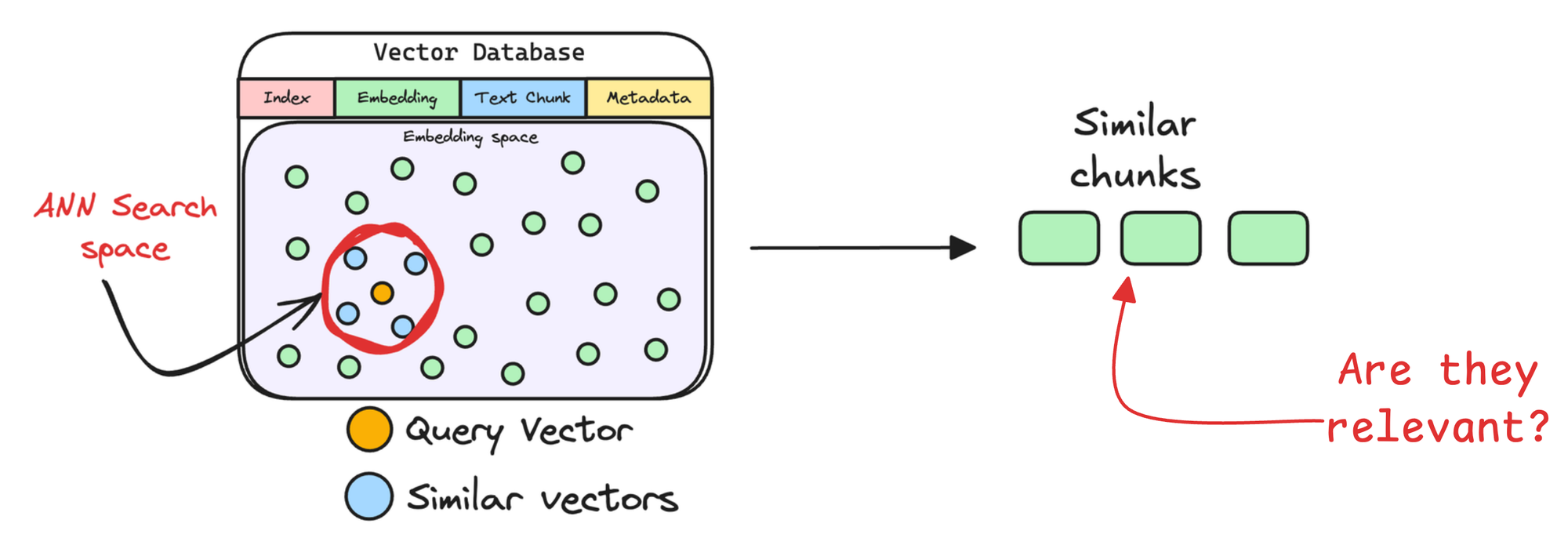
Some retrieved documents may seem relevant based on vector similarity but fail to provide the right context for answering a user’s question. These inaccuracies dilute accuracy, leading to vague or misleading AI responses.
Pitfall 2
Splitting documents into smaller chunks is standard practice, but how small is too small?
- If a chunk contains too little information, it may miss crucial context.
- If it’s too large, irrelevant details can dilute the response. The optimal chunk size varies depending on the use case, but balancing specificity and context is key.
Pitfall 3
How do you ensure your system remains effective over time? LLMOps is not just about deployment—it’s about tracking retrieval quality, response accuracy, and system reliability. This means setting up evaluation metrics like:
- Ground truth comparisons (checking AI responses against known correct answers, if available)
- Embedding drift detection (to track when retrieval starts to degrade)
- Latency and failure rate monitoring (ensuring smooth user experience)
Pitfall 4
Many real-world queries are too complex for a single retrieval step. If a question requires synthesizing multiple pieces of information, a standard RAG pipeline may fall short. Solutions include:
- Agentic workflows: Breaking queries into sub-questions and solving them sequentially.
- Multi-hop retrieval: Searching for intermediate facts before arriving at the final answer.
- Dynamic prompt generation: Adjusting LLM instructions based on the type of query.
Solutions to RAG’s pitfalls
As mentioned above, RAG systems aren’t a single component working in isolation—they’re pipelines where multiple steps interact to generate useful responses.
Each stage presents opportunities for improvement, and fine-tuning even one of them can significantly impact overall performance.
Thus, at a high level, we can break down the RAG process into five key stages, each of which can be optimized: