16 Techniques to Supercharge and Build Real-world RAG Systems (Part 2)
A comprehensive guide with practical tips on building robust RAG solutions.
Introduction
As discussed in Part 1 of this series, on paper, implementing a RAG system seems simple—connect a vector database, process documents, embed the data, embed the query, query the vector database, and prompt the LLM.
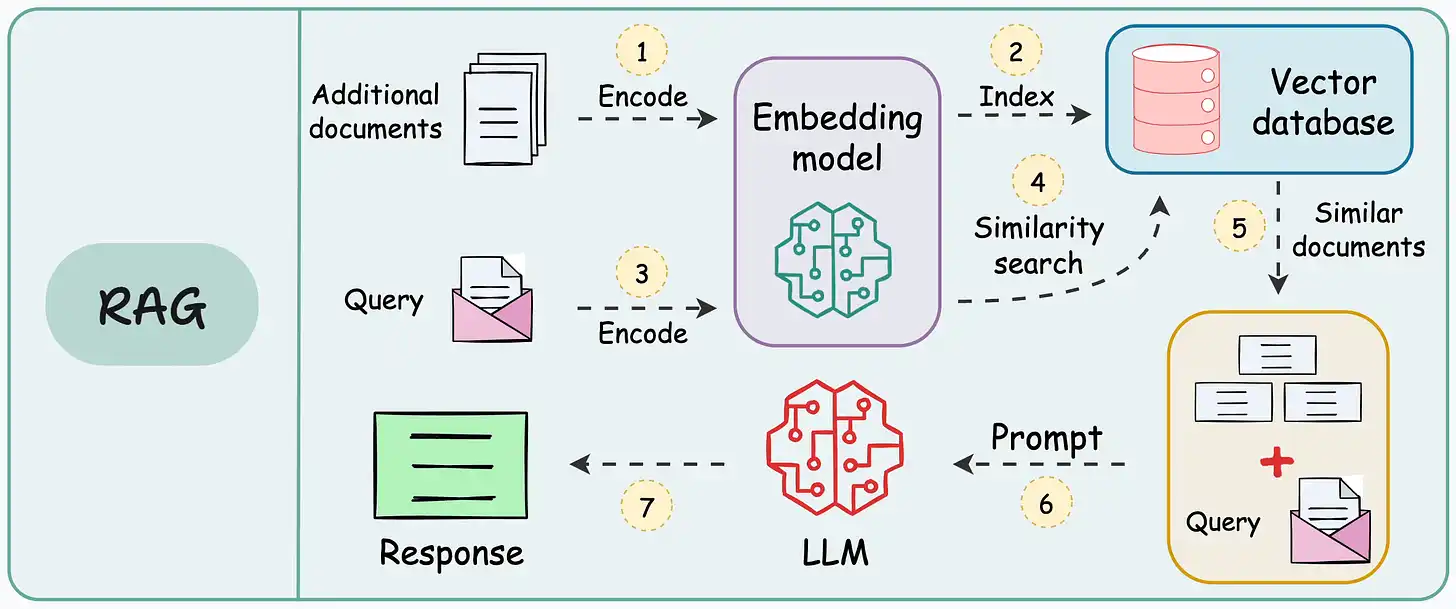
But in practice, turning a prototype into a high-performance application is an entirely different challenge.
Many developers build their first LLM-powered tool in a few weeks but soon realize that scaling it for real-world use is where the real work begins.
Performance bottlenecks, hallucinations, and inefficient retrieval pipelines can turn an initially promising system into an unreliable one.
This series is for those who have moved past experimentation and are now focused on building production-ready RAG applications.
We'll go beyond the basics and explore 16 practical techniques to refine retrieval, improve response quality, and optimize speed.
We have already covered 8 techniques in Part 1 and will continue our discussion in this part by discussing the next 8 techniques.
But before diving in, let’s revisit the key components of a standard RAG setup to pinpoint where these improvements can be made.
What's required for a production-ready solution?
The rapid advancements in LLMs are impressive, but let’s be honest—the biggest impact on RAG performance doesn’t come from just upgrading to the latest model. Instead, it comes from the fundamentals, which are:
☑ The quality of your data.
☑ How well it’s prepared.
☑ How efficiently it’s processed.
That's it!
Whether during inference or data ingestion, every step—from cleaning and structuring information to retrieving the right context—shapes the final output.
Expecting larger models to magically fix flawed data is not optimal.
In fact, even if we someday reach a point where AI can extract meaning from messy, unstructured data without intervention, the cost and efficiency trade-offs will still make structured workflows the smarter choice.
That’s why RAG (or Agentic RAG, shown below) isn’t just a "trend"—it’s a key approach that will consistently help us build LLM apps that are real-time and knowledge-driven.
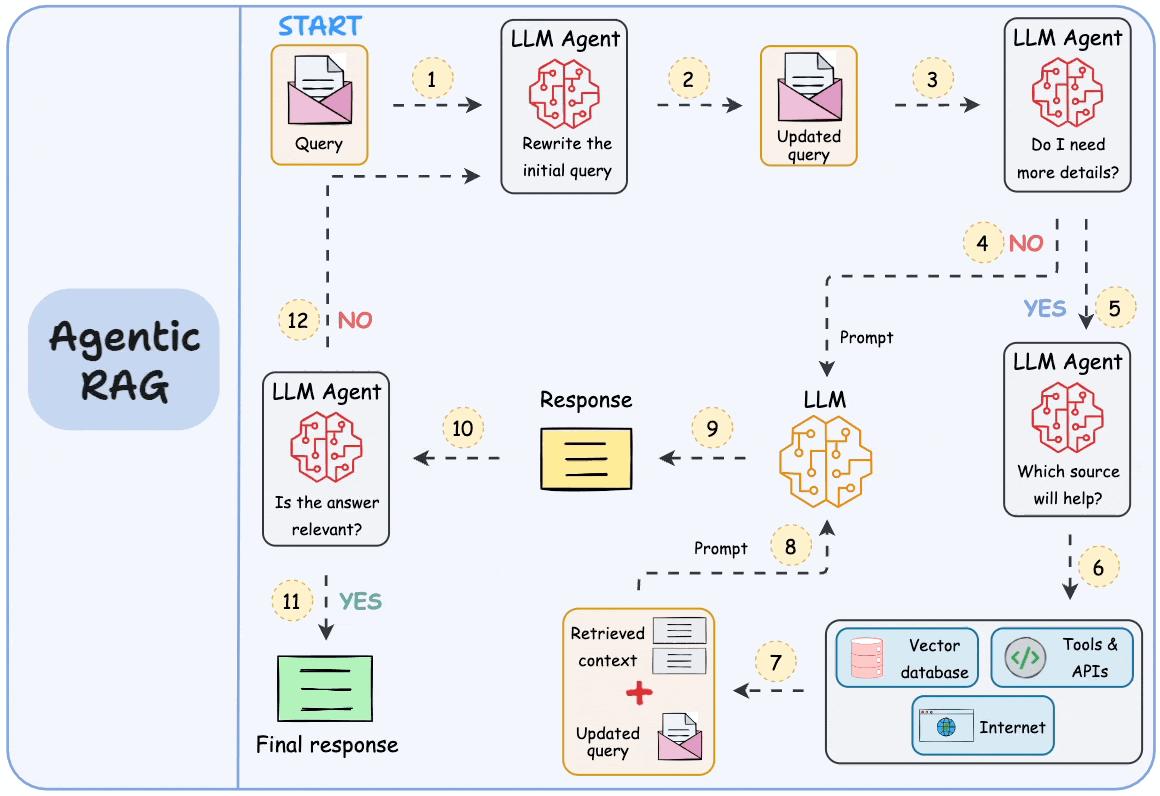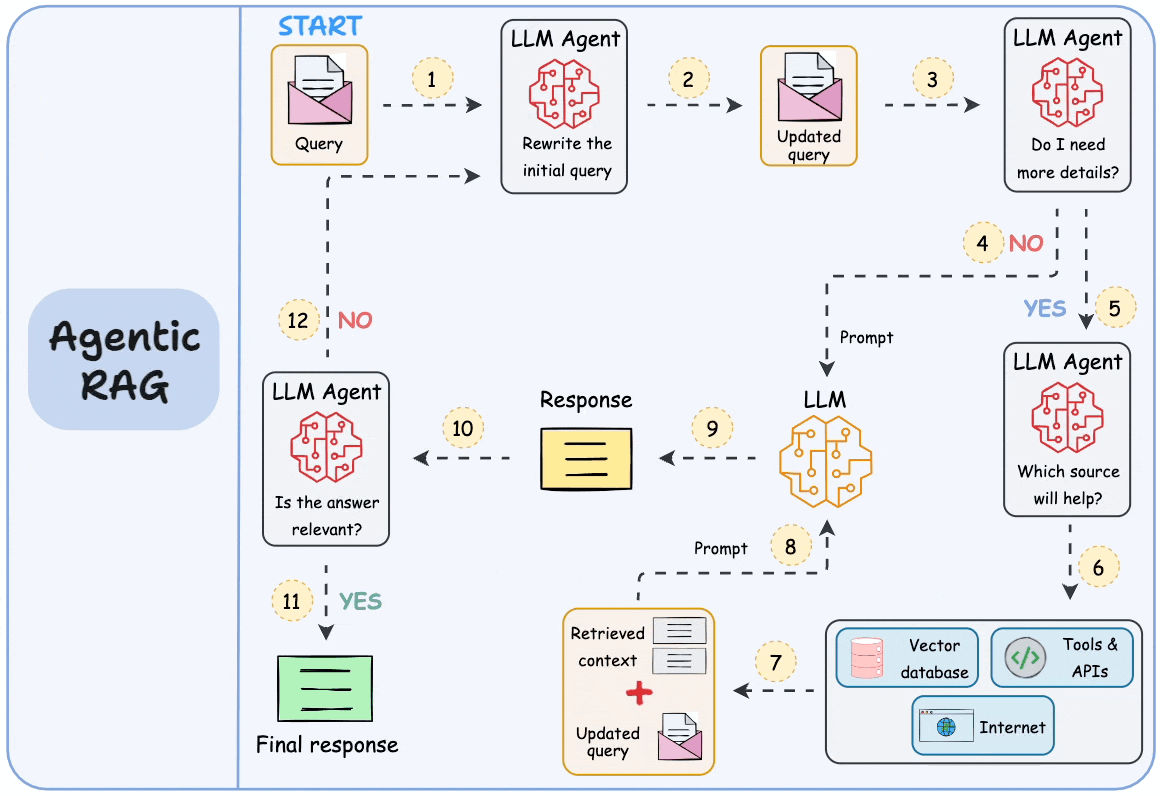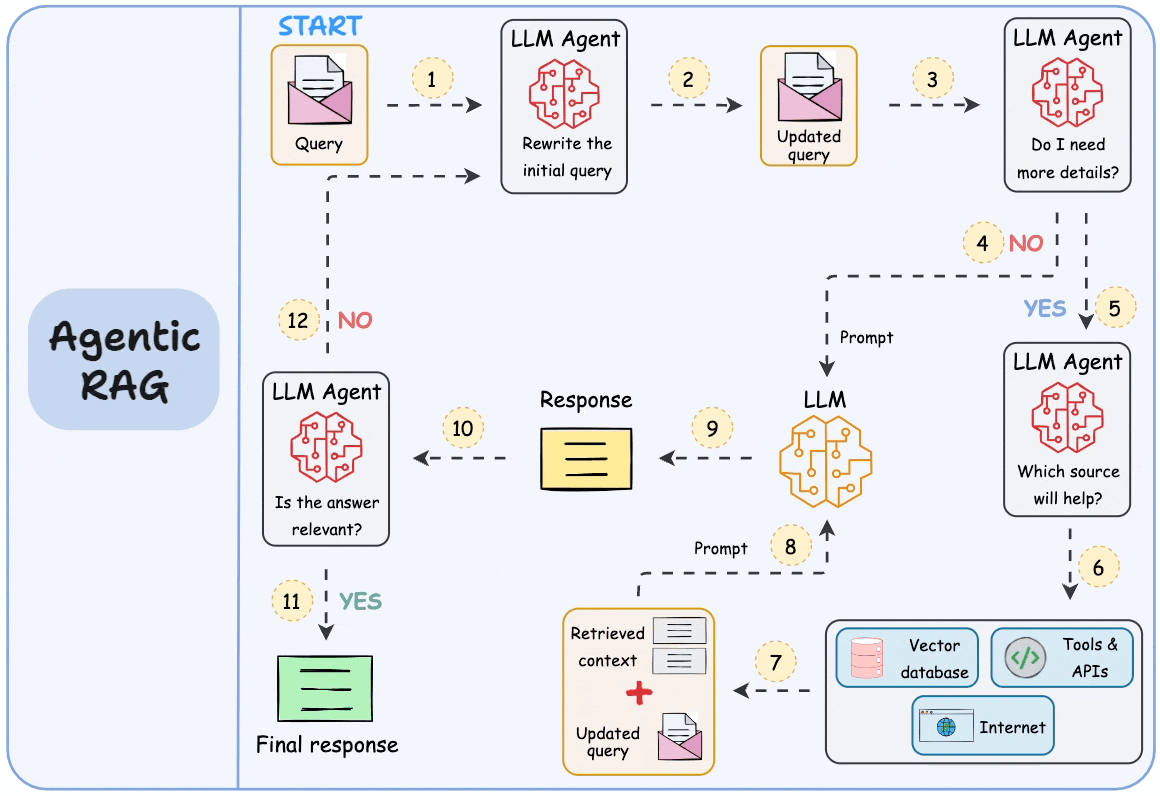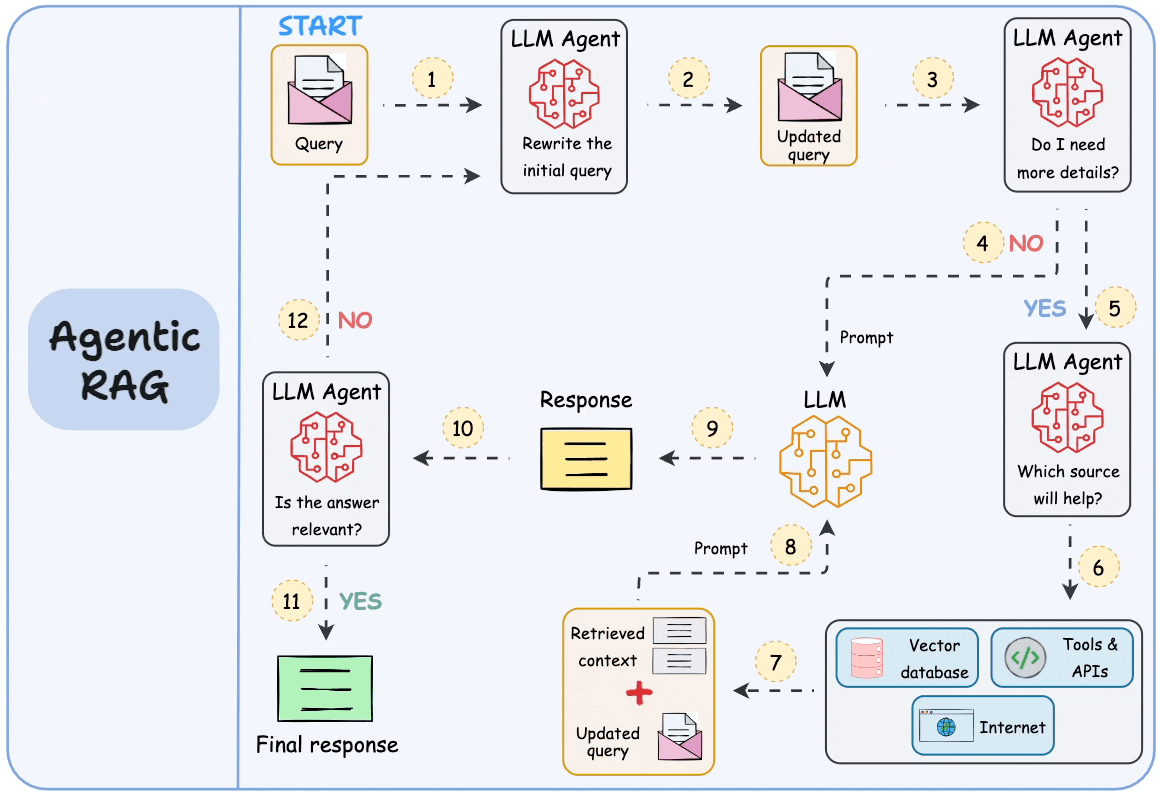
Moreover, while AGI (Artificial General Intelligence) is often seen as the ultimate goal, it’s unlikely that a single, all-knowing model will emerge as the solution.
Instead, the future lies in systems—a combination of LLMs, multimodal models, and supporting tools that work together seamlessly.
If that’s the case, the journey towards AGI is for all of us. We can fill the space between the large models and real-world applications and, step by step, make such a system more intelligent and capable over time.
That means the responsibility to make AI more capable isn’t just on the model creators. It’s on the builders and the practitioners to optimize how these models interact with real-world data.
This article explores practical techniques to increase retrieval accuracy, streamline data preparation, and structure your RAG system for long-term reliability.
These strategies will help answer key questions like:
- How to build robust retrieval mechanisms?
- How can the LLM interpret data effectively?
- Would a chain of LLMs help in refining responses? Is it worth the cost?
- How do we prevent hallucinations while maintaining response diversity?
- What role does embedding quality play in retrieval performance?
- Should document chunking strategies be adapted dynamically?
- How do we integrate multimodal inputs (text, images, tables) into a seamless RAG pipeline?
- What caching strategies help reduce redundant API calls and latency?
- How can retrieval evaluation be automated for continuous improvement?
Next, let's continue our discussion from where we ended Part 1.