


TODAY'S ISSUE
TODAY’S DAILY DOSE OF DATA SCIENCE
FireDucks vs. Pandas vs. DuckDB vs. Polars
I have been using FireDucks quite extensively lately.
For starters, FireDucks is a heavily optimized alternative to Pandas with exactly the same API as Pandas.
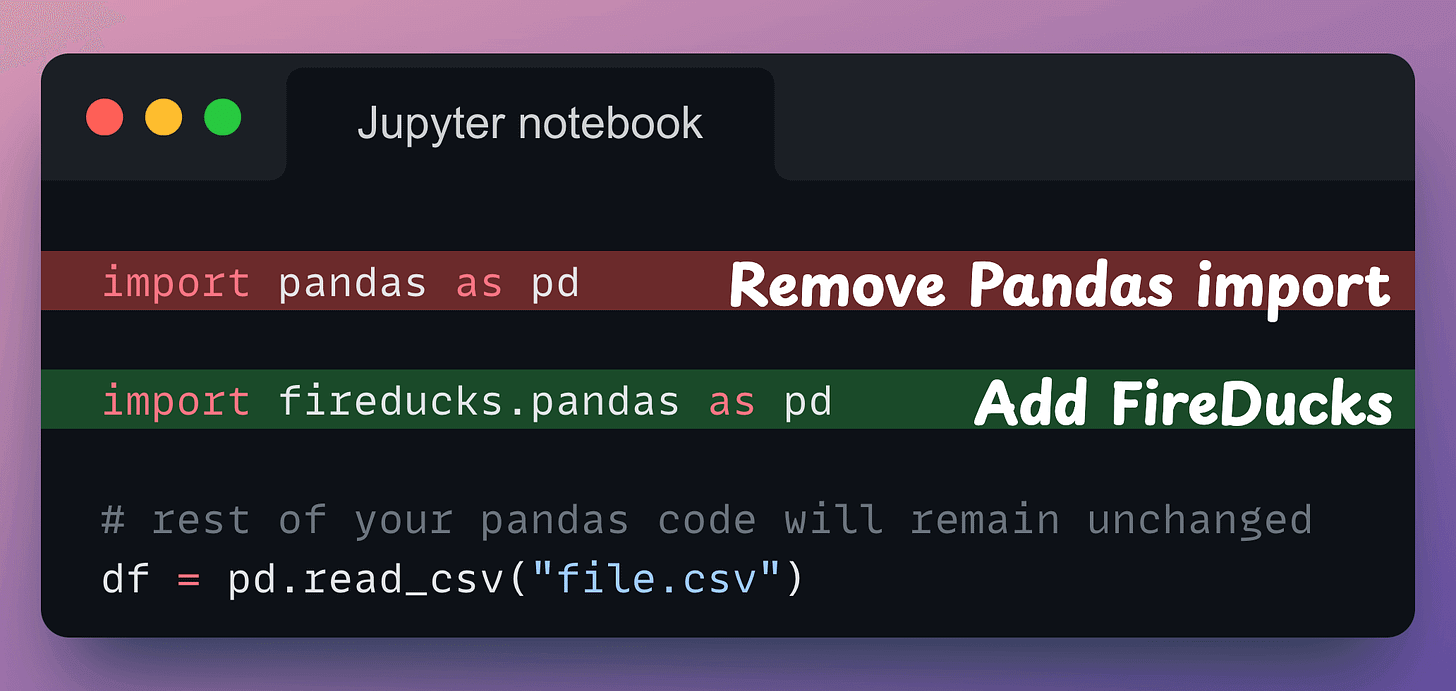
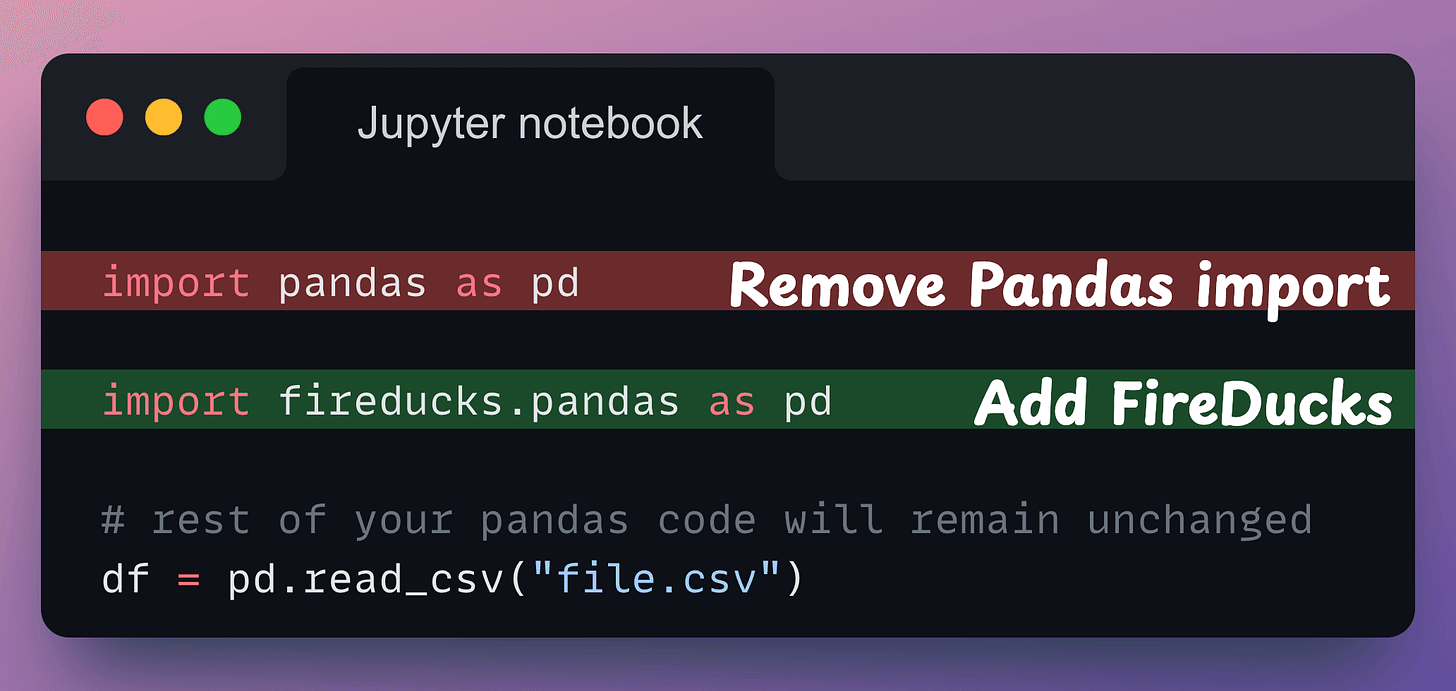
All you need to do is replace the Pandas import with the FireDucks import. That’s it.
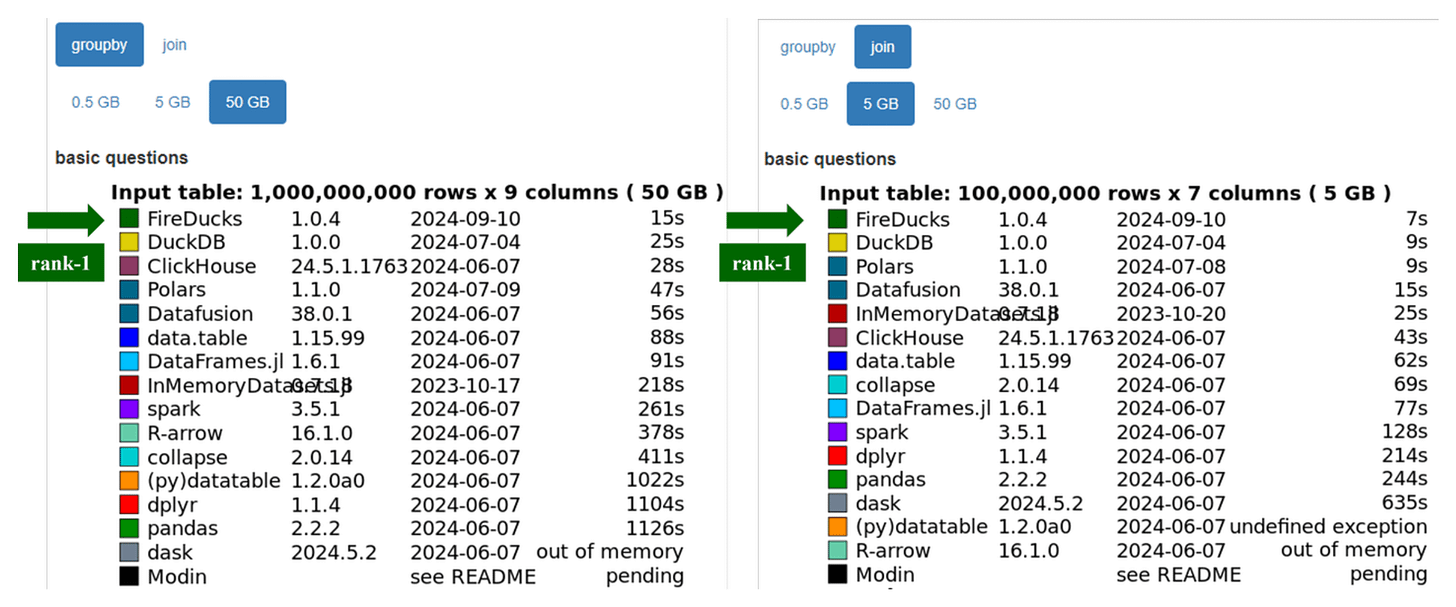
The db-benchmark includes scenarios that execute fundamental data science operations across multiple datasets. FireDucks appears to be the fastest DataFrame library for common big data operations under this benchmark:
Moreover, as per TPC-H benchmarks across 22 queries:
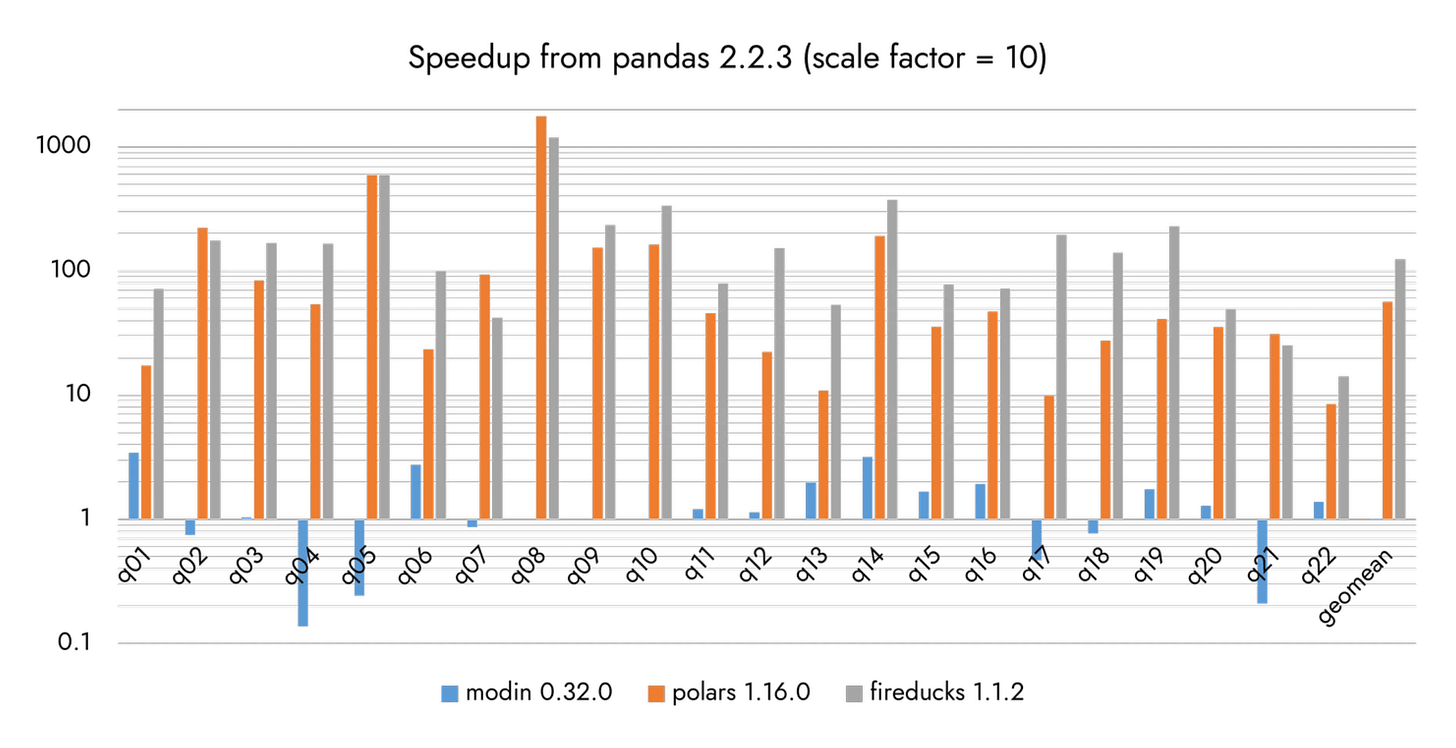
- Modin had an average speed-up of 1.0x over Pandas.
- Polars had an average speed-up of 57x over Pandas.
- But FireDucks had an average speed-up of 125x over Pandas.
A demo of this speed-up comparison between DuckDB, Pandas and Polars is shown in the video above.
At its core, FireDucks is heavily driven by lazy execution, unlike Pandas, which executes right away.
This allows FireDucks to build a logical execution plan and apply possible optimizations.
How to use FireDucks?
First, install the library:

Next, there are three ways to use it:
- If you are using IPython or Jupyter Notebook, load the extension as follows:

- Additionally, FireDucks also provides a pandas-like module (
fireducks.pandas), which can be imported instead of using Pandas. Thus, to use FireDucks in an existing Pandas pipeline, replace the standard import statement with the one from FireDucks:
- Lastly, if you have a Python script, executing it as shown below will automatically replace the Pandas import statement with FireDucks:

Done!
It’s that simple to use FireDucks.
The code for the above benchmarks is available in this colab notebook.
👉 Over to you: What are some other ways to accelerate Pandas operations in general?
IN CASE YOU MISSED IT
Traditional RAG vs. HyDE
One critical problem with the traditional RAG system is that questions are not semantically similar to their answers.
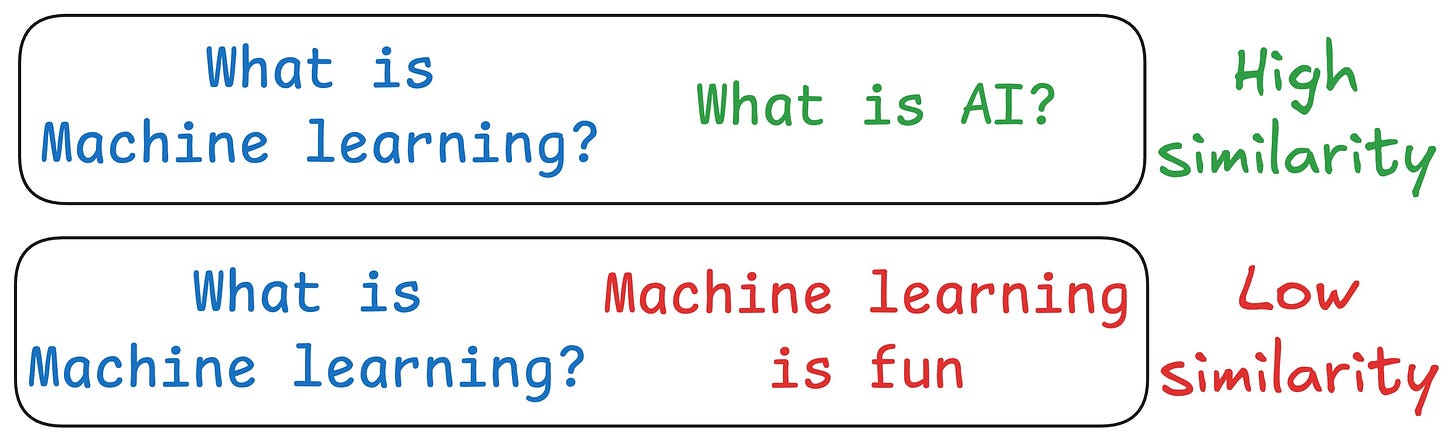
As a result, several irrelevant contexts get retrieved during the retrieval step due to a higher cosine similarity than the documents actually containing the answer.
HyDE solves this.
The following visual depicts how it differs from traditional RAG and HyDE.
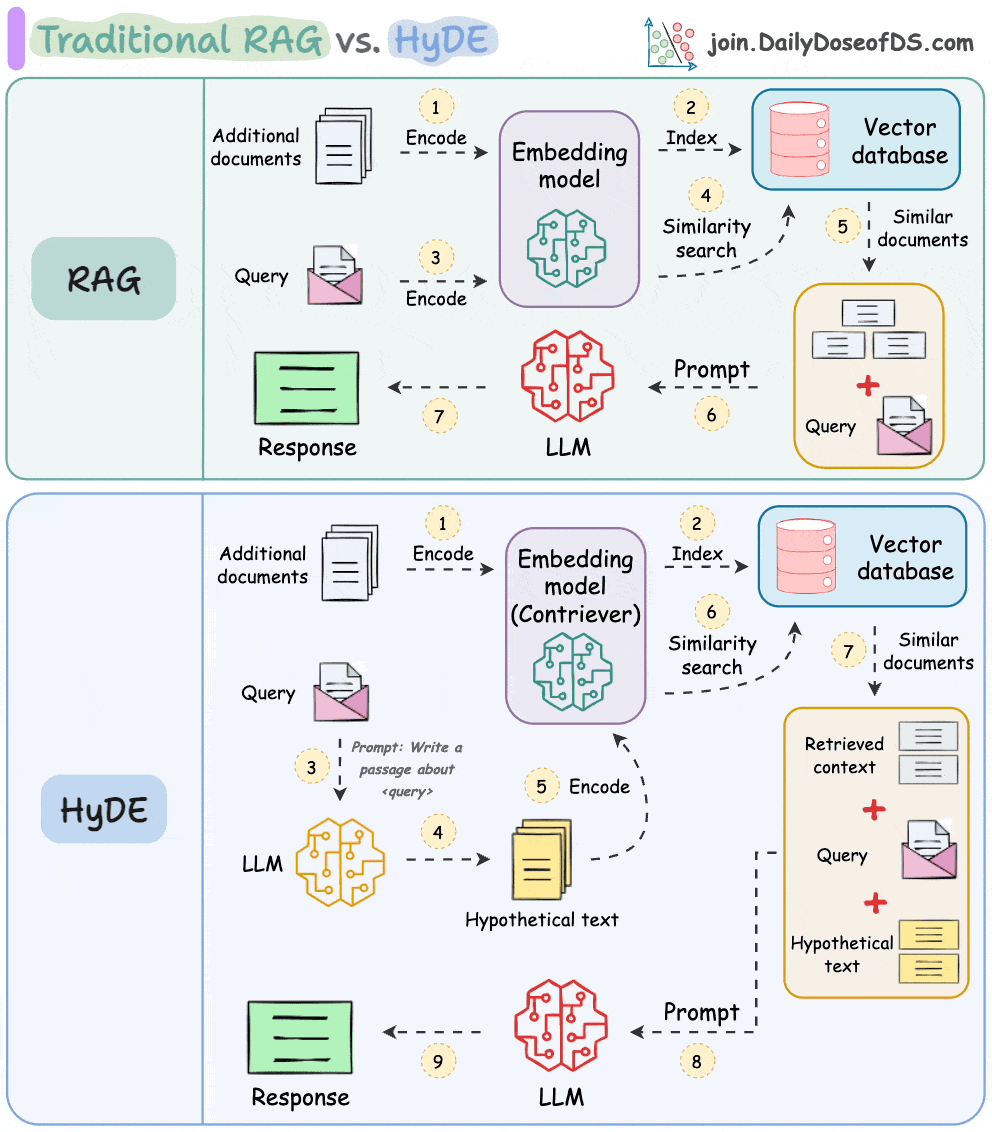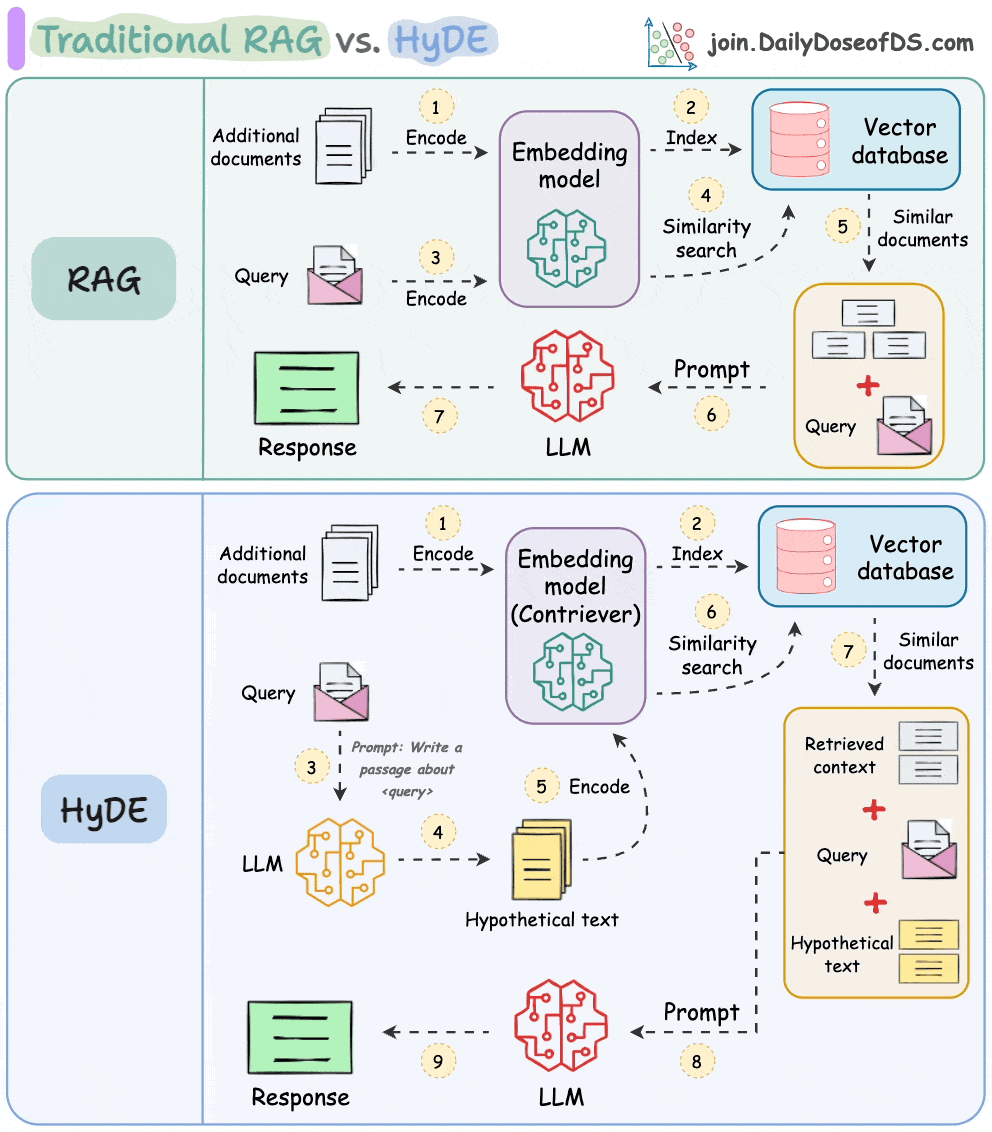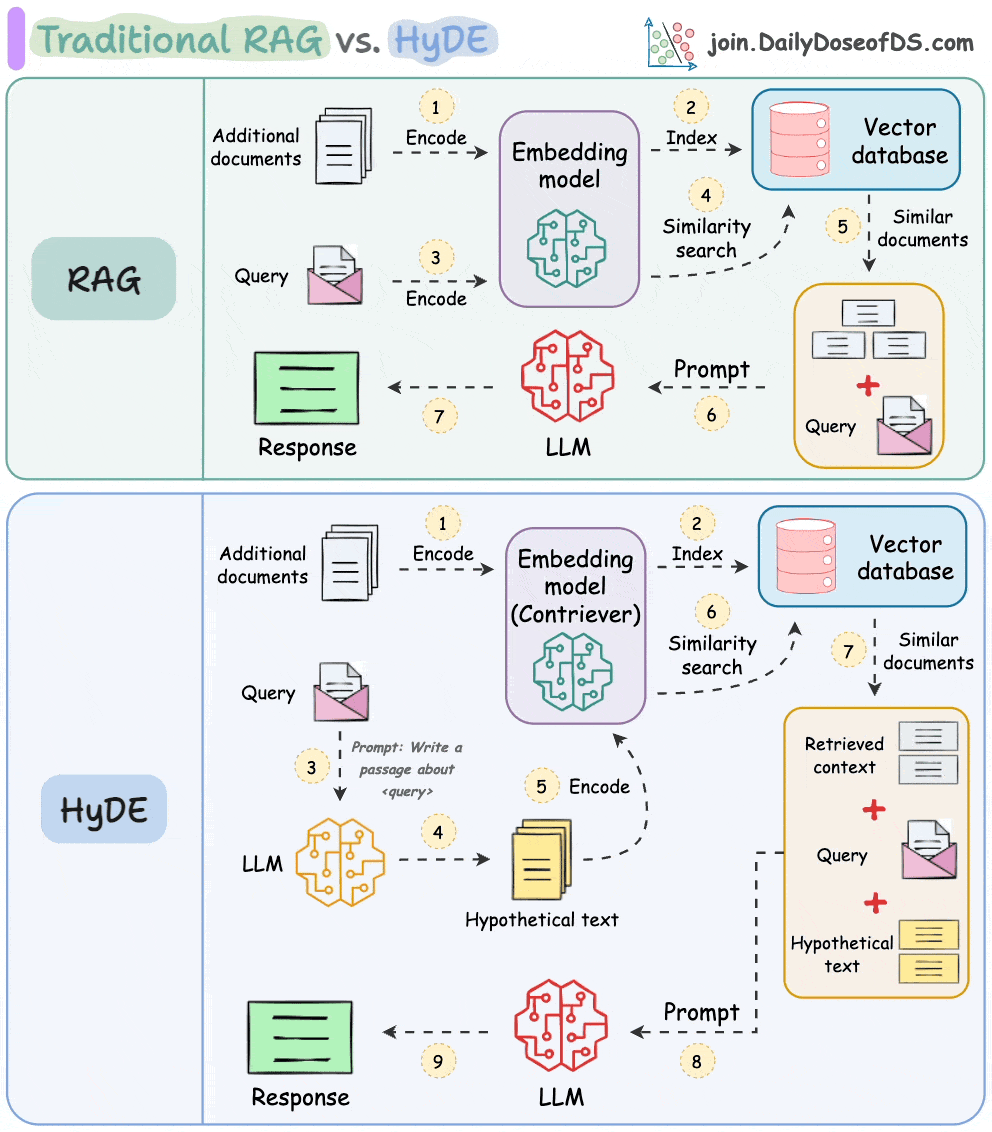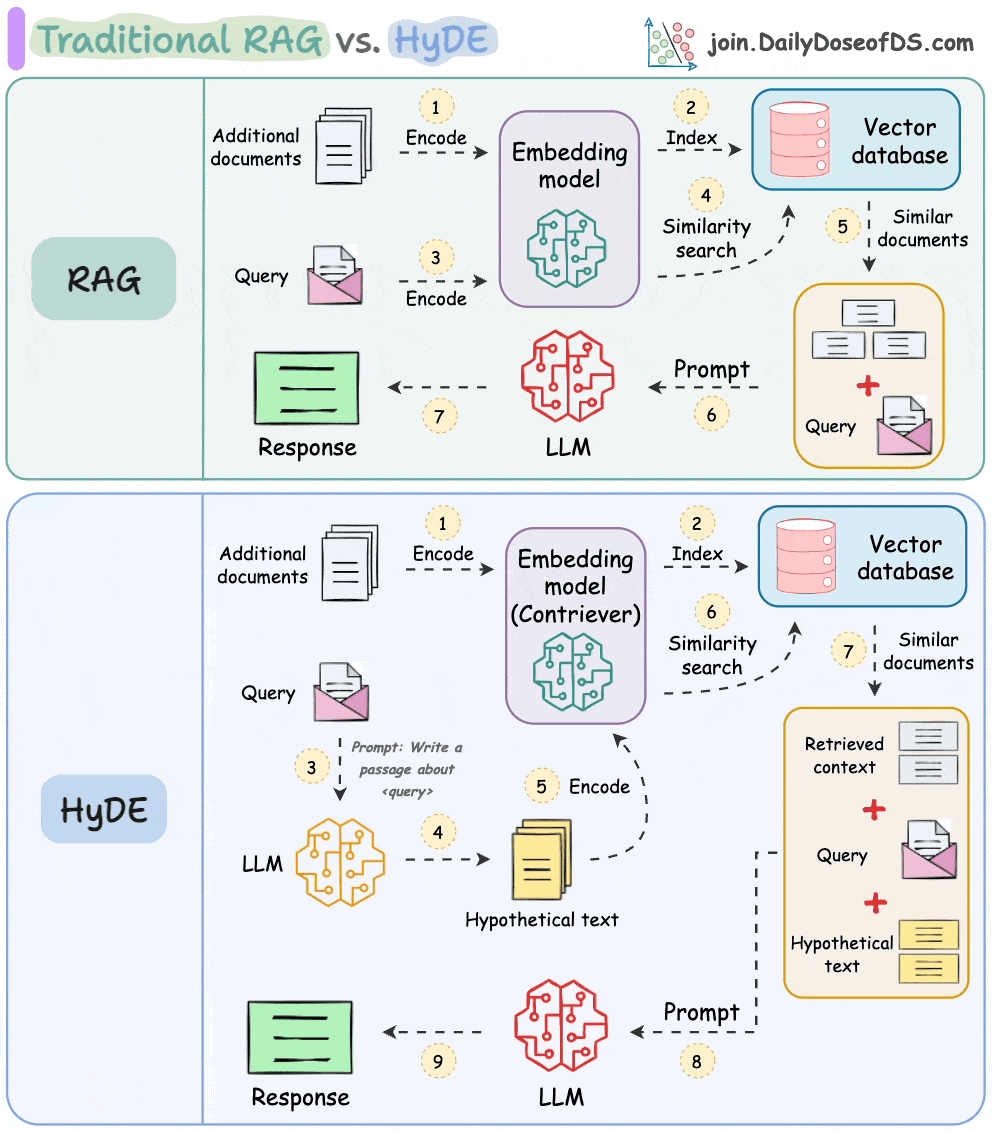
We covered this in detail in a newsletter issue published last week →
TRULY REPRODUCIBLE ML
Data Version Control
Versioning GBs of datasets is practically impossible with GitHub because it imposes an upper limit on the file size we can push to its remote repositories.
That is why Git is best suited for versioning codebase, which is primarily composed of lightweight files.
However, ML projects are not solely driven by code.
Instead, they also involve large data files, and across experiments, these datasets can vastly vary.
To ensure proper reproducibility and experiment traceability, it is also necessary to version datasets.
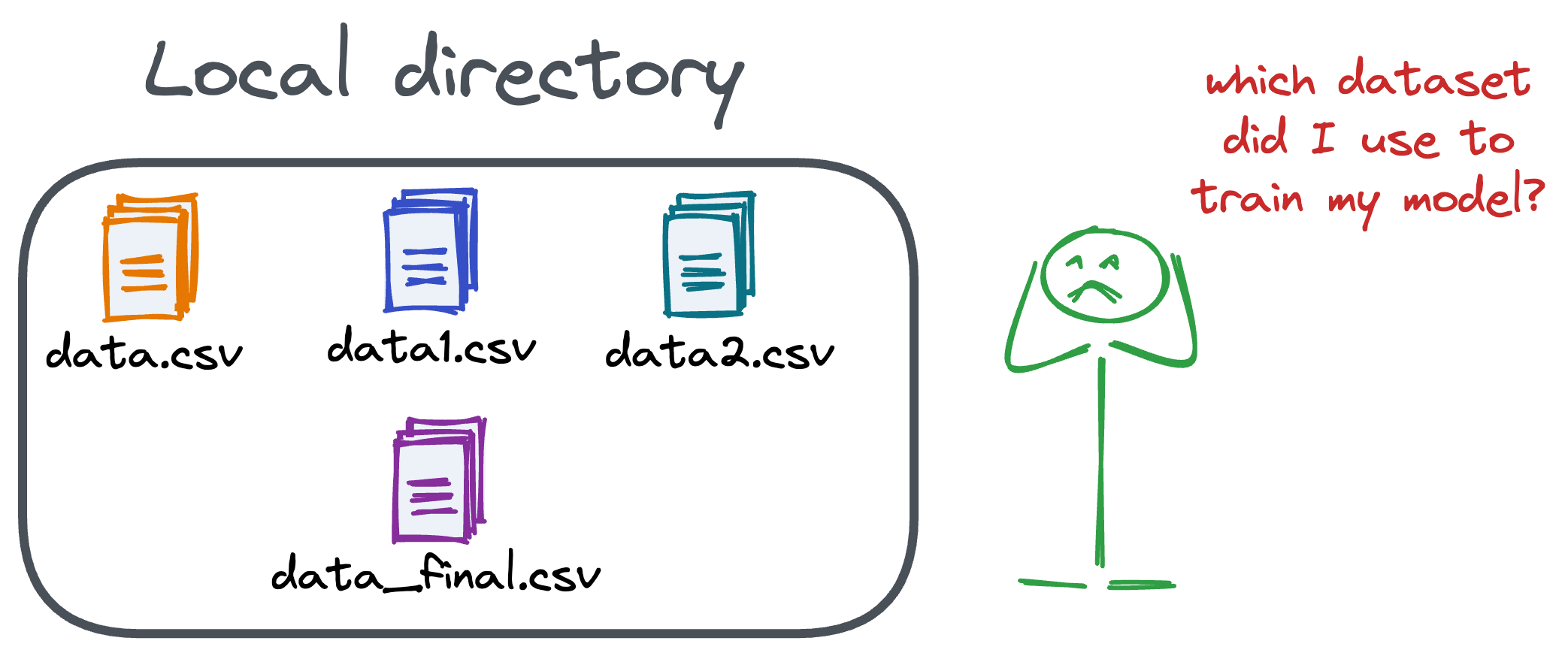
Data version control (DVC) solves this problem.
The core idea is to integrate another version controlling system with Git, specifically used for large files.
Here's everything you need to know (with implementation) about building 100% reproducible ML projects →
THAT'S A WRAP
No-Fluff Industry ML resources to
Succeed in DS/ML roles
At the end of the day, all businesses care about impact. That’s it!
- Can you reduce costs?
- Drive revenue?
- Can you scale ML models?
- Predict trends before they happen?
We have discussed several other topics (with implementations) in the past that align with such topics.
Here are some of them:
- Learn sophisticated graph architectures and how to train them on graph data in this crash course.
- So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
- Run large models on small devices using Quantization techniques.
- Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
- Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
- Learn how to scale and implement ML model training in this practical guide.
- Learn 5 techniques with implementation to reliably test ML models in production.
- Learn how to build and implement privacy-first ML systems using Federated Learning.
- Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.
SPONSOR US
Advertise to 600k+ data professionals
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., around the world.



