LLMs
5 LLM Fine-tuning Techniques
...explained visually

Avi Chawla
...explained visually

TODAY'S ISSUE
Traditional fine-tuning (depicted below) is infeasible with LLMs because these models have billions of parameters and are hundreds of GBs in size, and not everyone has access to such computing infrastructure.
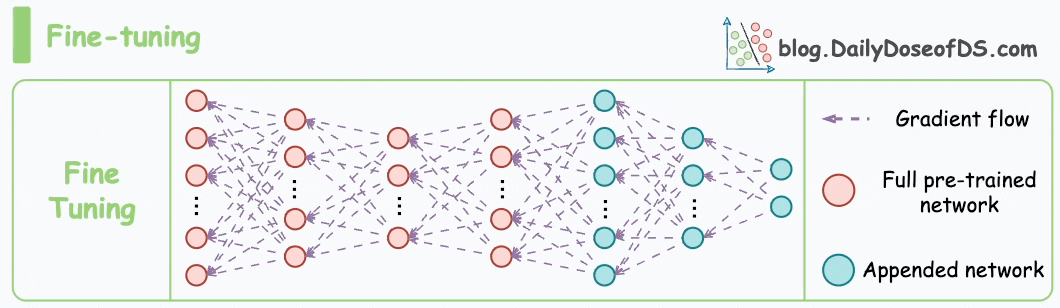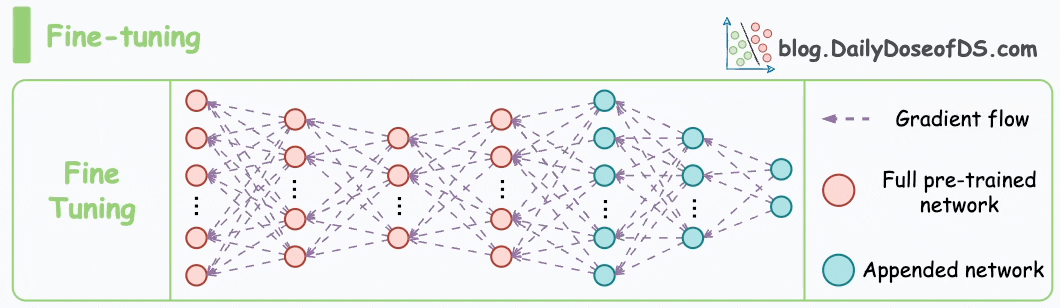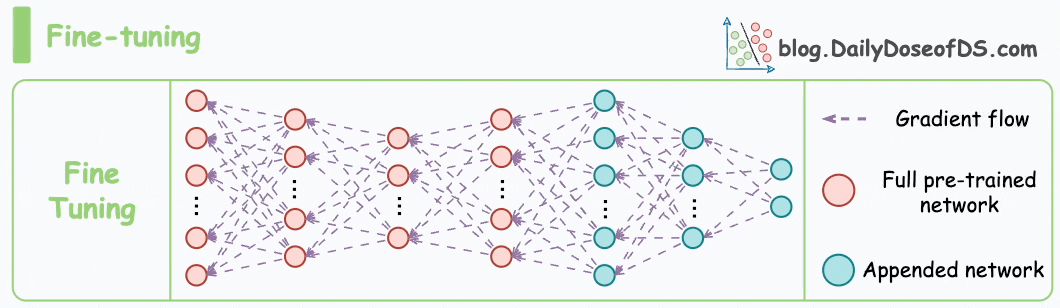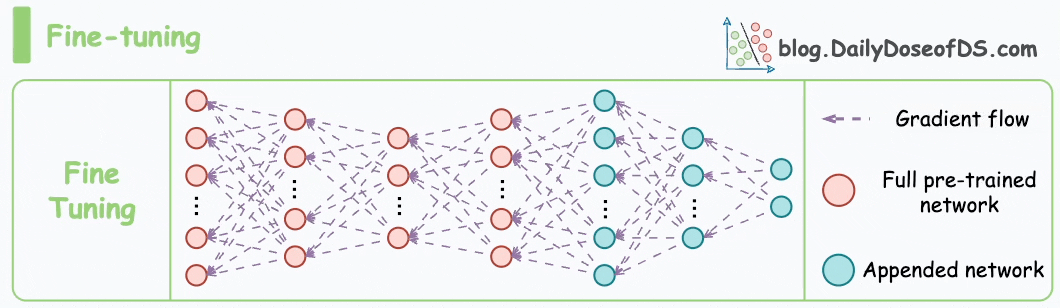
Thankfully, today, we have many optimal ways to fine-tune LLMs, and five such popular techniques are depicted below:
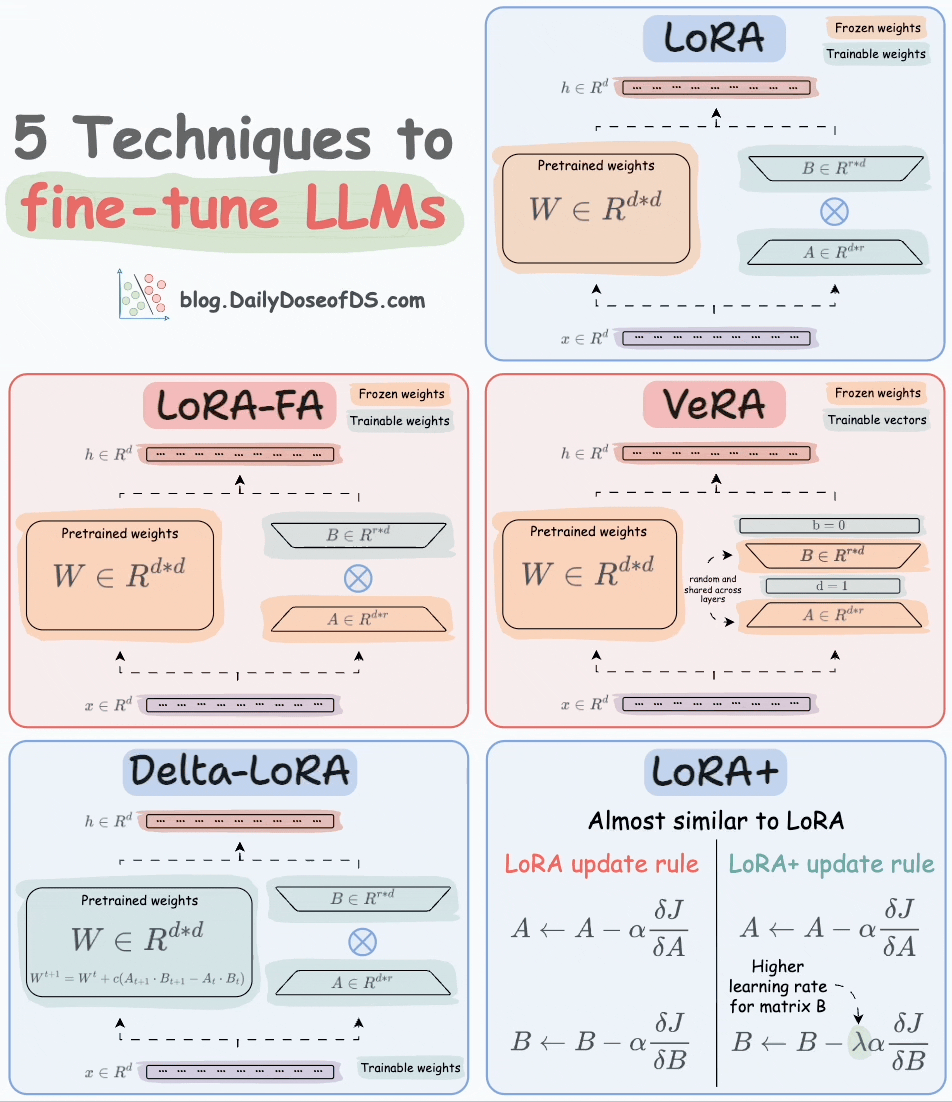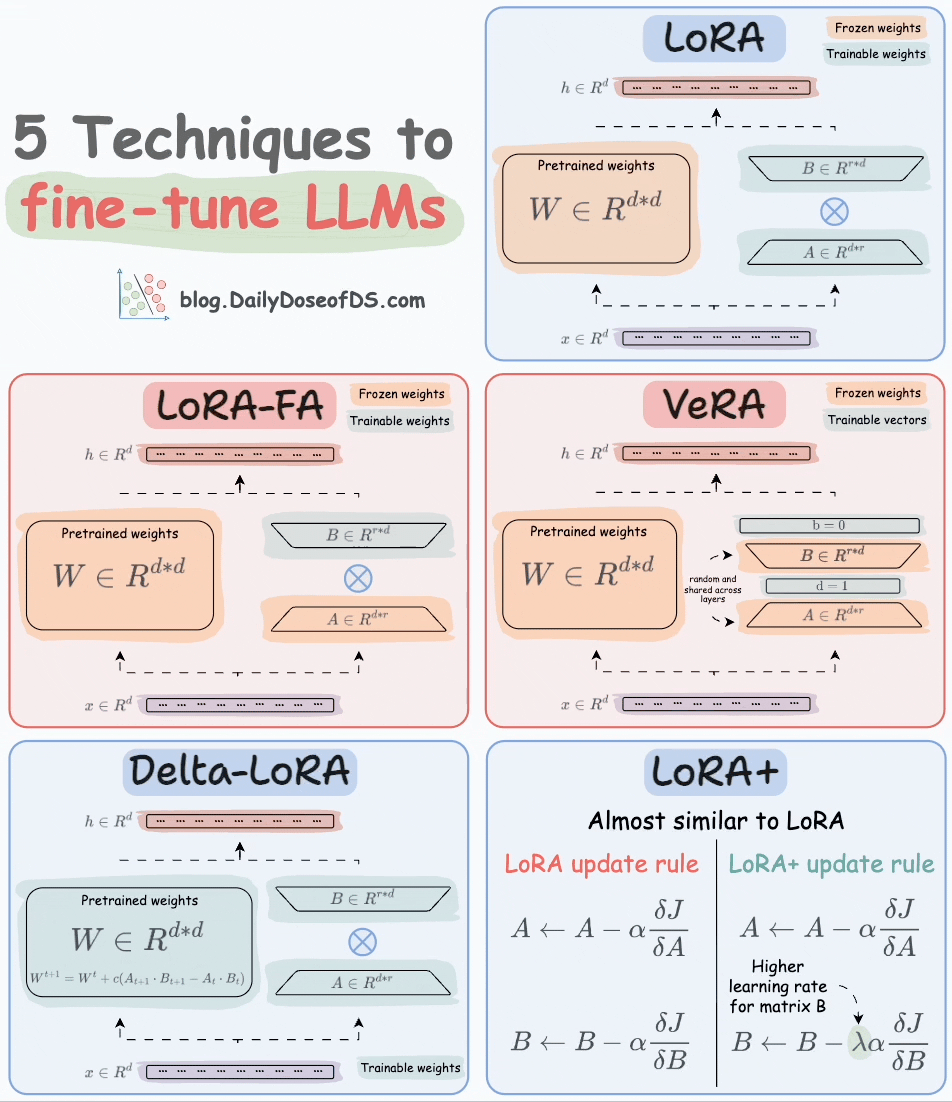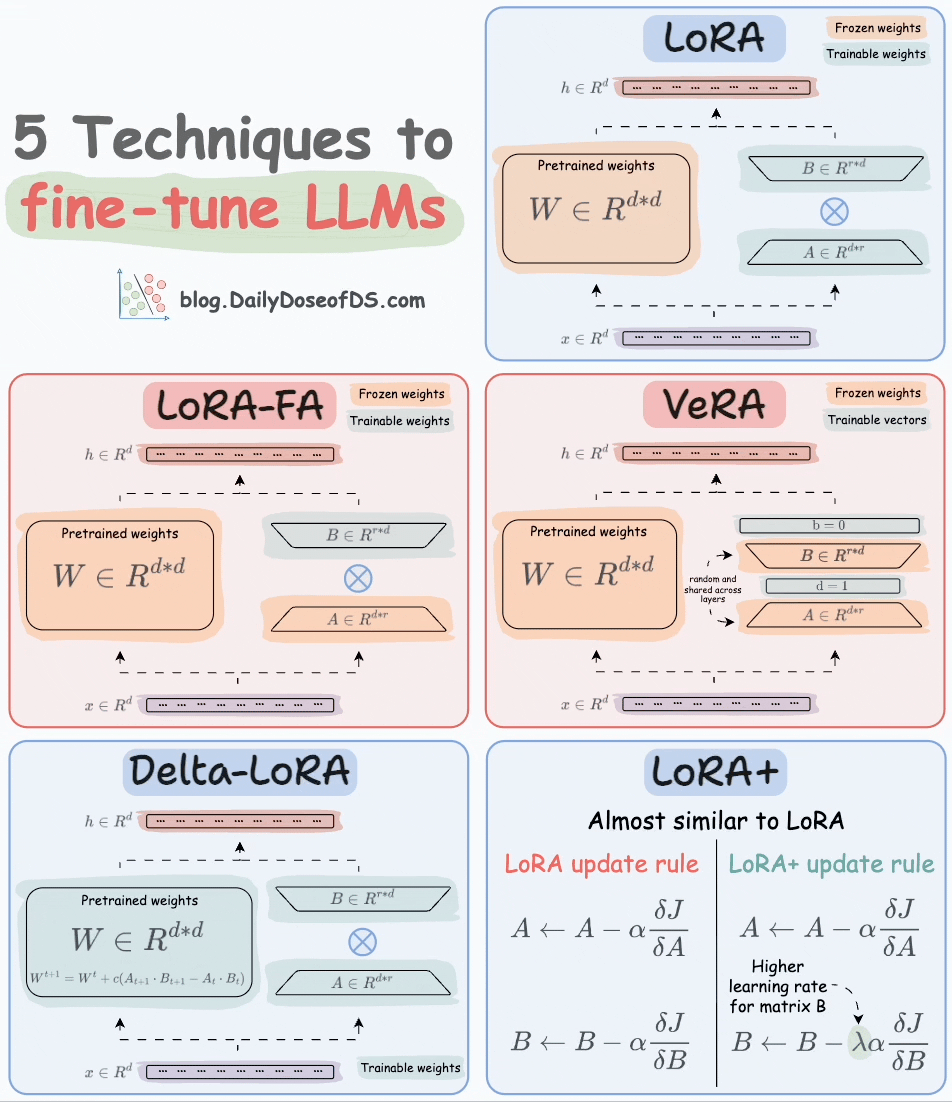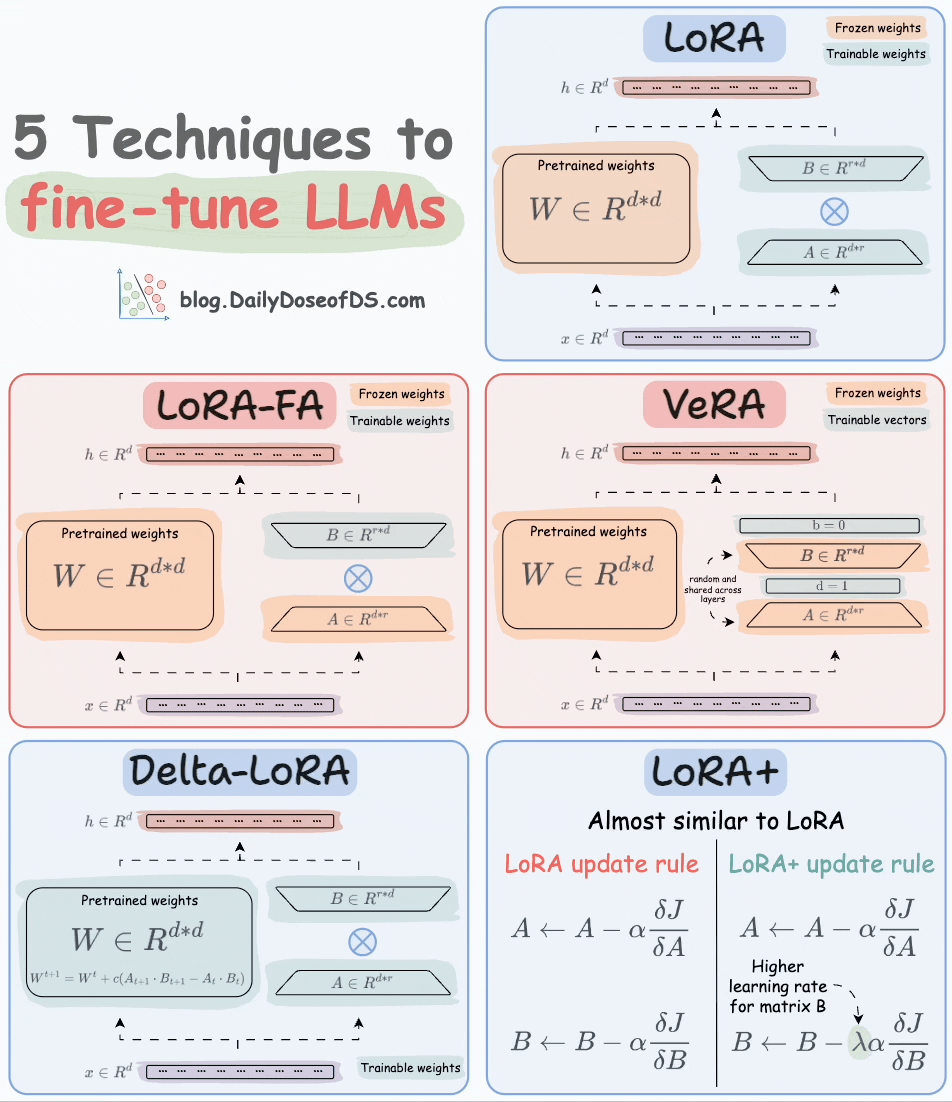
We covered them in detail here:
Here’s a brief explanation:
A and B alongside weight matrices, which contain the trainable parameters. Instead of fine-tuning W, adjust the updates in these low-rank matrices.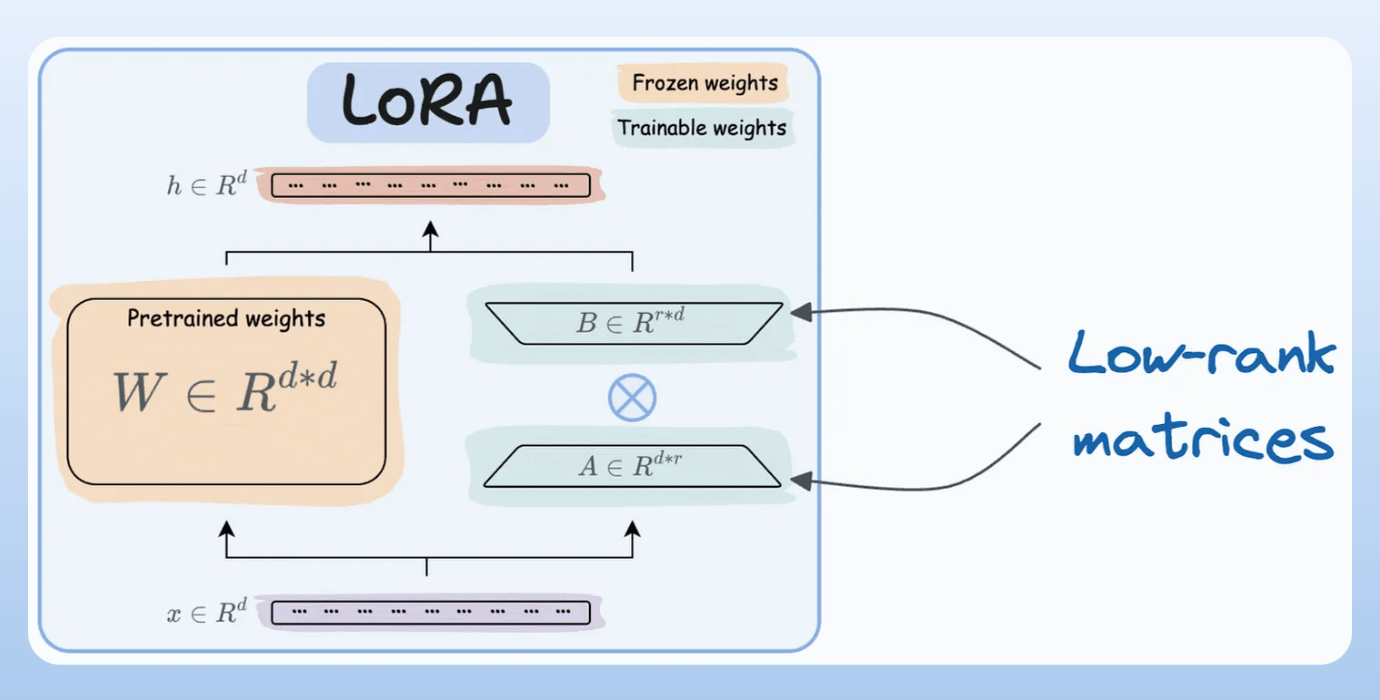
A and only updates matrix B.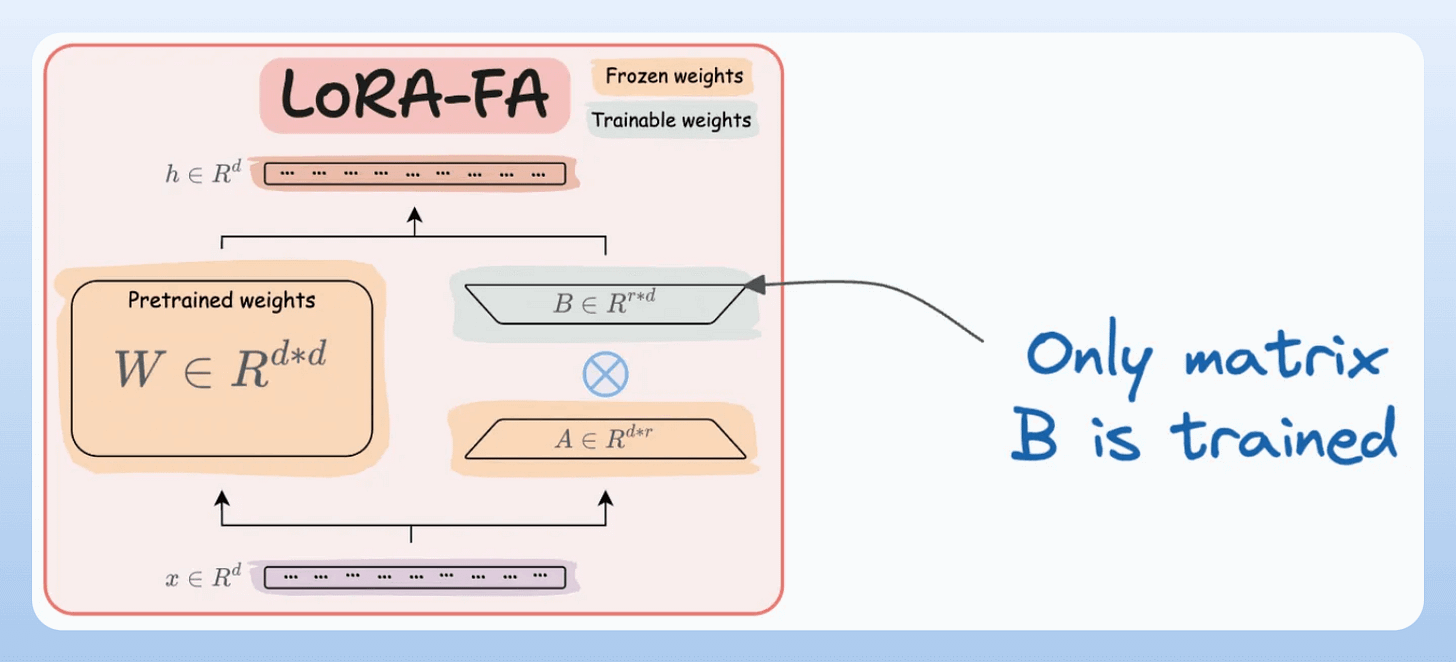
A and B, and both matrices are trained. In VeRA, however, matrices A and B are frozen, random, and shared across all model layers. VeRA focuses on learning small, layer-specific scaling vectors, denoted as b and d, which are the only trainable parameters in this setup.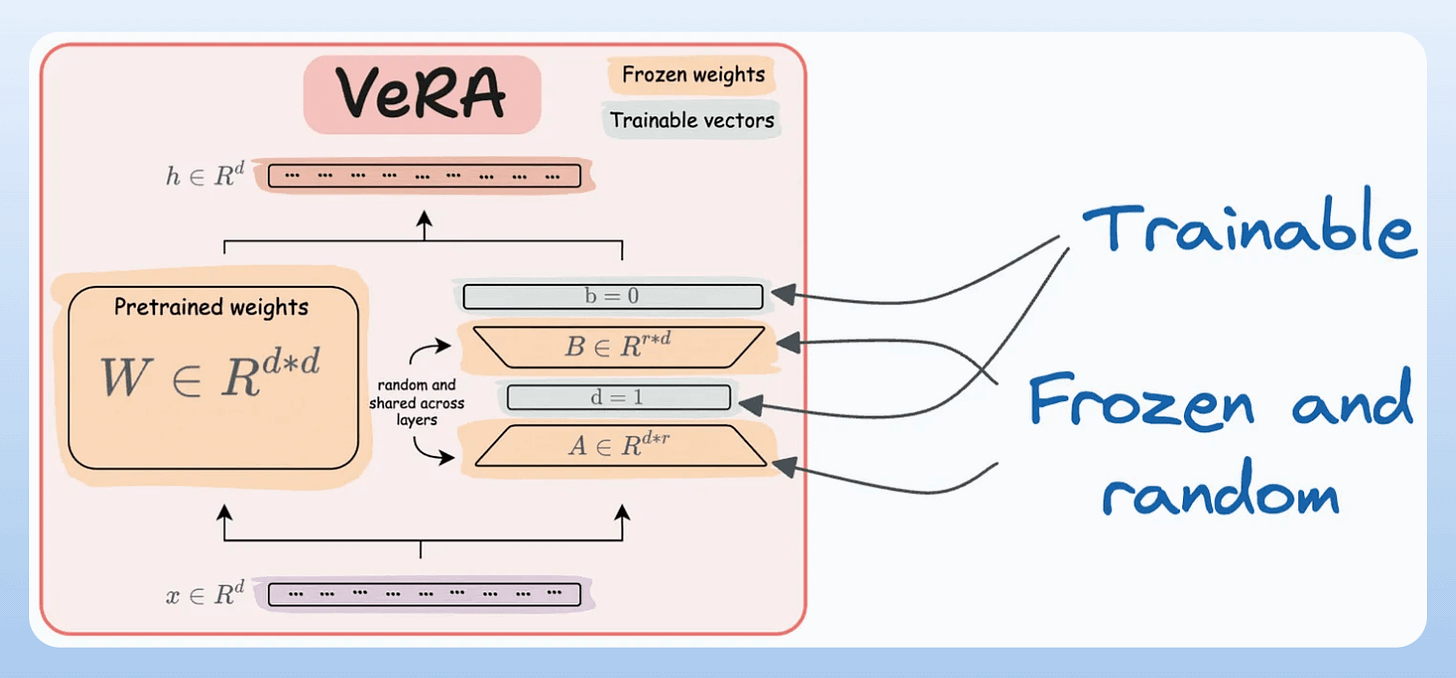
W is also adjusted but not in the traditional way. Instead, the difference (or delta) between the product of the low-rank matrices A and B in two consecutive training steps is added to W: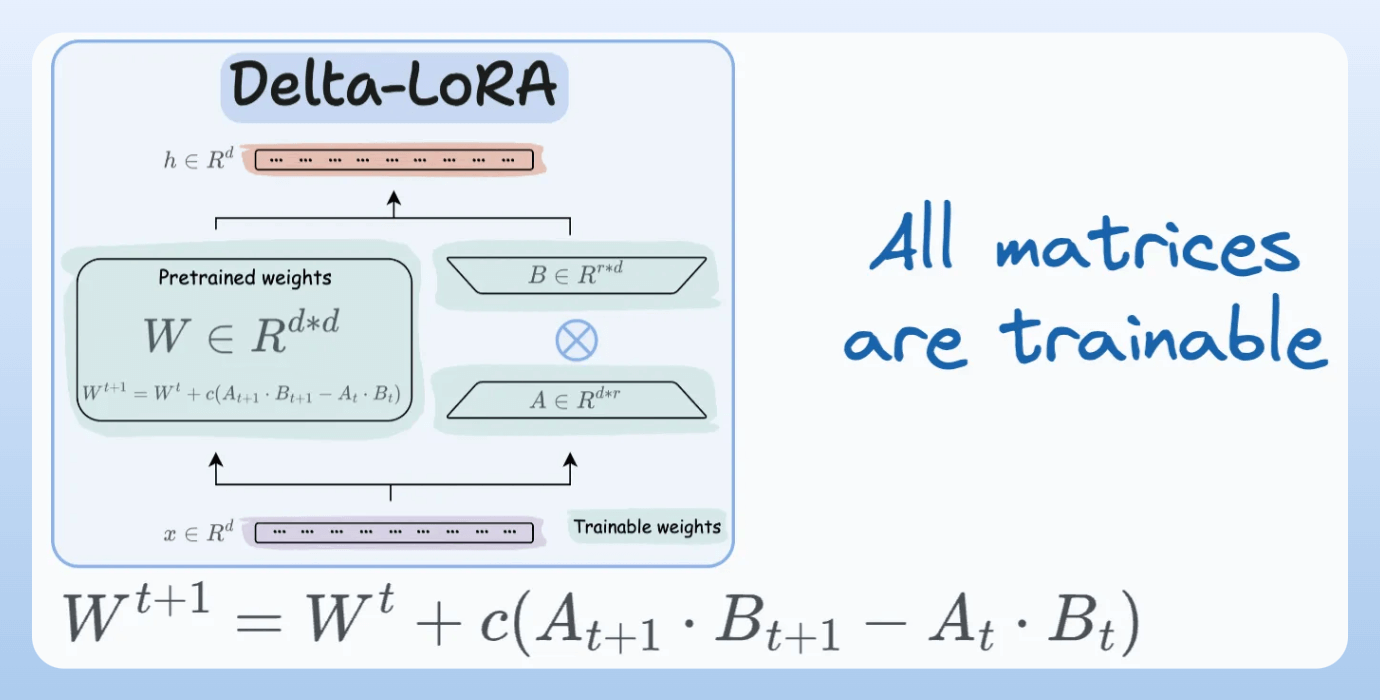
A and B are updated with the same learning rate. Authors found that setting a higher learning rate for matrix B results in more optimal convergence.
To get into more detail about the precise steps, intuition, and results, read these articles:
That said, these are not the only LLM fine-tuning techniques. The following visual depicts a timeline of popular approaches:
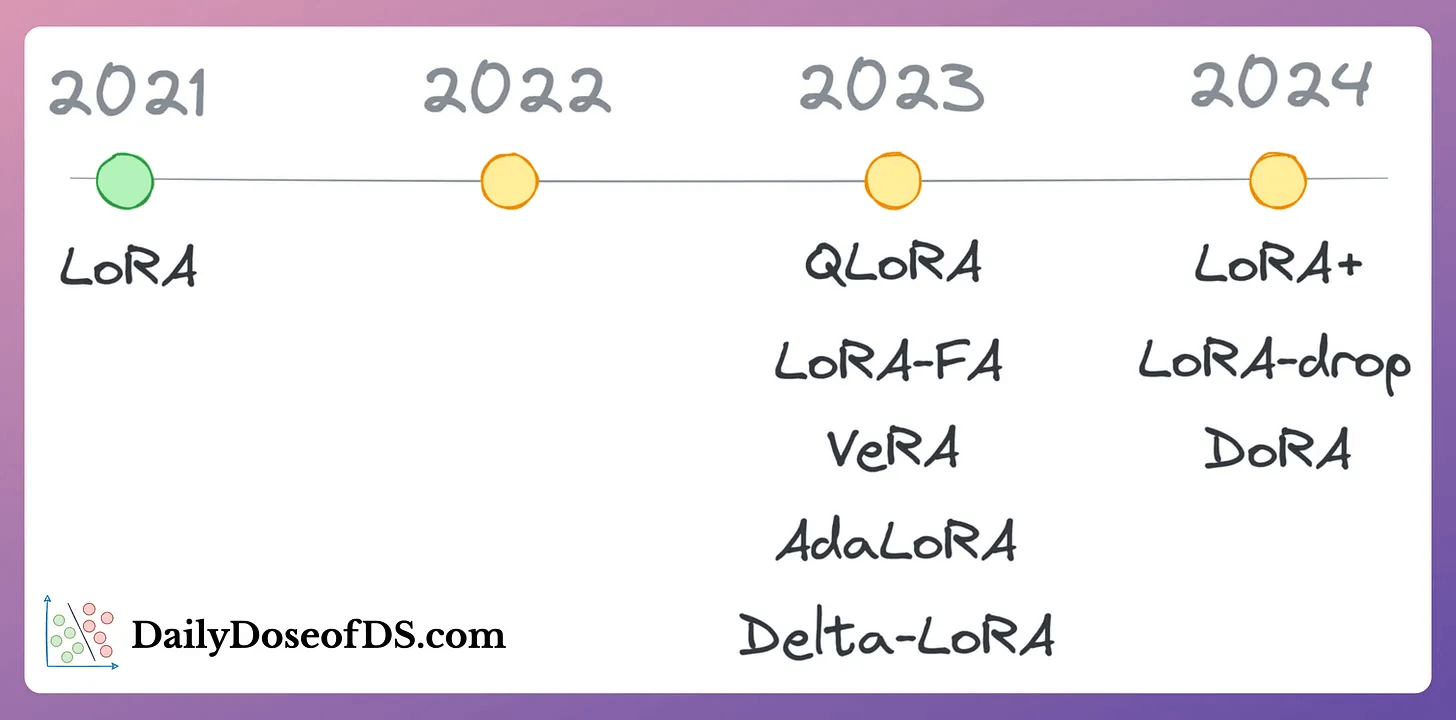
👉 Over to you: What are some ways to reduce the computational complexity of fine-tuning LLMs?
Talking about efficient training...
If you look at job descriptions for Applied ML or ML engineer roles on LinkedIn, most of them demand skills like the ability to train models on large datasets:
Of course, this is not something new or emerging.
But the reason they explicitly mention “large datasets” is quite simple to understand.
Businesses have more data than ever before.
Traditional single-node model training just doesn’t work because one cannot wait months to train a model.
Distributed (or multi-GPU) training is one of the most essential ways to address this.
Here, we covered the core technicalities behind multi-GPU training, how it works under the hood, and implementation details.
We also look at the key considerations for multi-GPU (or distributed) training, which, if not addressed appropriately, may lead to suboptimal performance or slow training.