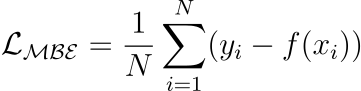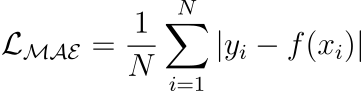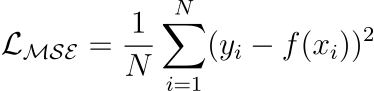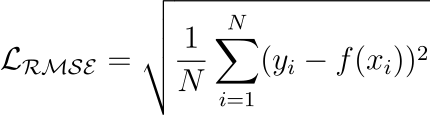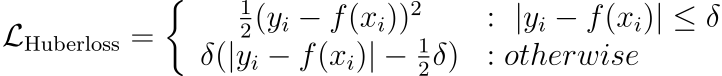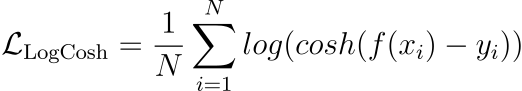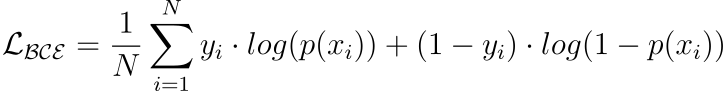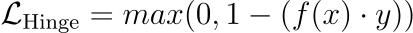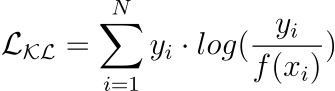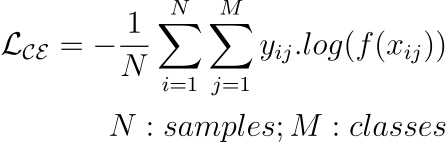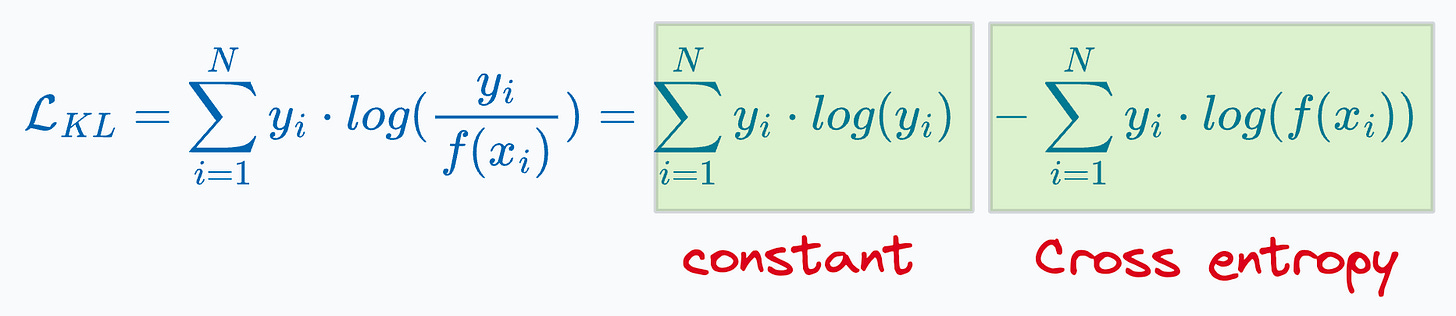10 Most Common Regression and Classification Loss Functions
...explained in a single frame.
Avi Chawla
👉
Loss functions are a key component of ML algorithms.
They specify the objective an algorithm should aim to optimize during its training. In other words, loss functions tell the algorithm what it should minimize or maximize to improve its performance.
Model training with an objective function
Therefore, being aware of the most common loss functions is extremely crucial.
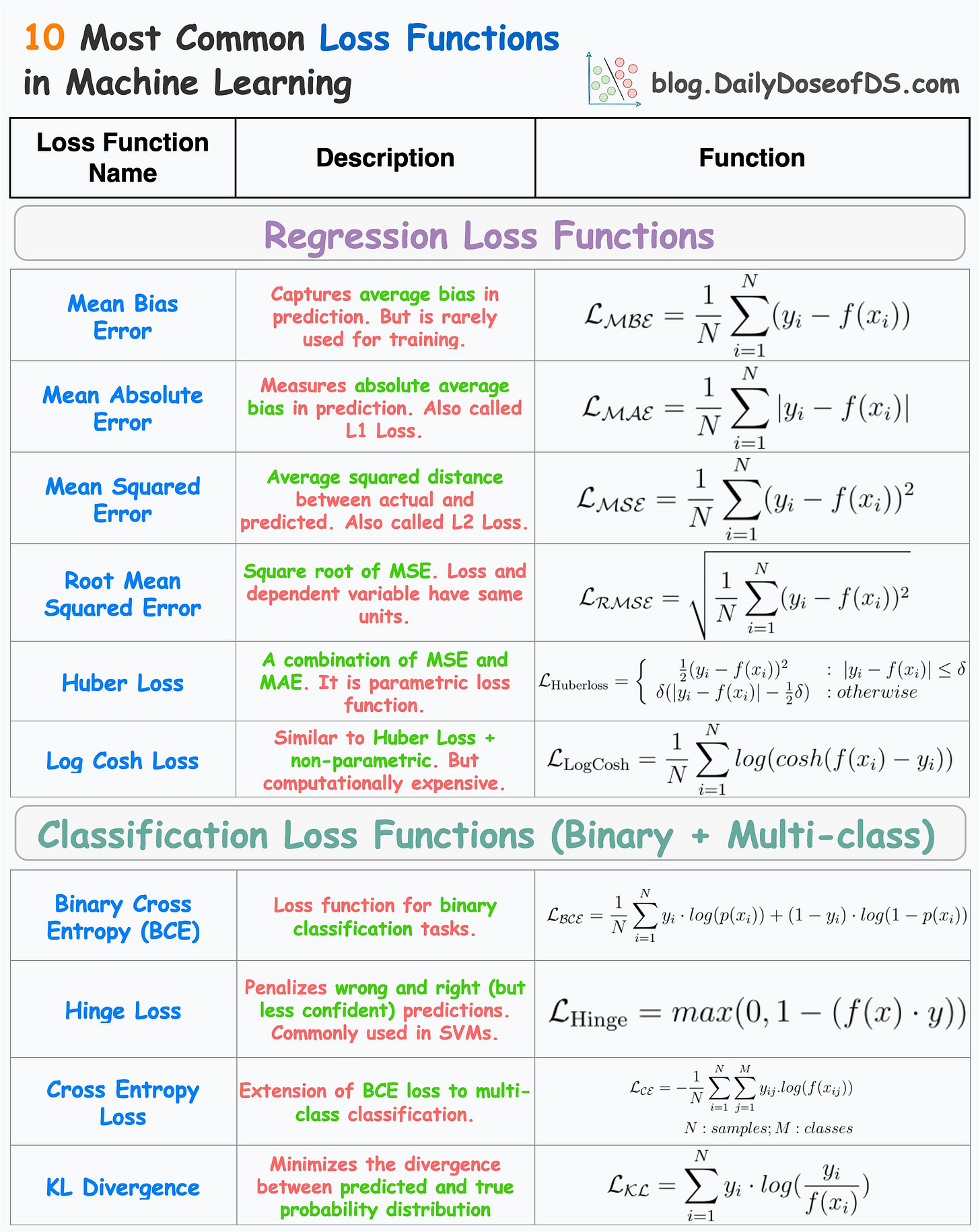
The visual below depicts the most commonly used loss functions for regression and classification tasks.
Regression
Mean Bias Error
Captures the average bias in the prediction.
However, it is rarely used in training ML models.
This is because negative errors may cancel positive errors, leading to zero loss, and consequently, no weight updates.
Mean bias error is foundational to the more advanced regression losses discussed below.
Mean Absolute Error (or L1 loss)
Measures the average absolute difference between predicted and actual value.
Positive errors and negative errors don’t cancel out.
One caveat is that small errors are as important as big ones. Thus, the magnitude of the gradient is independent of error size.
Mean Squared Error (or L2 loss)
It measures the squared difference between predicted and actual value.
Larger errors contribute more significantly than smaller errors.
The above point may also be a caveat as it is sensitive to outliers.
Yet, it is among the most common loss functions for many regression models.
Root Mean Squared Error
Mean Squared Error with a square root.
Loss and the dependent variable (y) have the same units.
Huber Loss
It is a combination of mean absolute error and mean squared error.
For smaller errors, mean squared error is used, which is differentiable through (unlike MAE, which is non-differentiable at x=0).
For large errors, mean absolute error is used, which is less sensitive to outliers.
One caveat is that it is parameterized — adding another hyperparameter to the list.
Log Cosh Loss
For small errors, log cosh loss is approximately → x²/2 — quadratic.
For large errors, log cash loss is approximately → |x| - log(2) — linear.
Thus, it is very similar to Huber loss.
Also, it is non-parametric.
The only caveat is that it is a bit computationally expensive.
Classification
Log Cosh Loss
A loss function used for binary classification tasks.
Measures the dissimilarity between predicted probabilities and true binary labels, through the logarithmic loss.