LLMs
Time Complexity of 10 ML Algorithms
(training and inference)...in a single frame.

Avi Chawla
(training and inference)...in a single frame.

TODAY'S ISSUE
This visual depicts the run-time complexity of the 10 most popular ML algorithms.
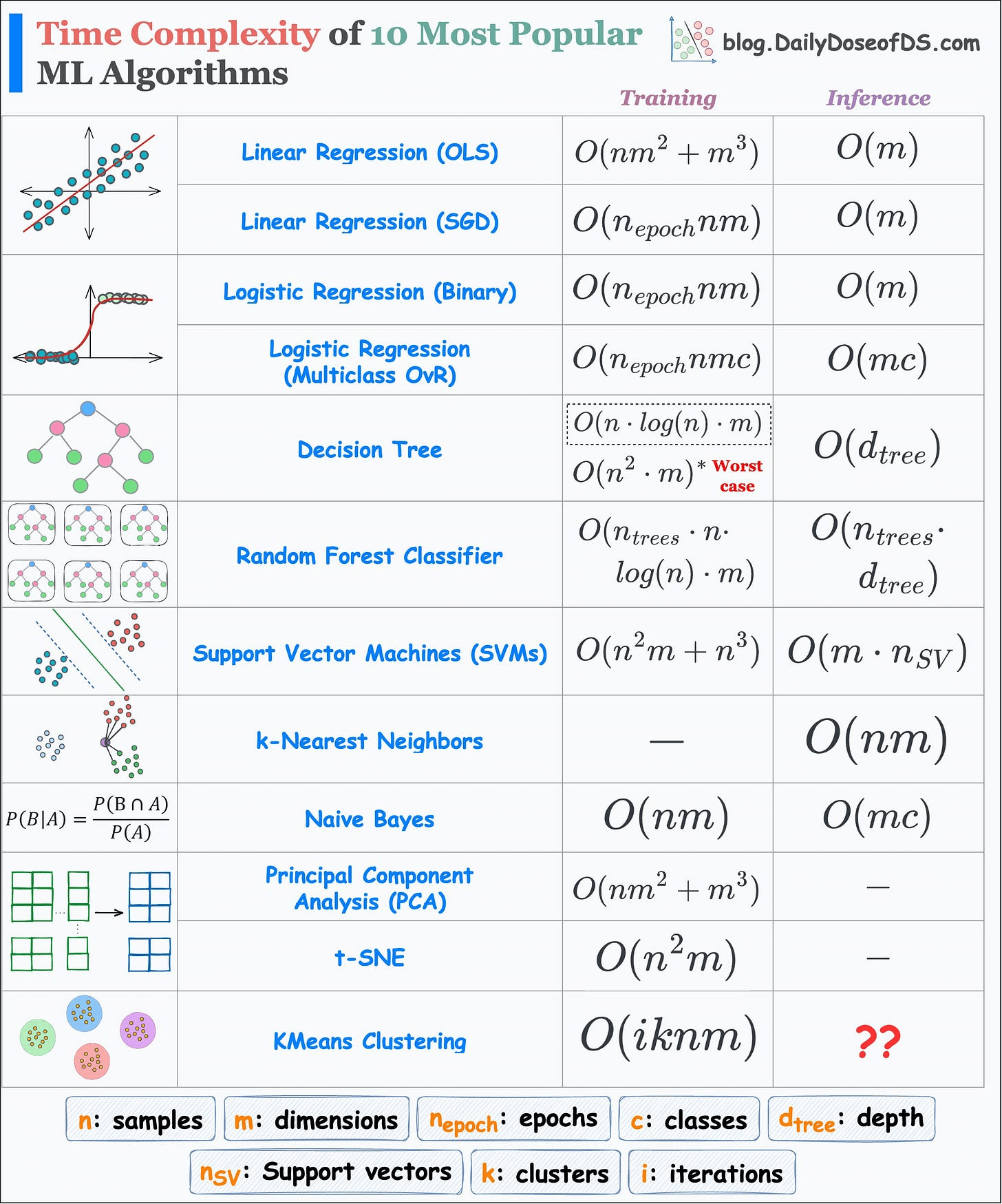
Everyone is a big fan of sklearn implementations.
It takes just two (max three) lines of code to run any ML algorithm with sklearn.
However, due to this simplicity, most people often overlook the core understanding of an algorithm and the data-specific conditions that allow us to use an algorithm.
For instance, you cannot use SVM or t-SNE on a big dataset:
Another advantage of understanding the run-time is that it helps us understand how an algorithm works end-to-end.
That said, we made a few assumptions in the above table:
O(nlogn).O(nlog(k)).During inference in kNN, we first find the distance to all data points. This gives a list of distances of size n (total samples).

Today, as an exercise, I would encourage you to derive these run-time complexities yourself.
This activity will give you confidence in algorithmic understanding.
👉 Over to you: Can you tell the inference run-time of KMeans Clustering?
Thanks for reading!
If you have used DeepSeek-R1 (or any other reasoning model), you must have seen that they autonomously allocate thinking time before producing a response.
Last week, we shared how to embed reasoning capabilities into any LLM.
We trained our own reasoning model like DeepSeek-R1 (with code).

To do this, we used:
Find the implementation and detailed walkthrough newsletter here →
Once a model has been trained, we move to productionizing and deploying it.
If ideas related to production and deployment intimidate you, here’s a quick roadmap for you to upskill (assuming you know how to train a model):
This roadmap should set you up pretty well, even if you have NEVER deployed a single model before since everything is practical and implementation-driven.