LLMs
[Hands-on] Multimodal RAG using DeepSeek's Janus
100% Local.

Avi Chawla
100% Local.

TODAY'S ISSUE
After DeepSeek-R1, DeepSeek dropped more open-weight multimodal models—Janus, Janus-Pro, and Janus-Flow.
They can understand images and generate images from text input.
Moreover, they beat OpenAI's DALL-E 3 and Stable Diffusion in GenEval and DPG-Bench benchmarks.
Today, let’s do a hands-on demo of building a multimodal RAG with Janus-Pro on a complex document shown below:

It has several complex diagrams, text within visualizations, and tables—perfect for multimodal RAG.
We’ll use:
This image shows the final outcome of today's issue (the code is available towards the end):
Let's build it!
We extract each document page as an image and embed it using ColPali.
We did a full architectural breakdown of ColPali in Part 9 of the RAG crash course and also optimized it with binary quantization.
ColPali uses vision capabilities to understand the context. It produces patches for every page, and each patch gets an embedding vector.
This is implemented below:

Embeddings are ready. Next, we create a Qdrant vector database and store these embeddings in it, as demonstrated below:
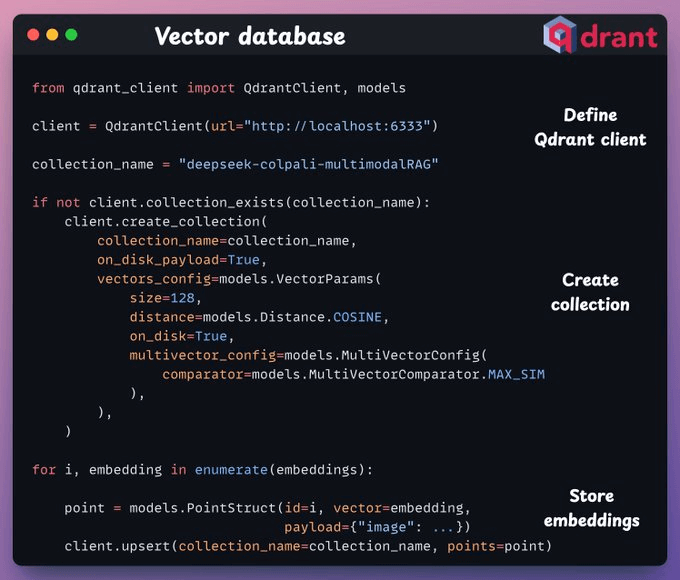
Next, we set up our DeepSeek's latest Janus-Pro by downloading it from HuggingFace.

Next, we:

Done!
We have implemented a 100% local Multimodal RAG powered by DeepSeek's latest Janus-Pro.
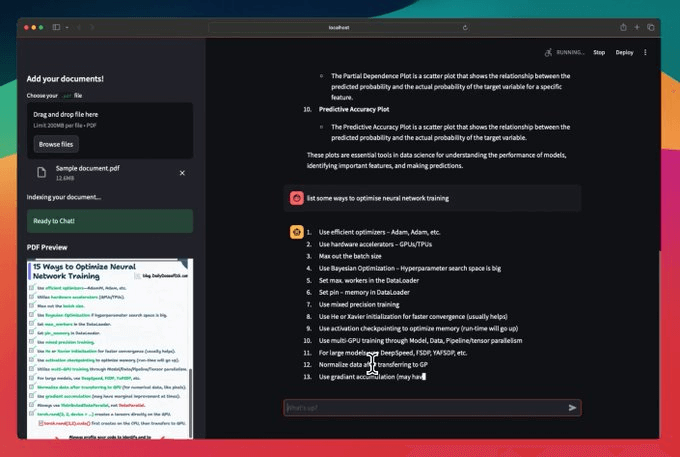
There’s some streamlit part we have shown here, but after building it, we get this clear and neat interface.
In this example, it produces the right response by retrieving the correct page and understanding a complex visualization👇

Here's one more example with a correct response:
Wasn’t that easy and straightforward?
The code for today's demo is available here: Multimodal RAG with DeepSeek.
👉 Over to you: What other demos would you like to see with DeepSeek?
Thanks for reading!
There are many issues with Grid search and random search.
Bayesian optimization solves this.
It’s fast, informed, and performant, as depicted below:

Learning about optimized hyperparameter tuning and utilizing it will be extremely helpful to you if you wish to build large ML models quickly.
There’s so much data on your mobile phone right now — images, text messages, etc.
And this is just about one user — you.
But applications can have millions of users. The amount of data we can train ML models on is unfathomable.
The problem?
This data is private.
So consolidating this data into a single place to train a model.
The solution?
Federated learning is a smart way to address this challenge.
The core idea is to ship models to devices, train the model on the device, and retrieve the updates:
But this isn't as simple as it sounds.
1) Since the model is trained on the client side, how to reduce its size?
2) How do we aggregate different models received from the client side?
3) [IMPORTANT] Privacy-sensitive datasets are always biased with personal likings and beliefs. For instance, in an image-related task:
Learn how to implement federated learning systems (beginner-friendly) →