Pandas
FireDucks with Seaborn
Speed + Seamless third-party integration.

Avi Chawla
Speed + Seamless third-party integration.

TODAY'S ISSUE
We have talked about FireDucks a few times before.
For starters, while Pandas is the most popular DataFrame library, it is terribly slow.
FireDucks is a highly optimized, drop-in replacement for Pandas with the same API.
You just need to change one line of code → 𝐢𝐦𝐩𝐨𝐫𝐭 𝗳𝗶𝗿𝗲𝗱𝘂𝗰𝗸𝘀.𝐩𝐚𝐧𝐝𝐚𝐬 𝐚𝐬 𝐩𝐝
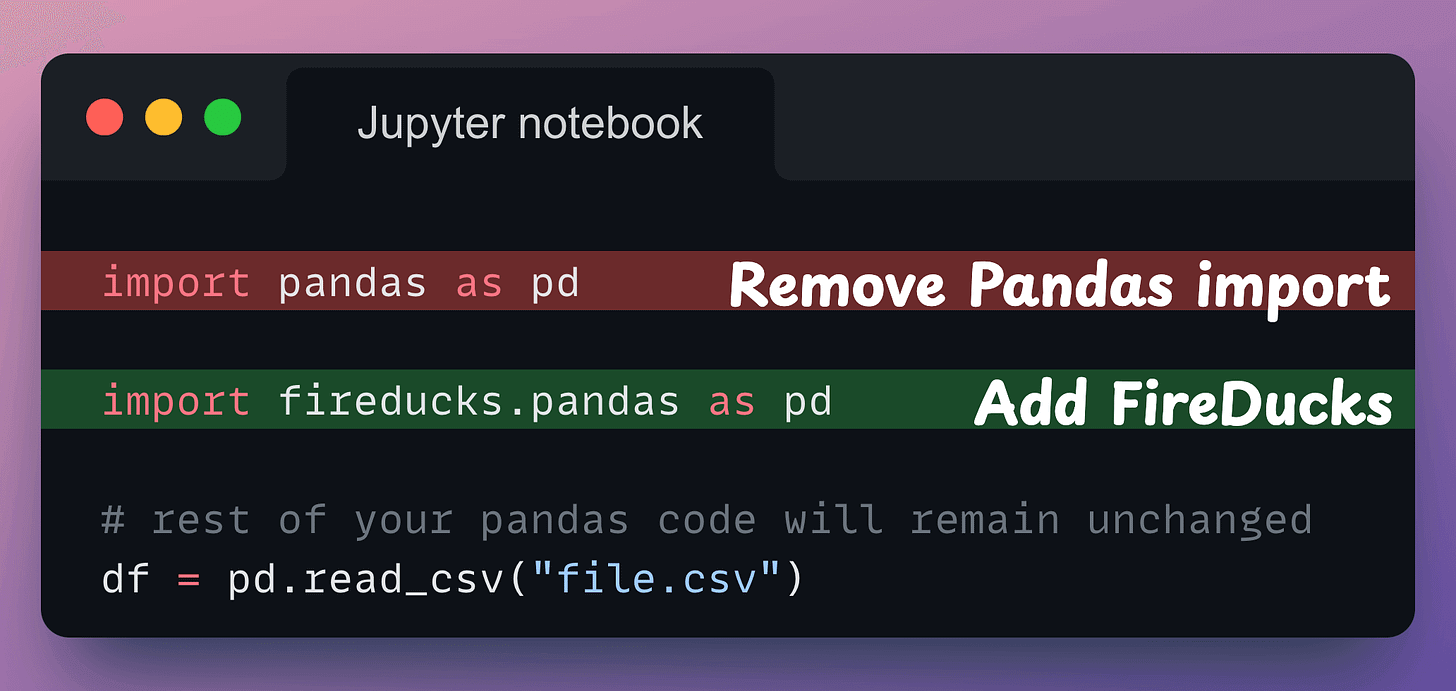
Done!
One thing we haven’t covered yet is its seamless integration with third-party libraries like Seaborn.
Let’s look at a quick demo below (here’s the Colab notebook with code).
We start by installing it:

Next, we download a sample dataset to work with.

Moving on, we load this data with Pandas and FireDucks:

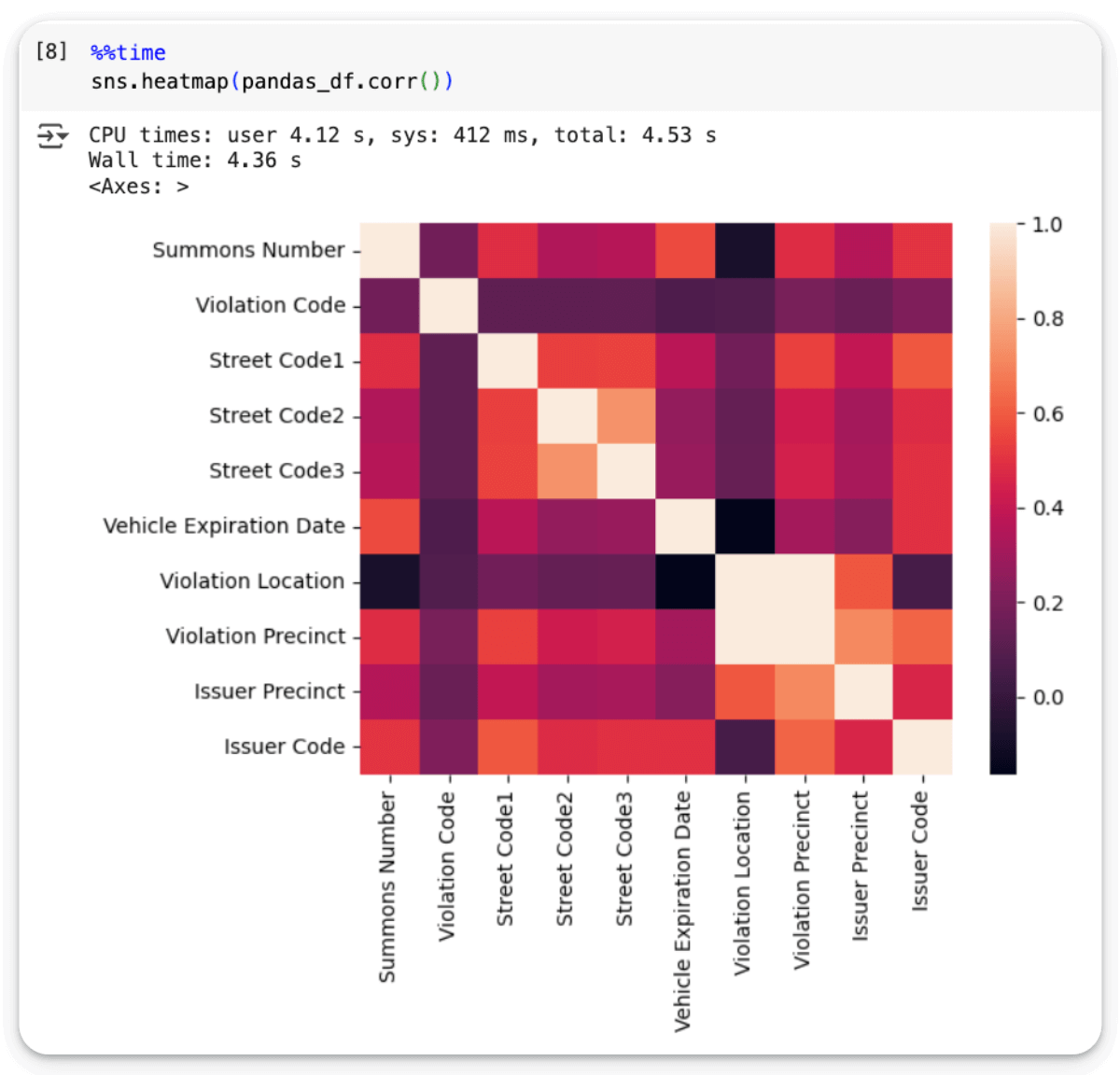
Creating a correlation heatmap on the Pandas DataFrame takes 4.36 seconds:
Doing the same on FireDucks DataFrame takes over 60% less time:
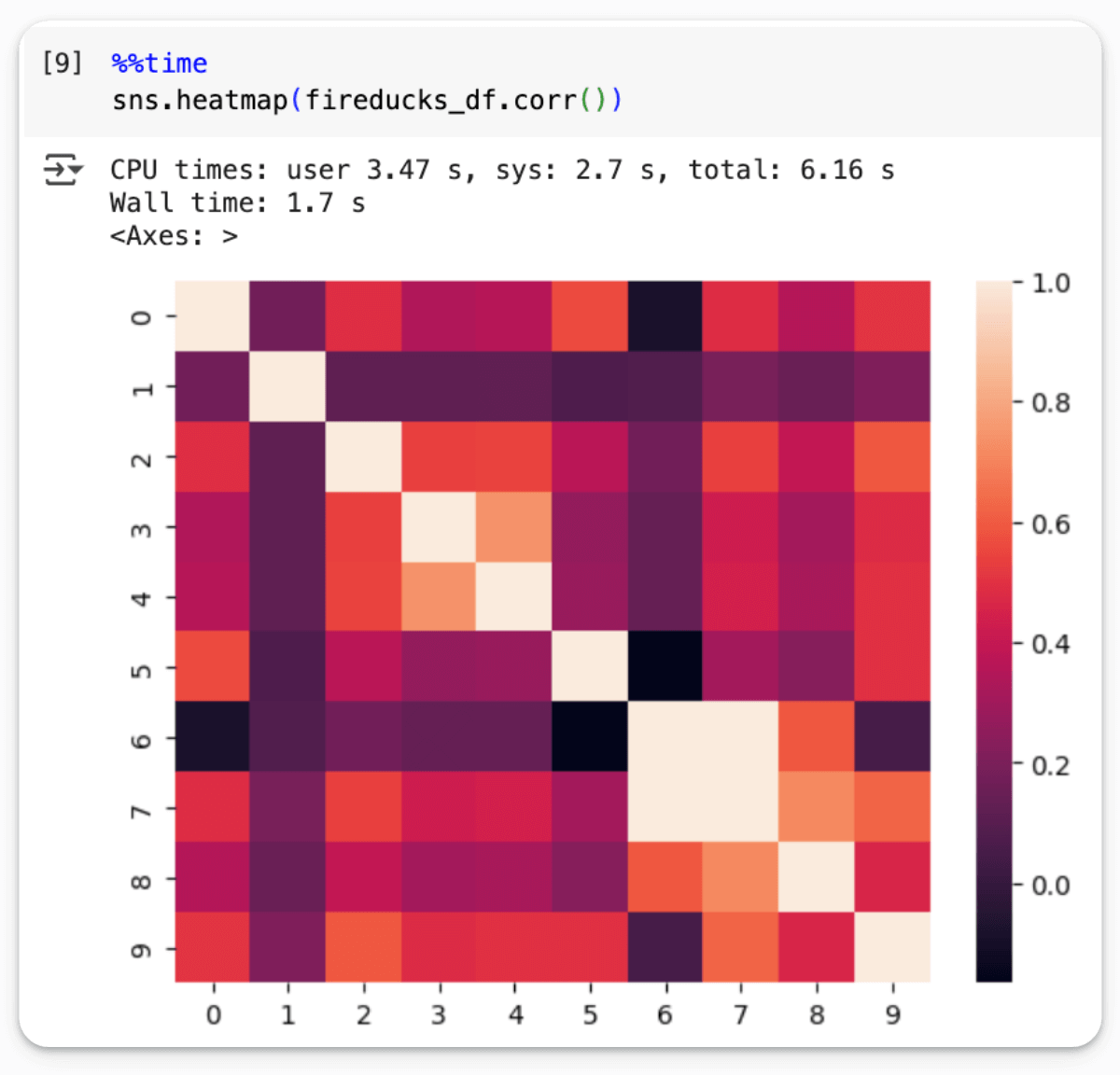
Technically, Seaborn doesn't recognize a FireDucks DataFrame.
However, because of the import-hook (via %load_ext fireducks.pandas), FireDucks can be integrated seamlessly with a third-party library like Seaborn that expects a Pandas DataFrame.
And everything while accelerating the overall computation.
We have several benchmarking before and in all tests, FireDucks comes out to be the fastest:
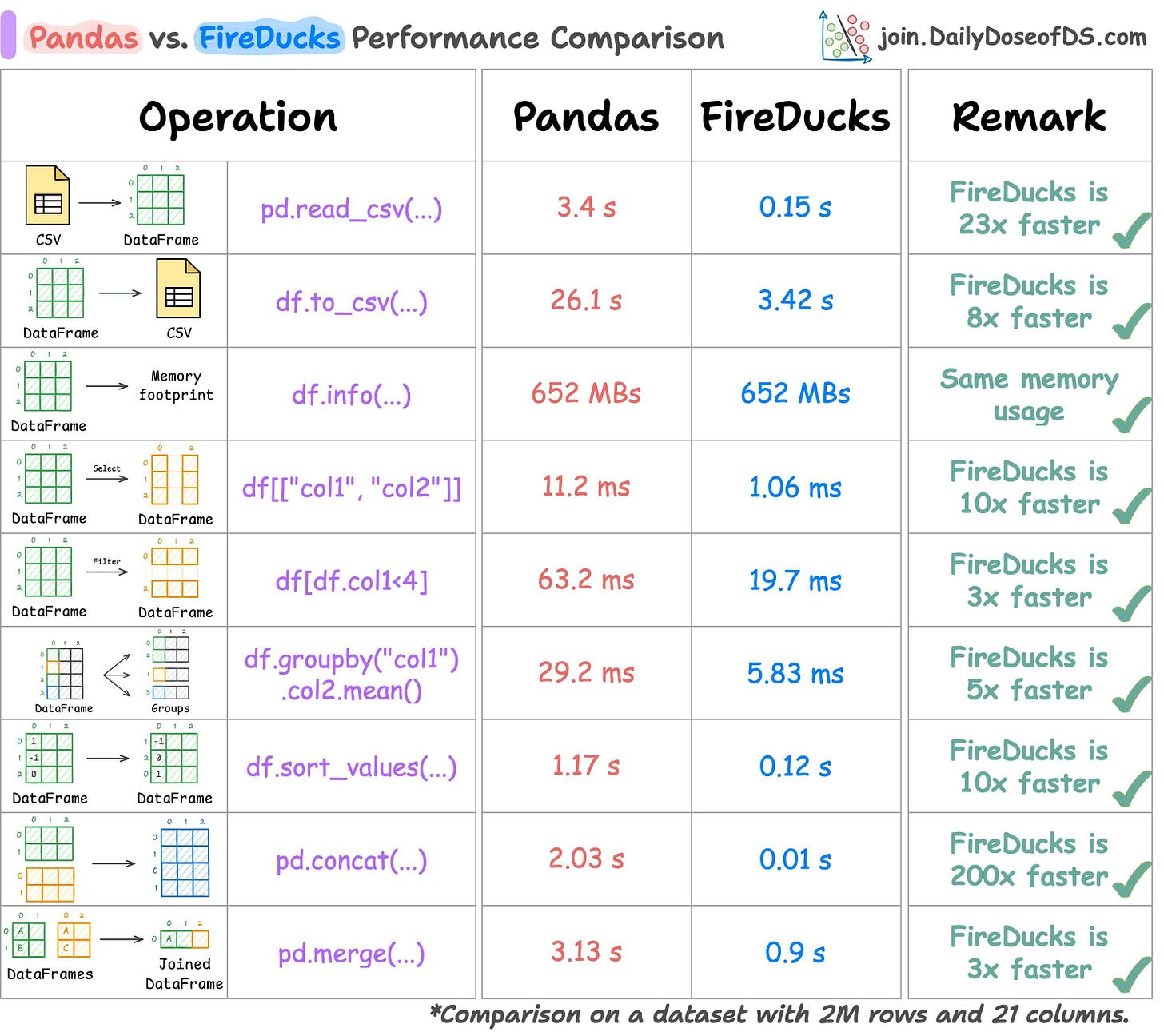
In all cases, FireDucks is the fastest.
You can find the Colab notebook for Seaborn integration here →
Thanks for reading!
One critical problem with the traditional RAG system is that questions are not semantically similar to their answers.
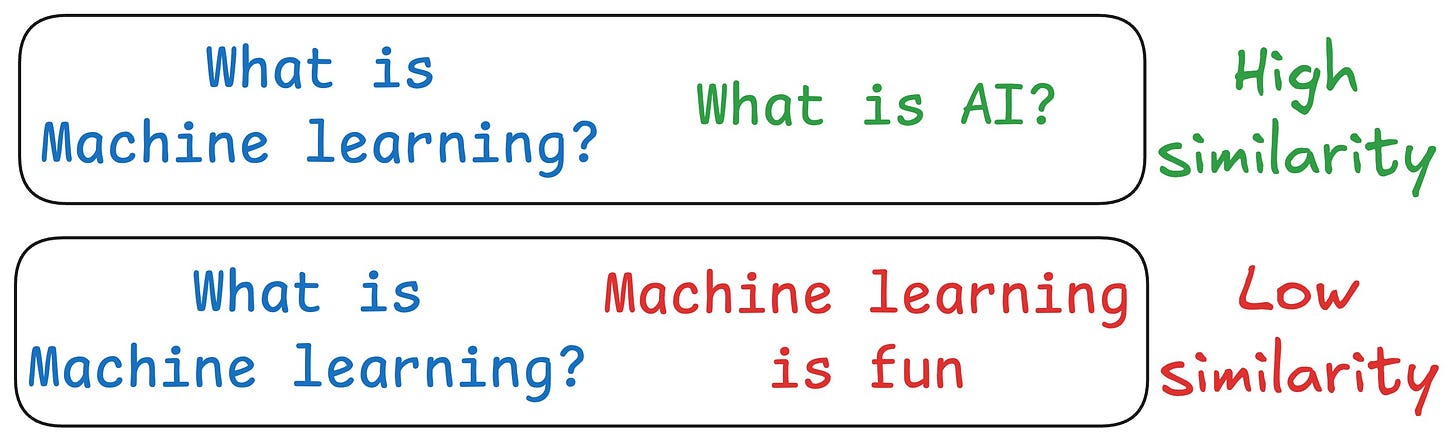
As a result, several irrelevant contexts get retrieved during the retrieval step due to a higher cosine similarity than the documents actually containing the answer.
HyDE solves this.
The following visual depicts how it differs from traditional RAG and HyDE.
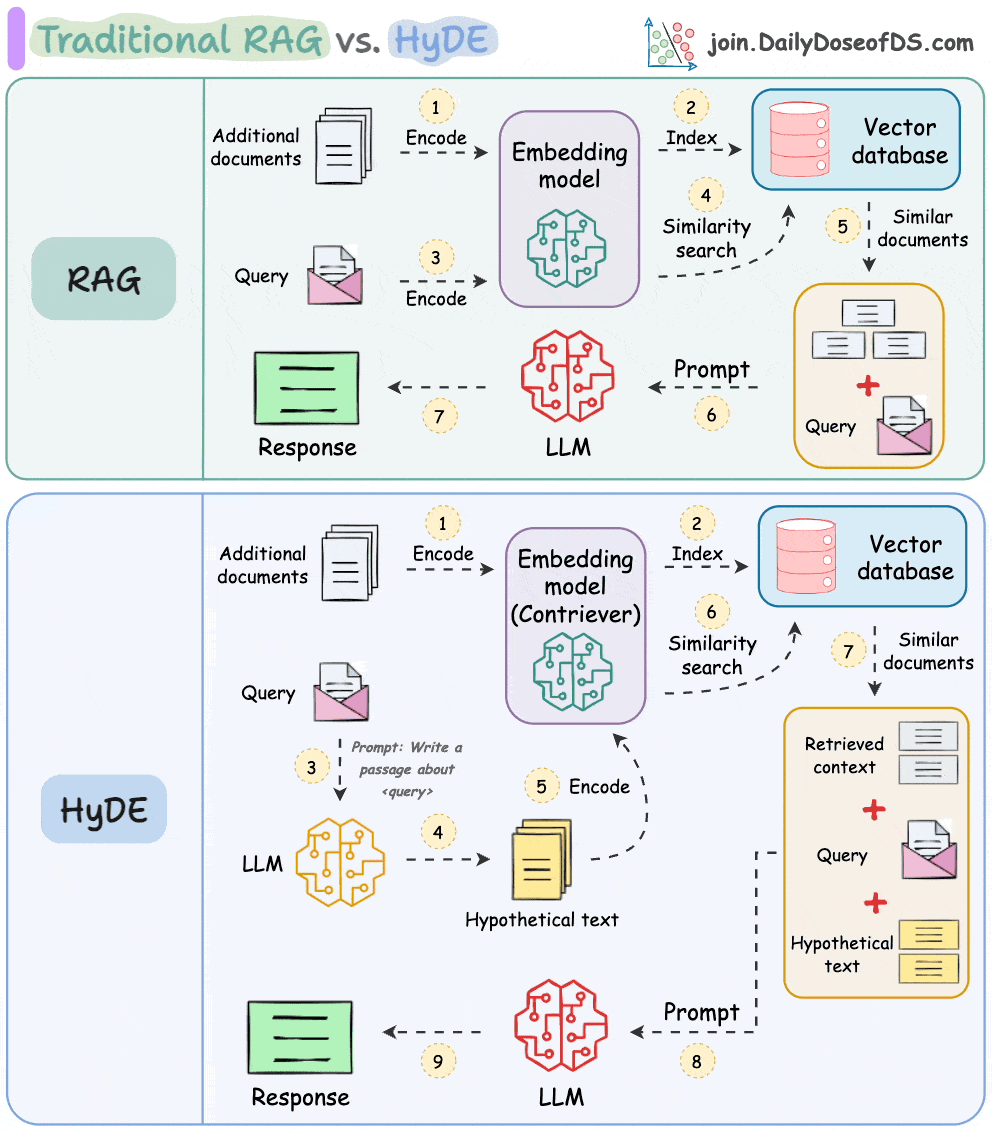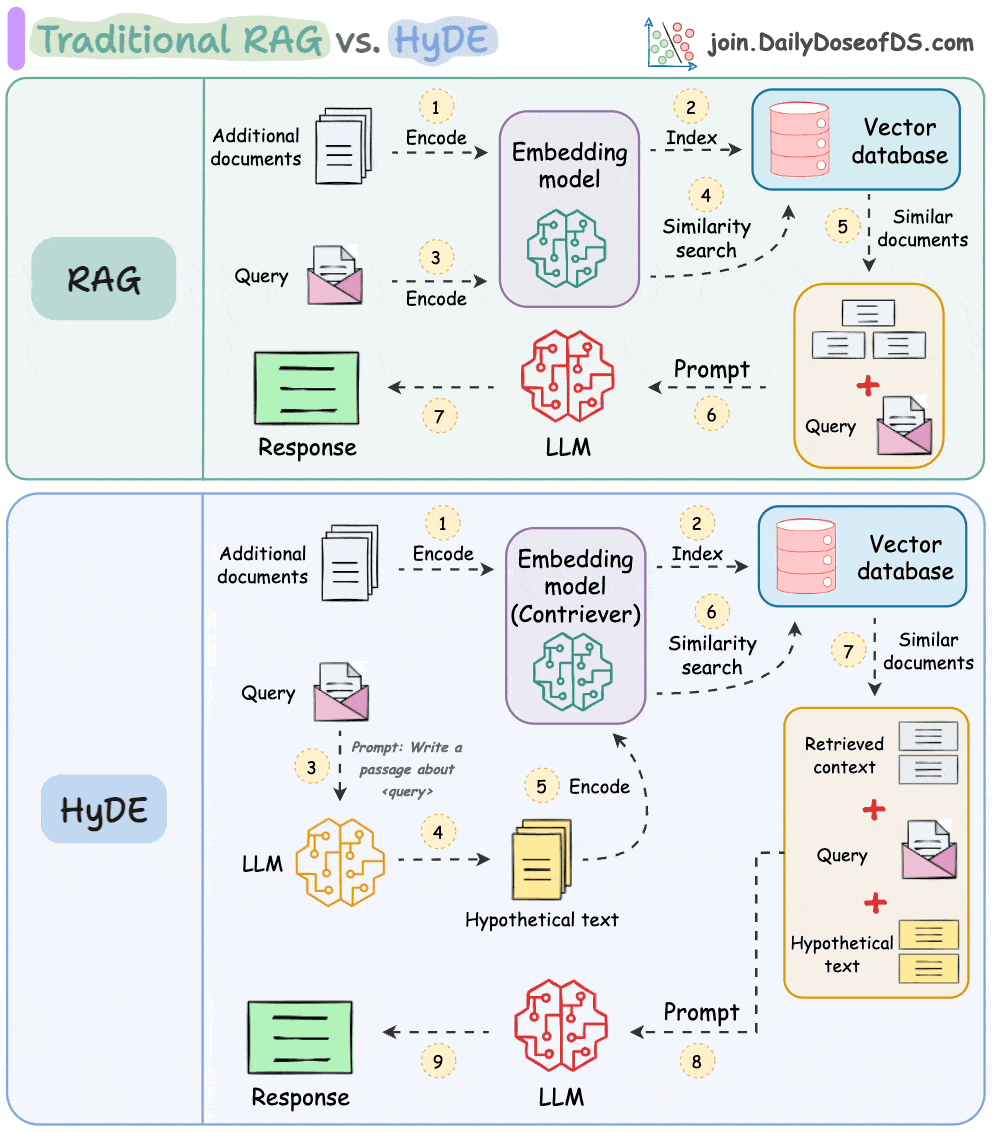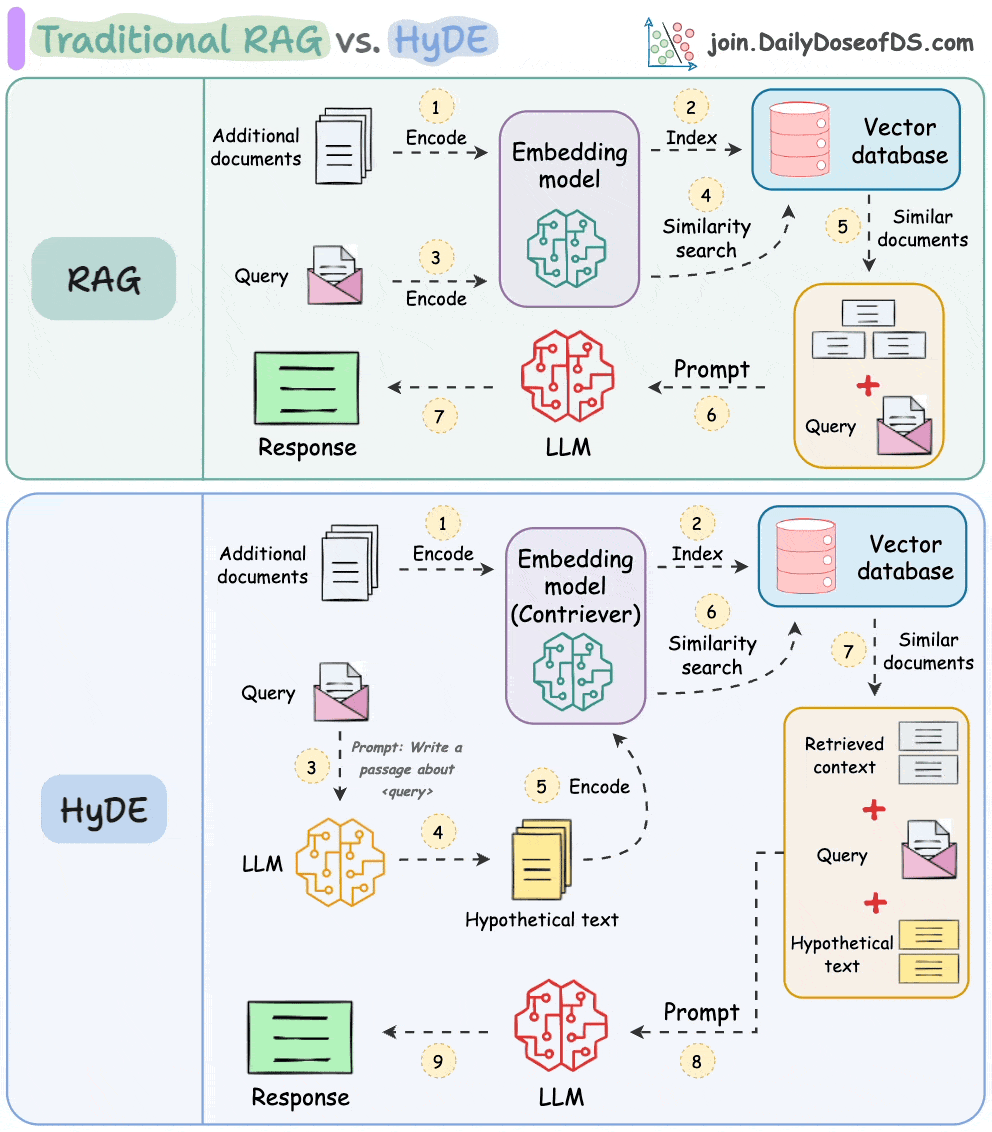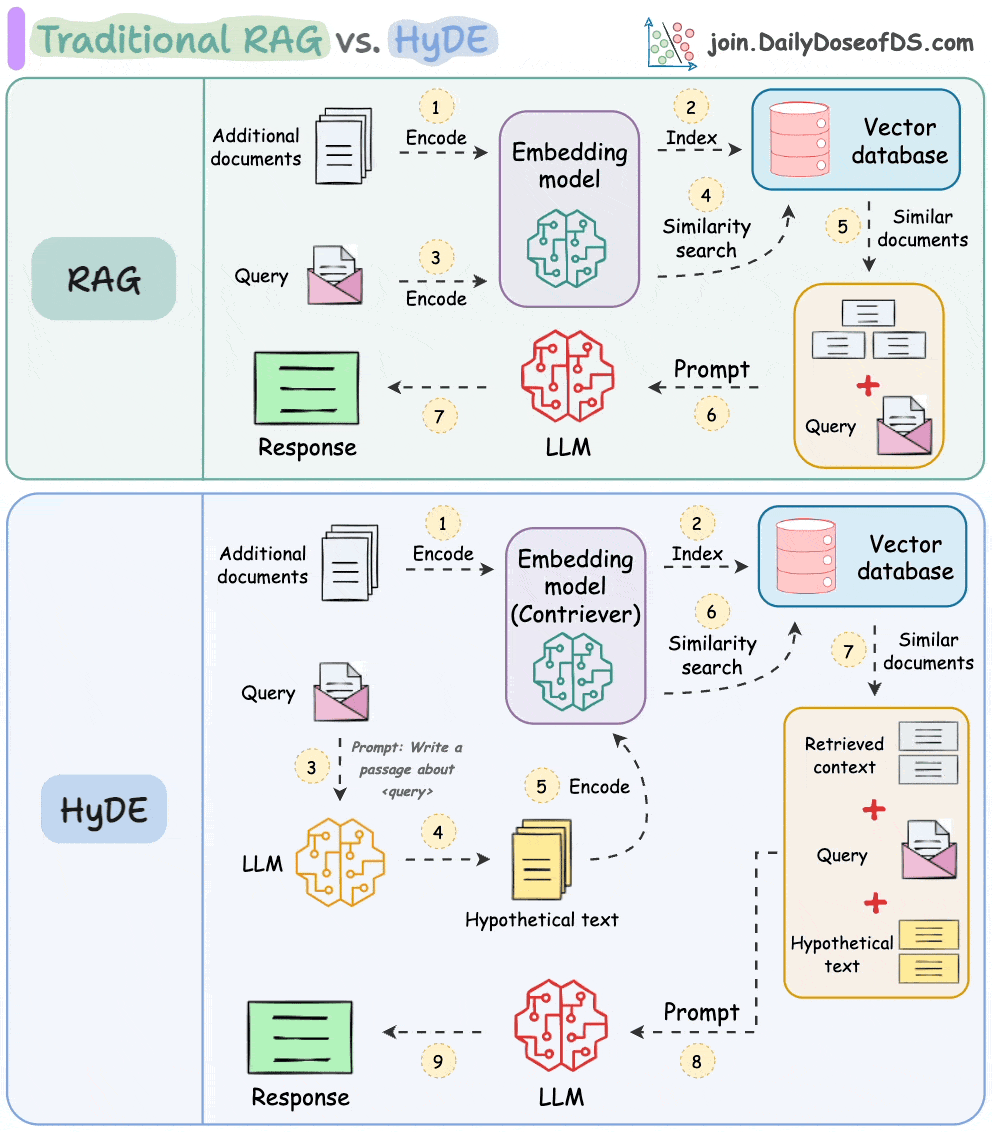
We covered this in detail in a newsletter issue published last week →
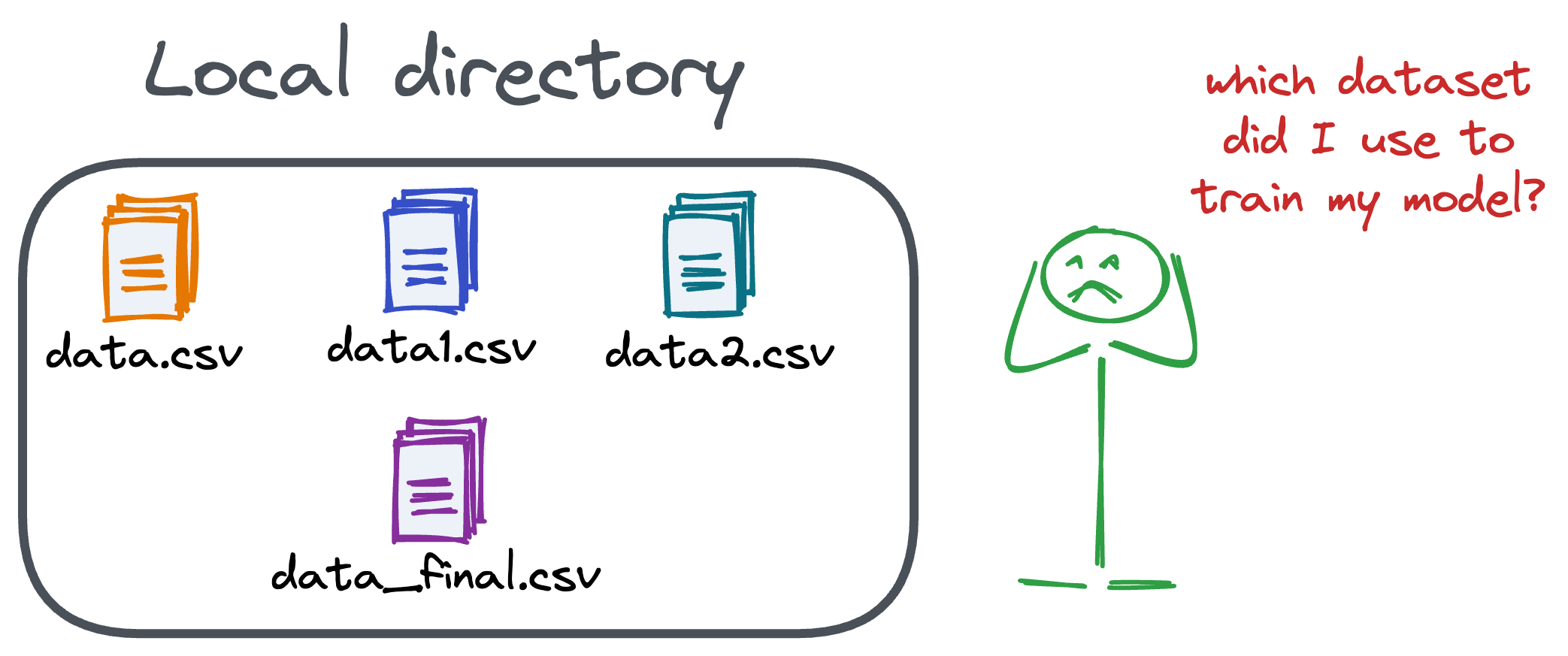
Versioning GBs of datasets is practically impossible with GitHub because it imposes an upper limit on the file size we can push to its remote repositories.
That is why Git is best suited for versioning codebase, which is primarily composed of lightweight files.
However, ML projects are not solely driven by code.
Instead, they also involve large data files, and across experiments, these datasets can vastly vary.
To ensure proper reproducibility and experiment traceability, it is also necessary to version datasets.
Data version control (DVC) solves this problem.
The core idea is to integrate another version controlling system with Git, specifically used for large files.
Here's everything you need to know (with implementation) about building 100% reproducible ML projects →