Clustering
Categorization of Clustering Algorithms
...explained in a single frame.

Avi Chawla
...explained in a single frame.

TODAY'S ISSUE
Dynamiq is a completely open-source, low-code, and all-in-one Gen AI framework for developing LLM applications with AI Agents and RAGs.
Here’s what stood out for me about Dynamiq:
All this makes it 10x easier to build production-ready AI applications.
If you're an AI Engineer, Dynamiq will save you hours of tedious orchestrations!
There’s a whole world of clustering algorithms beyond KMeans, which a data scientist must be familiar with.
In the following visual, we have summarized 6 different types of clustering algorithms:
1) Centroid-based: Cluster data points based on proximity to centroids.
2) Connectivity-based: Cluster points based on proximity between clusters.
3) Density-based: Cluster points based on their density. It is more robust to clusters with varying densities and shapes than centroid-based clustering.
4) Graph-based: Cluster points based on graph distance.
5) Distribution-based: Cluster points based on their likelihood of belonging to the same distribution.
6) Compression-based: Transform data to a lower dimensional space and then perform clustering.
👉 Over to you: What other clustering algorithms will you include here?
“Because” is possibly one of the most powerful words in business decision-making.
Backing any observation/insights with causality gives so much ability to confidently use the word “because” in business/regular discussions.
Identifying these causal relationships is vital because these relationships typically require an additional inspection and statistical analysis that goes beyond the typical correlation analysis (which anyone can do).
Learn how to develop causal inference-driven systems →
It uncovers:
Model accuracy alone (or an equivalent performance metric) rarely determines which model will be deployed.
Much of the engineering effort goes into making the model production-friendly.
Because typically, the model that gets shipped is NEVER solely determined by performance — a misconception that many have.
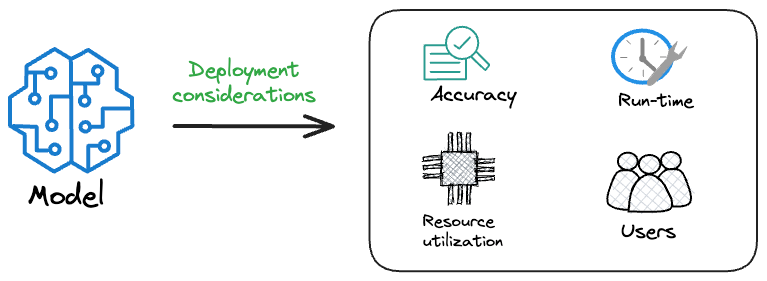
Instead, we also consider several operational and feasibility metrics, such as:
For instance, consider the image below. It compares the accuracy and size of a large neural network I developed to its pruned (or reduced/compressed) version:
Looking at these results, don’t you strongly prefer deploying the model that is 72% smaller, but is still (almost) as accurate as the large model?
Of course, this depends on the task but in most cases, it might not make any sense to deploy the large model when one of its largely pruned versions performs equally well.
We discussed and implemented 6 model compression techniques in the article here, which ML teams regularly use to save 1000s of dollars in running ML models in production.
Learn how to compress models before deployment with implementation →