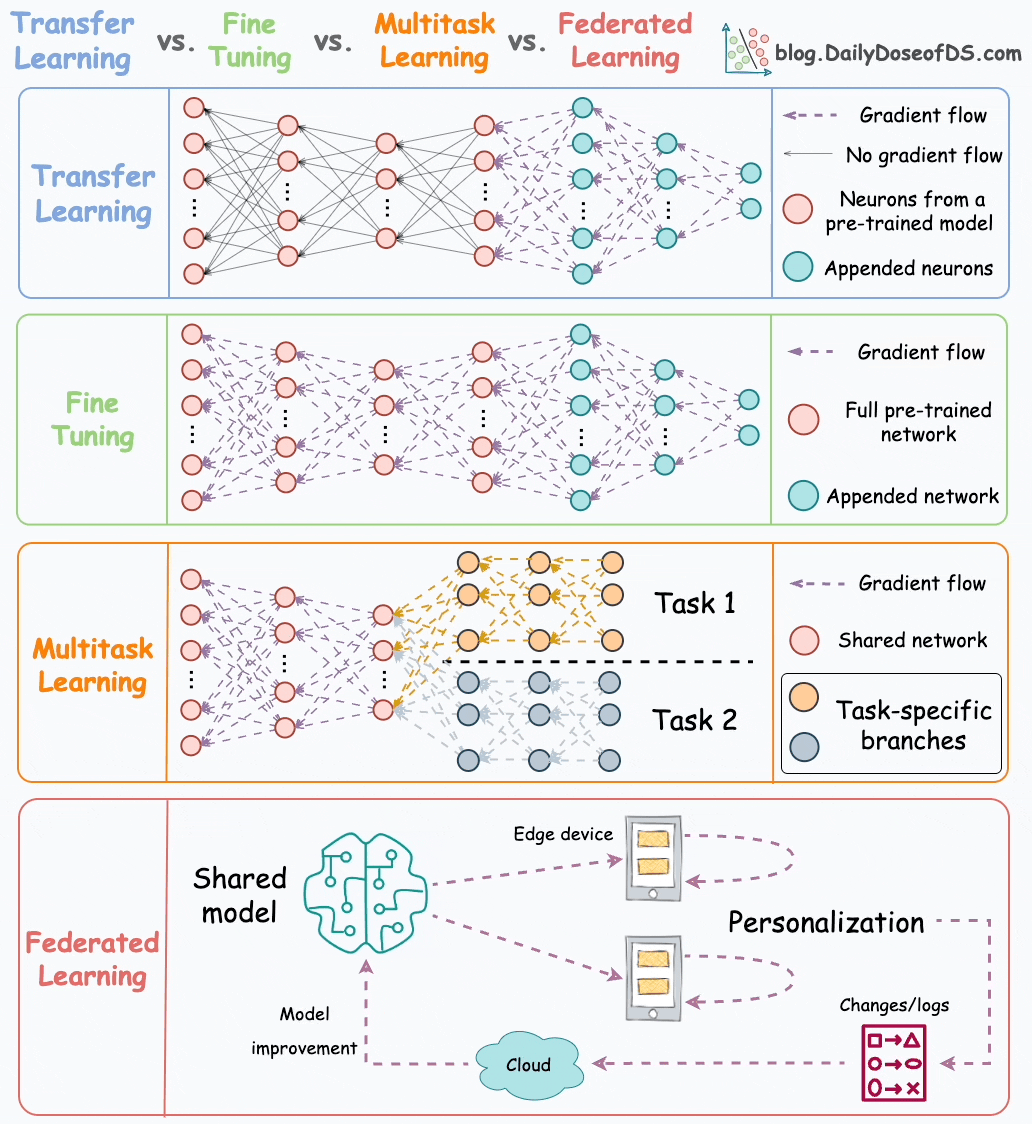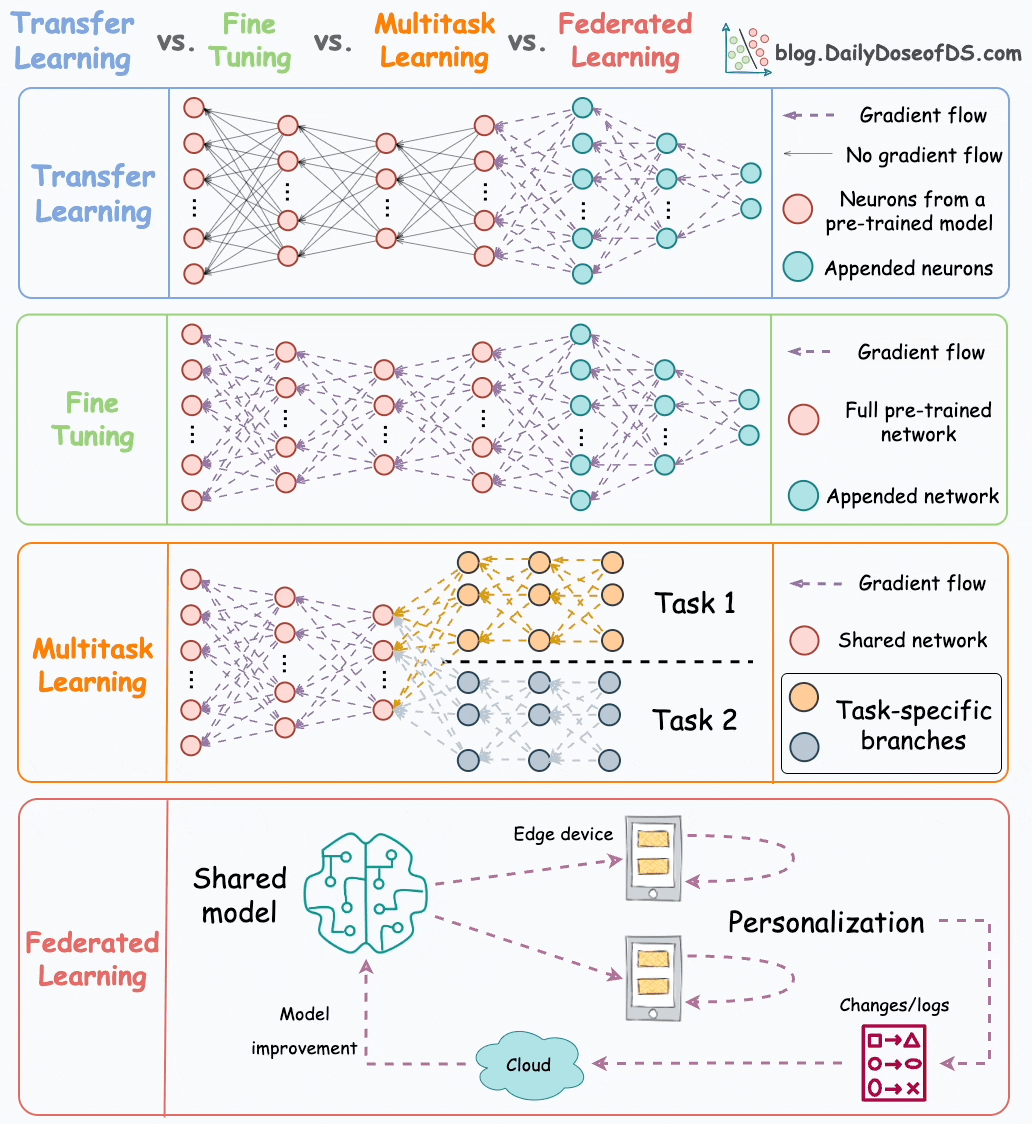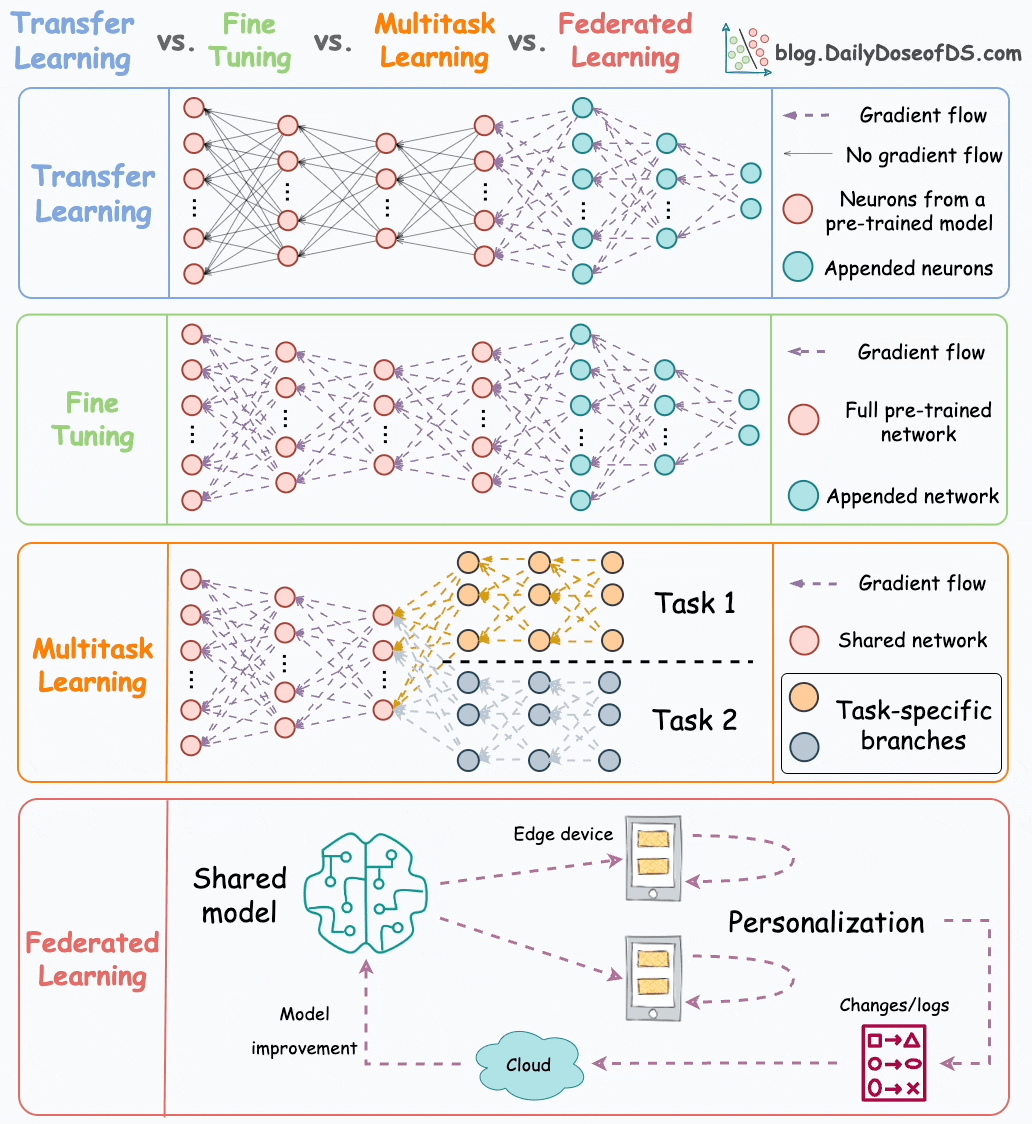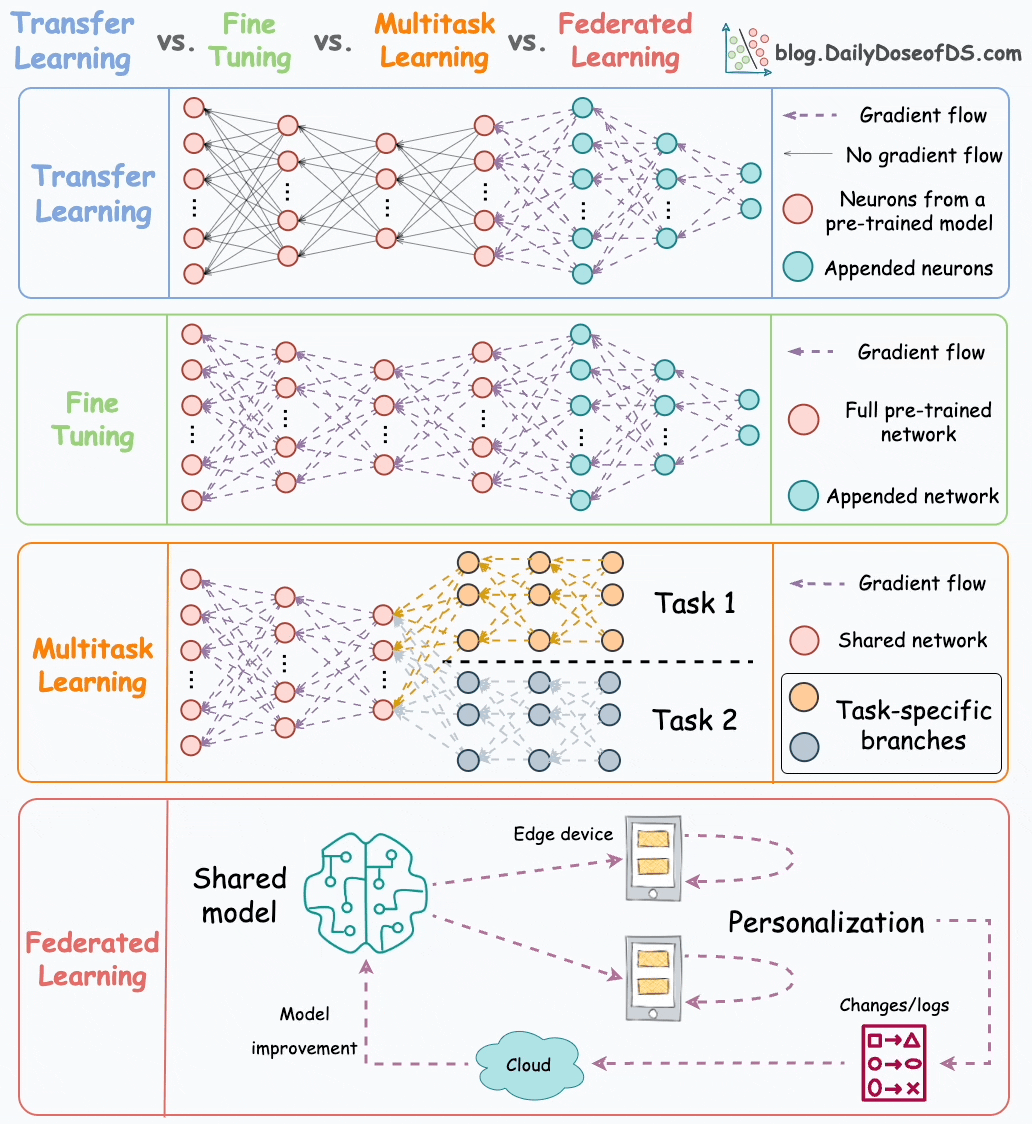
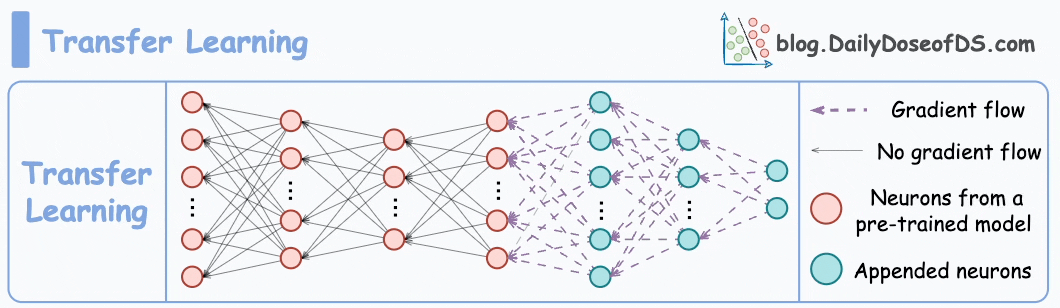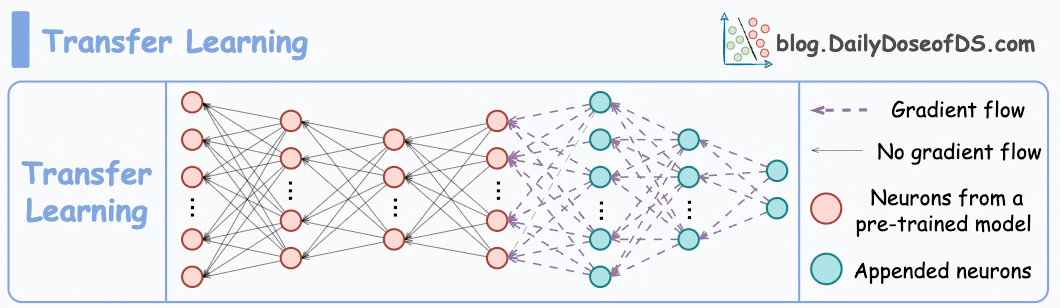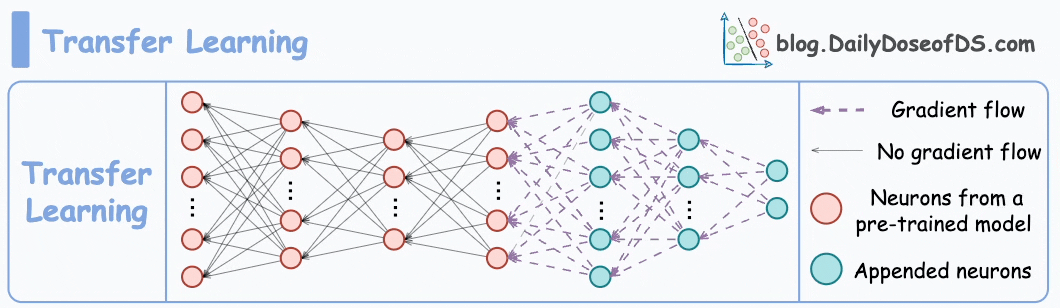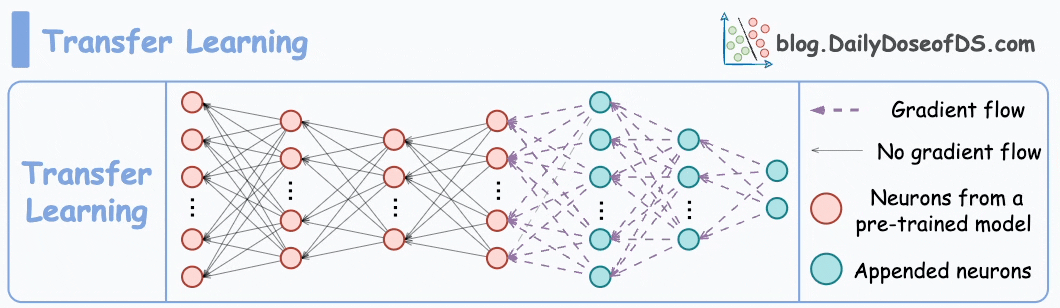
Transfer learning is commonly used in many computer vision tasks.
#2) Fine-tuning
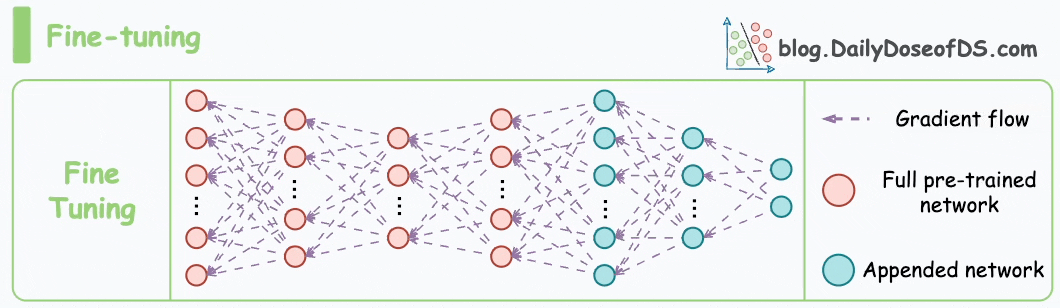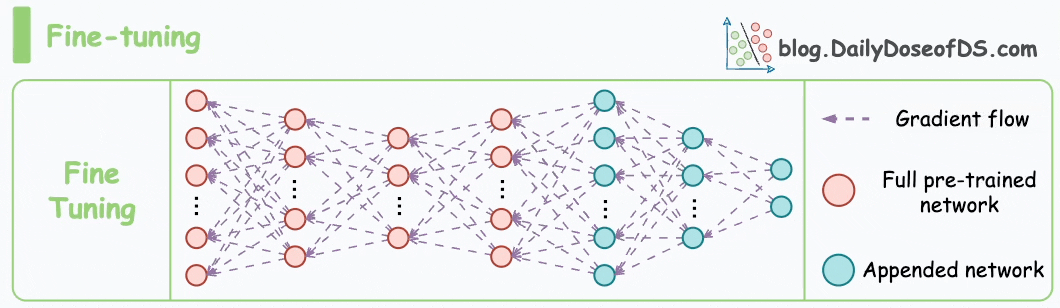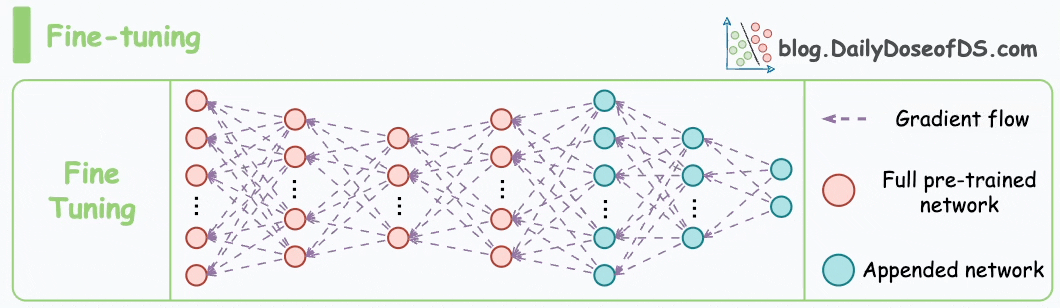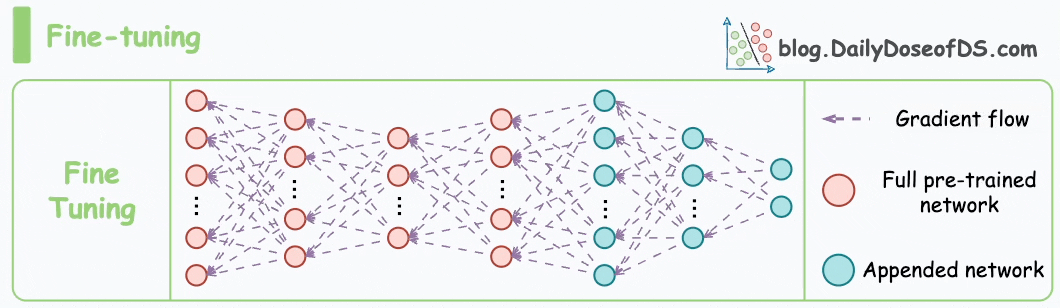
Fine-tuning involves updating the weights of some or all layers of the pre-trained model to adapt it to the new task.
The idea may appear similar to transfer learning, but in fine-tuning, we typically do not replace the last few layers of the pre-trained network.
Instead, the pretrained model itself is adjusted to the new data.
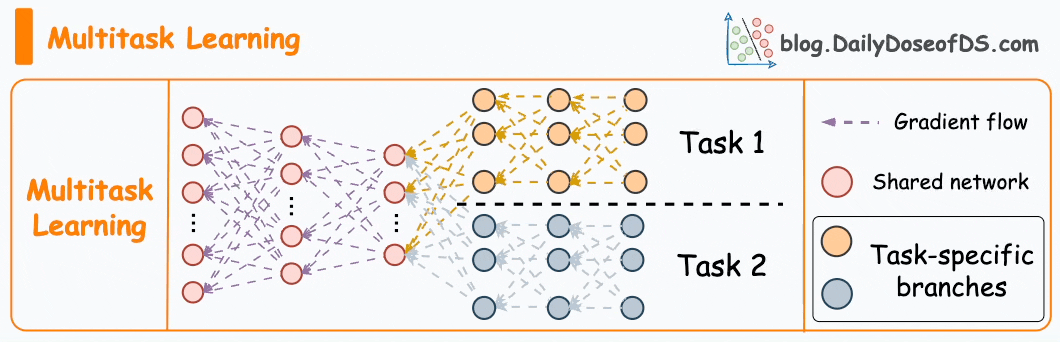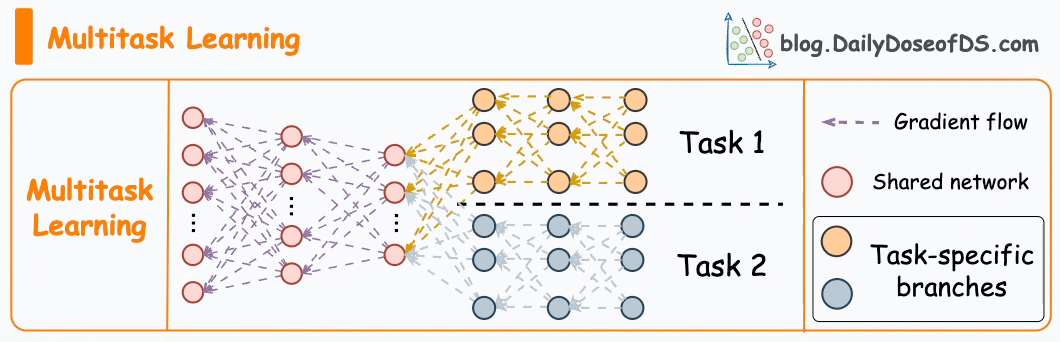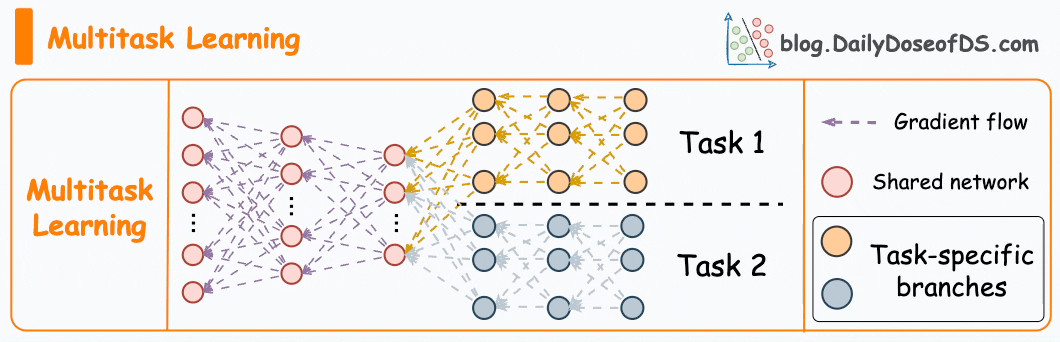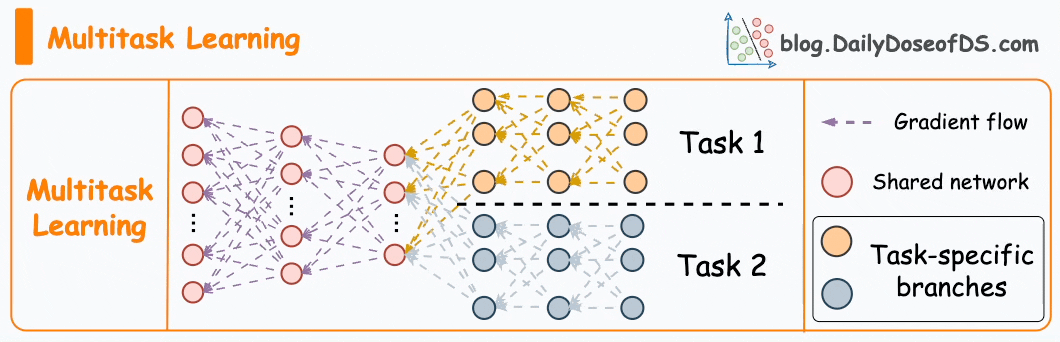
#3) Multi-task learning
As the name suggests, a model is trained to perform multiple tasks simultaneously.
The model shares knowledge across tasks, aiming to improve generalization and performance on each task.
It can help in scenarios where tasks are related, or they can benefit from shared representations.
In fact, the motive for multi-task learning is not just to improve generalization.
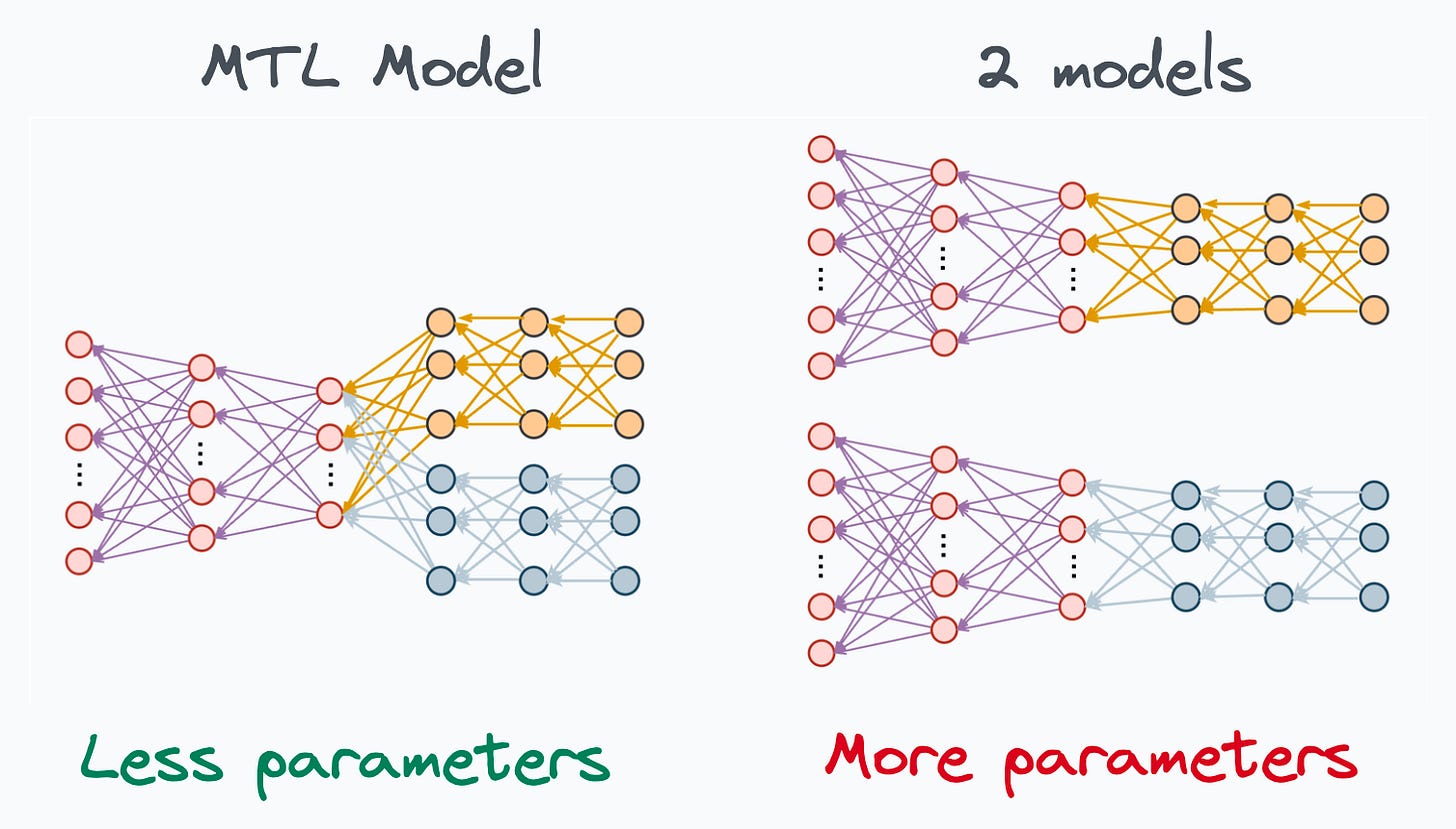
We can also save compute power during training by having a shared layer and task-specific segments.
Imagine training two models independently on related tasks.
Now compare it to having a network with shared layers and then task-specific branches.
Option 2 will typically result in:
Better generalization across all tasks.
Less memory utilization to store model weights.
Less resource utilization during training.
This and this are two of the best survey papers I have ever read on multi-task learning.
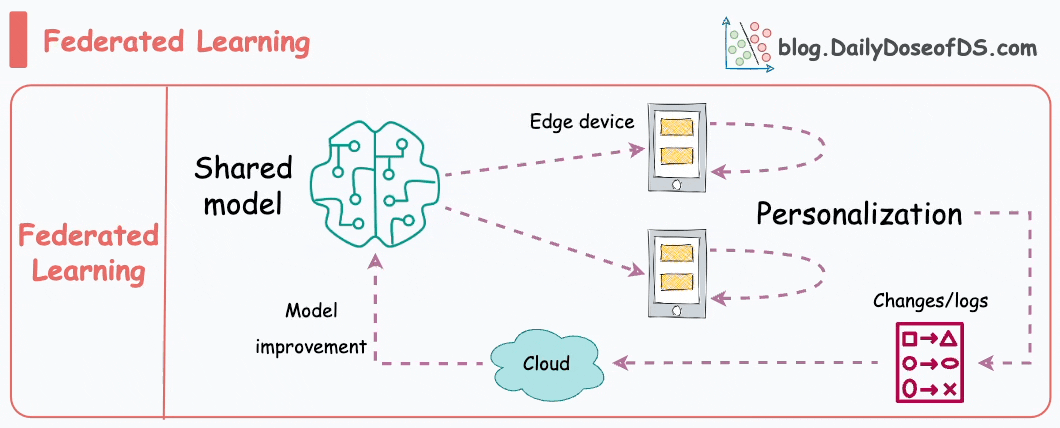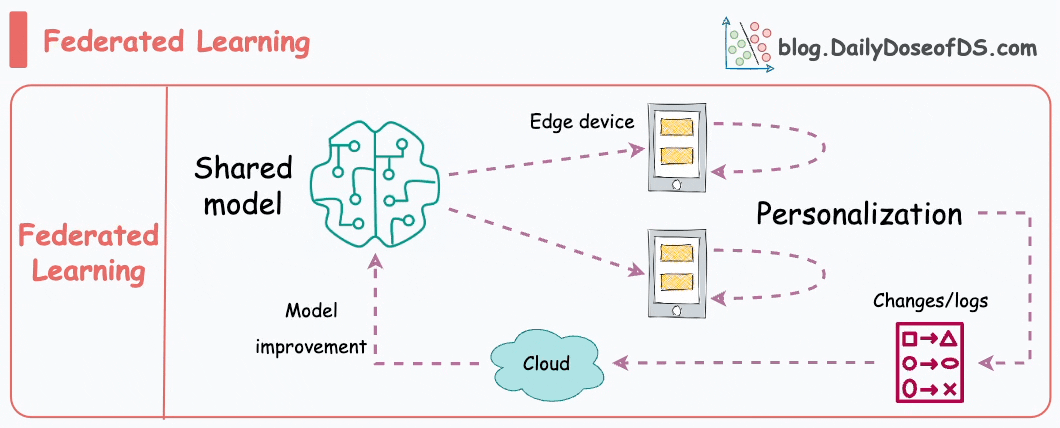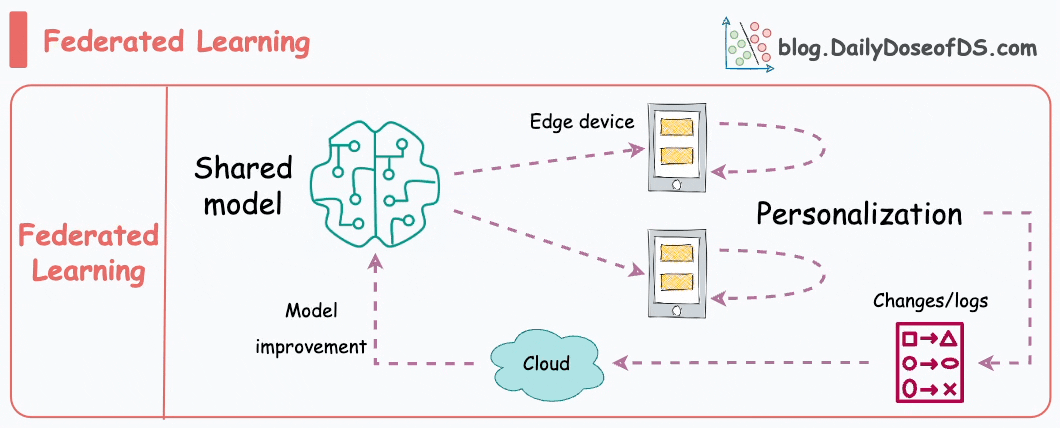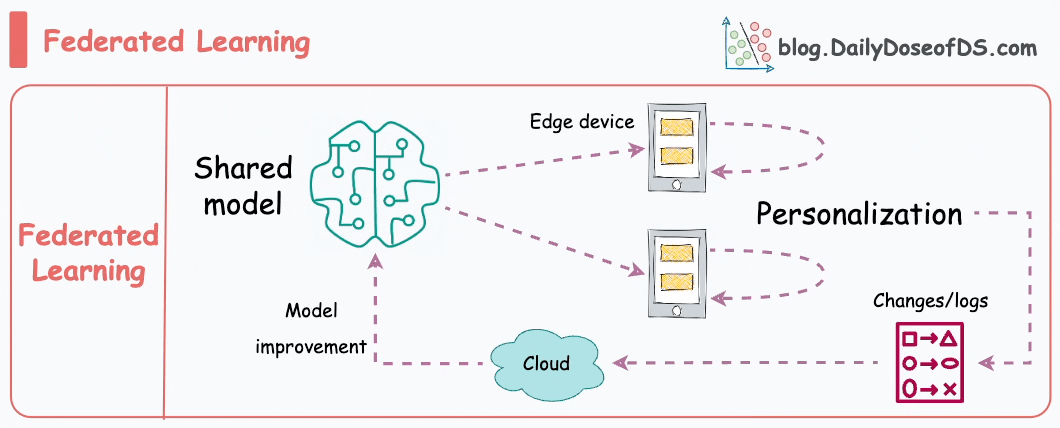
#4) Federated learning
This is another pretty cool technique for training ML models.
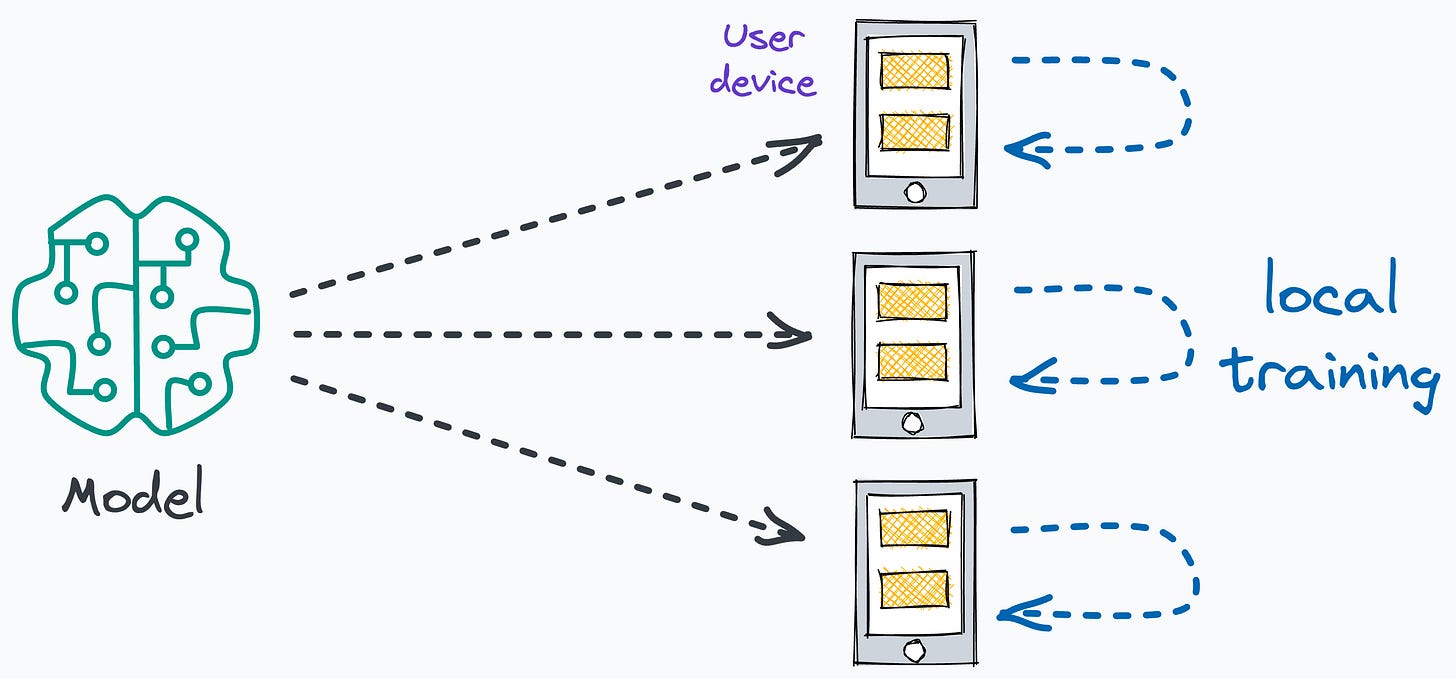
Simply put, federated learning is a decentralized approach to machine learning. Here, the training data remains on the devices (e.g., smartphones) of users.
Instead of sending data to a central server, models are sent to devices, trained locally, and only model updates are gathered and sent back to the server.
It is particularly useful to enhance privacy and security. What’s more, it also reduces the need for centralized data collection.
The keyboard of our smartphone is a great example of this.
Federated learning allows our smartphone’s keyboard to learn and adapt to our typing habits. This happens without transmitting sensitive keystrokes or personal data to a central server.
The model, which predicts our next word or suggests auto-corrections, is sent to our device, and the device itself fine-tunes the model based on our input.
Over time, the model becomes personalized to our typing style while preserving our data privacy and security.
Do note that as the model is trained on small devices, it also means that these models must be extremely lightweight yet powerful enough to be useful.
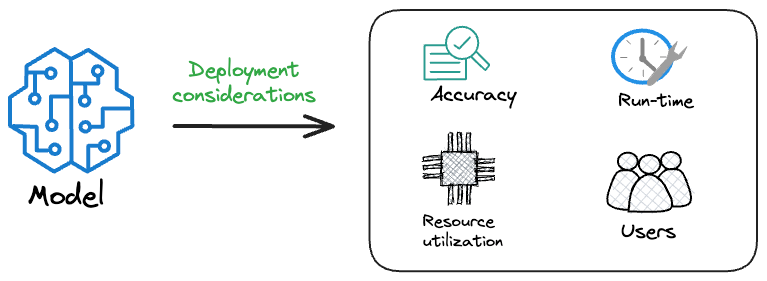
Model accuracy alone (or an equivalent performance metric) rarely determines which model will be deployed.
Much of the engineering effort goes into making the model production-friendly.
Because typically, the model that gets shipped is NEVER solely determined by performance — a misconception that many have.
Instead, we also consider several operational and feasibility metrics, such as:
Inference Latency: Time taken by the model to return a prediction.
Model size: The memory occupied by the model.
Ease of scalability, etc.
For instance, consider the image below. It compares the accuracy and size of a large neural network I developed to its pruned (or reduced/compressed) version:
Looking at these results, don’t you strongly prefer deploying the model that is 72% smaller, but is still (almost) as accurate as the large model?
Of course, this depends on the task but in most cases, it might not make any sense to deploy the large model when one of its largely pruned versions performs equally well.
We discussed and implemented 6 model compression techniques in the article here, which ML teams regularly use to save 1000s of dollars in running ML models in production.
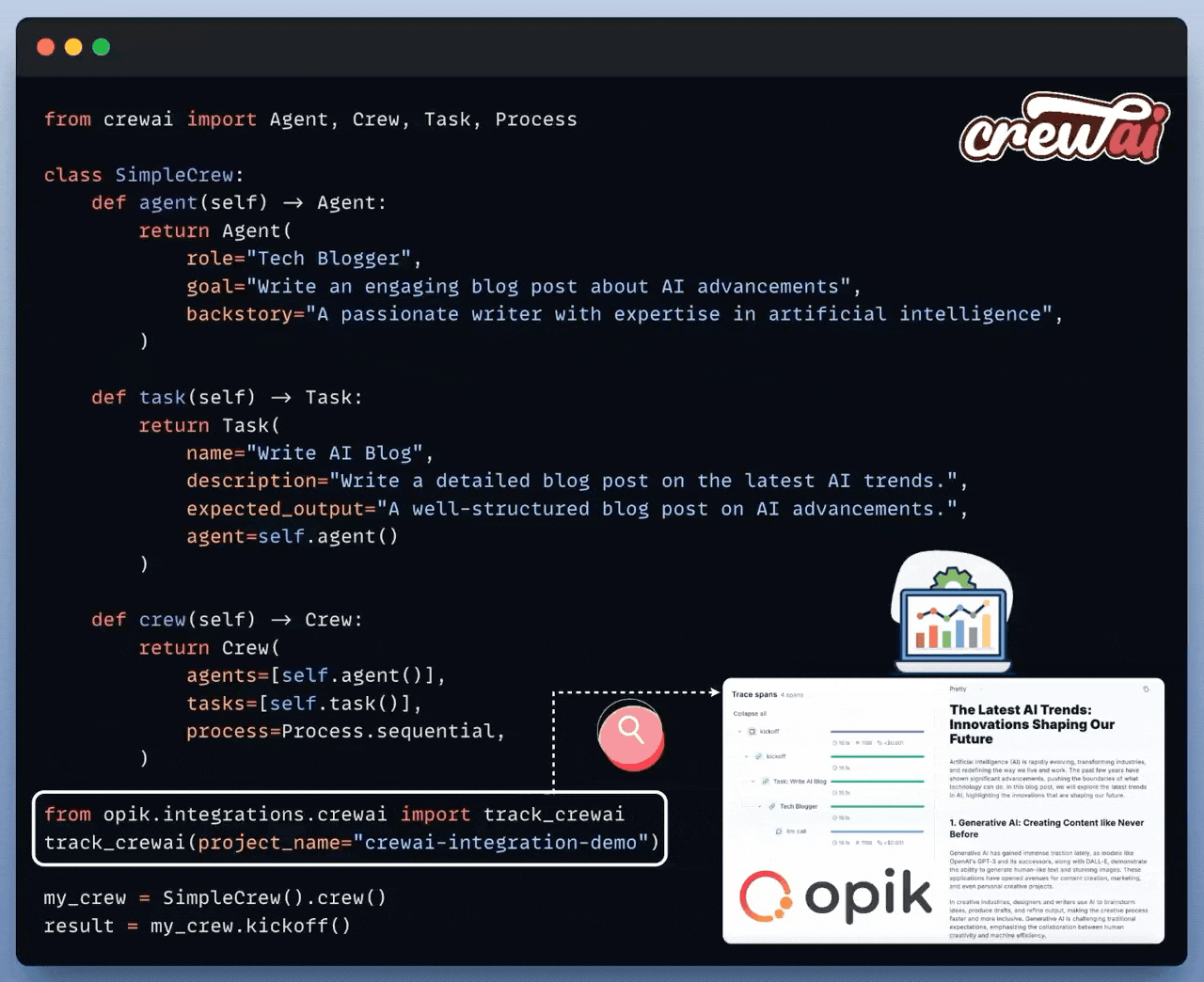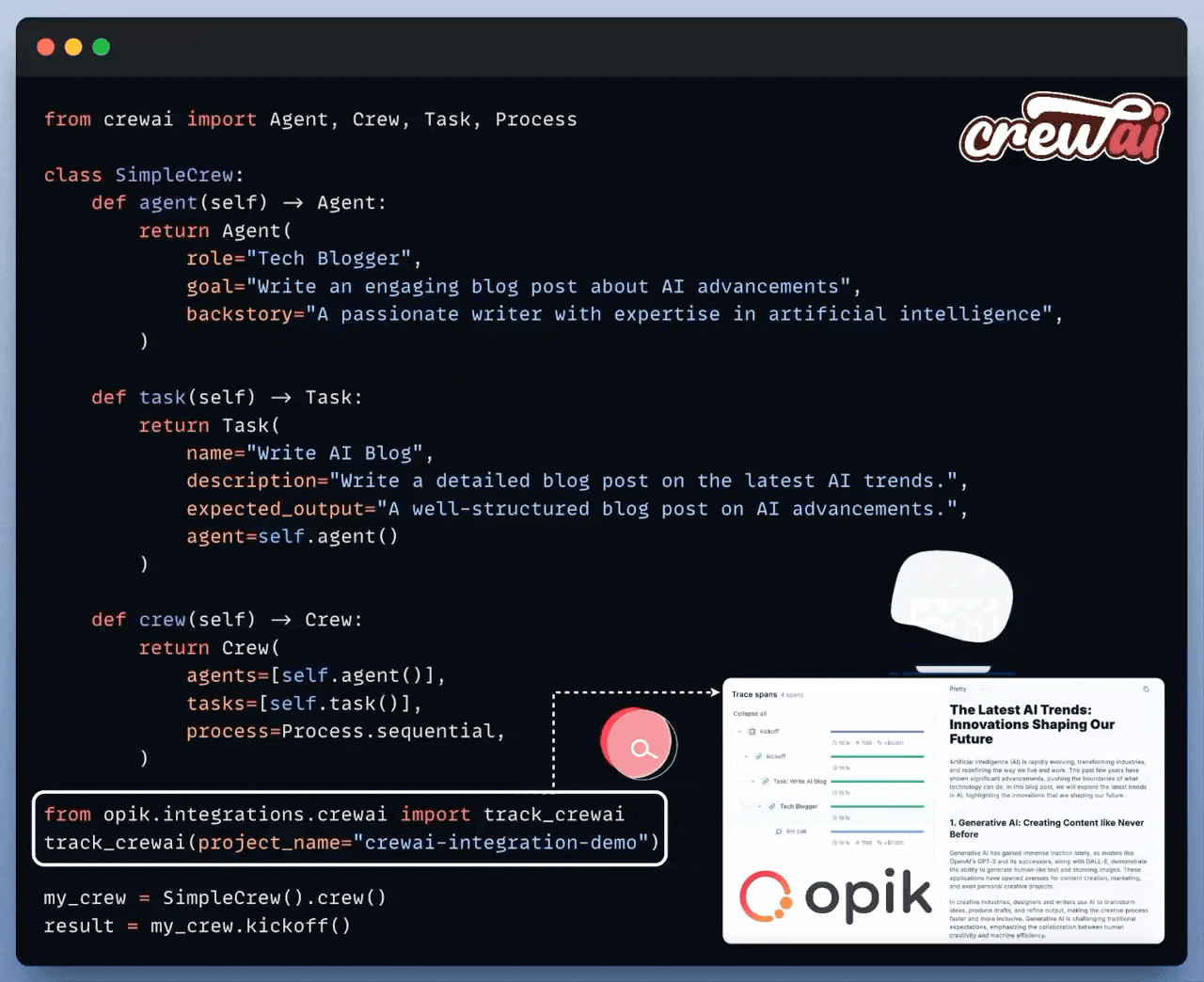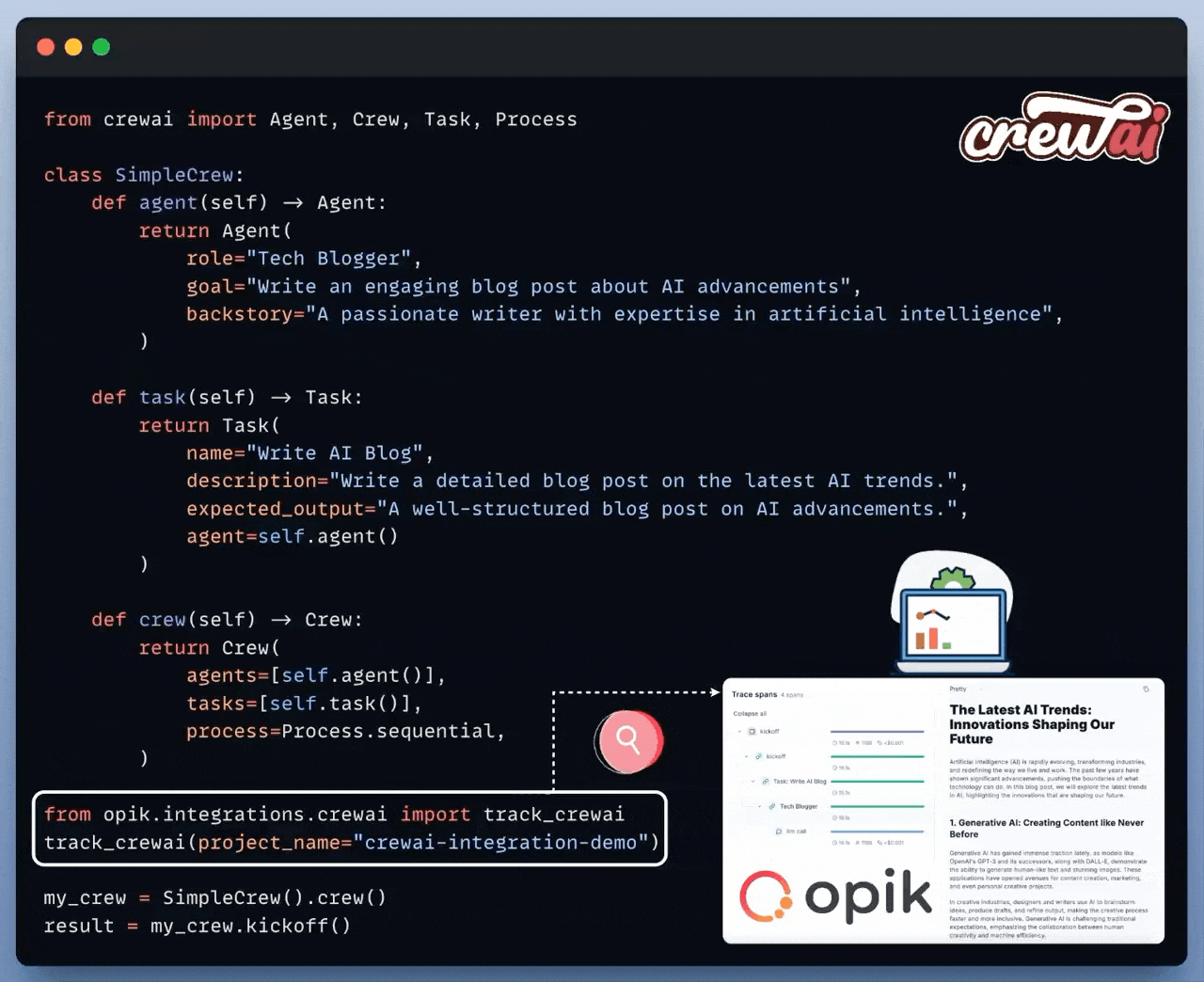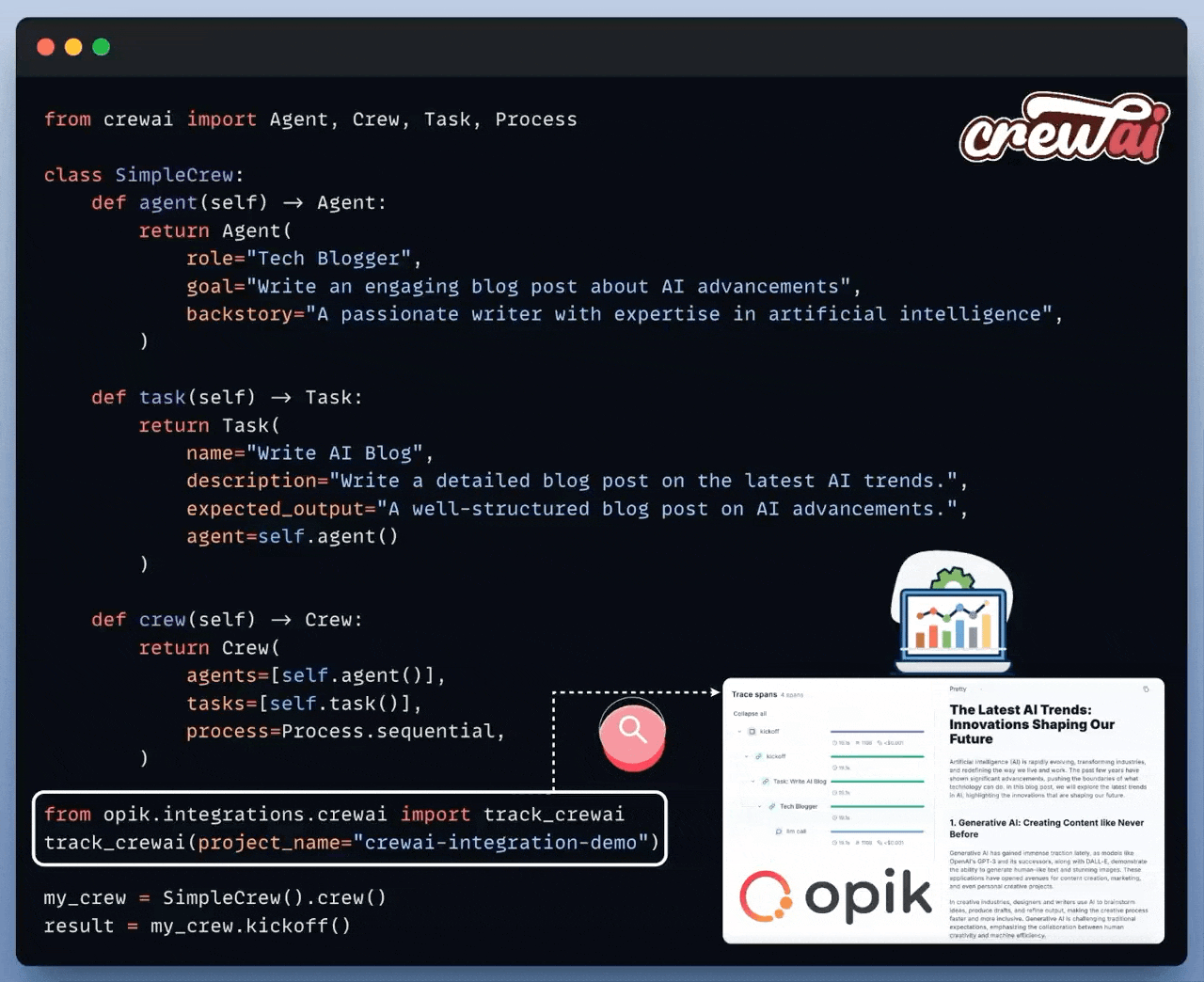
If you are building with LLMs, you absolutely need traceability.
Opik is an open-source, production-ready end-to-end LLM evaluation platform.
It allows developers to test their LLM applications in development, before a release (CI/CD), and in production.
Here’s an example with CrewAI below:
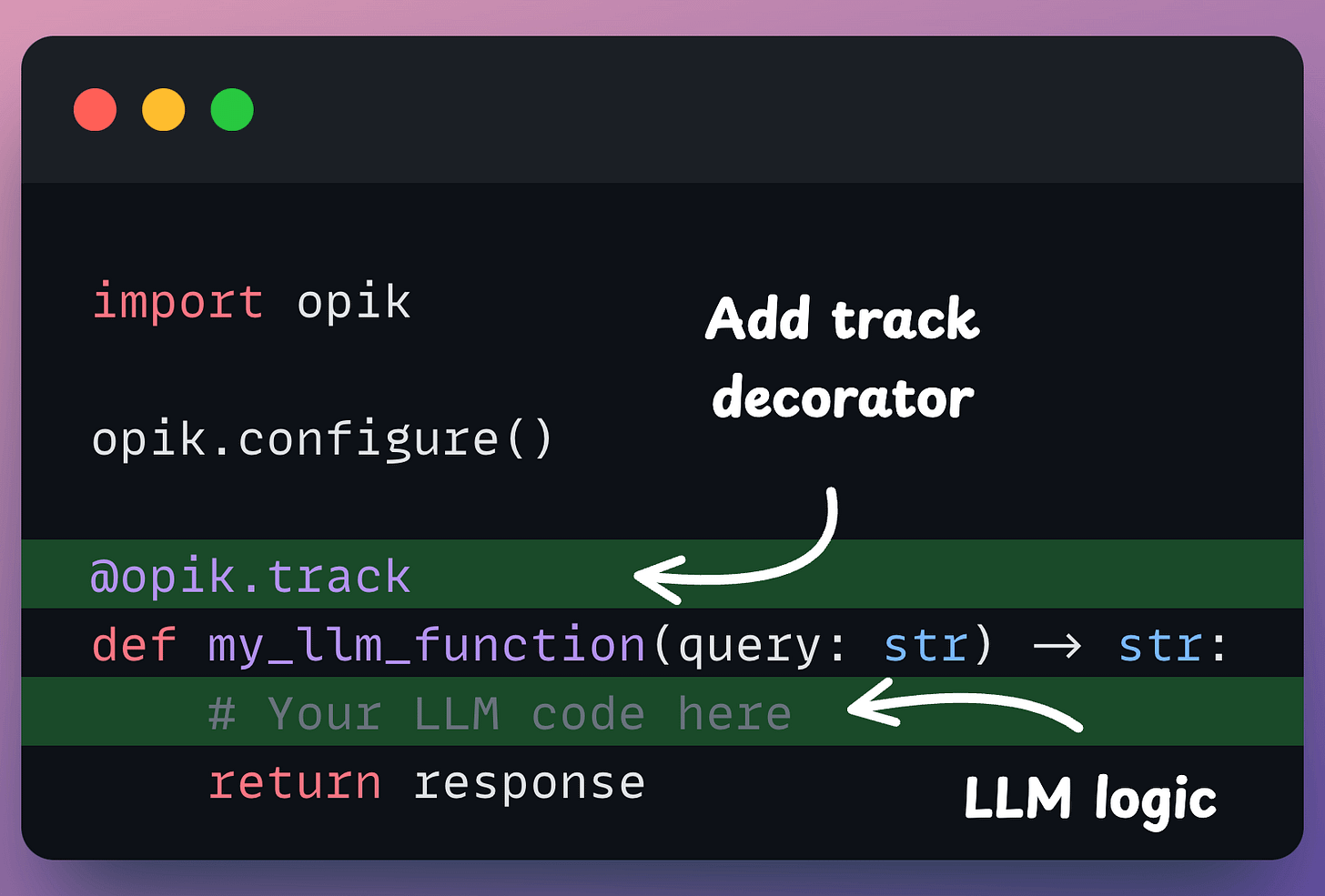
All you need to do is this:
Put your LLM logic inside a function.
Add the @track decorator.
Done!
After this, Opik will track everything within your AI application, from LLM calls (with cost) to evaluation metrics and intermediate logs.
If you want to dive further, we also published a practical guide on Opik to help you integrate evaluation and observability into your LLM apps (with implementation).