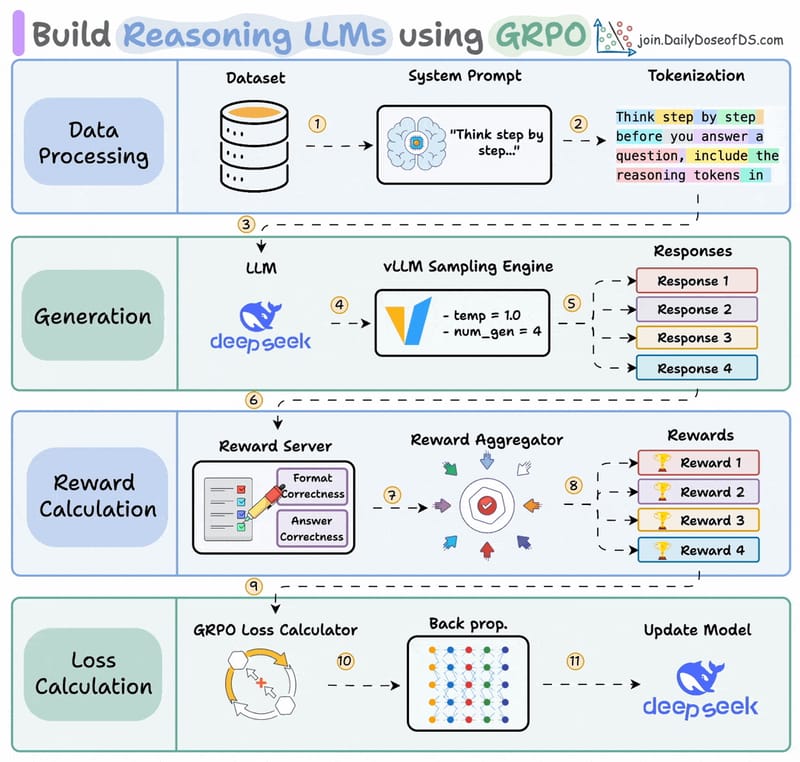
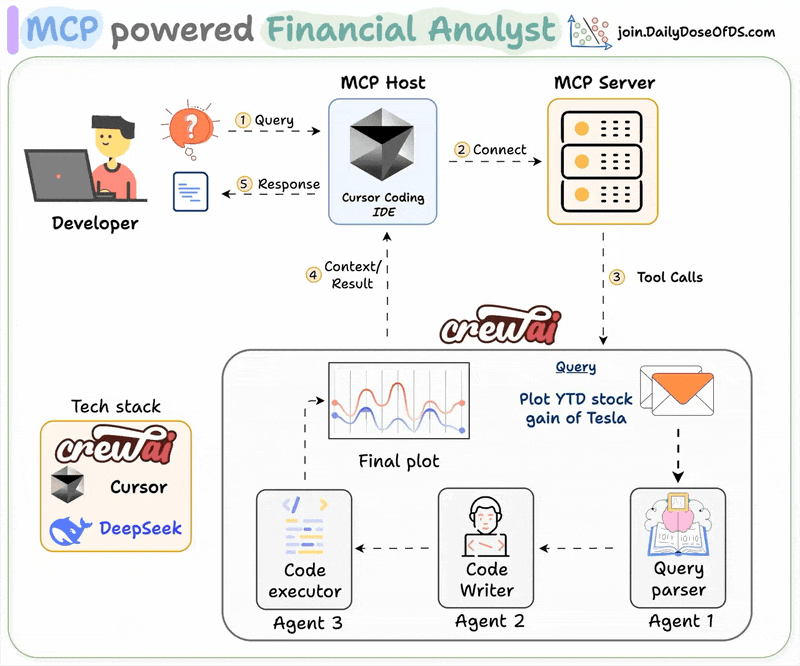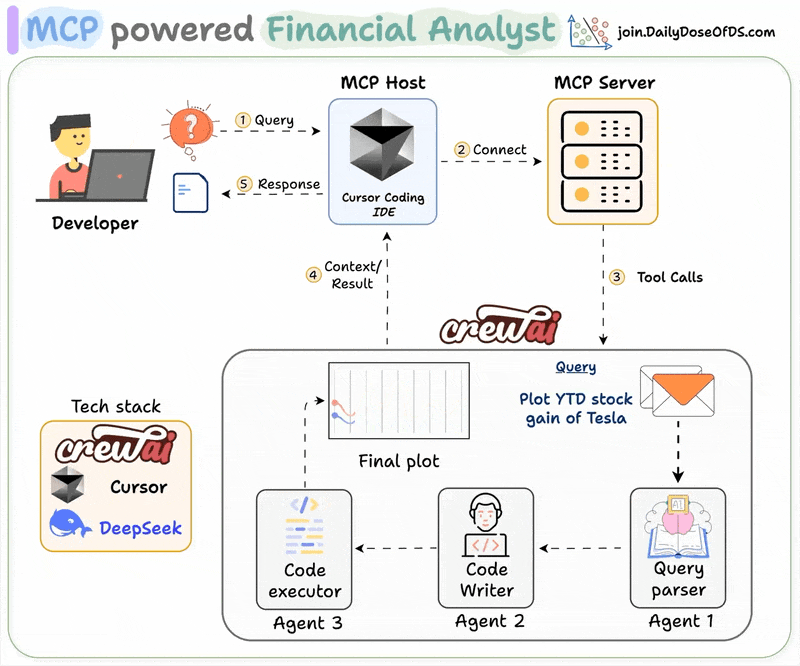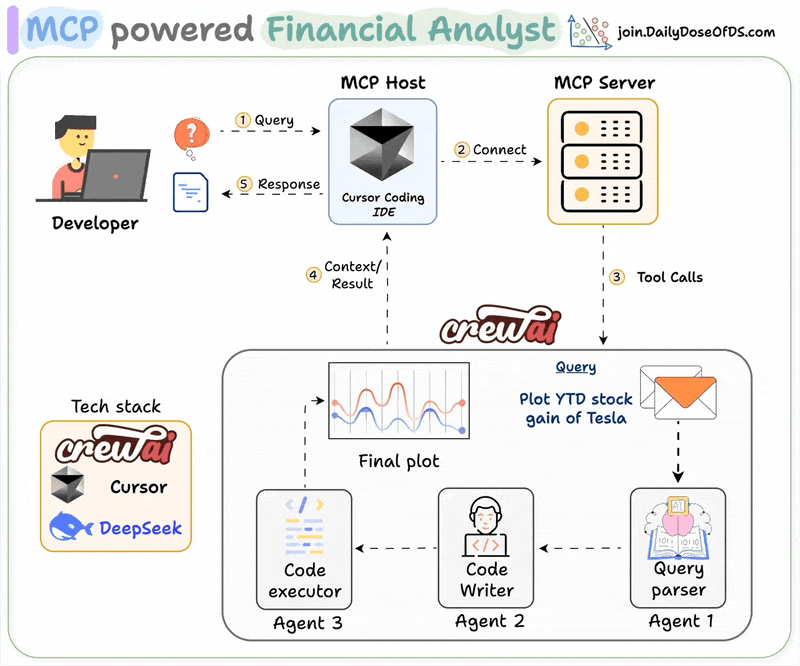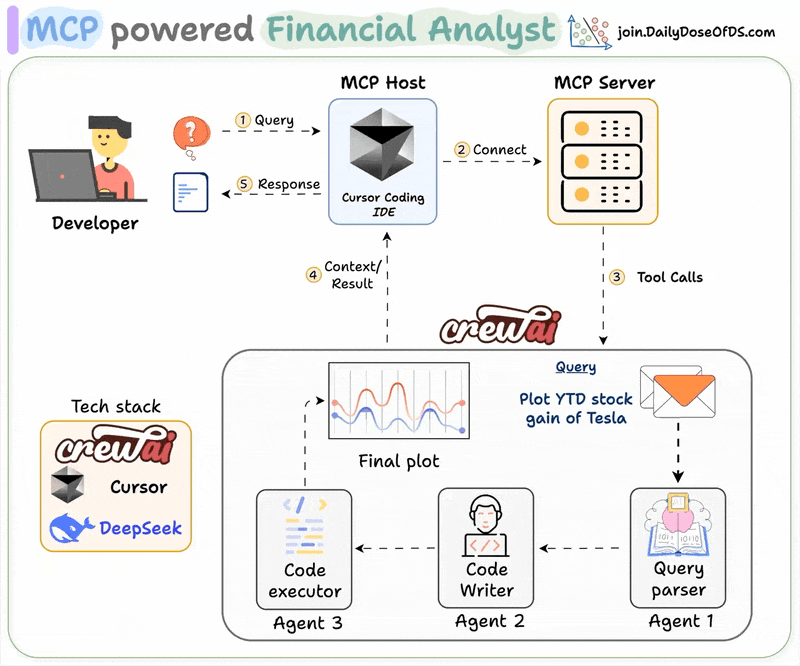
MLOps/LLMOps Course
Data and Pipeline Engineering: Distributed Processing and Workflow Orchestration
MLOps Part 7: An applied look at distributed data processing with Spark and workflow orchestration and scheduling with Prefect.




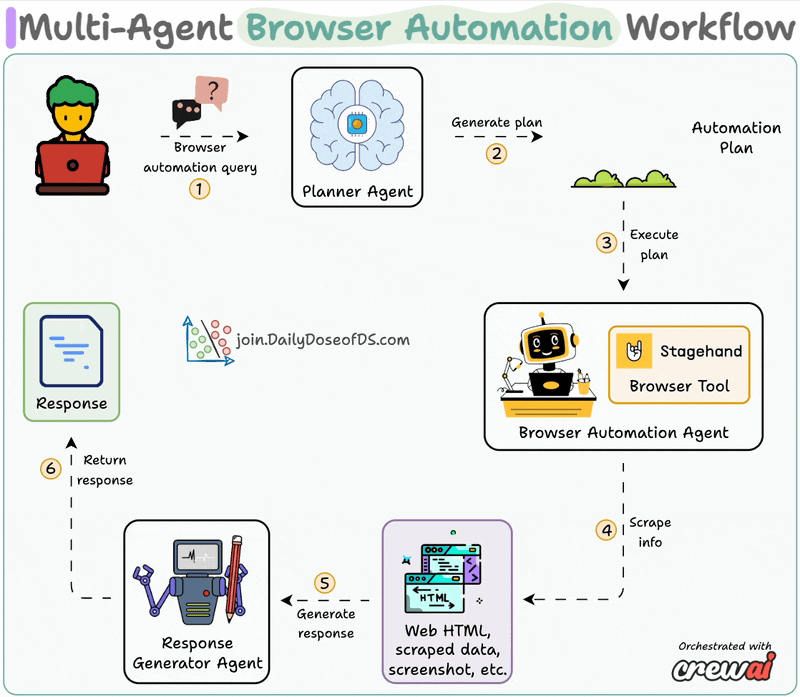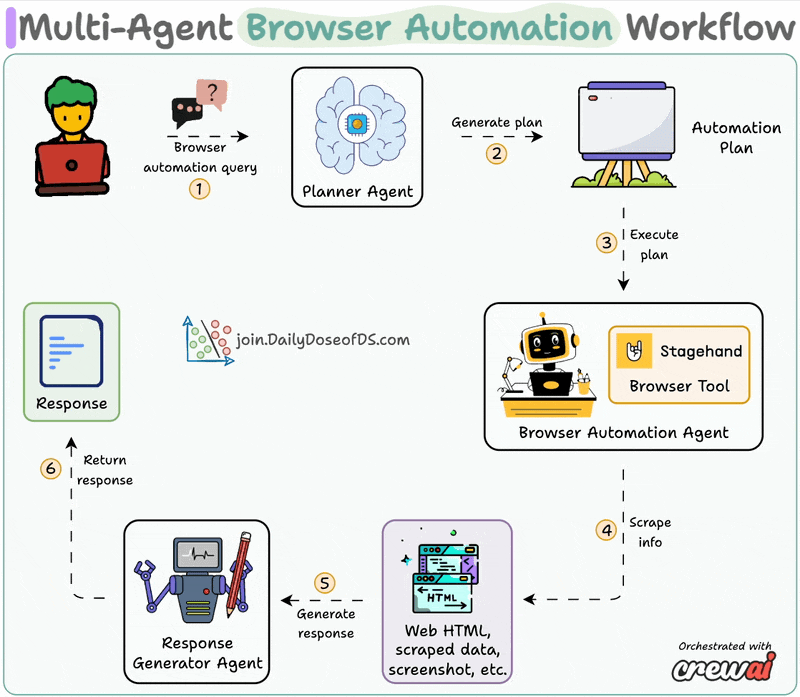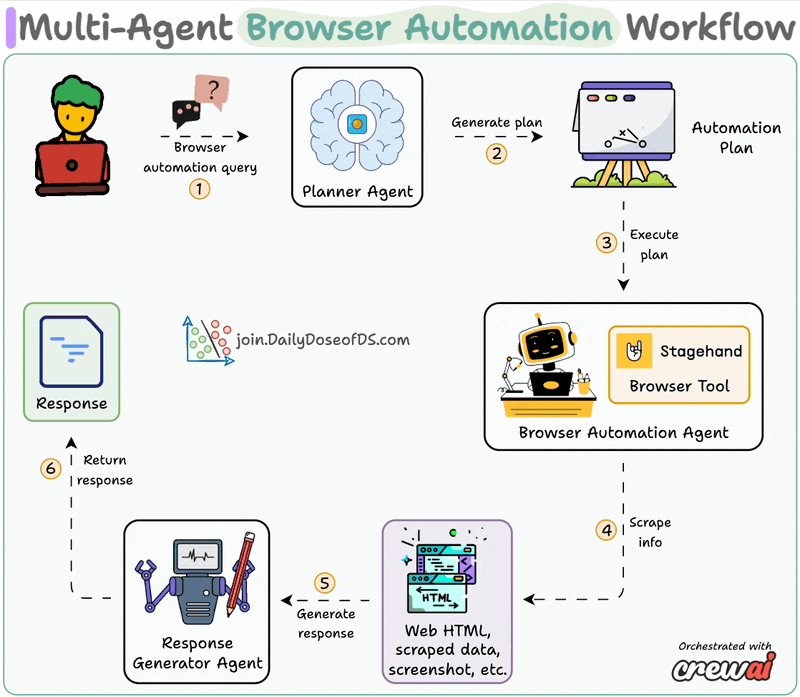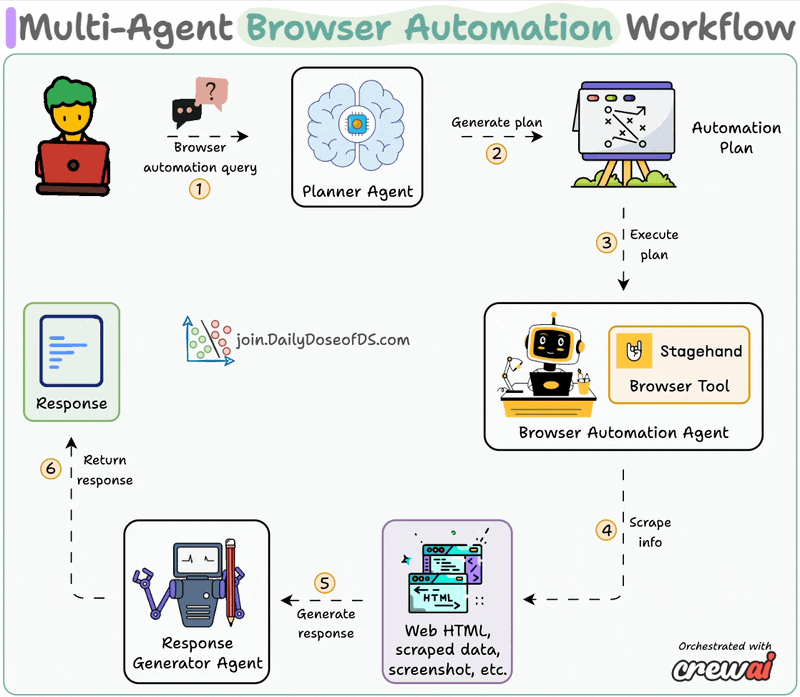

![[Hands-on] Make RAG systems 32x memory efficient!](/content/images/size/w800/2025/06/zep-claude-cursor.gif)