LLMs
Techniques to Extend Context Length of LLMs
Key techniques, explained in simple terms.

Avi Chawla
Key techniques, explained in simple terms.

TODAY'S ISSUE
Consider this:
We have been making great progress in extending the context window of LLMs.
Today, let's understand some techniques that help us unlock this.
What's the challenge?
In a traditional transformer, a model processing 4,096 tokens requires 64 times more computation (quadratic growth) than one handling 512 tokens due to the attention mechanism.
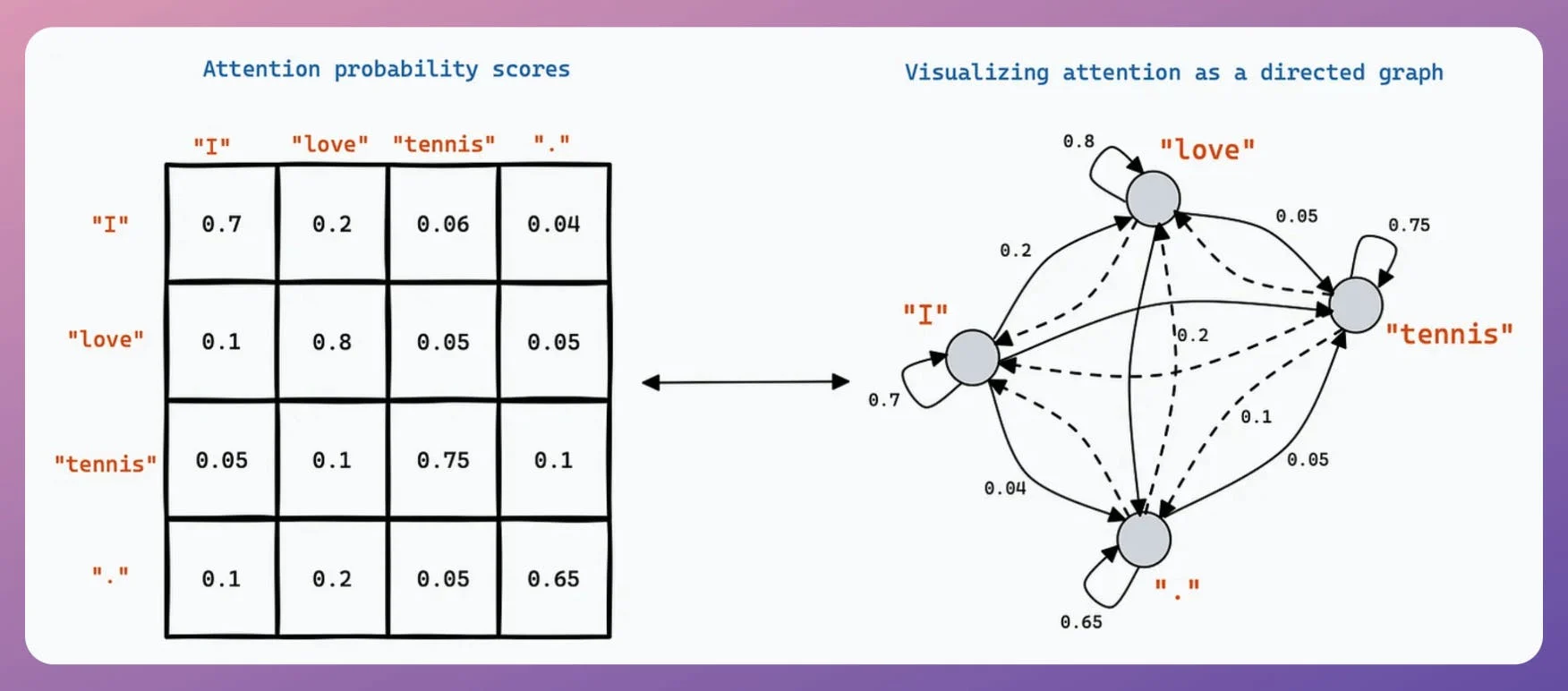
Thus, having a longer context window isn't just as easy as increasing the size of the matrices, if you will.
But at least we have narrowed down the bottleneck.
If we can optimize this quadratic complexity, we have optimized the network.
A quick note: This bottleneck was already known way back in 2017 when transformers were introduced. Since GPT-3, most LLMs have been utilizing non-quadratic approaches for attention computation.
1) Approximate attention using Sparse Attention
Instead of computing attention scores between all pairs of tokens, sparse attention limits that to a subset of tokens, which reduces the computations.
There are two common ways:
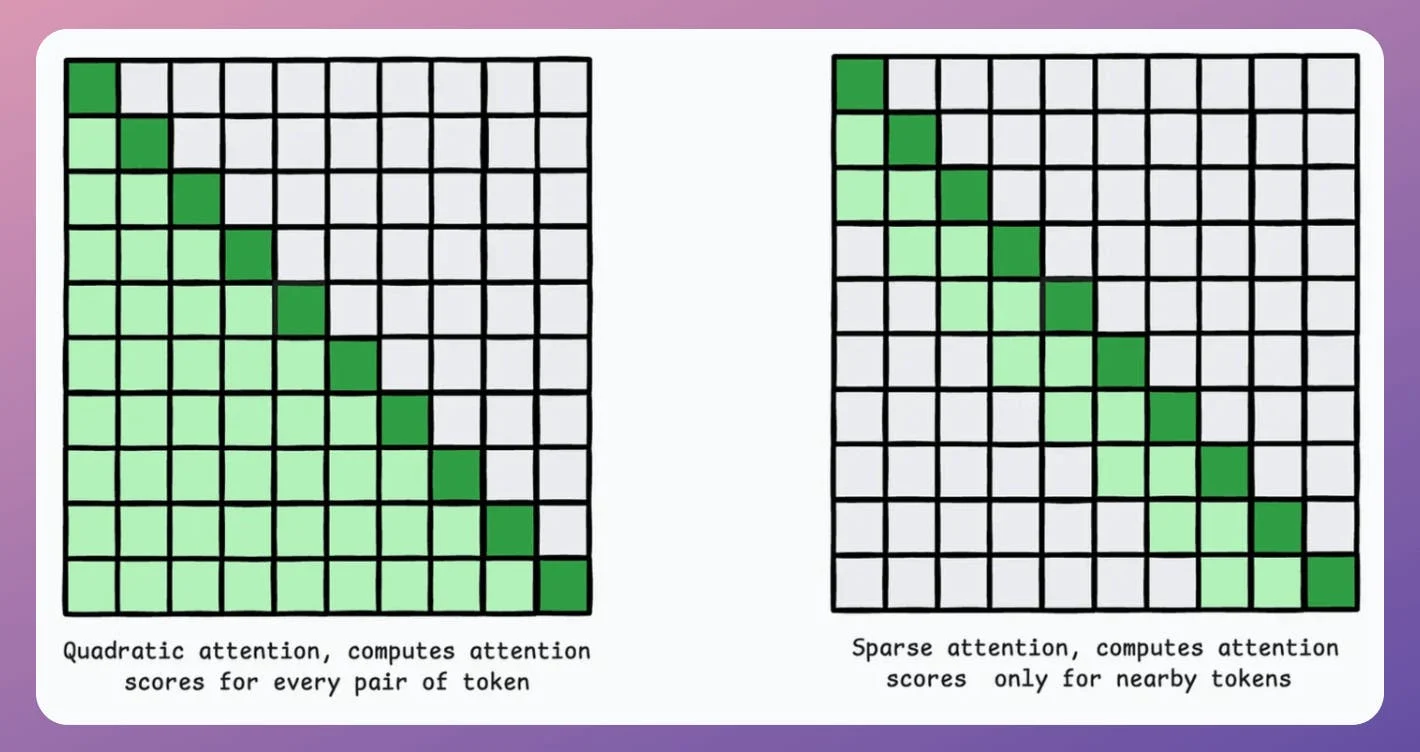
As you may have guessed, there's a trade-off between computational complexity and performance.
2) Flash Attention
This is a fast and memory-efficient method that retains the exactness of the traditional attention mechanism.
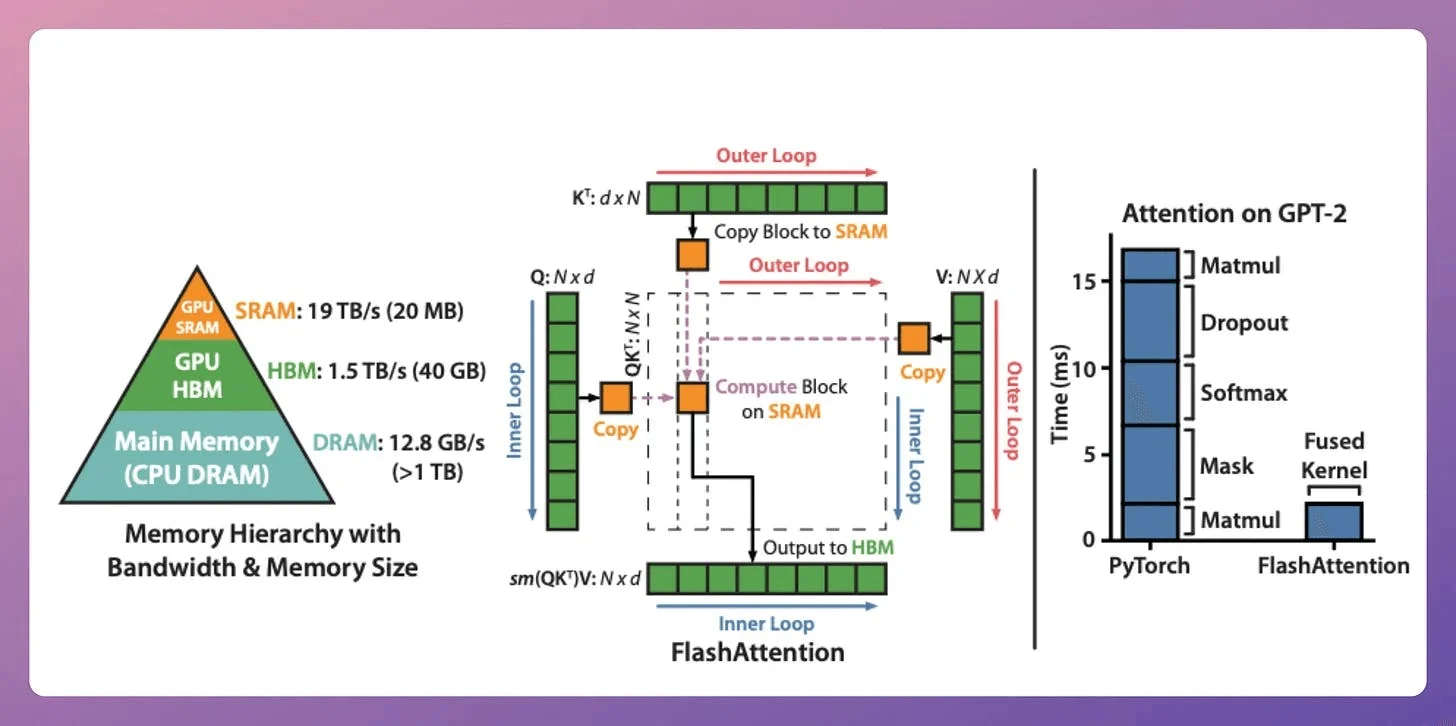
The whole idea revolves around optimizing the data movement within GPU memory. Here are some background details and how it works.
In a GPU:
Also:
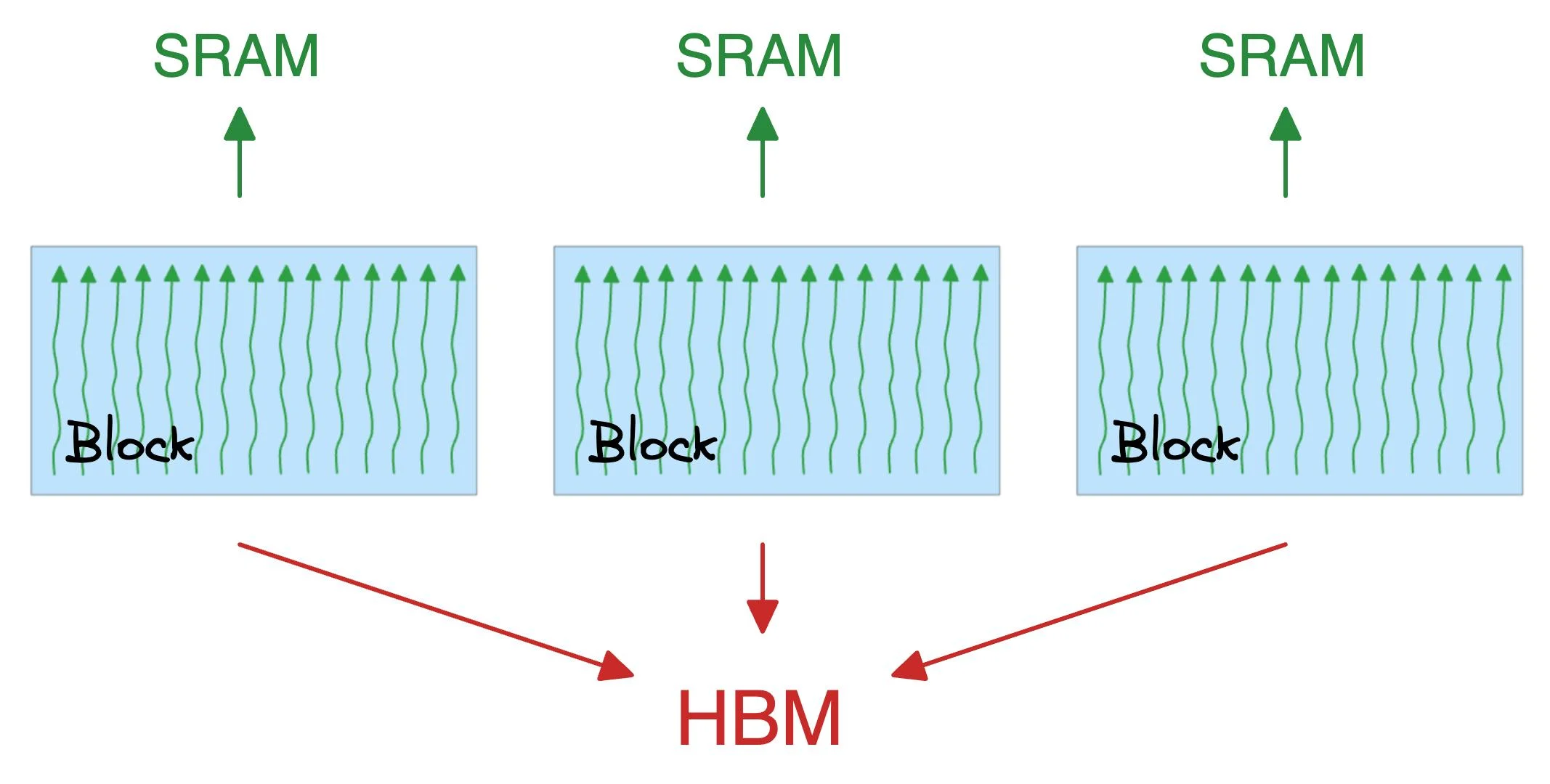
A note about SRAM and HBM:
The quadratic attention and typical optimizations involve plenty of movement of large matrices between SRAM and HBM:

Flash attention reduces the repeated movements by utilizing SRAM to cache the intermediate results.
This way, it reduces the redundant movements, and typically, this offers a speed up of ~8x over standard attention methods.
Also, it scales linearly with sequence length, which is great.
What else?
While reducing the computational complexity is crucial, this is not sufficient.
See, using the above optimization, we have made it practically feasible to pass longer contexts without drastically increasing the computation cost.
However, the model must know how to comprehend longer contexts and the relative position of tokens.
That is why the selection of positional embeddings is crucial.
Rotary positional embeddings (RoPE) usually work the best since they preserve both the relative position and the relation.
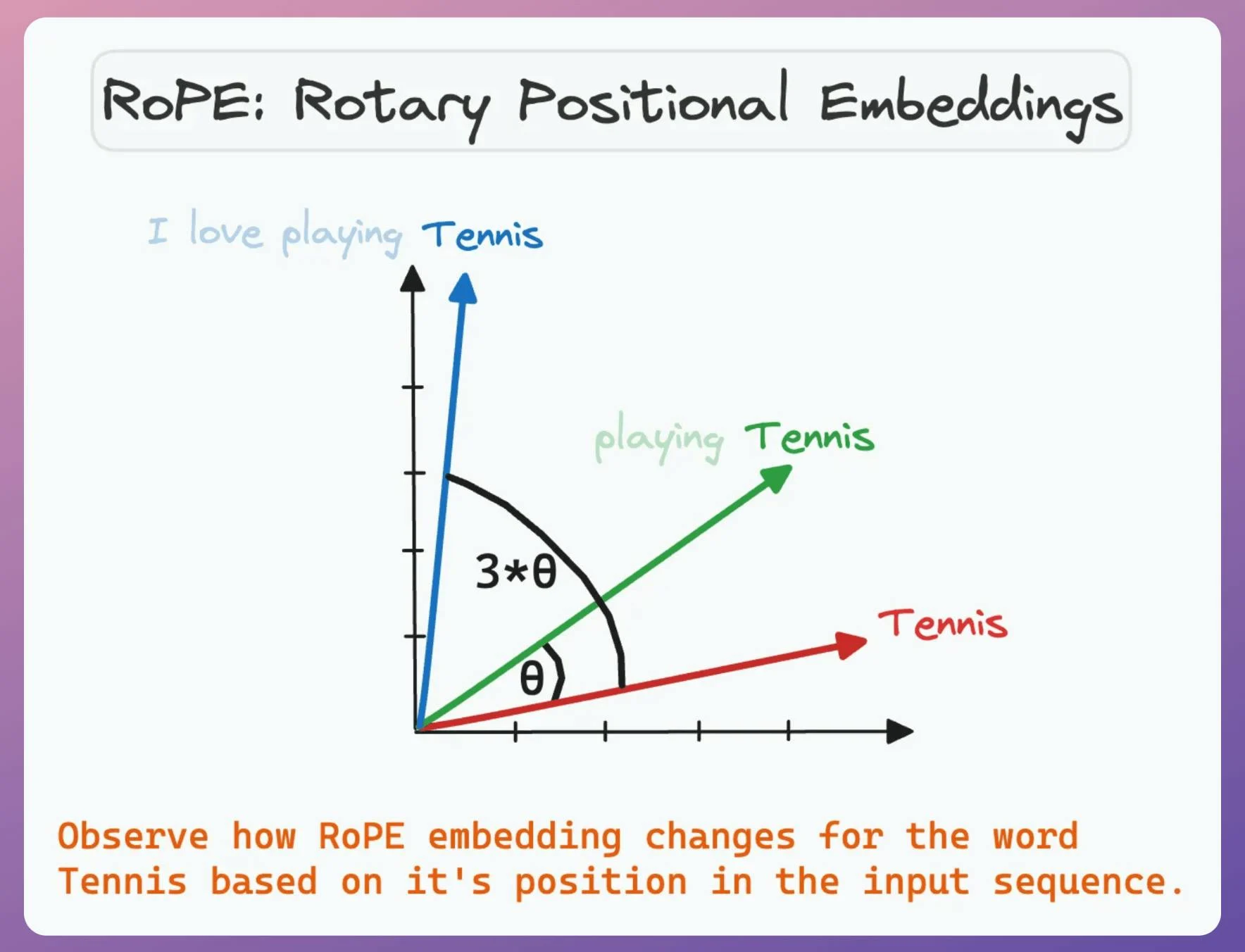
If you want to learn more about RoPE, let us know. We can cover it in another issue.
In the meantime, if you want to get into the internals of CUDA GPU programming and understand the internals of GPU, how it works, and learn how CUDA programs are built, we covered it here: Implementing (Massively) Parallelized CUDA Programs From Scratch Using CUDA Programming.
👉 Over to you: What are some other ways to extend the context length of LLMs?
There’s so much data on your mobile phone right now — images, text messages, etc.
And this is just about one user — you.
But applications can have millions of users. The amount of data we can train ML models on is unfathomable.
The problem?
This data is private.
So consolidating this data into a single place to train a model.
The solution?
Federated learning is a smart way to address this challenge.
The core idea is to ship models to devices, train the model on the device, and retrieve the updates:
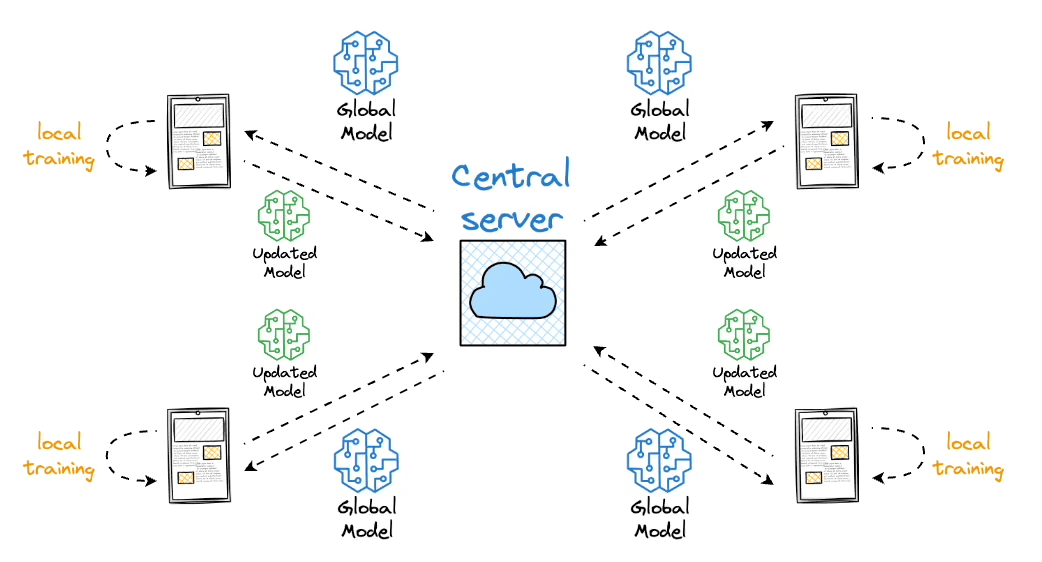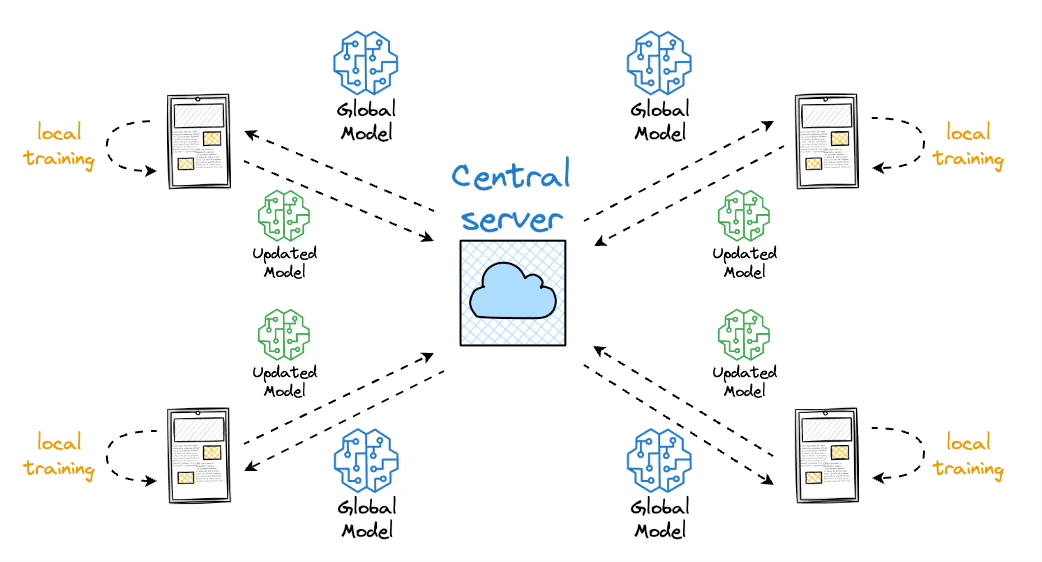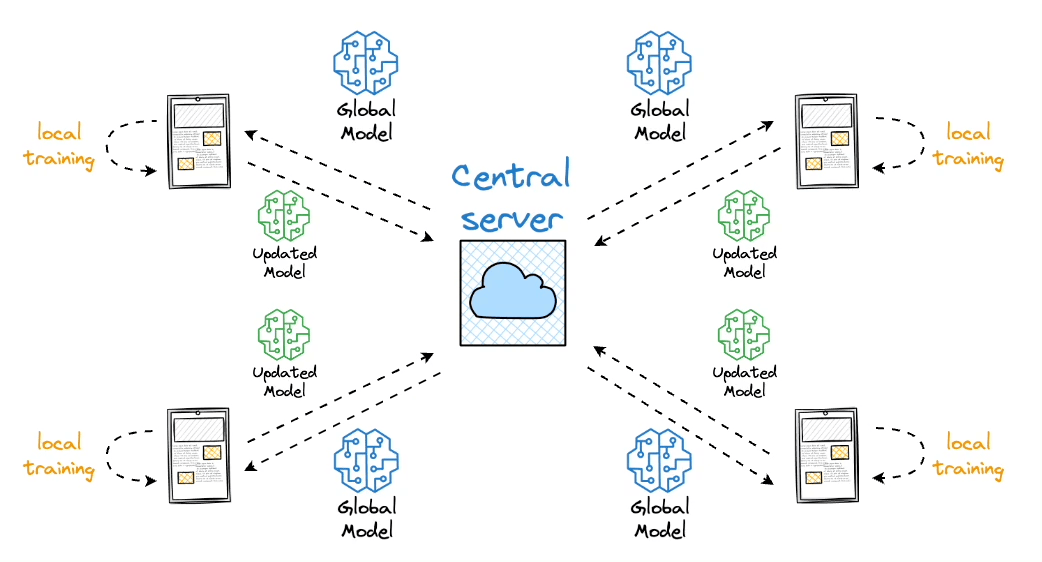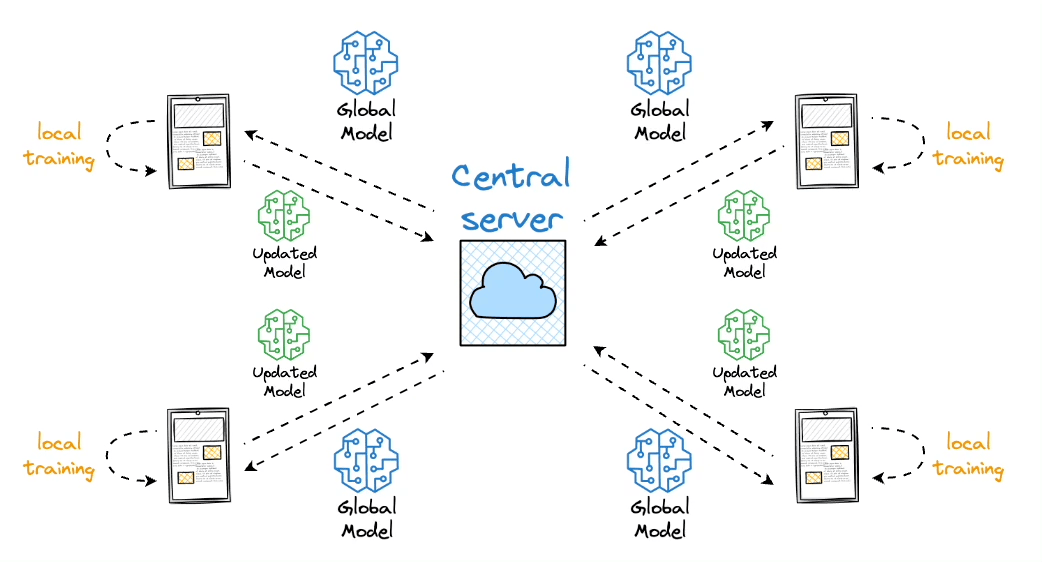
But this isn't as simple as it sounds.
1) Since the model is trained on the client side, how to reduce its size?
2) How do we aggregate different models received from the client side?
3) [IMPORTANT] Privacy-sensitive datasets are always biased with personal likings and beliefs. For instance, in an image-related task:
Learn how to build federated learning systems (beginner-friendly and with implementation) →
Despite rigorously testing an ML model locally (on validation and test sets), it could be a terrible idea to instantly replace the previous model with the new model.
A more reliable strategy is to test the model in production (yes, on real-world incoming data).

While this might sound risky, ML teams do it all the time, and it isn’t that complicated.
There are many ways to do this.