LLMs
From PyTorch to Lightning Fabric
Scale model training with 4 small changes.

Avi Chawla
Scale model training with 4 small changes.

TODAY'S ISSUE
Understand the concepts powering technology like ChatGPT in minutes a day with Brilliant.
Thousands of quick, interactive lessons in AI, programming, logic, data science, and more make it easy. Try it free for 30 days.
Thanks to Brilliant for sponsoring today’s issue.
PyTorch gives so much flexibility and control. But it leads to a ton of boilerplate code.
PyTorch Lightning, however:

But it isn’t as flexible as PyTorch to write manual training loops and stuff.
Lately, I have been experimenting with Lightning Fabric, which brings together:
Today’s issue covers the 4 small changes you can make to your existing PyTorch code to easily scale it to the largest billion-parameter models/LLMs.
This is summarized in a single frame below:
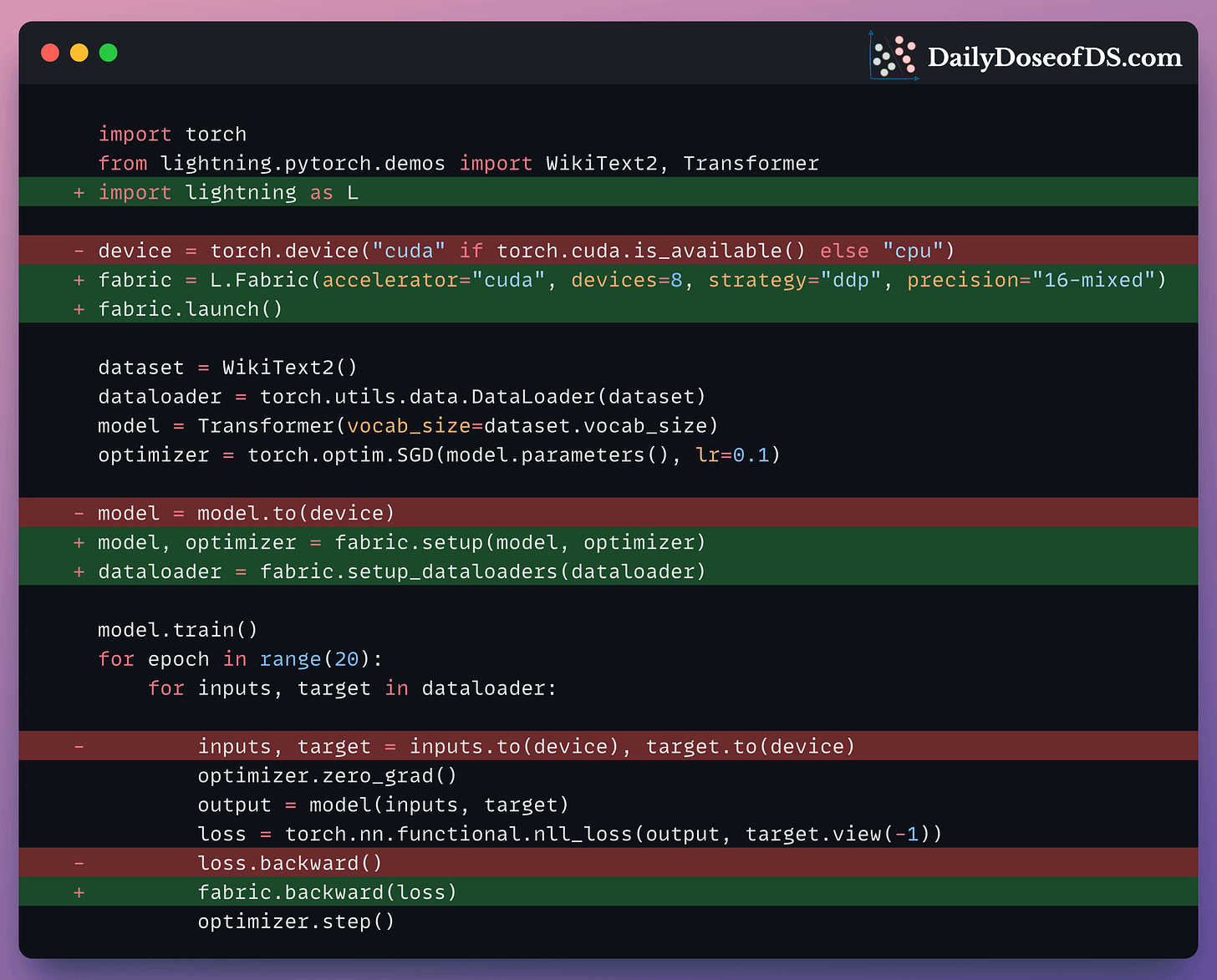
Let’s distill it!
Begin by importing the lightning module (install using pip install lightning), creating a Fabric object and launching it.

In my opinion, this Fabric object is the most powerful aspect here since you can specify the training configuration and settings directly with parameters.
For instance, with a single line of code, you specify the number of devices and the parallelism strategy to use:

Moreover, it lets you take full advantage of the hardware on your system. It supports CPU, TPU, and GPU (NVIDIA, AMD, Apple Silicon).

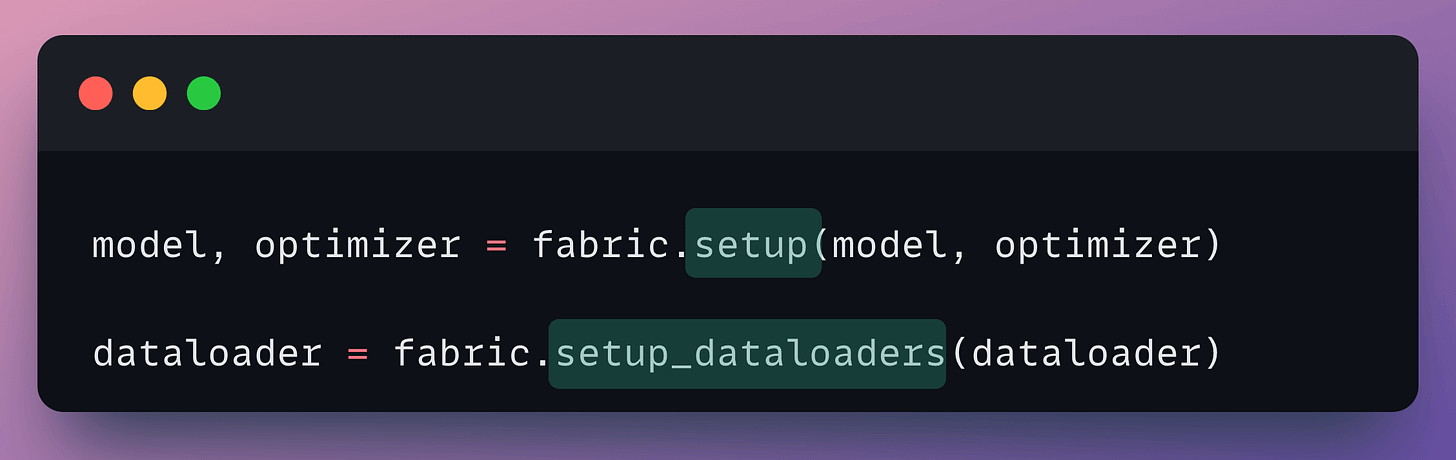
Moving on, configure the model, the optimizer, and the dataloader as follows:
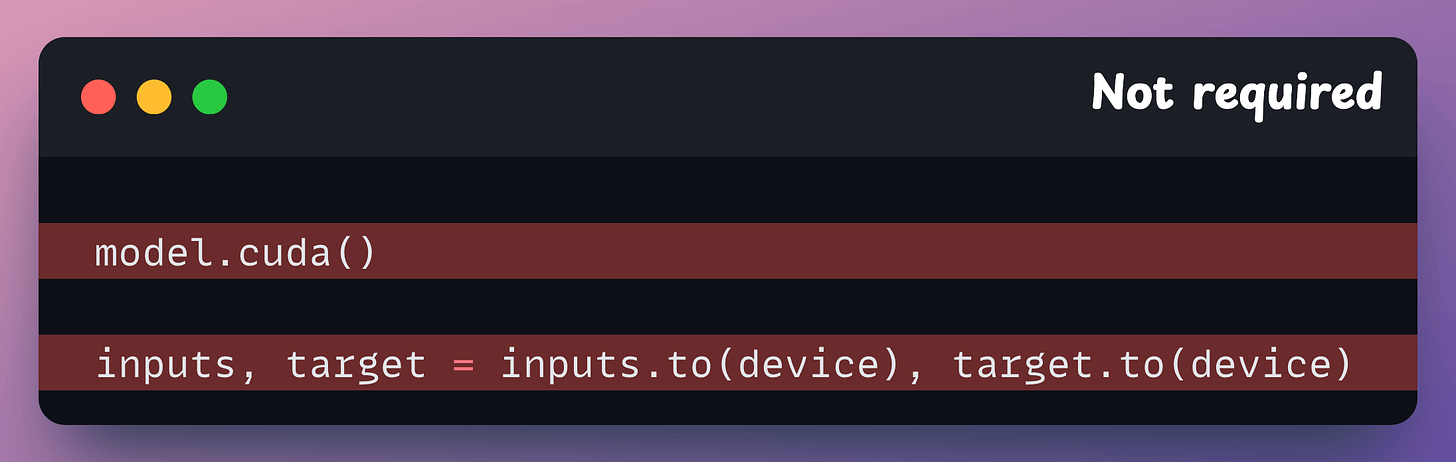
Next, remove all .to() and .cuda() calls since Fabric takes care of it automatically:
Finally, replace the loss.backward() call by fabric.backward(loss) call.

Done!
Now, you can train the model as you usually would, but with PyTorch Fabric, you have reduced the model scaling efforts.
That was simple, wasn’t it?
Here’s the documentation if you want to dive into more details about the usage: Lightning Fabric.
👉 Over to you: What are some issues with PyTorch?
If you look at job descriptions for Applied ML or ML engineer roles on LinkedIn, most of them demand skills like the ability to train models on large datasets:

Of course, this is not something new or emerging.
But the reason they explicitly mention “large datasets” is quite simple to understand.
Businesses have more data than ever before.
Traditional single-node model training just doesn’t work because one cannot wait months to train a model.
Distributed (or multi-GPU) training is one of the most essential ways to address this.
Here, we covered the core technicalities behind multi-GPU training, how it works under the hood, and implementation details.
We also look at the key considerations for multi-GPU (or distributed) training, which, if not addressed appropriately, may lead to suboptimal performance or slow training.
The list could go on since almost every major tech company I know employs graph ML in some capacity.
Becoming proficient in graph ML now seems to be far more critical than traditional deep learning to differentiate your profile and aim for these positions.
A significant proportion of our real-world data often exists (or can be represented) as graphs:
The field of graph neural networks (GNNs) intends to fill this gap by extending deep learning techniques to graph data.
Learn sophisticated graph architectures and how to train them on graph data in this crash course →