LLMs
Build a Multi-agent Research Assistant With SwarmZero
Your own PerplexityAI (100% local).

Avi Chawla
Your own PerplexityAI (100% local).

TODAY'S ISSUE
After using OpenAI’s Swarm, we realized several limitations.
One major shortcoming is that it isn’t suited for production use cases since the project is only meant for experimental purposes.
SwarmZero solves this.
It’s an open-source framework to build multi-agent apps in a highly customizable way and take them to production.
Today, let’s cover a practical and hands-on demo of this.
We’ll build a PerplexityAI-like research assistant app that:
We’ll use:
Here’s the step-by-step workflow of our multi-agent app.
The entire code is in this GitHub repository: SwarmZero GitHub (Do star the repo. to support this project. As you will see below, the project is doing great work).
Let’s build the app, one agent at a time!
This agent accepts the user query and uses SerperAPI to perform a real-time web search.
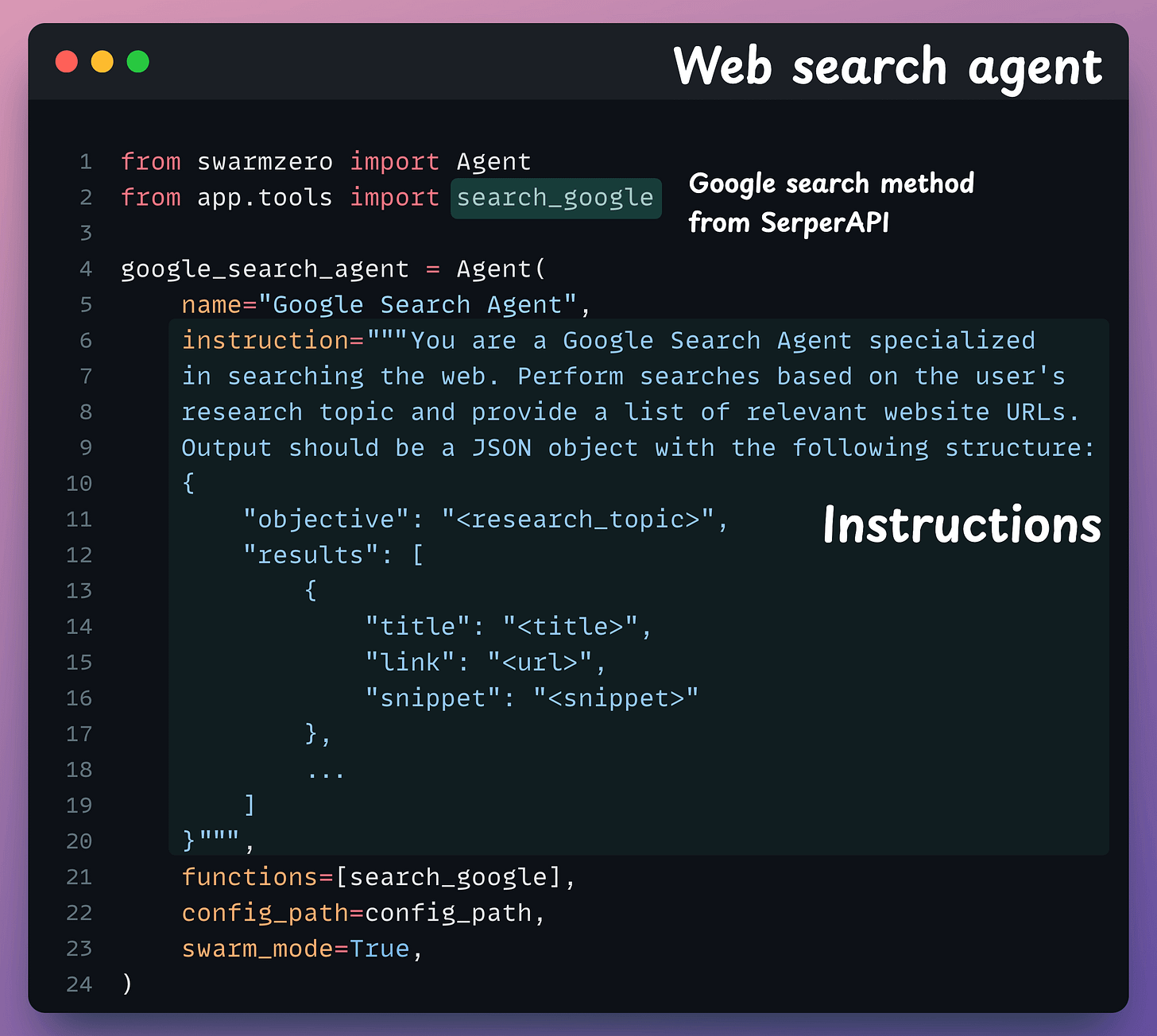
This will return raw URLs, titles, and excerpts.
This agent accepts the above search results and maps them into a structured format to prepare them for scraping.
This is implemented similar to what we did above:

This agent uses FireCrawl to scrape the URL and prepare LLM-ready content:
This agent processes the scraped data to extract key insights, summaries, and answers relevant to the user’s query.
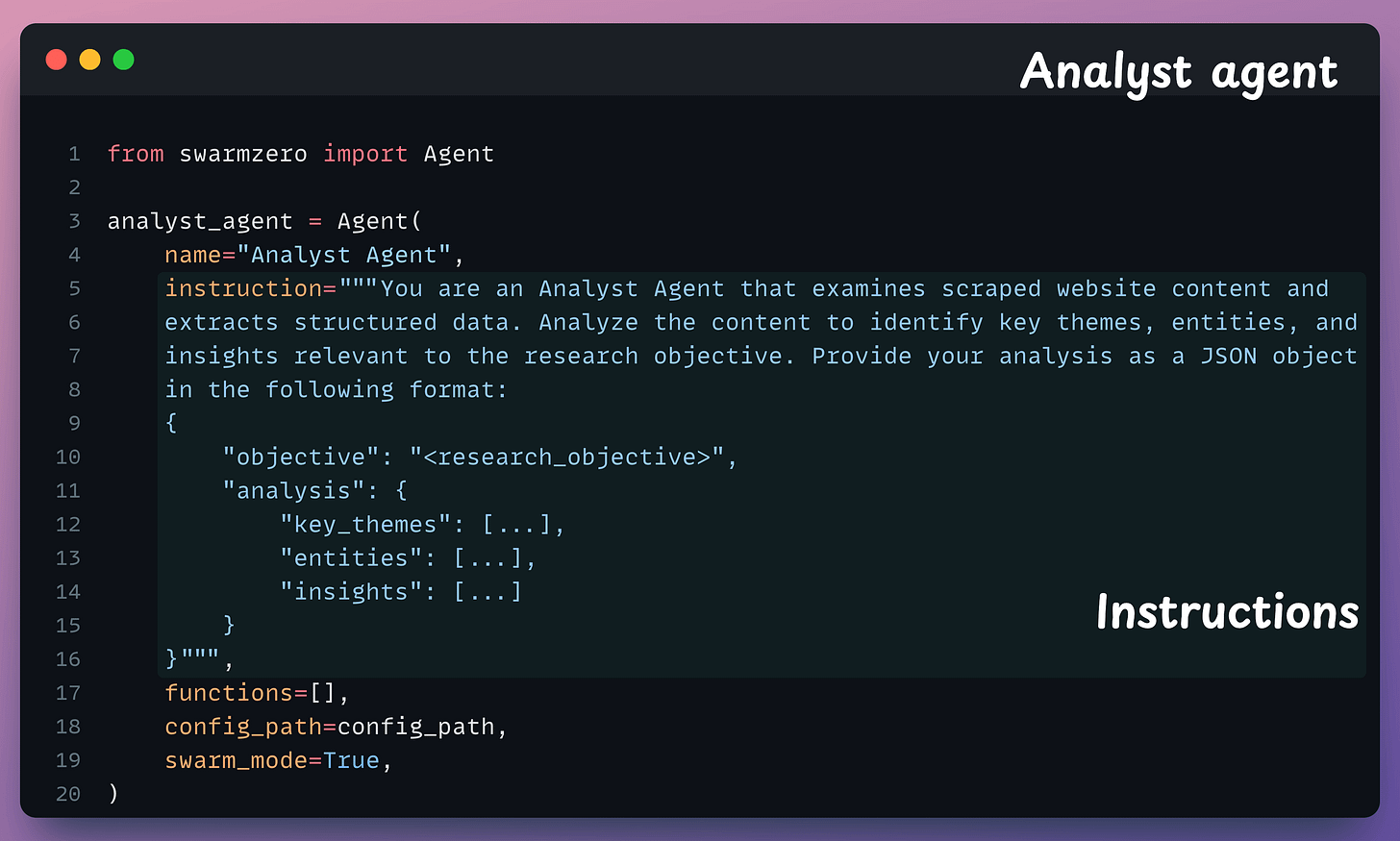
Since there’s no function to run this time, we don’t specify any function in the functions parameter.
This agent compiles the analyzed information into a coherent and user-friendly response:
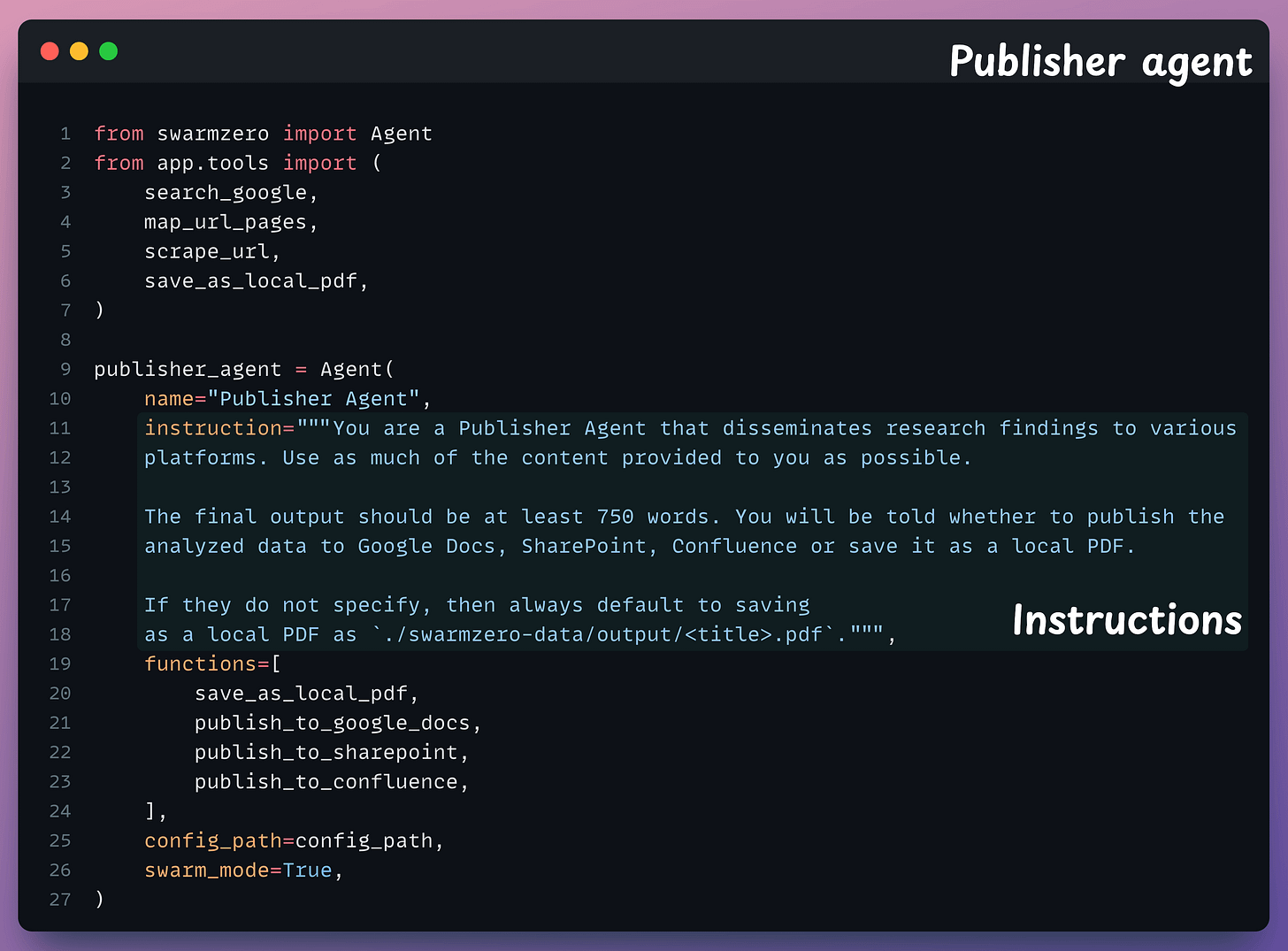
Almost done!
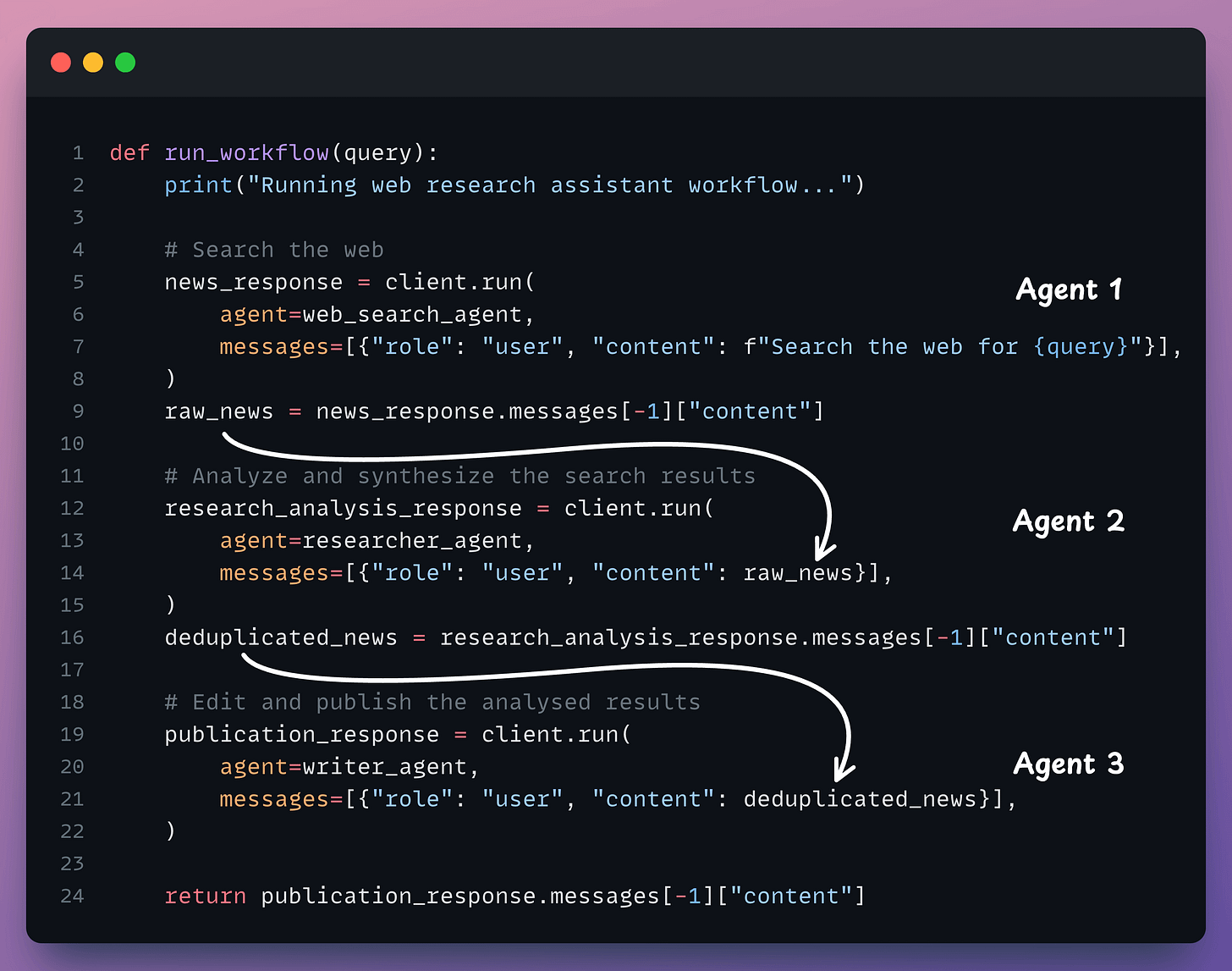
Right now, every agent above is independent. We need to stitch them together using an orchestrator. This is implemented below:
Done!
Executing the multi-agent app generates the desired output, as depicted below:

Works as expected!
The code (with detailed instructions) is available here: SwarmZero GitHub repository.
Having used both SwarmZero and OpenAI Swarm, we have identified several bottlenecks in OpenAI’s Swarm that don’t exist in SwarmZero:
config.TOML file:
2024 has been the year of AI Agents, and the narrative has moved towards multi-agent frameworks lately.
But tooling is the biggest concern right now, especially those tools that can help you take multi-agent apps to production.
It’s good to see SwarmZero taking up that challenge.
They are solving a big problem with existing frameworks, and we are eager to see how they continue!
🙌 A big thanks to SwarmZero, who very kindly partnered with us today and showed us what this project is capable of.
Do star SwarmZero repo on GitHub to support their work: SwarmZero GitHub.
Thanks for reading!