Foundations of Reinforcement Learning
RL Part 1: Agents, environments, rewards, and why RL is different from supervised learning.
Introduction
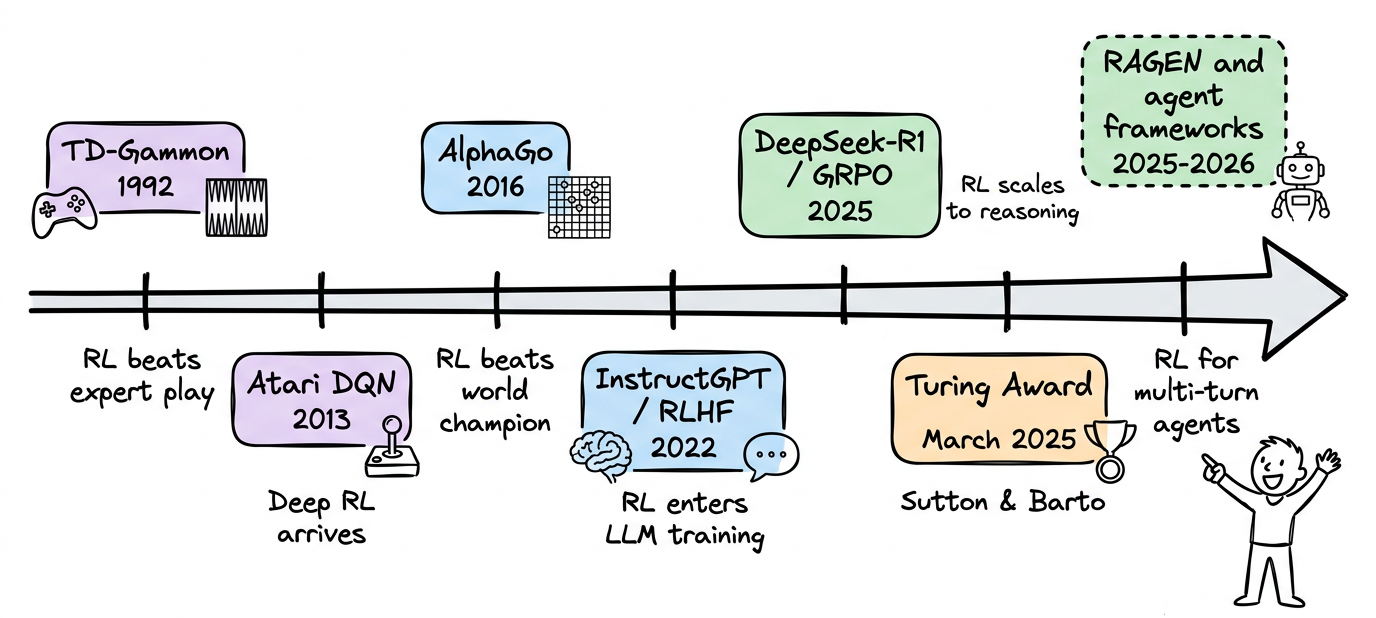
On 5 March 2025, the Association for Computing Machinery announced that Andrew G. Barto and Richard S. Sutton had won the 2024 ACM A.M. Turing Award, the computing world's equivalent of the Nobel Prize.
The citation was specific: "for developing the conceptual and algorithmic foundations of reinforcement learning." Their 1998 textbook, "Reinforcement Learning: An Introduction", has been cited over 75,000 times and is still the standard reference for the field.
But Reinforcement learning (RL) sat quietly for decades, producing impressive but niche results such as TD-Gammon in the 1990s and AlphaGo in 2016.
Then something shifted, almost every LLM released in the past two years (e.g. DeepSeek-R1, GPT-5, etc.) was trained using some form of reinforcement learning in its post-training pipeline.
RL, today, is a core part of how the most capable AI systems are built.
We’re starting this RL series as a structured learning path, designed to build a thorough understanding while developing a strong conceptual intuition of the key topics and ideas.
Just as the MLOps and LLMOps crash course, each chapter will clearly explain necessary concepts, provide examples, diagrams, and implementations.
In this chapter, we'll understand what makes RL different from supervised and unsupervised learning, how to describe an agent interacting with an environment, why exploration is fundamentally unavoidable, and how all of this plays out in the simplest possible RL setting: the multi-armed bandit.
As always, every notion will be explained through clear examples and walkthroughs to develop a solid understanding.
Let's begin!
What makes RL different
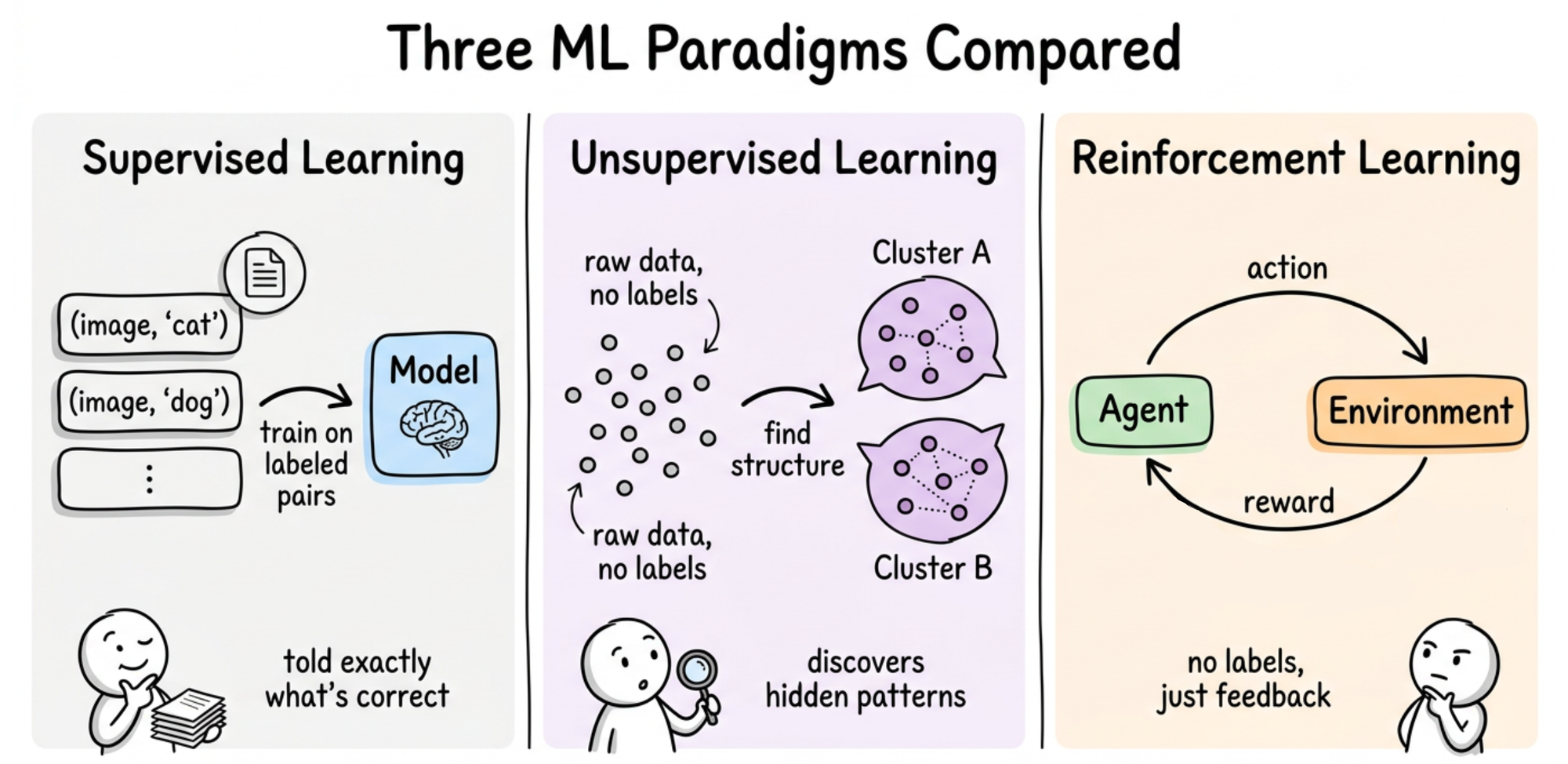
Most machine learning that we have seen so far falls into two buckets:
- Supervised learning gives the model input-output pairs and asks it to learn the mapping.
- Unsupervised learning gives the model only inputs and asks it to find structure, like clusters in a dataset or a lower-dimensional representation.
Reinforcement learning is a third kind of machine learning, and it is a genuinely different setup.
There are no labeled pairs. There is no hidden structure to discover. Instead, there is an agent that takes actions in an environment, and after each action, the environment returns something called a reward.makeThe agent's goal is to pick actions so that the total reward it collects over time is as large as possible.
Properties that set RL apart
There are four key properties that make RL distinctive:
- The first is that feedback is evaluative, not instructive. A supervised loss function tells the model exactly what the correct output was. An RL reward just tells the agent how good its action was, not what the best action would have been. The agent has to figure out "best" on its own.
- The second is that the data distribution depends on the agent. In supervised learning, the training set is fixed. In RL, the states the agent ends up in are a consequence of its own choices. A bad early policy can steer the agent into regions of the environment it would never have visited with a good policy. This means the data is not independent and identically distributed (i.i.d.), and thus most guarantees from supervised learning do not carry over directly.
- The third is delayed consequences. An action taken now might only pay off many steps later.
- The fourth is the exploration-exploitation tradeoff. The agent has to use what it knows to pick good actions. But it also has to try actions it is uncertain about, in case they turn out to be even better. This tension does not exist in supervised learning, where the labels are given.
The agent-environment loop
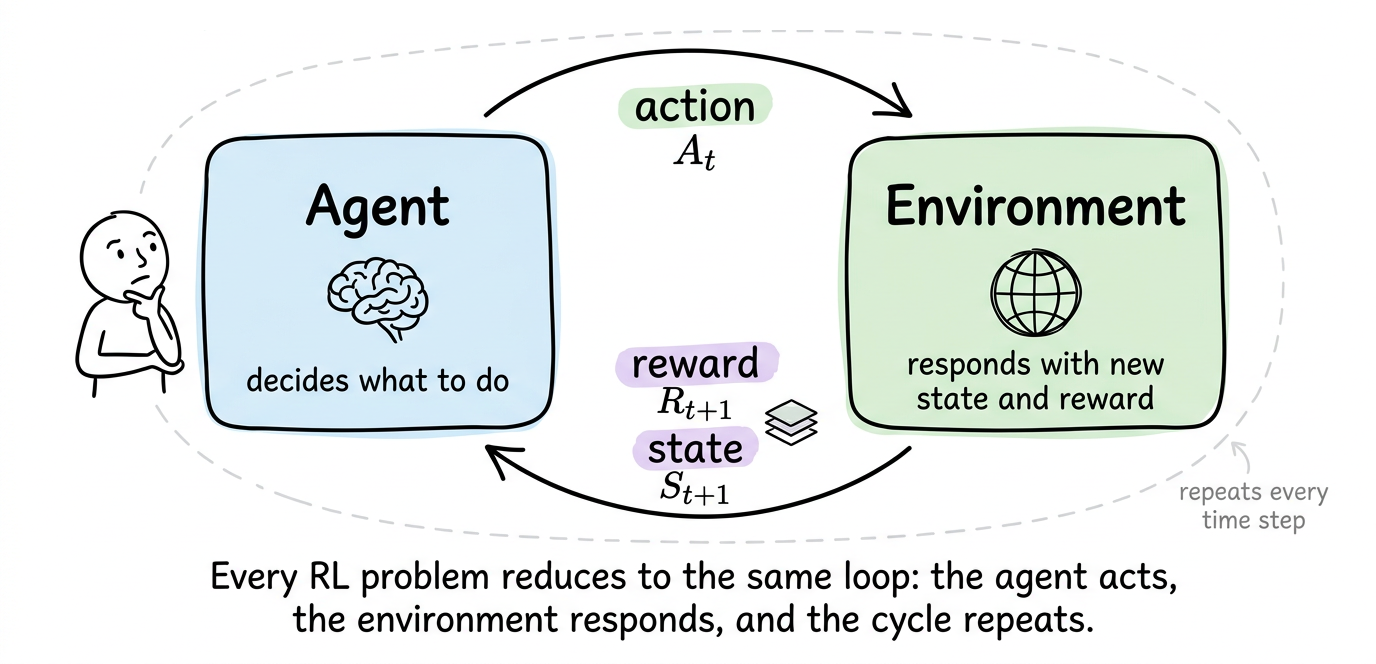
The canonical RL diagram shows two boxes, one labeled "agent" and one labeled "environment", with arrows between them. Every RL problem that we will study in this series fits inside this picture.
The interaction
Time proceeds in discrete steps $t=0,1,2,…$. At each step, three things happen in order:
- The agent observes the current state of the environment, written $S_t$.
- The agent picks an action $A_t$ based on what it sees.
- The environment then does two things. It transitions to a new state $S_{t+1}$, and it emits a reward $R_{t+1}$, a scalar number that evaluates the previous action. The next time step begins and the loop continues.
Stringing this together gives a trajectory, also called an episode when it has a clear end:
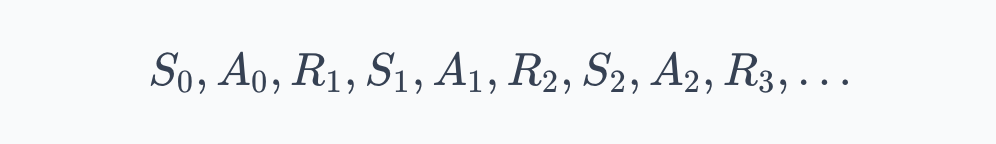
Reading left to right, this is the entire history of the agent's interaction. Each $(S_t, A_t, R_{t+1}, S_{t+1})$ quartet is one transition, and much of RL is about learning from such transitions.
Where does the agent end and the environment begin?
This question might sound philosophical but it has a concrete answer that Sutton and Barto crystallized. The boundary between agent and environment is drawn wherever the agent's direct control ends.
Anything the agent cannot change arbitrarily and instantly is part of the environment, even if it is physically inside the agent's body.
The tradeoff here is practical:
- Drawing the boundary tightly (almost everything is environment) keeps the action space small and clean but leaves the agent with less control.
- Drawing it loosely (a lot of internal state is "agent") gives the agent more levers but makes learning harder because the action space explodes.
With the interaction picture in place, we now need to understand how does the agent figure out the right policy when it starts out knowing nothing?
Exploration and exploitation
Suppose the agent has been interacting with an environment for a while and has some sense of which actions tend to produce good rewards. At each step, it faces a choice:
Should it take the action that looks best based on what it has seen so far?
Or
Should it try something different?
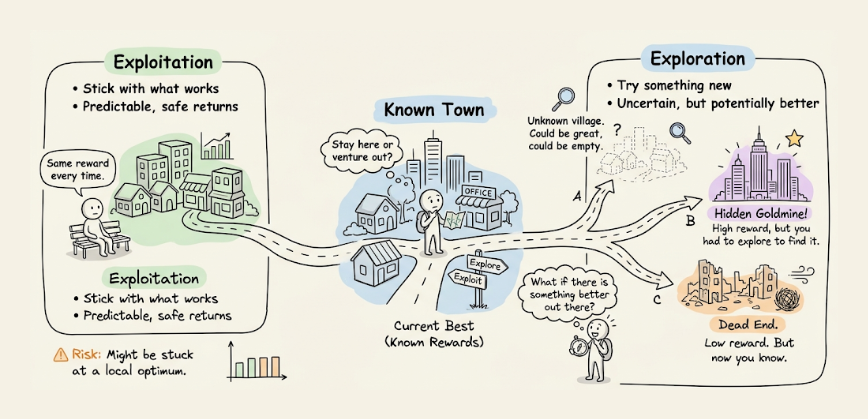
This is the exploration-exploitation tradeoff, and it is the defining tension of RL.
Exploitation means using current knowledge to pick the action that currently looks best. This is what maximizes immediate expected reward given what the agent knows.
Exploration means deliberately picking a different action to gather more information about it. This does not maximize immediate expected reward, but it can pay off later if the action turns out to be better than expected.
Pure exploitation fails. If the agent always picks the action that looks best after only a few tries, it will often lock in on a suboptimal choice it happened to sample well early on.
Pure exploration also fails. If the agent never uses what it has learned, it collects endless data but never turns it into reward.
One way to picture this is that for each action, the agent holds a belief about its reward (not a single number, but a distribution reflecting how sure it is).
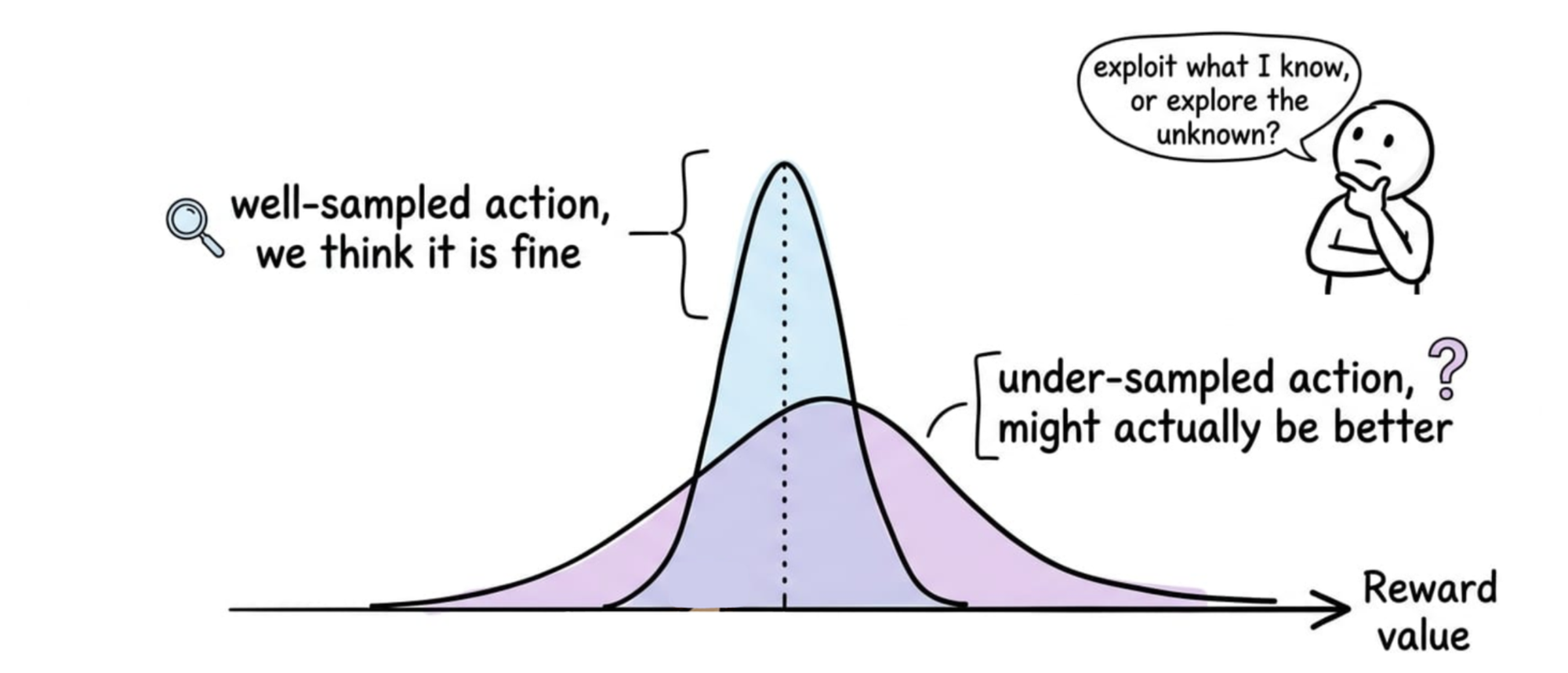
- A well-sampled action has a narrow belief; the agent is confident about roughly where its reward lies.
- An under-sampled action has a wide belief; its true value could plausibly be much higher or much lower than the current estimate. Exploration is worthwhile precisely because of that upper tail.
This tradeoff shows up in every RL problem. It is cleanest in a setting where there are no states to worry about, just actions and rewards. That setting is the multi-armed bandit, and studying it carefully is how we will build intuition for the rest of the series.