LLMs
Generate Synthetic Datasets with Llama3
...for fine-tuning other LLMs.

Avi Chawla
...for fine-tuning other LLMs.

TODAY'S ISSUE
The LLM that emerges from the pre-training phase isn’t entirely useful to engage with. For instance, here’s how a pre-trained (not fine-tuned yet) model typically behaves when prompted:

It’s clear that the model simply continues the sentence as if it is one long text in a book or an article.
Generating synthetic data through existing LLMs and utilizing that for fine-tuning can improve this.
In this case, the synthetic data will have fabricated examples of human-AI interactions—an instruction or query paired with an appropriate AI response:

Lately, we’ve been playing around with Distilabel, an open-source framework that facilitates generating domain-specific synthetic text data using Llama-3.
This is great for anyone working on fine-tuning LLMs or building small language models (SLMs).
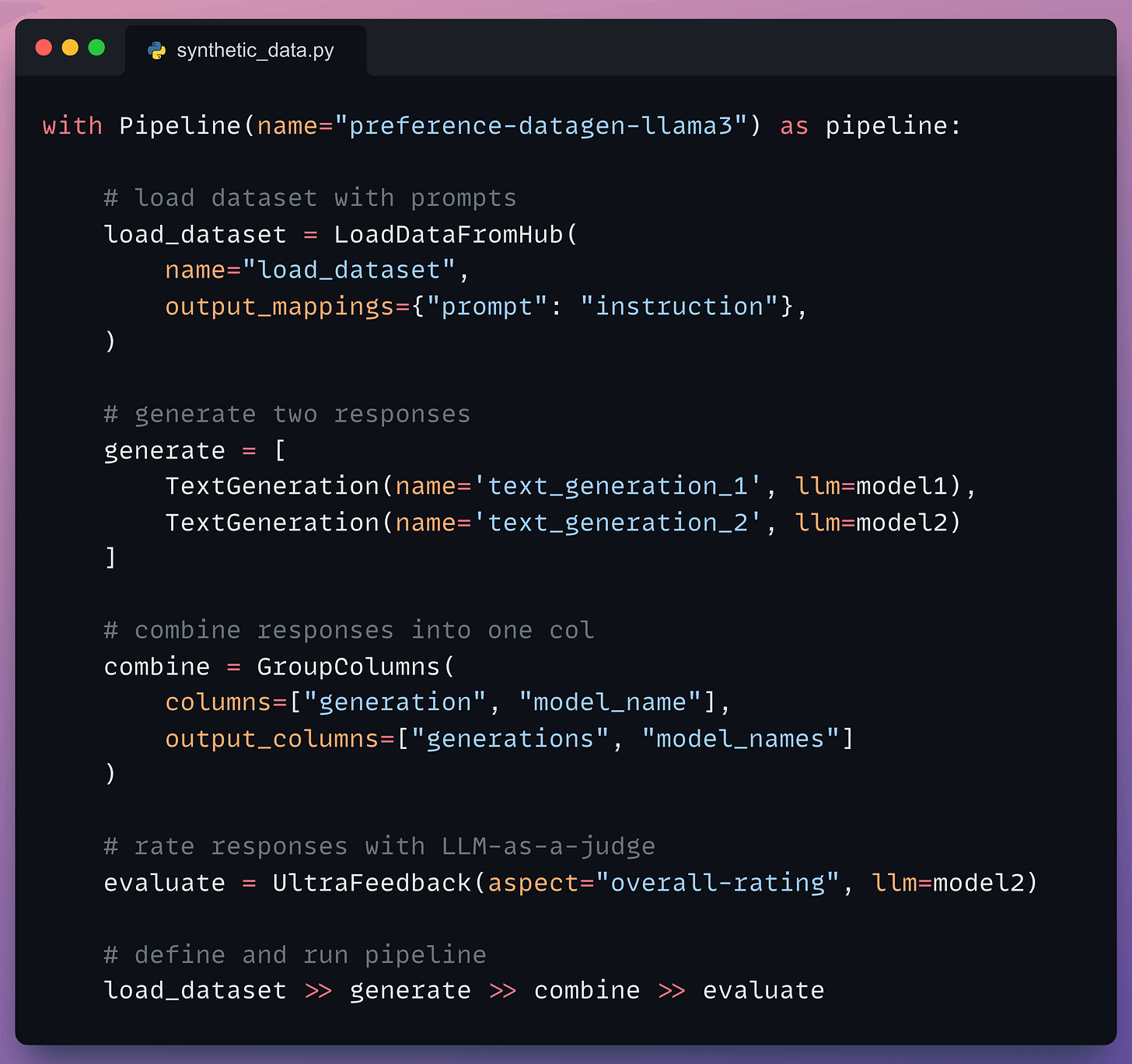
The underlying process is simple:
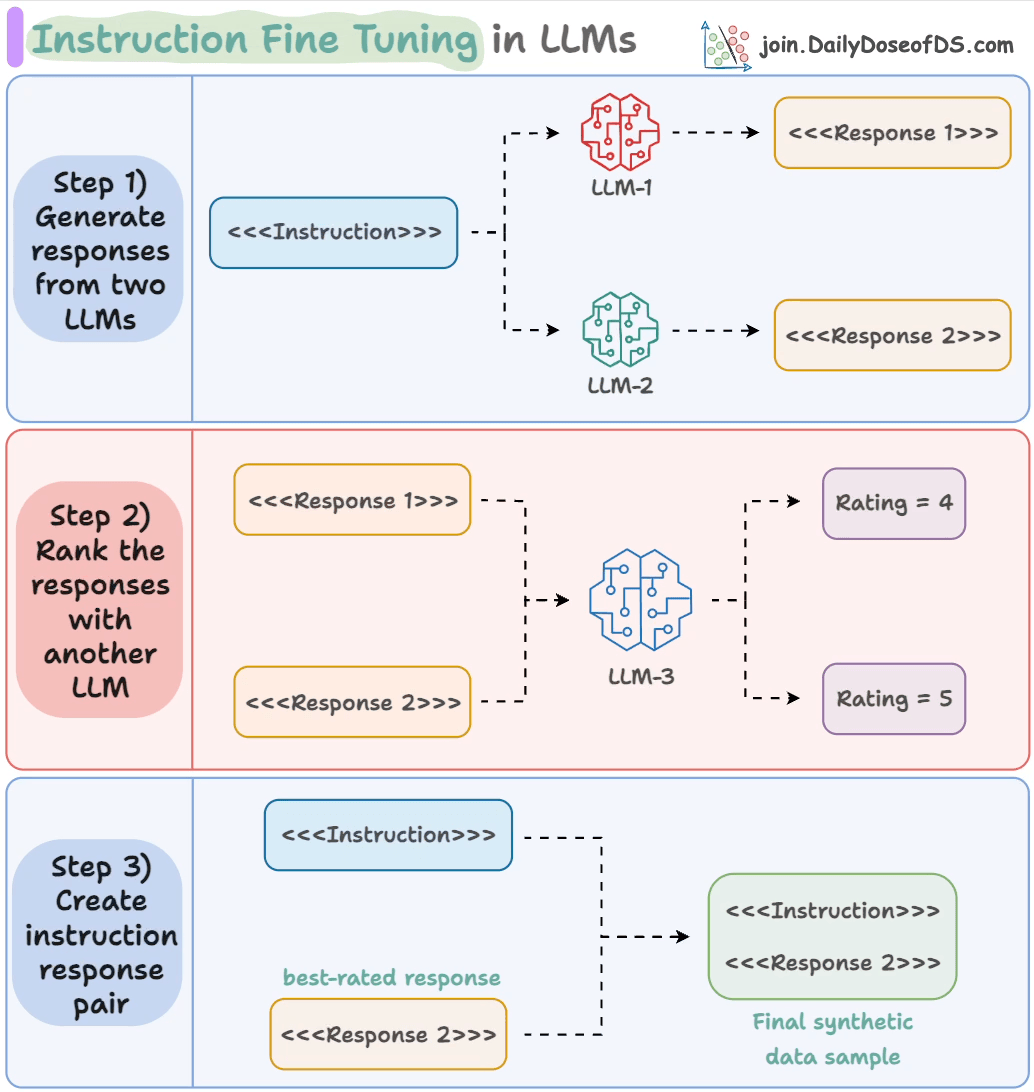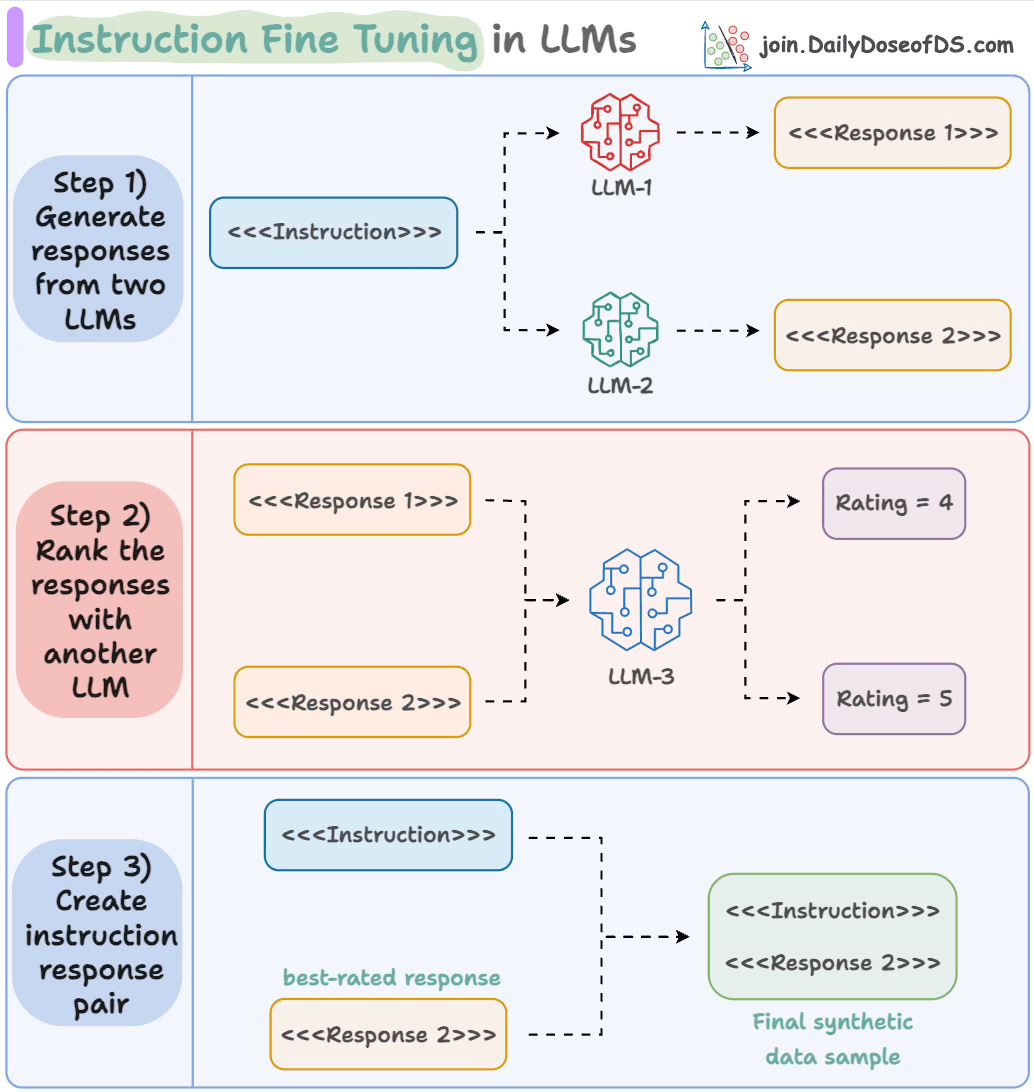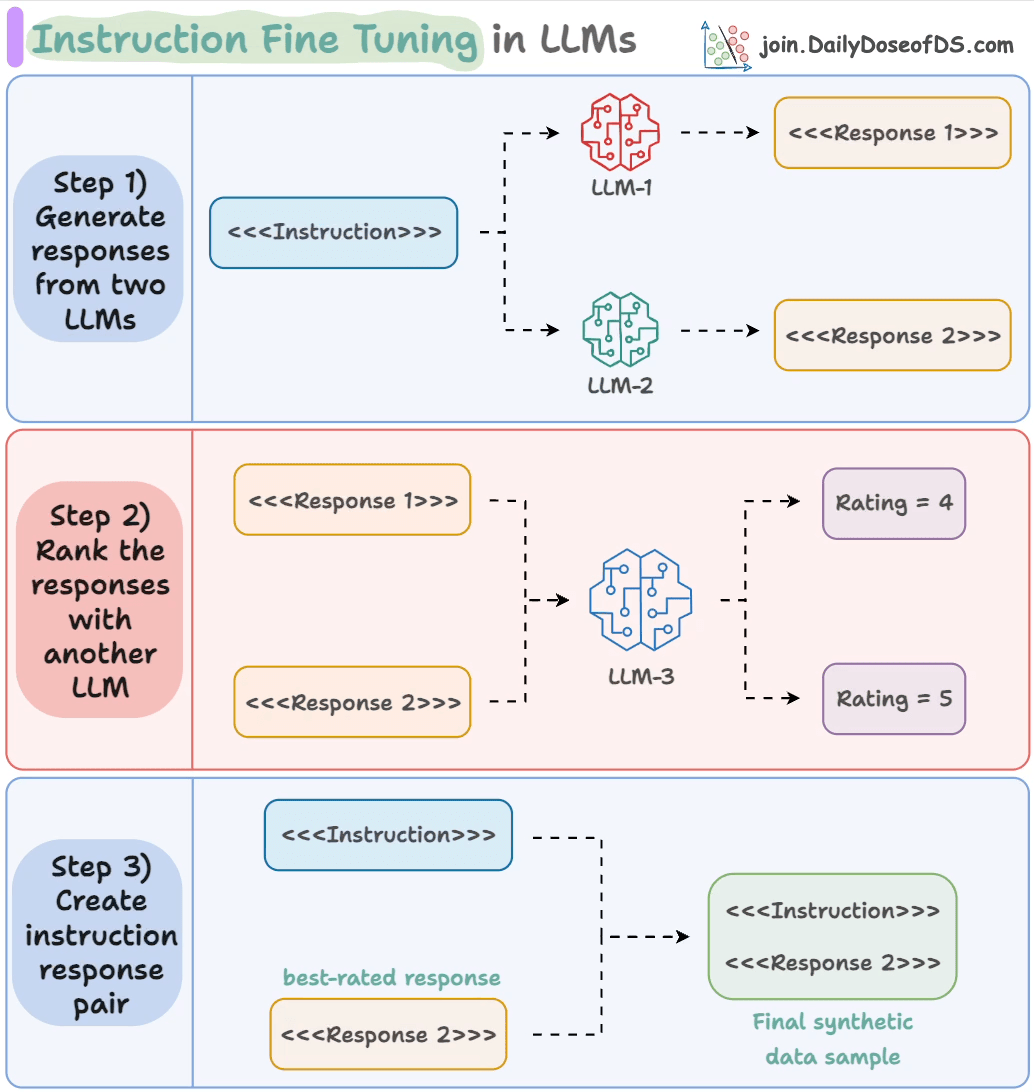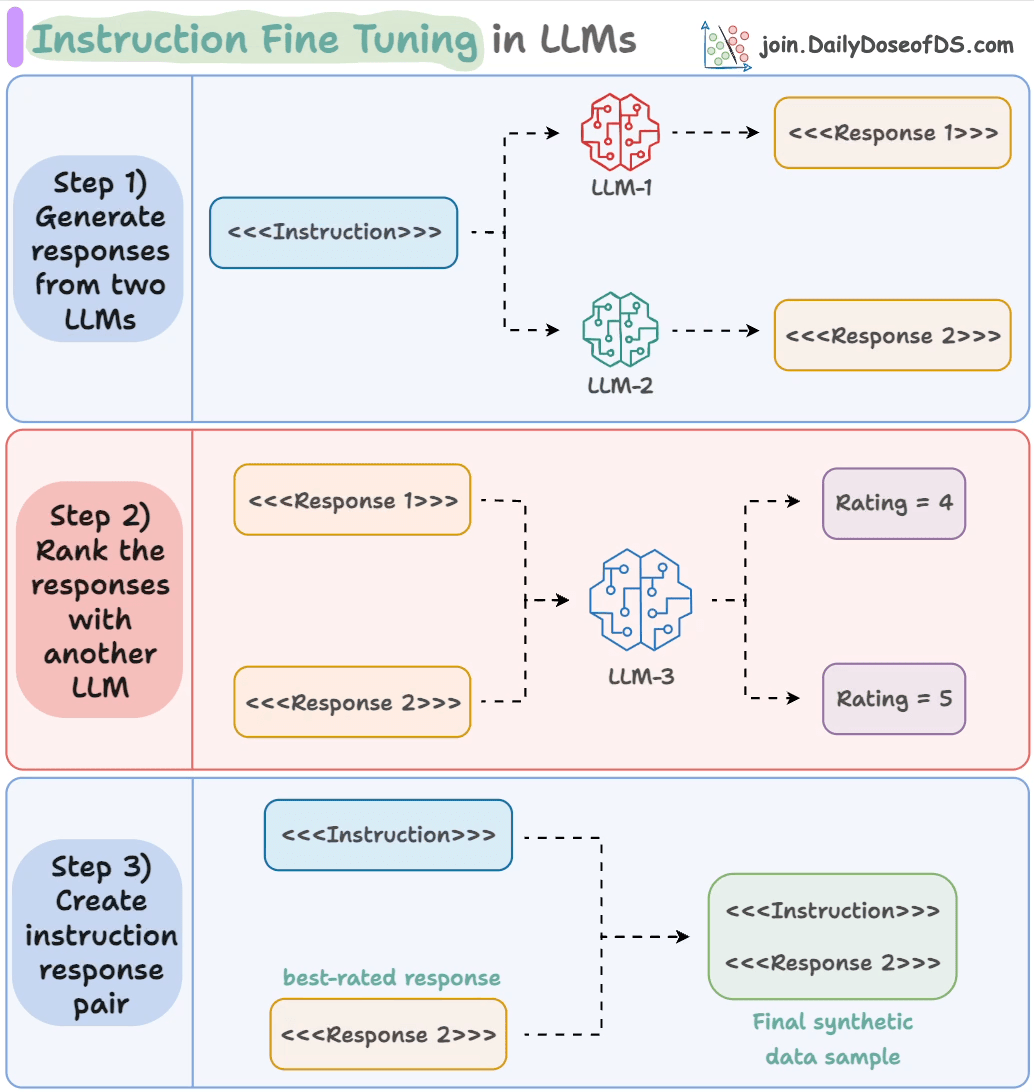
- Input an instruction.
- Two LLMs generate responses.
- A judge LLM rates the responses.
- The best response is paired with the instruction.
And you get the synthetic dataset!
A sample is shown below:

On a side note, this is quite similar to how we learned to evaluate our RAG pipelines in Part 2 of our RAG crash course.
Let’s look at the implementation below with the Distilabel library.
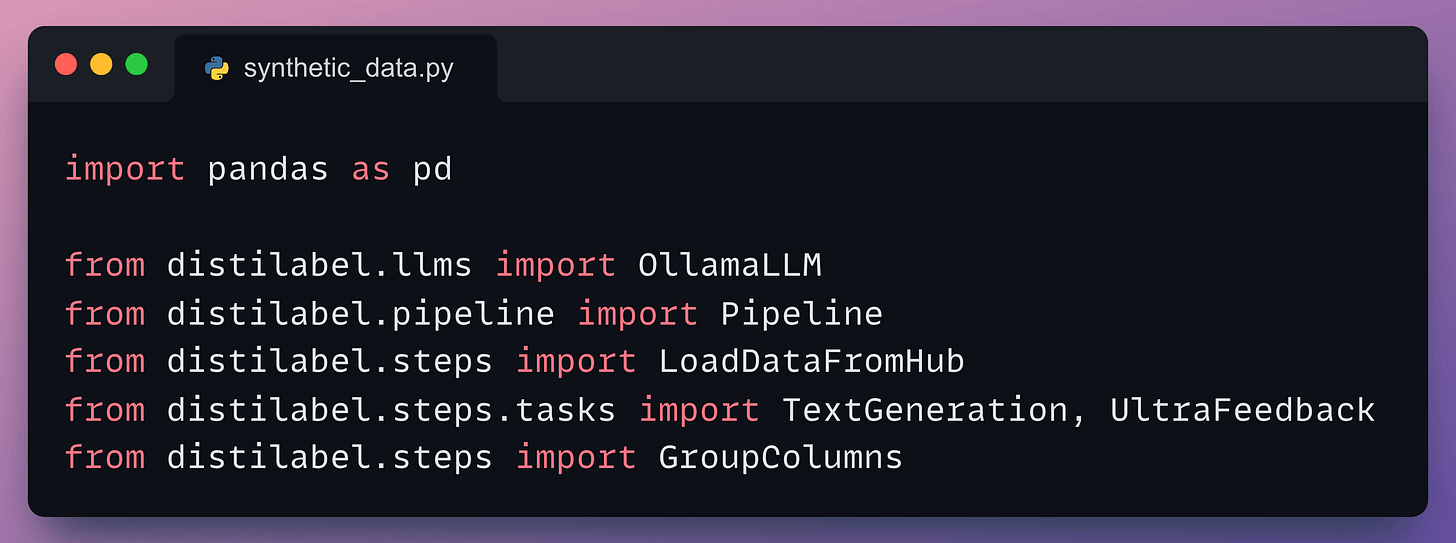
First, we start with some standard imports:
Next, we load the Lllama-3 models locally with Ollama (we covered the procedure to setup Ollama here):

Moving on, we define our pipeline:
We execute this as follows:
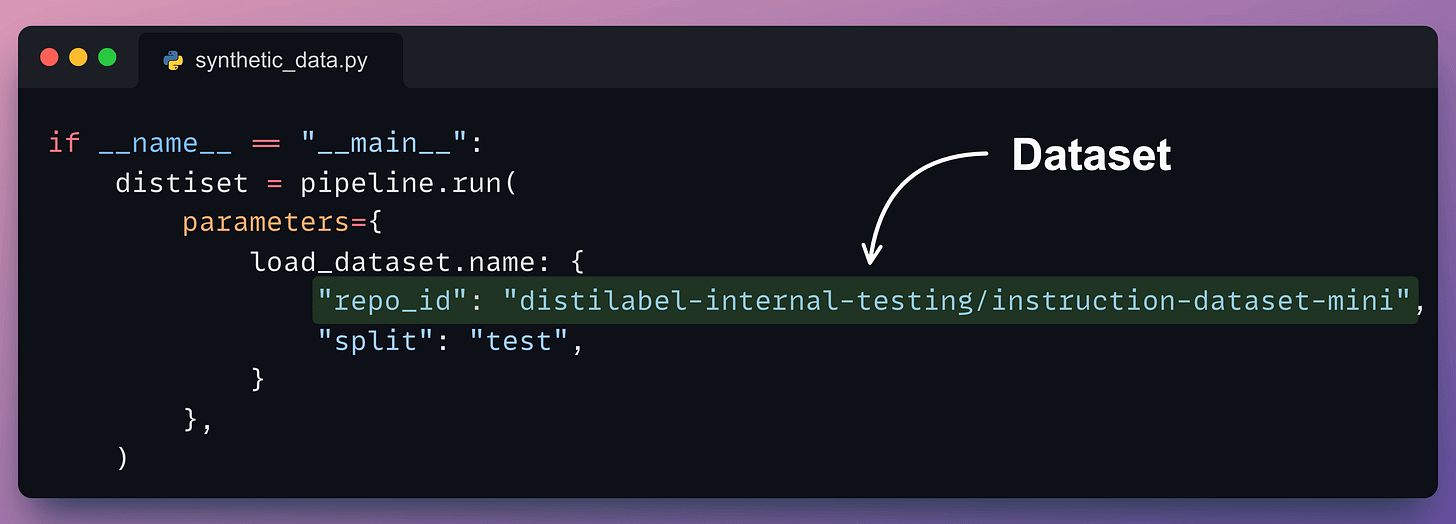
Done!
This produces the instruction and response synthetic dataset as desired.

That was simple, wasn’t it?
This produces a dataset on which the LLM can be easily fine-tuned.
In future issues, we’ll cover more about our learnings from synthetic data generation.
That said, if you know how to build a reliable RAG system, you can bypass the challenge and cost of further fine-tuning an LLM specific to your data.
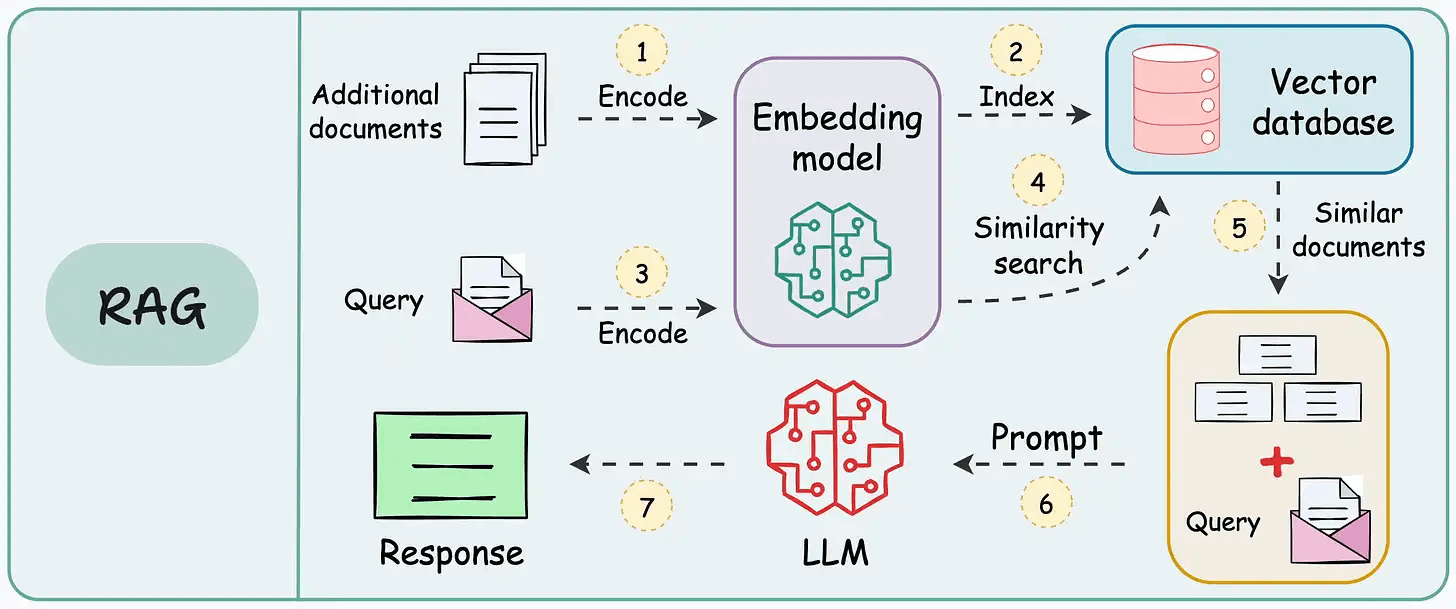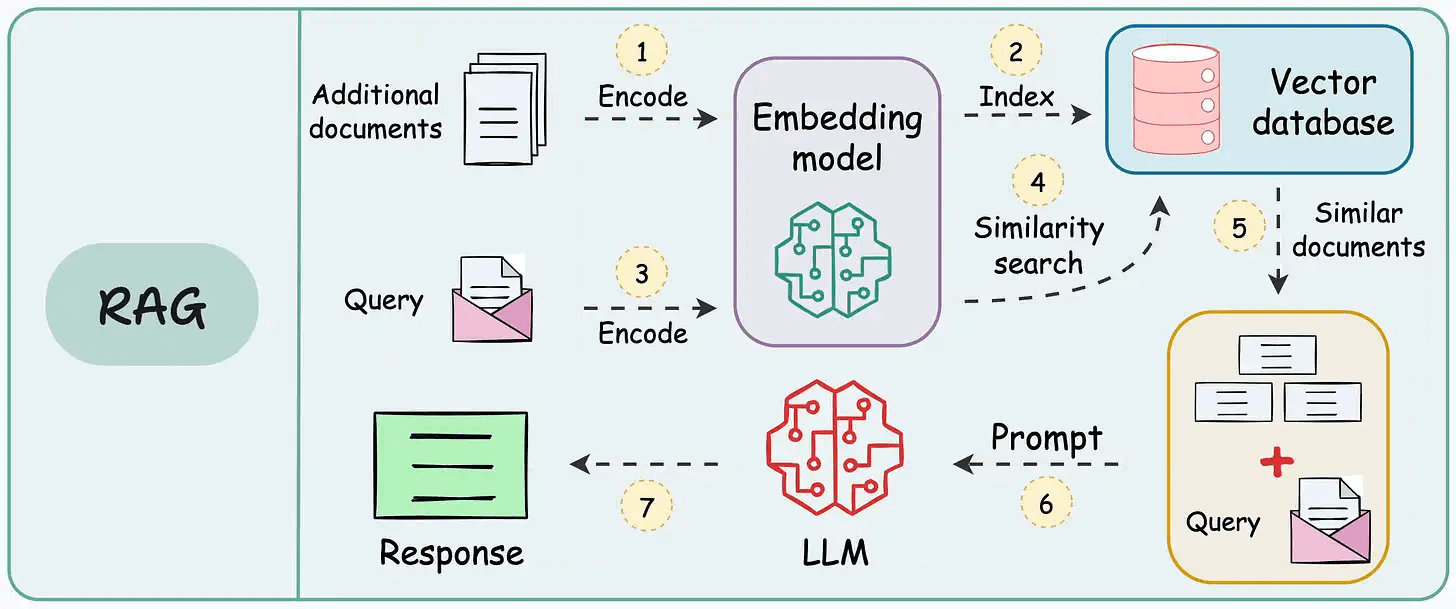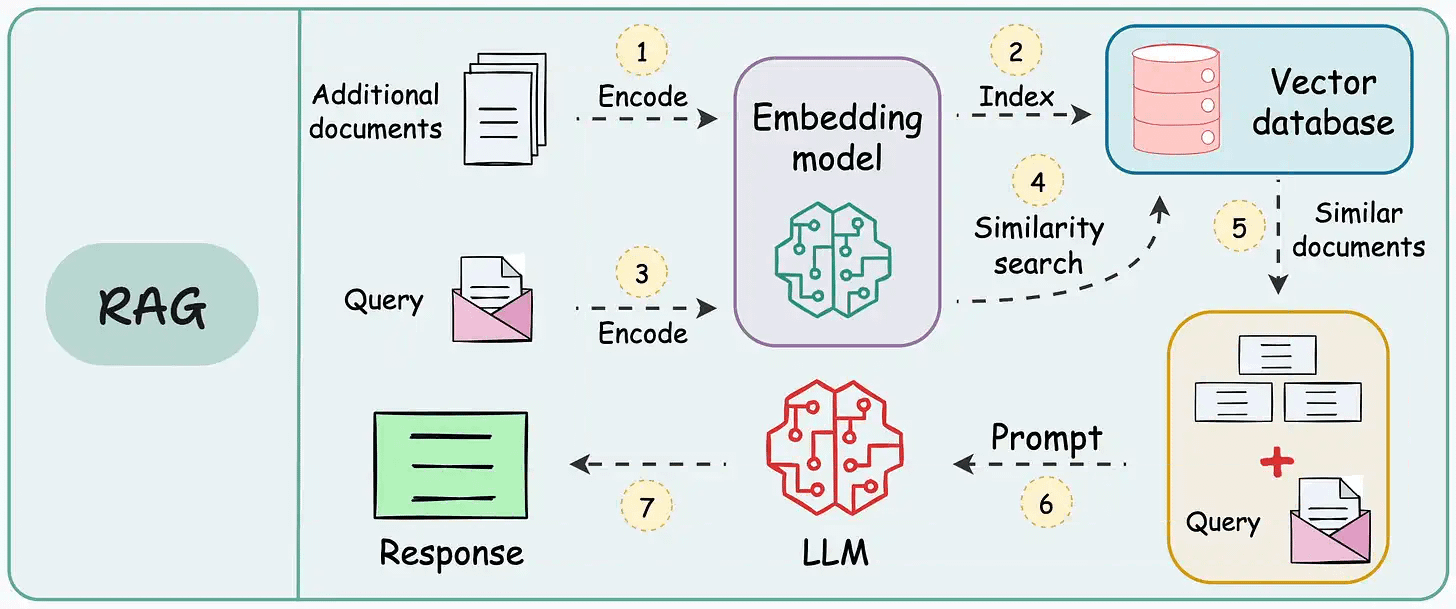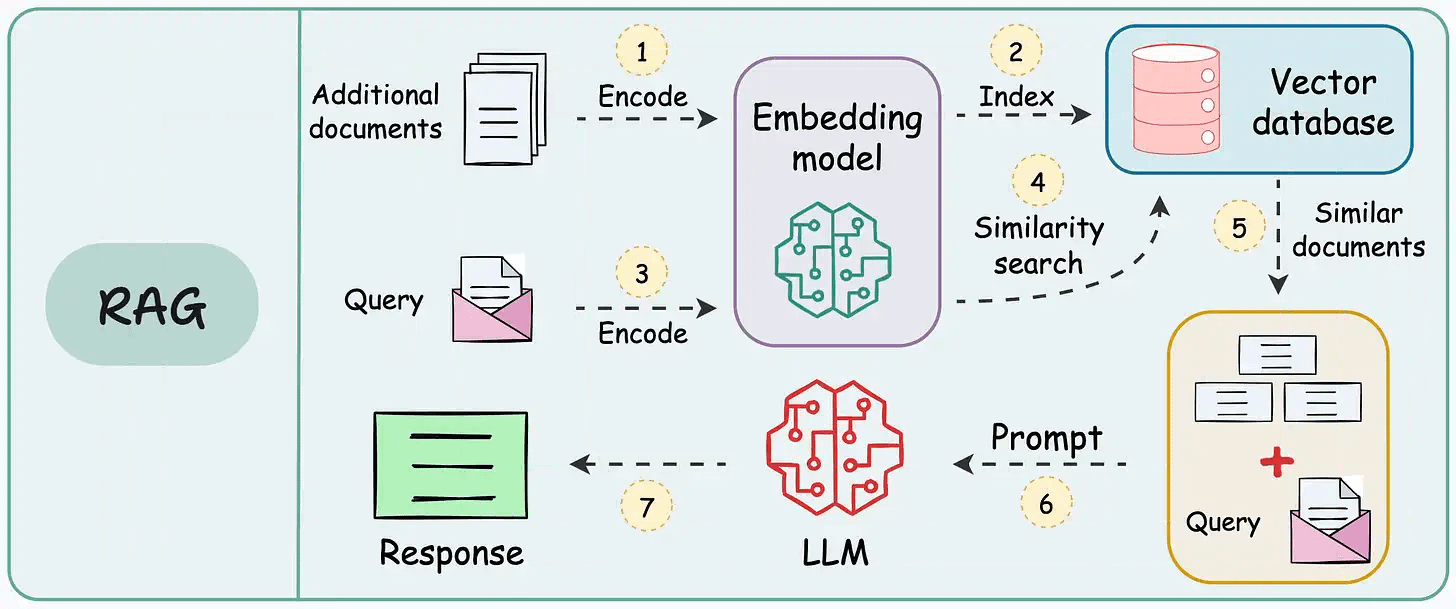
That’s a considerable cost saving for enterprises.
We started a crash course to help you implement reliable RAG systems, understand the underlying challenges, and develop expertise in building RAG apps on LLMs, which every industry cares about now.
Of course, if you have never worked with LLMs, that’s okay. We cover everything in a practical and beginner-friendly way.
👉 Over to you: What are some other ways to generate synthetic data for fine-tuning?
Model accuracy alone (or an equivalent performance metric) rarely determines which model will be deployed.
Much of the engineering effort goes into making the model production-friendly.
Because typically, the model that gets shipped is NEVER solely determined by performance — a misconception that many have.
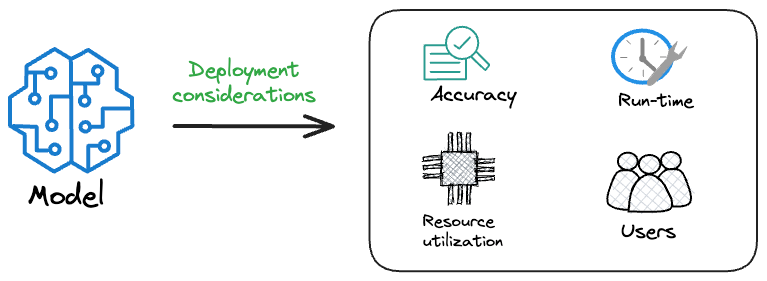
Instead, we also consider several operational and feasibility metrics, such as:
For instance, consider the image below. It compares the accuracy and size of a large neural network I developed to its pruned (or reduced/compressed) version:
Looking at these results, don’t you strongly prefer deploying the model that is 72% smaller, but is still (almost) as accurate as the large model?
Of course, this depends on the task but in most cases, it might not make any sense to deploy the large model when one of its largely pruned versions performs equally well.
We discussed and implemented 6 model compression techniques in the article here, which ML teams regularly use to save 1000s of dollars in running ML models in production.
Learn how to compress models before deployment with implementation →
Meta released Llama-3.3 last week.
So, we released a practical and hands-on demo of using Llama 3.3 to build a RAG app.
The outcome is shown in the video below:
The app accepts a document and lets the user interact with it via chat.
We used: