Building Trustworthy Agentic/RAG Workflows
...explained step-by-step with code.

Avi Chawla
...explained step-by-step with code.

TODAY'S ISSUE
It is common for RAG systems to produce inaccurate/unhelpful responses.
Today, let’s look at how we can improve this using Cleanlab Codex, which is commonly used in production systems to automatically detect and resolve RAG inaccuracies.
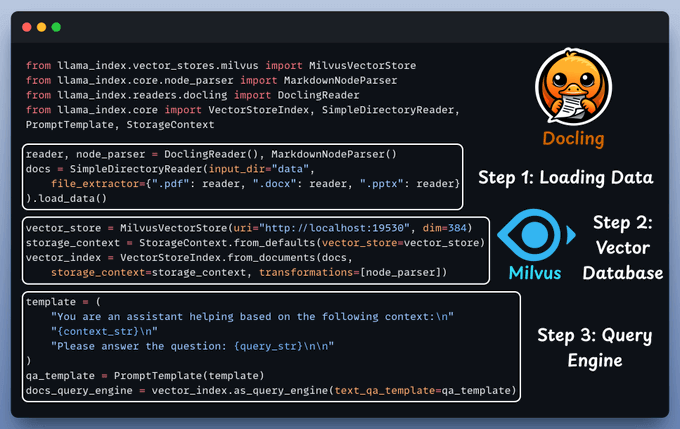
Tech stack:
Here's the workflow:
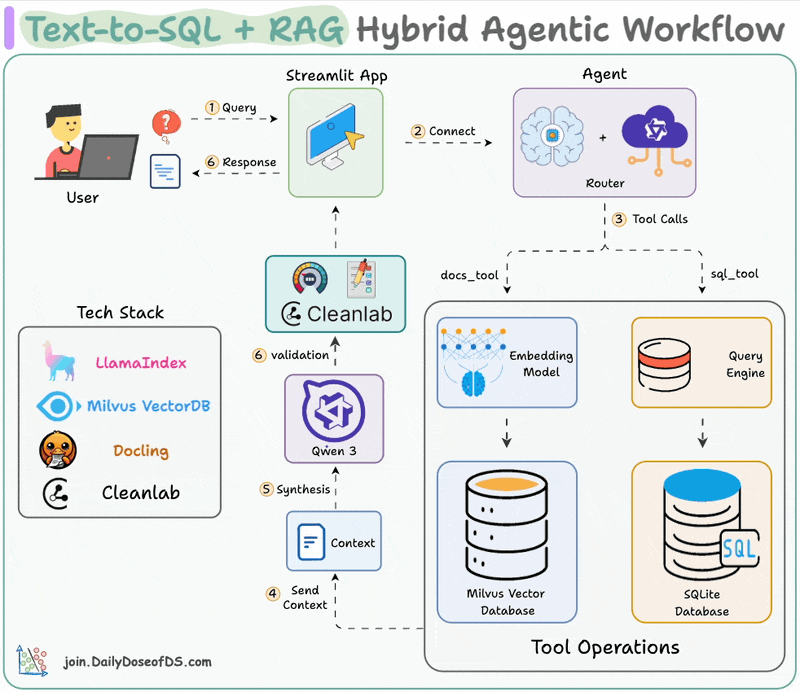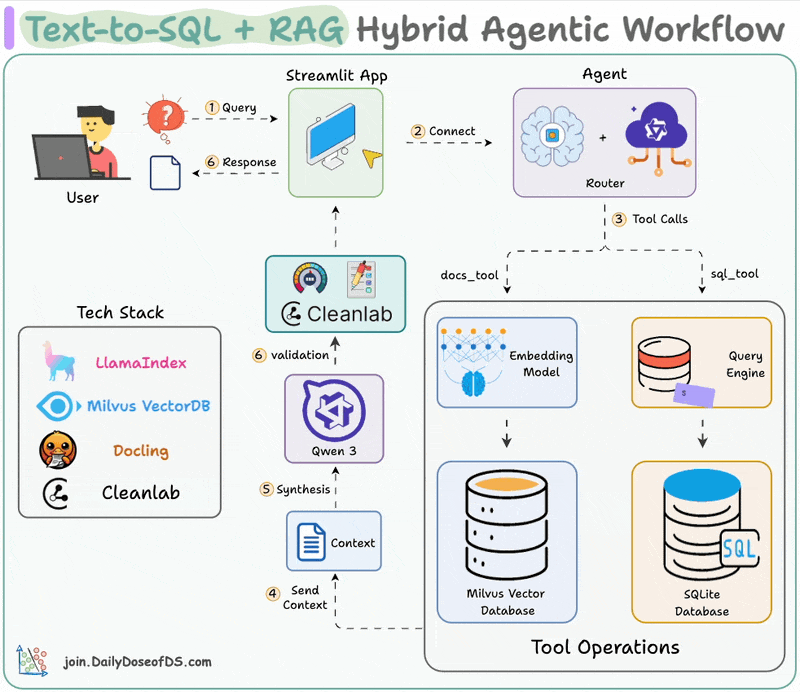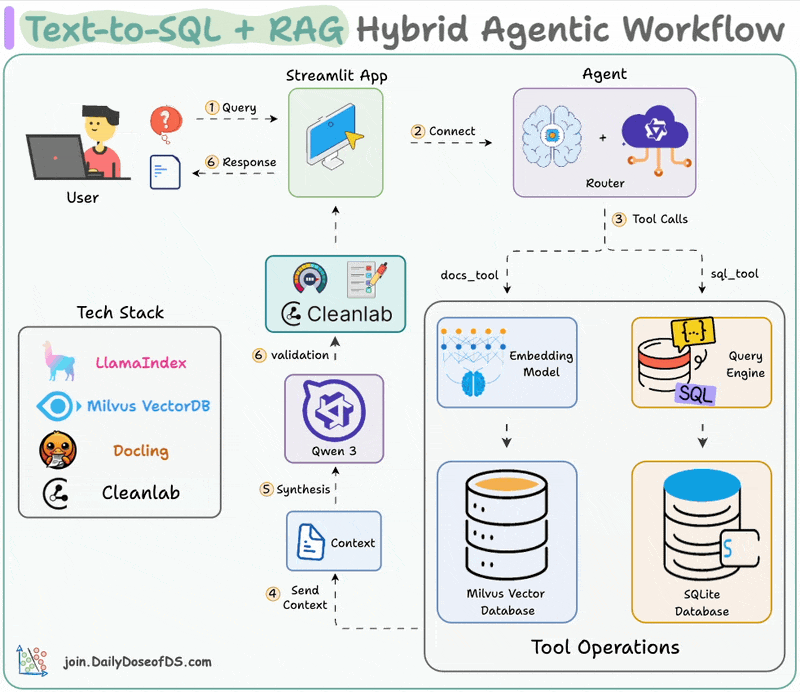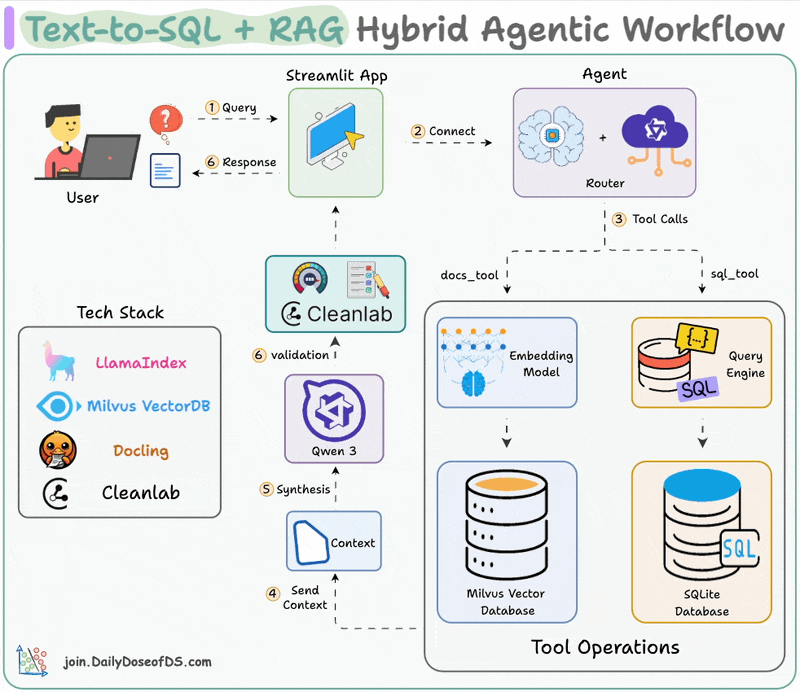
The video below depicts this entire system in action:
Now, let's see the code!
We'll use the latest Qwen3, served via OpenRouter.
Ensure the LLM supports tool calling for seamless execution.

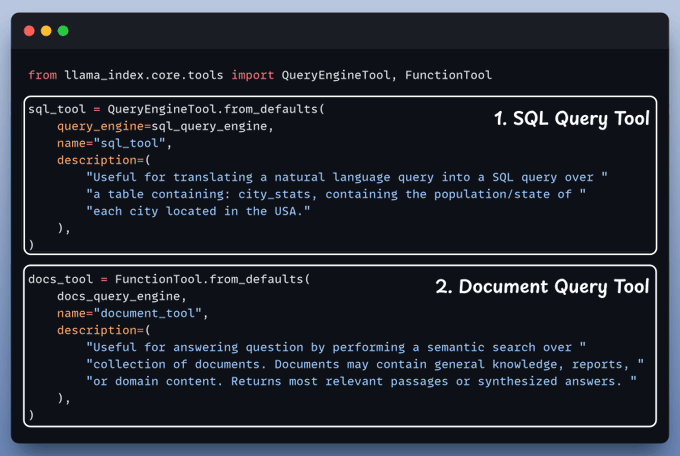
A Natural Language to SQL Engine turns plain queries into SQL commands, enabling easy data interaction.

Now, it's time to set up and use both the query engines we defined above as tools. Our Agent will then smartly route the query to it's right tools.
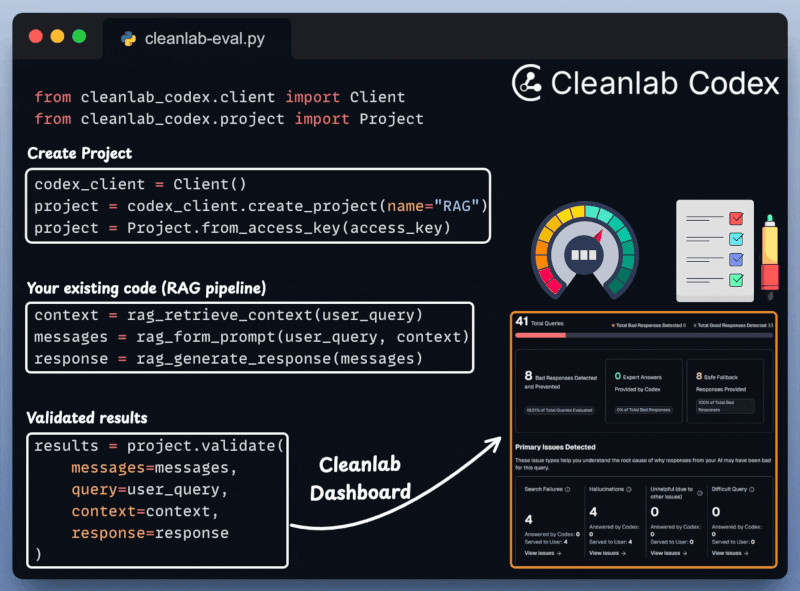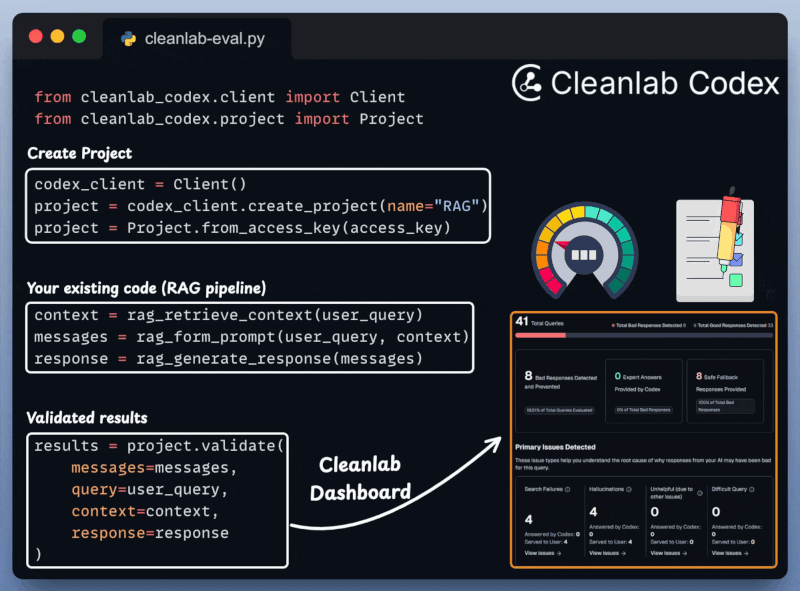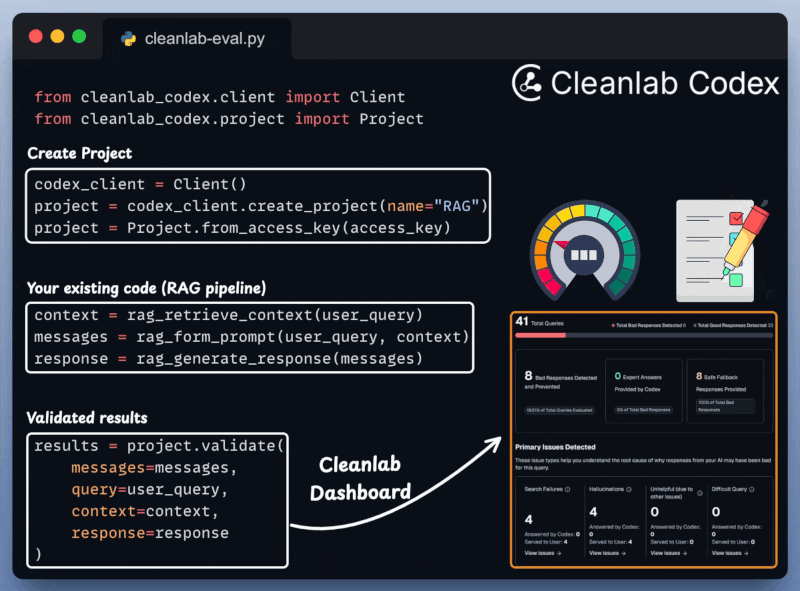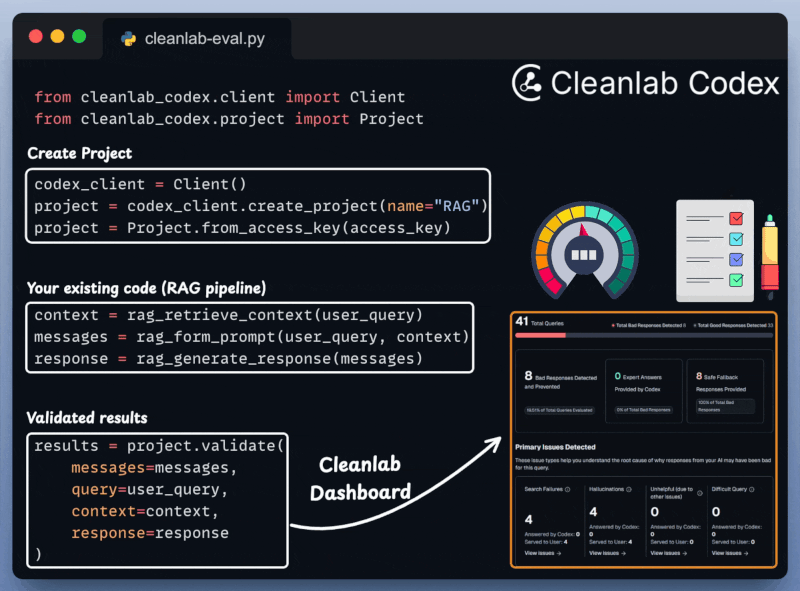
Next, we integrate Cleanlab Codex to evaluate and monitor the RAG app in just a few lines of code:
With everything set up, let's create our agentic routing workflow.
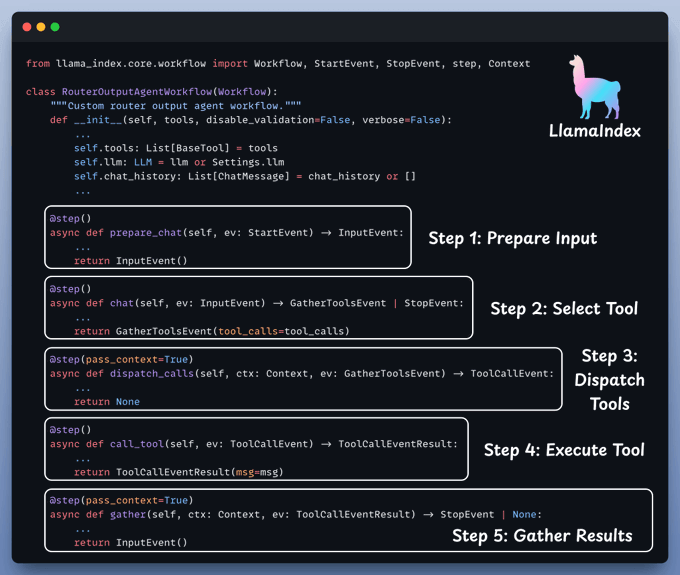
With everything set, it's time to activate our workflow.
We begin by equipping LLM with two tools: Document & Text-to-SQL Query.
After that, we invoke the workflow:
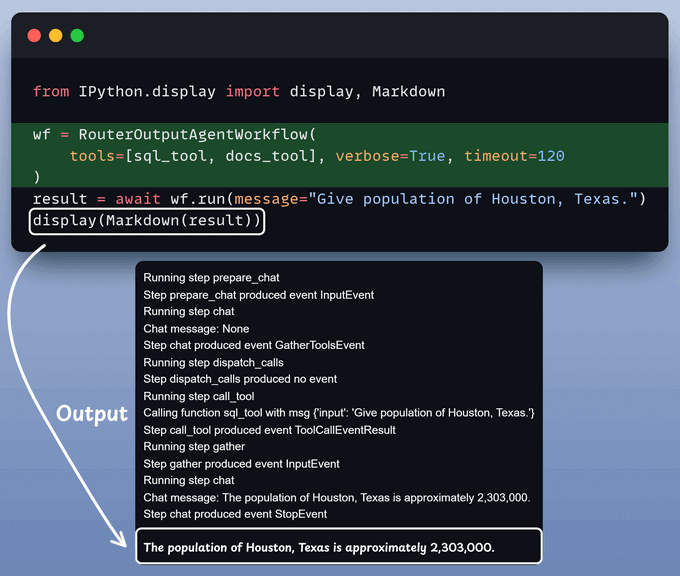
To enhance user-friendliness, we present everything within a clean and interactive Streamlit UI.
Upon prompting, notice that the app displays a Trust Score on the generated response.
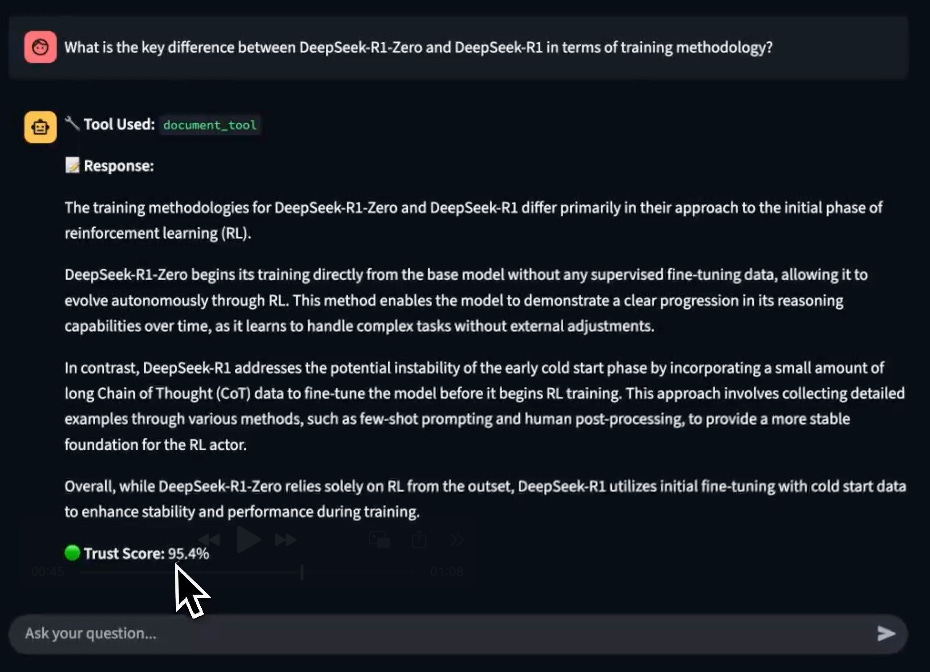
This is incredibly important for RAG/Agentic workflows that are quite susceptible to inaccuracies and hallucinations.
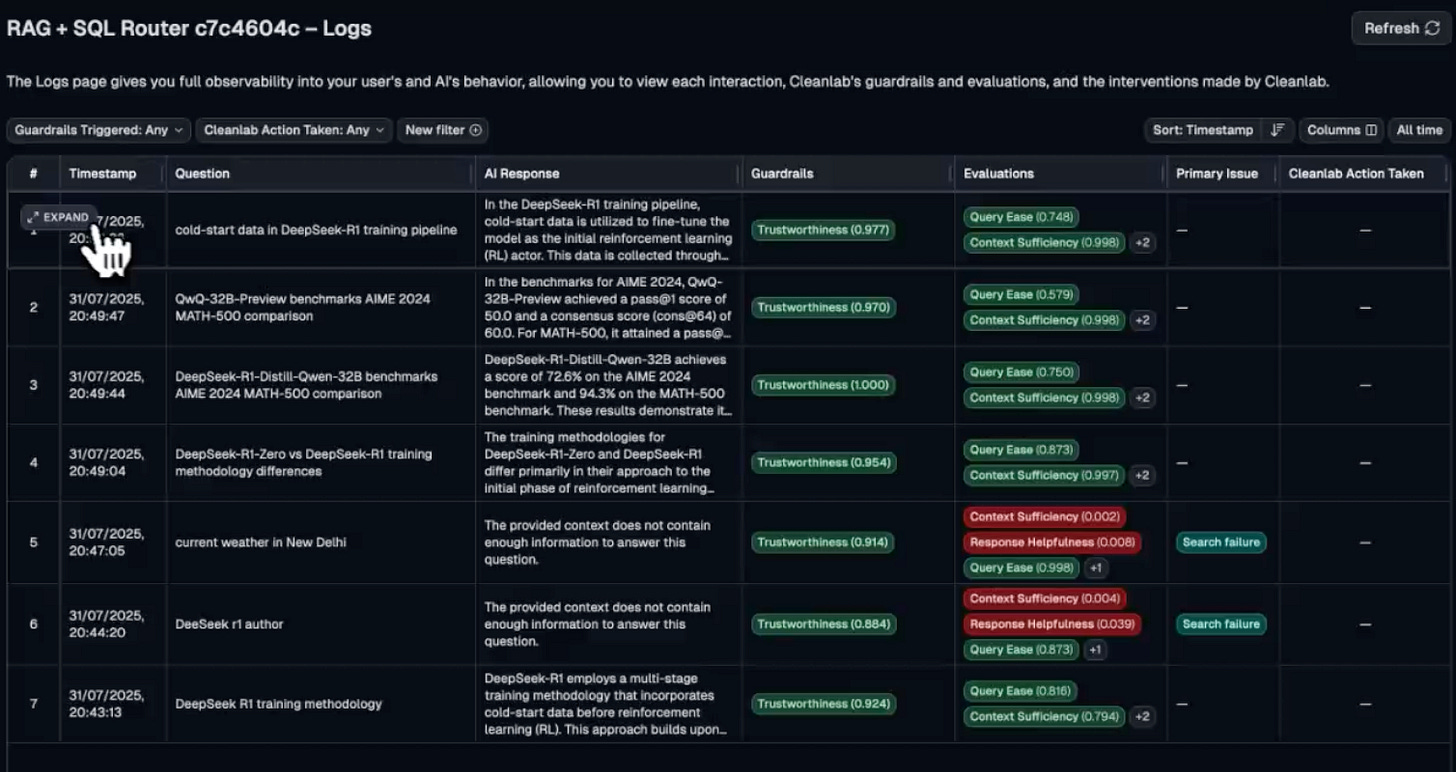
Along with this, we also get specific evaluation metrics along with detailed insights and reasoning for each test run:
Here’s the Codex documentation →
And you can find the code for today’s issue in this GitHub repo →
There are many issues with Grid search and random search.
Bayesian optimization solves this.
It’s fast, informed, and performant, as depicted below:

Learning about optimized hyperparameter tuning and utilizing it will be extremely helpful to you if you wish to build large ML models quickly.
Conformal prediction has gained quite traction in recent years, which is evident from the Google trends results:
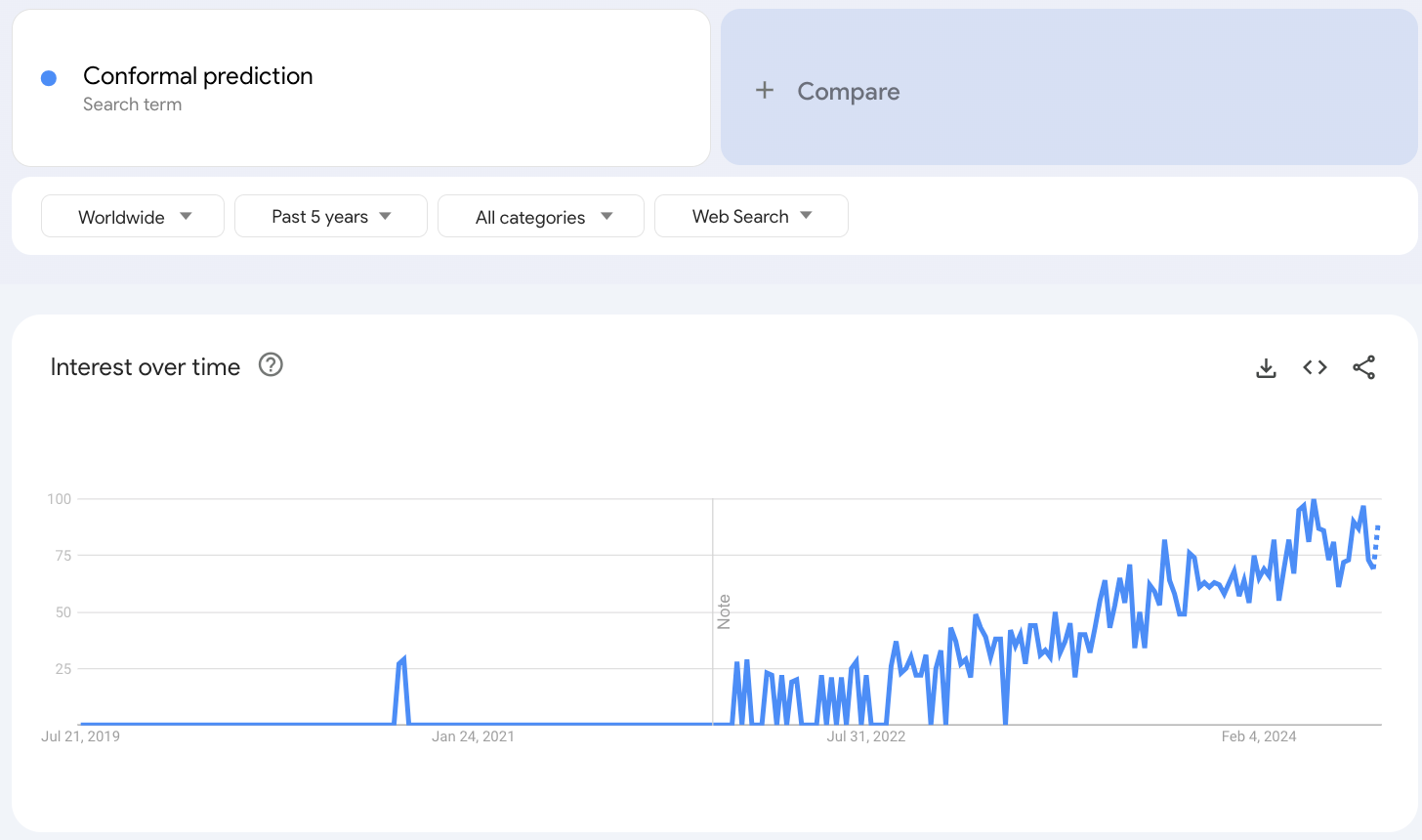
The reason is quite obvious.
ML models are becoming increasingly democratized lately. However, not everyone can inspect its predictions, like doctors or financial professionals.
Thus, it is the responsibility of the ML team to provide a handy (and layman-oriented) way to communicate the risk with the prediction.
For instance, if you are a doctor and you get this MRI, an output from the model that suggests that the person is normal and doesn’t need any treatment is likely pretty useless to you.
This is because a doctor's job is to do a differential diagnosis. Thus, what they really care about is knowing if there's a 10% percent chance that that person has cancer or 80%, based on that MRI.
Conformal predictions solve this problem.
A somewhat tricky thing about conformal prediction is that it requires a slight shift in making decisions based on model outputs.
Nonetheless, this field is definitely something I would recommend keeping an eye on, no matter where you are in your ML career.
Learn how to practically leverage conformal predictions in your model →useless