LLMs
Build a Reasoning LLM using GRPO
100% local.

Avi Chawla
100% local.

TODAY'S ISSUE
Group Relative Policy Optimization is a reinforcement learning method that fine-tunes LLMs for math and reasoning tasks using deterministic reward functions, eliminating the need for labeled data.
Here's a brief overview of GRPO:
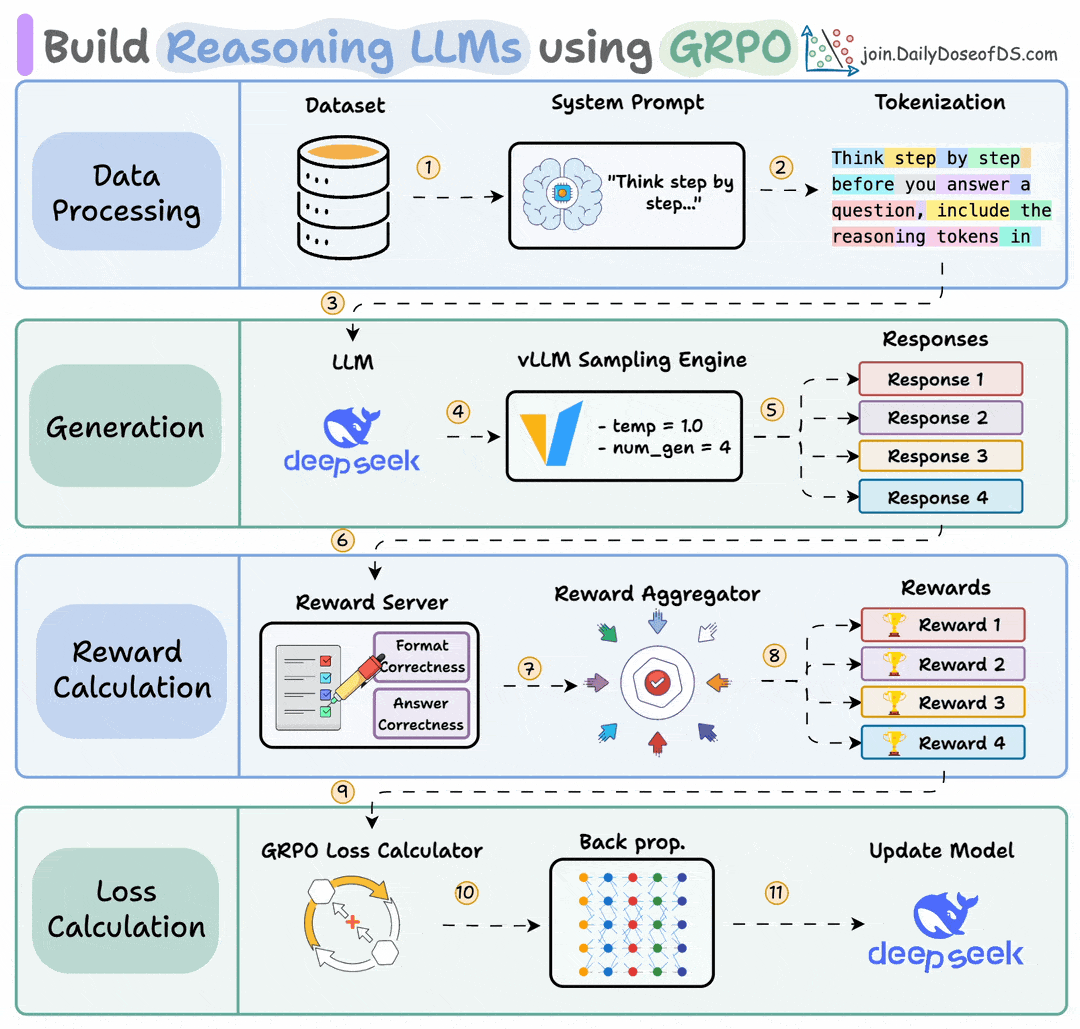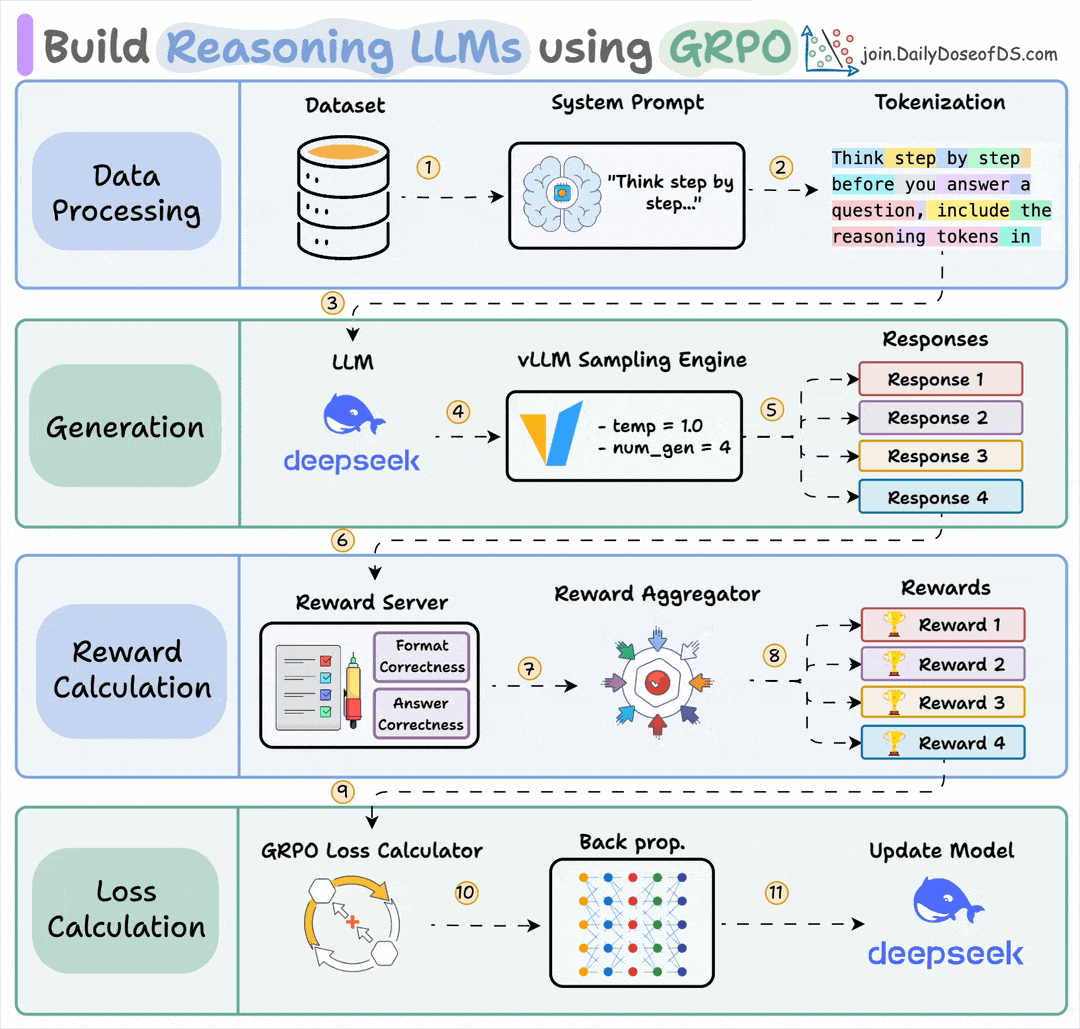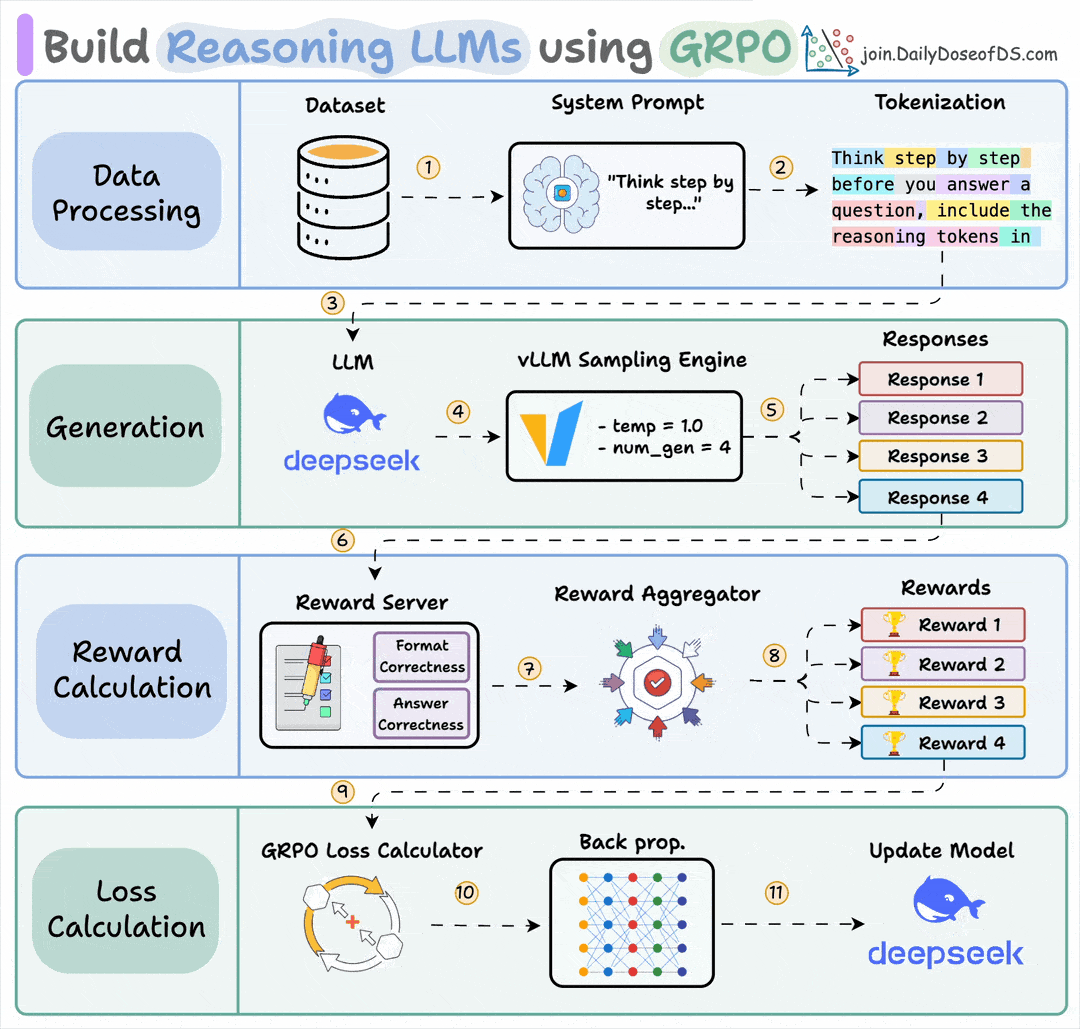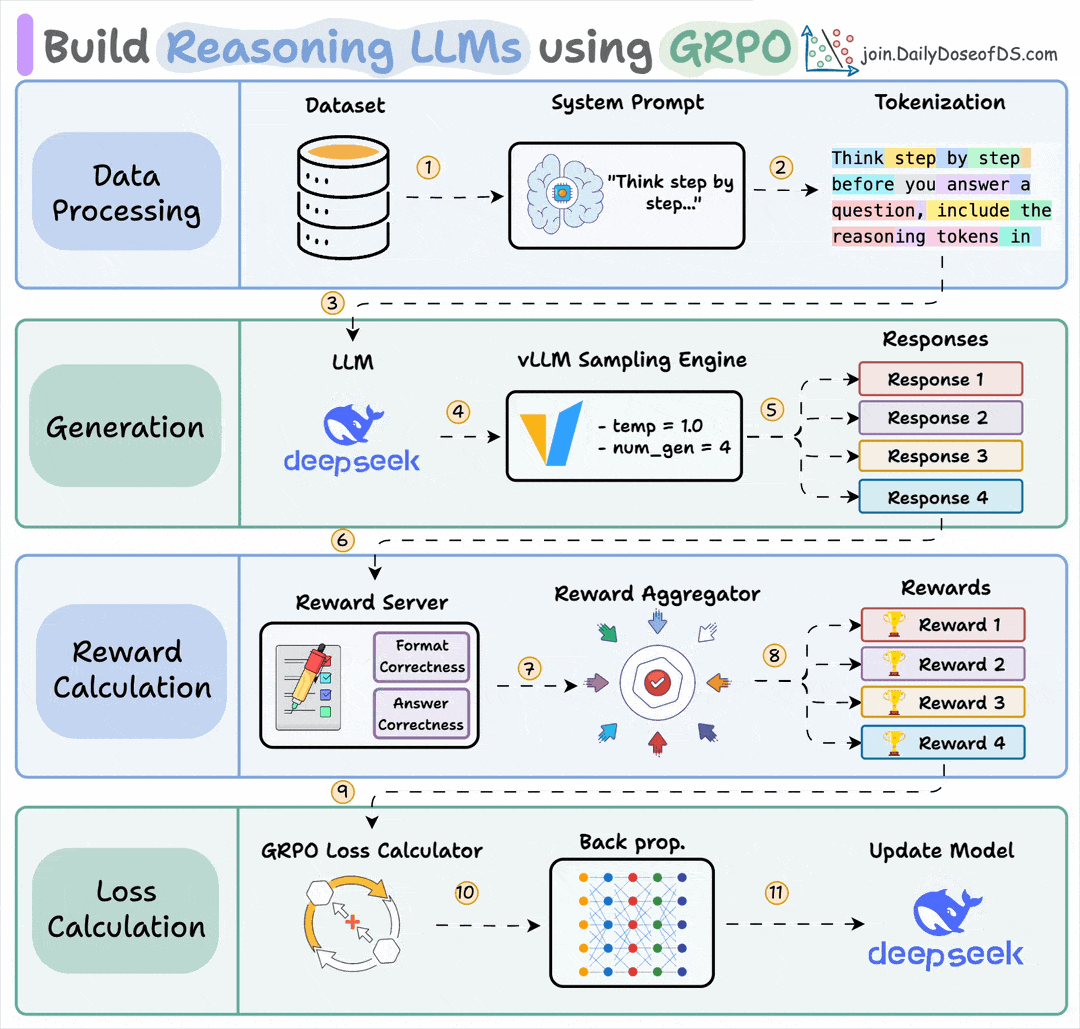
Let’s dive into the code to see how we can use GRPO to turn any model into a reasoning powerhouse without any labeled data or human intervention.
We’ll use:
The code is available here: Build a reasoning LLM from scratch using GRPO. You can run it without any installations by reproducing our environment below:
Let’s begin!
We start by loading Qwen3-4B-Base and its tokenizer using Unsloth.
You can use any other open-weight LLM here.

We'll use LoRA to avoid fine-tuning the entire model weights. In this code, we use Unsloth's PEFT by specifying:
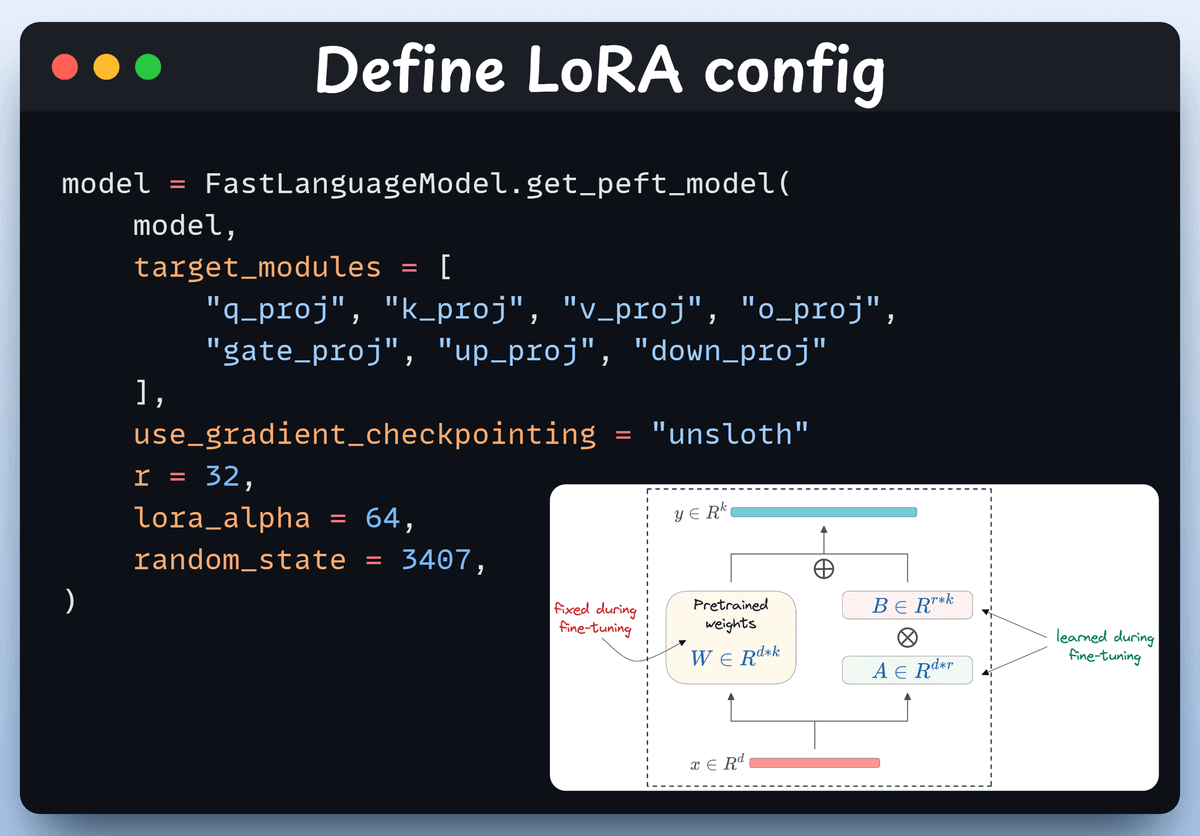
We load the Open R1 Math dataset (a math problem dataset) and format it for reasoning.
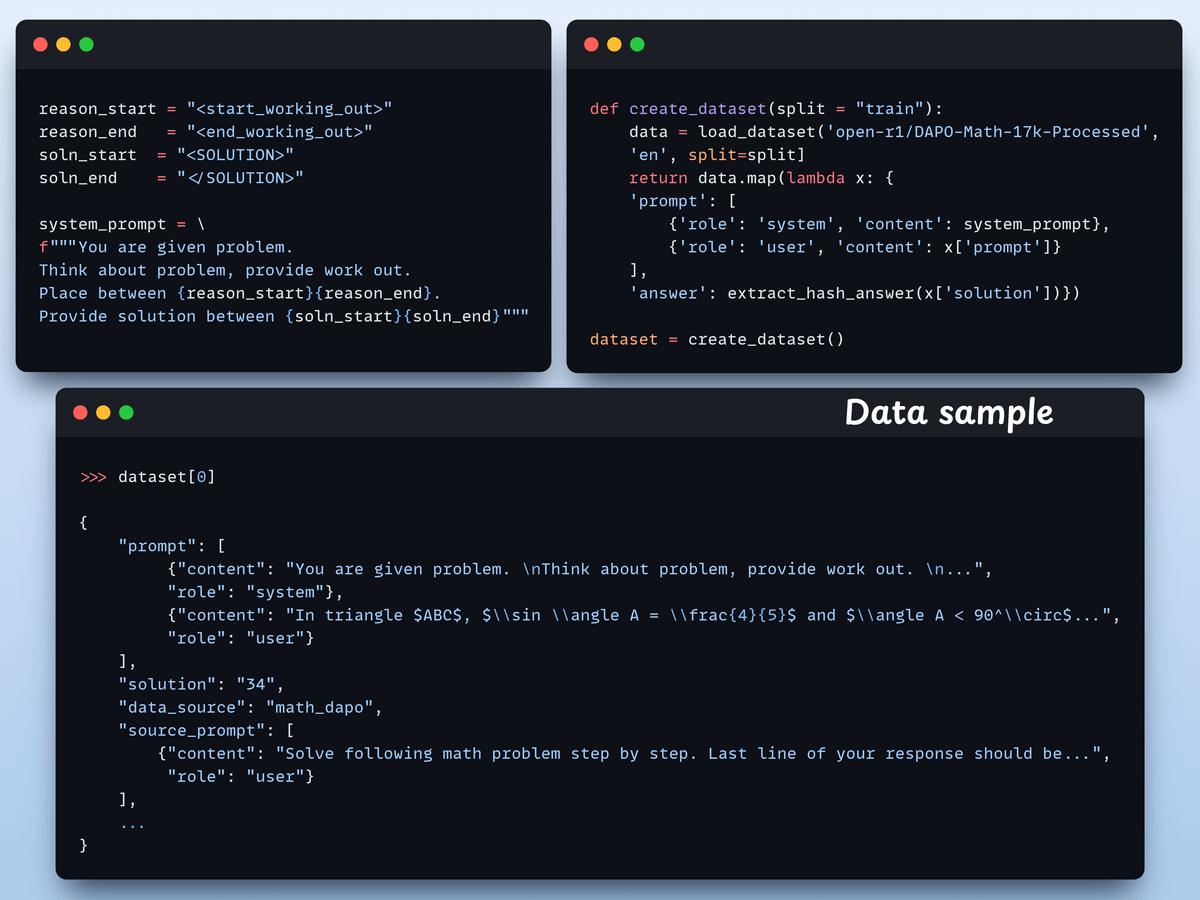
Each sample includes:
In GRPO, we use deterministic functions to validate the response and assign a reward. No manual labelling required!
The reward functions:

Now that we have the dataset and reward functions ready, it's time to apply GRPO.
HuggingFace TRL provides everything we described in the GRPO diagram, out of the box, in the form of the GRPOConfig and GRPOTrainer.
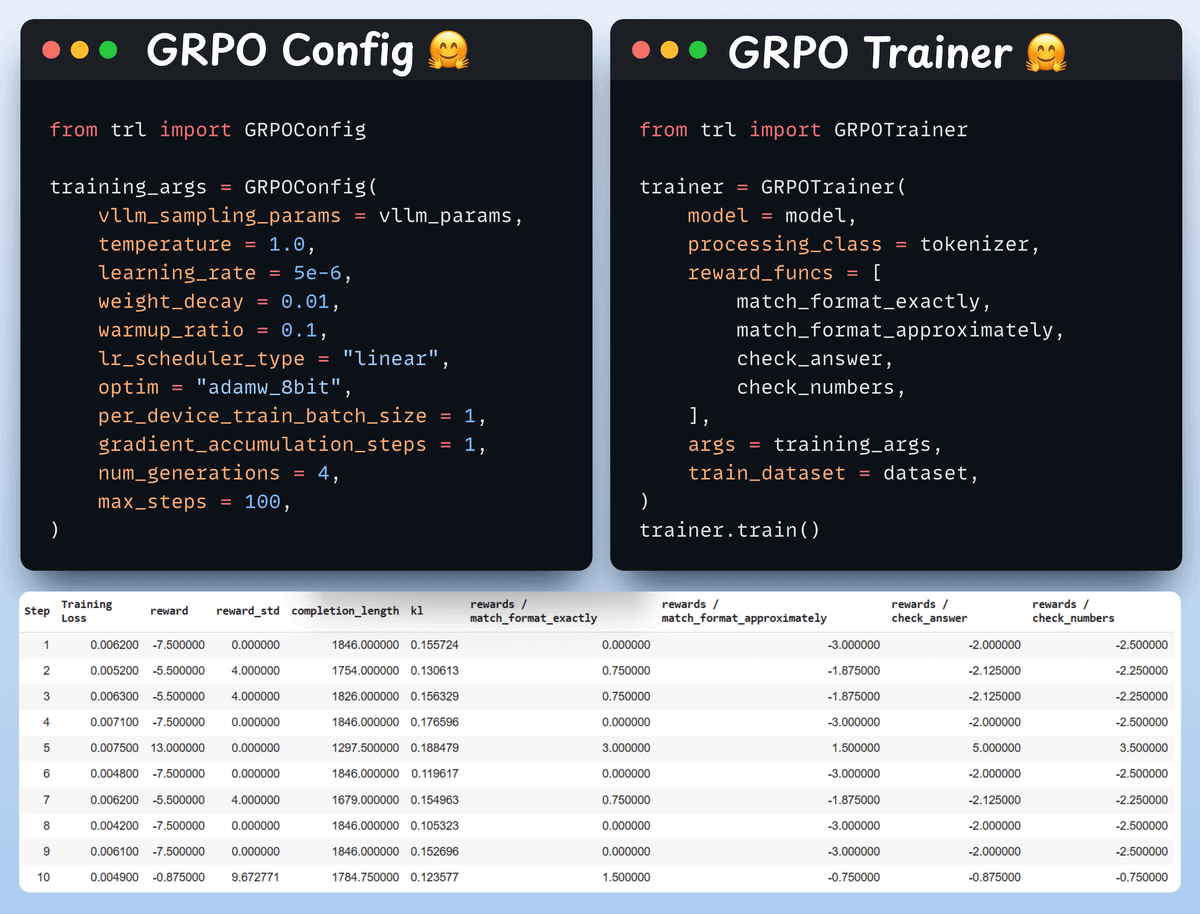
We can see how GRPO turned a base model into a reasoning powerhouse:
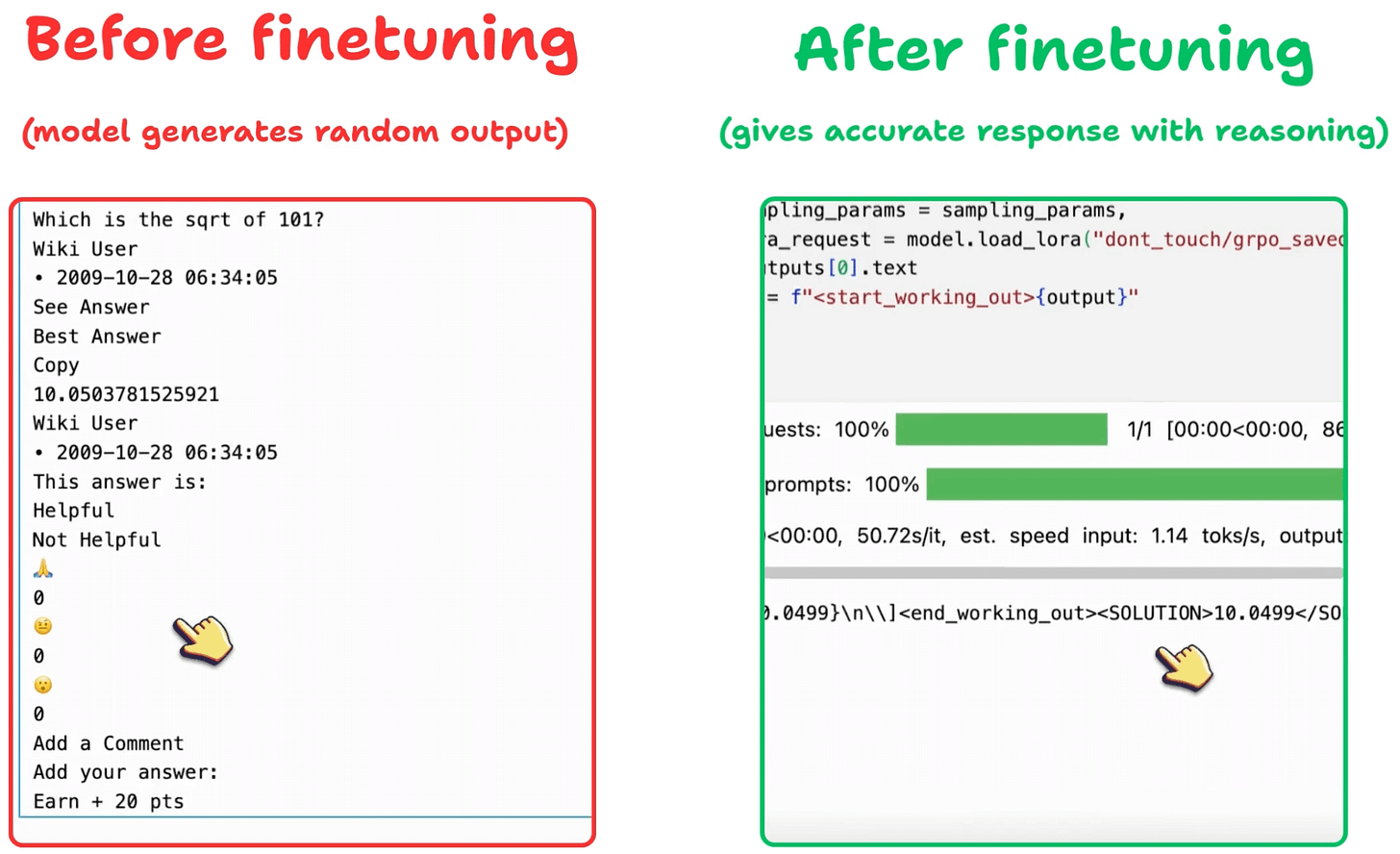
Before we conclude, let’s address an important question:
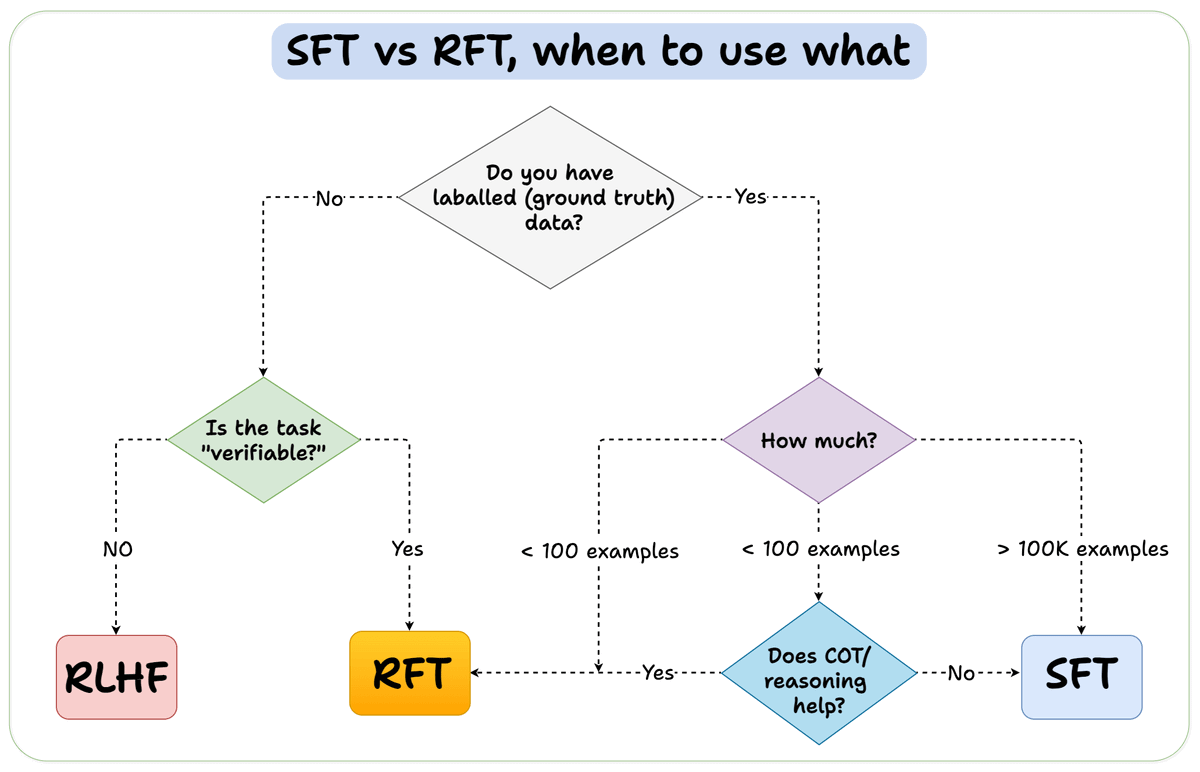
When should you use reinforcement fine-tuning (RFT) versus supervised fine-tuning (SFT)?
We created this diagram to provide an answer:
Finally, we'll leave you with an overview of the GRPO process.
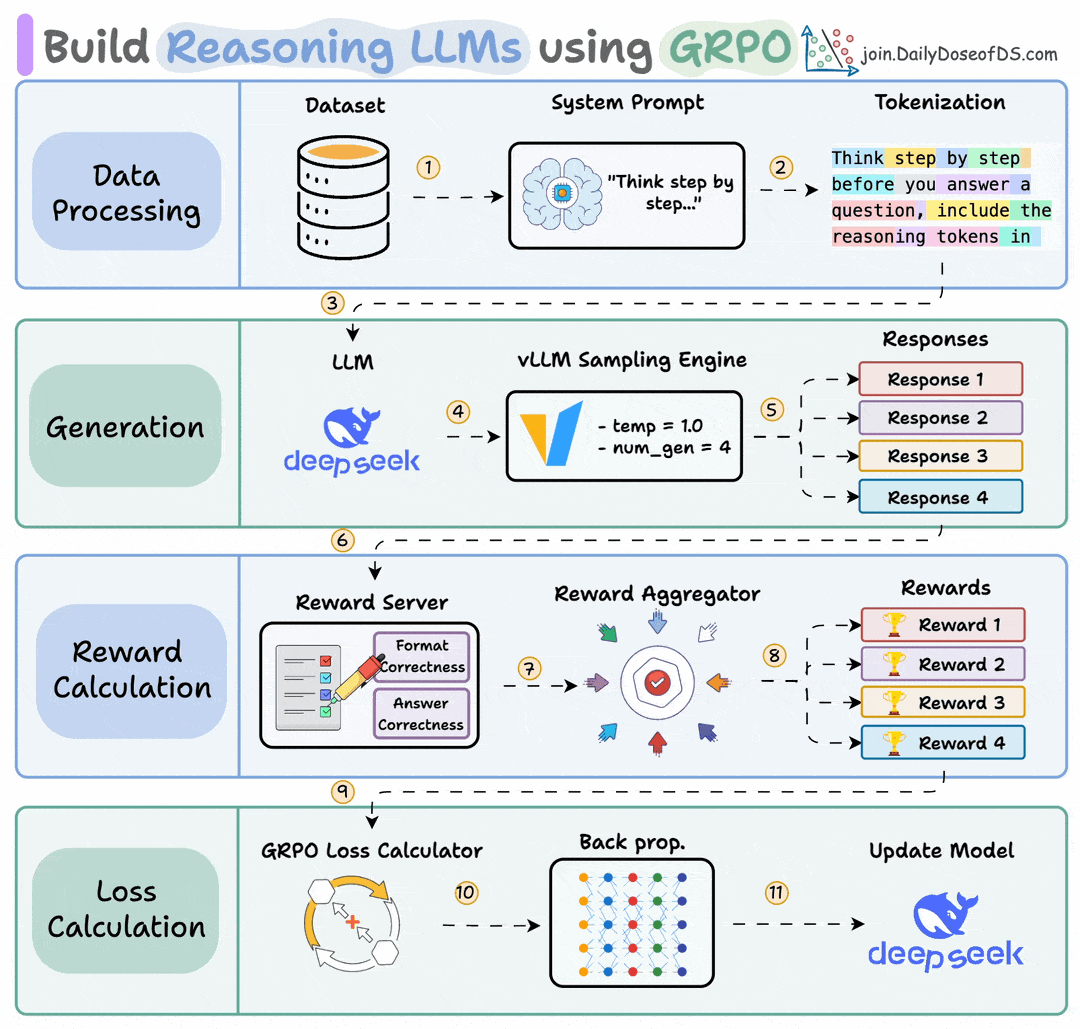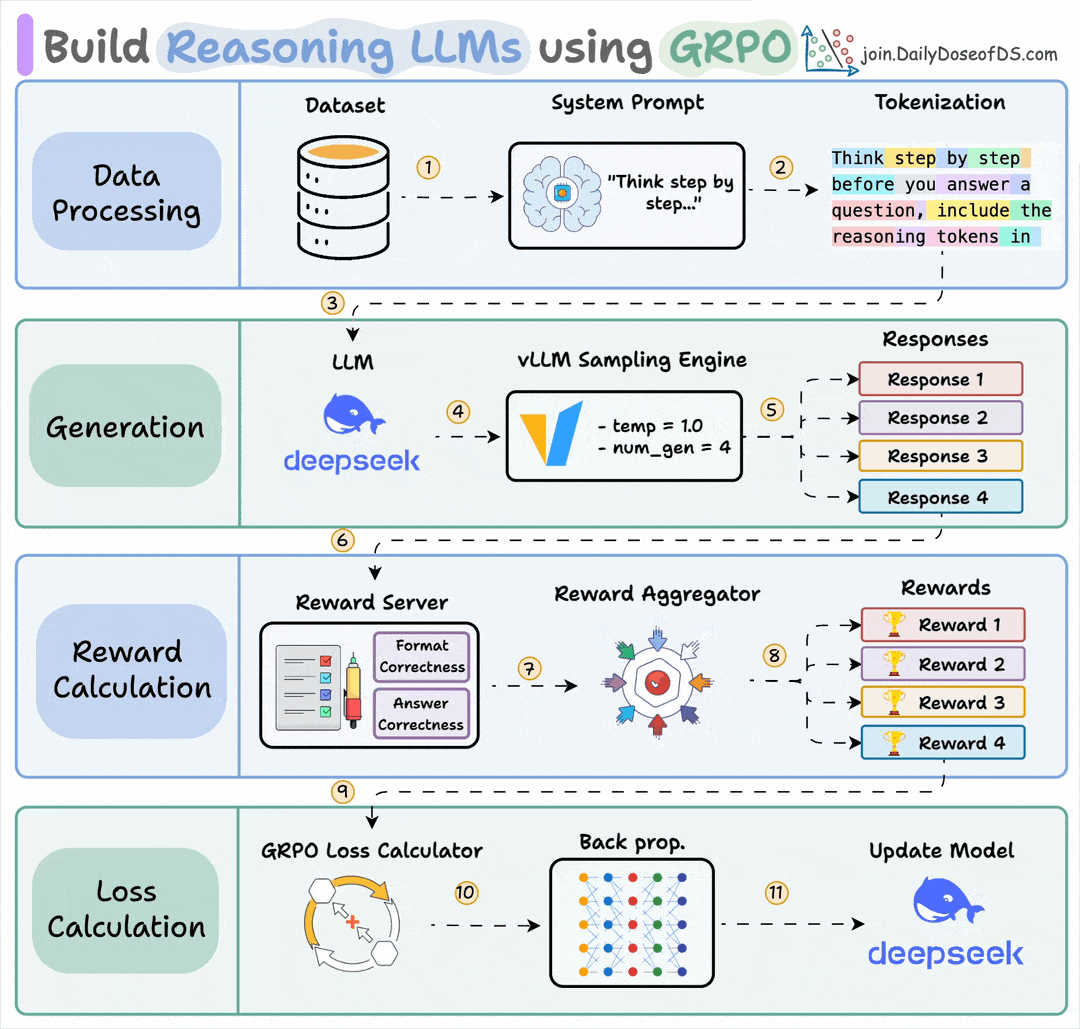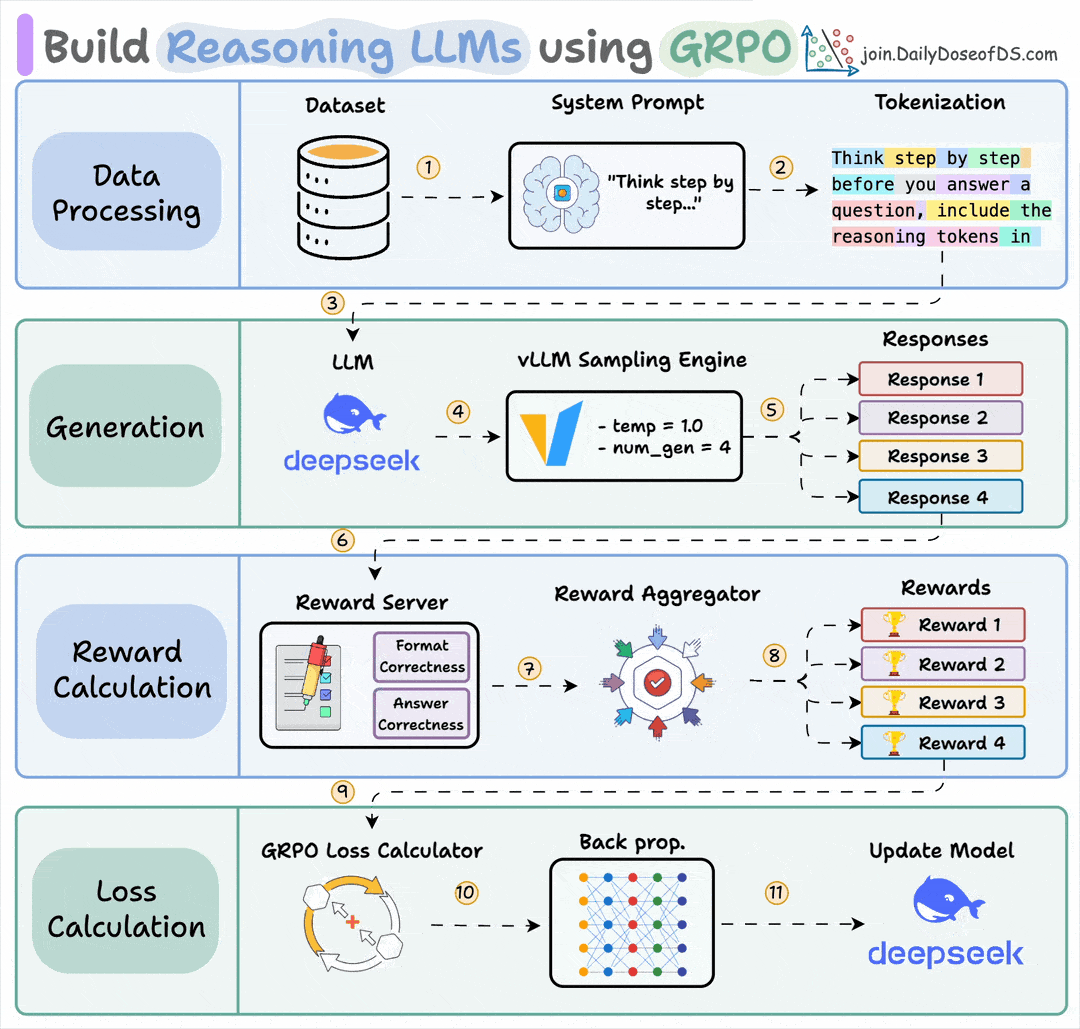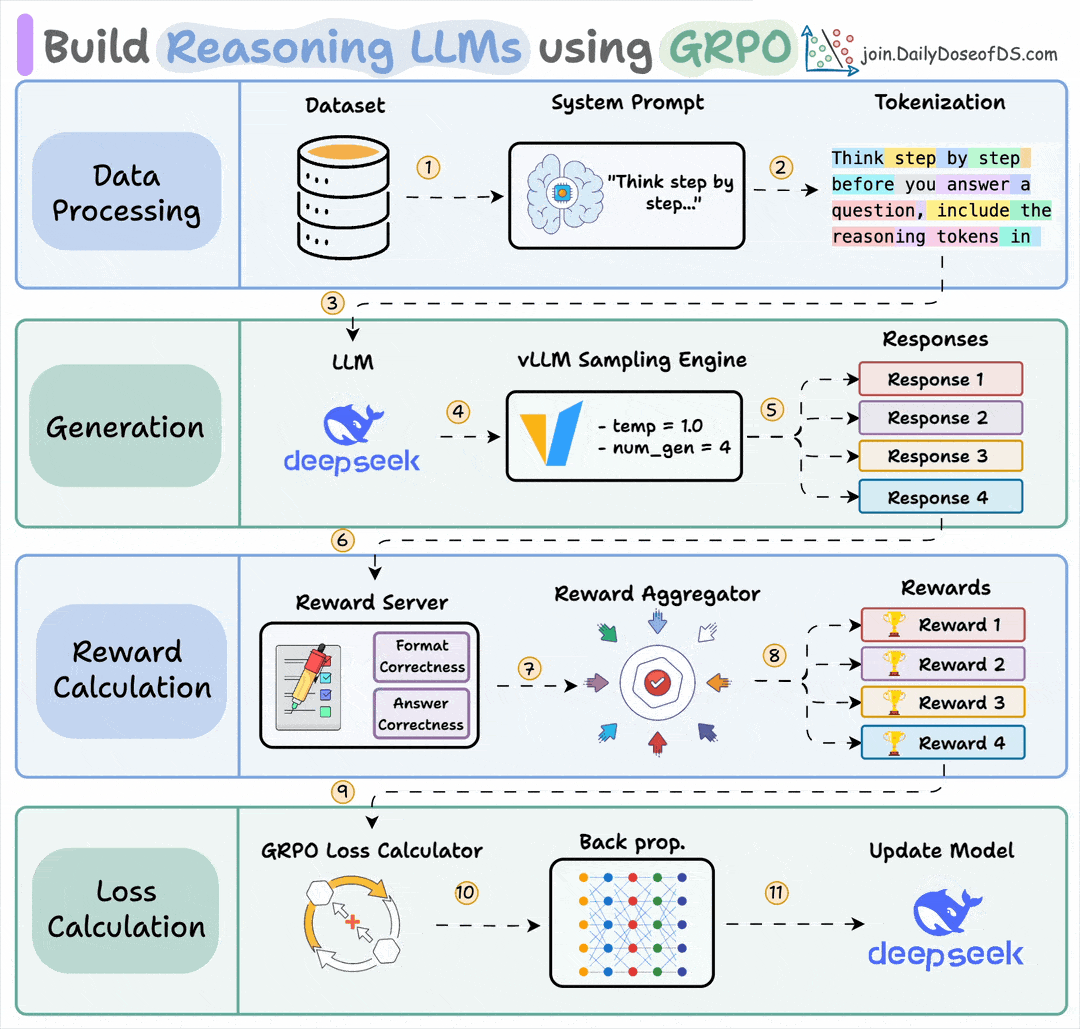
Let us know what other techniques you have used for fine-tuning LLMs.
The code is available here: Build a reasoning LLM from scratch using GRPO. You can run it without any installations by reproducing our environment below:
Thanks for reading!
Once a model has been trained, we move to productionizing and deploying it.
If ideas related to production and deployment intimidate you, here’s a quick roadmap for you to upskill (assuming you know how to train a model):
This roadmap should set you up pretty well, even if you have NEVER deployed a single model before since everything is practical and implementation-driven.