LLMs
4 Stages of Training LLMs from Scratch
...explained visually.

Avi Chawla
...explained visually.
Today, we are covering the 4 stages of building LLMs from scratch that are used to make them applicable for real-world use cases.
We’ll cover:
The visual summarizes these techniques.
Let's dive in!
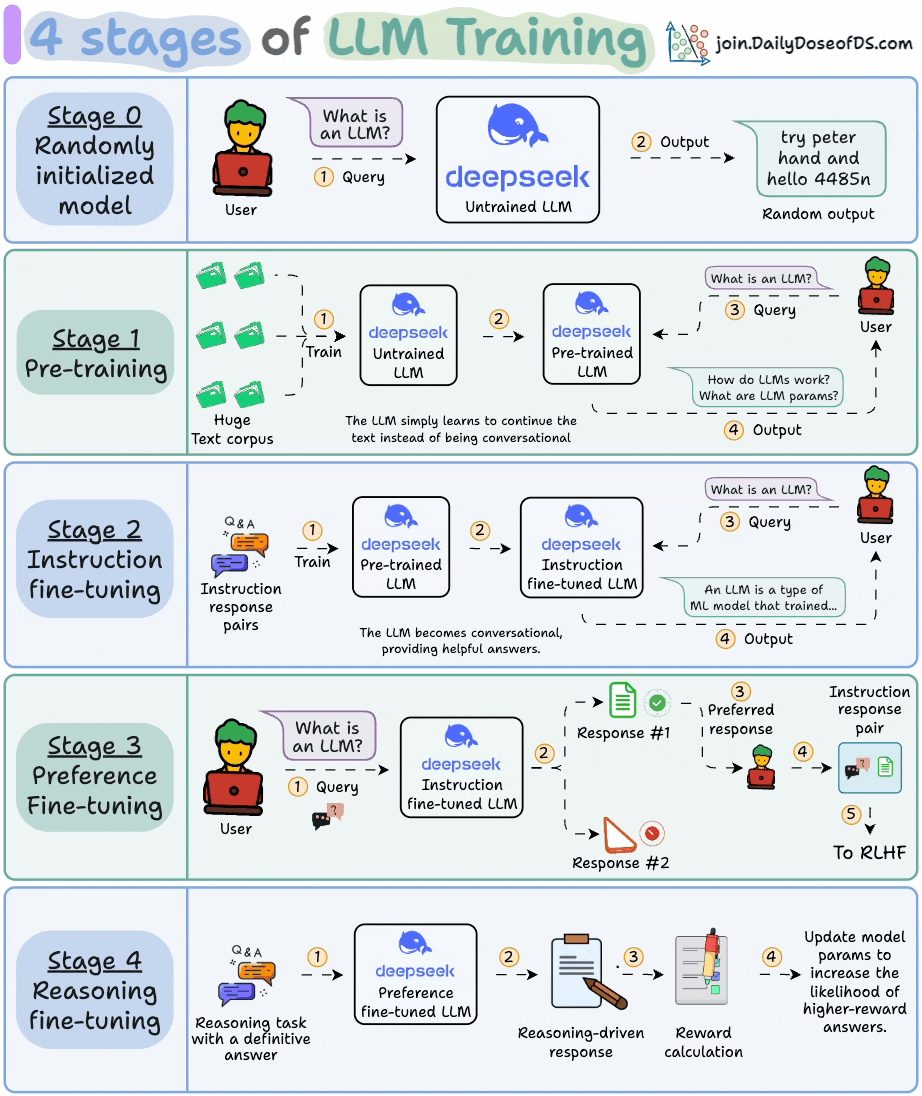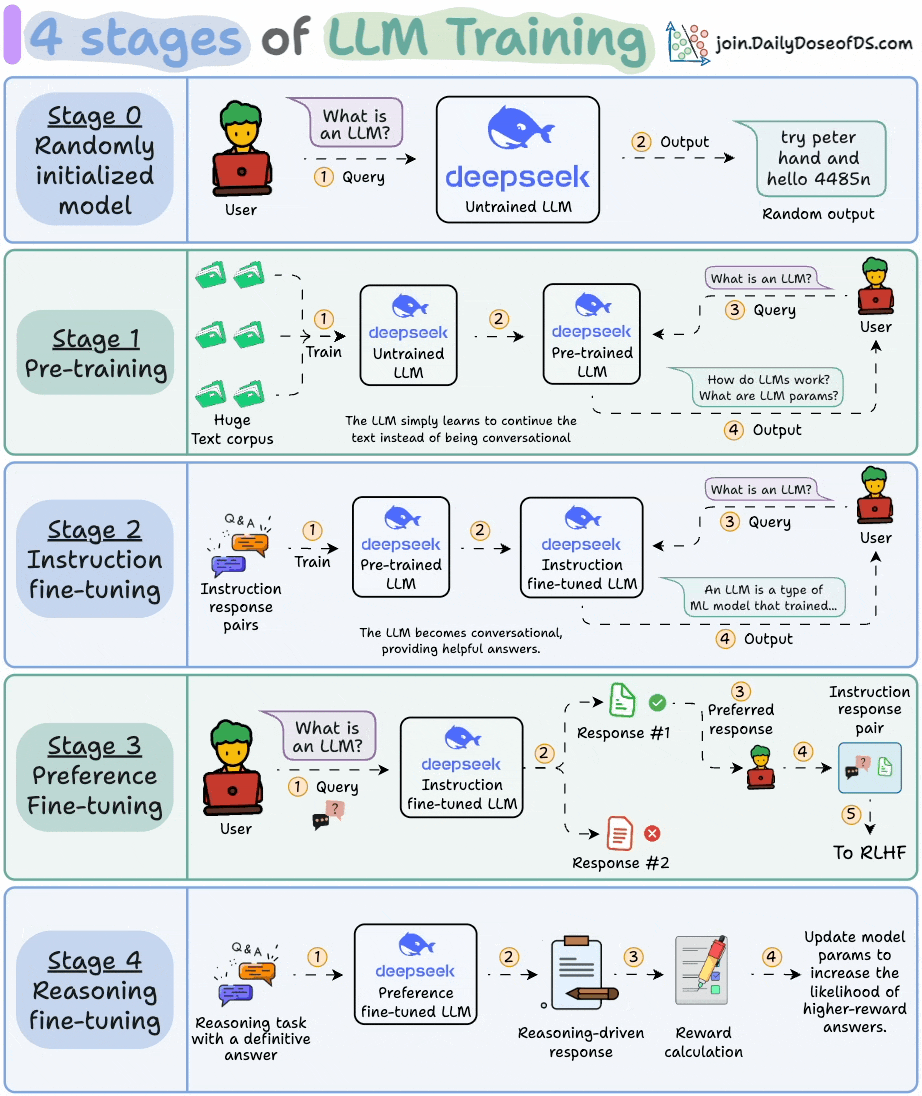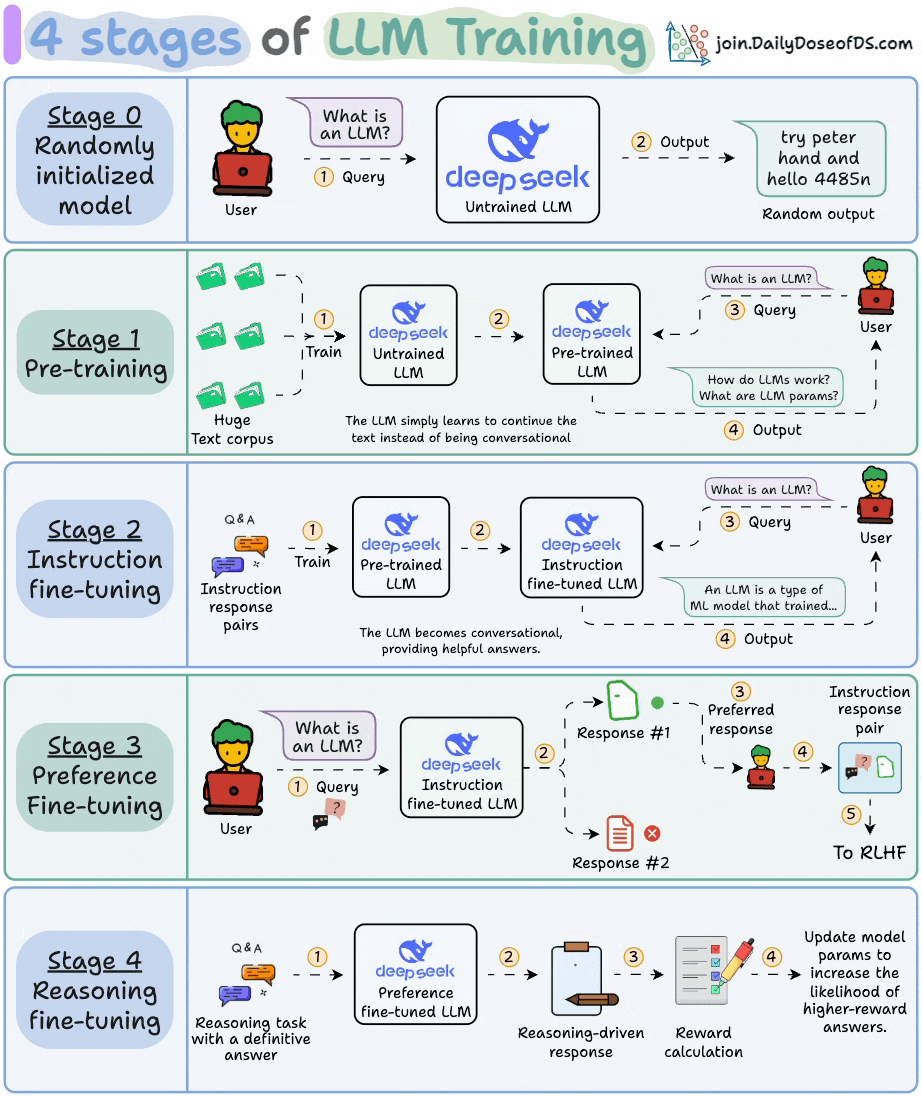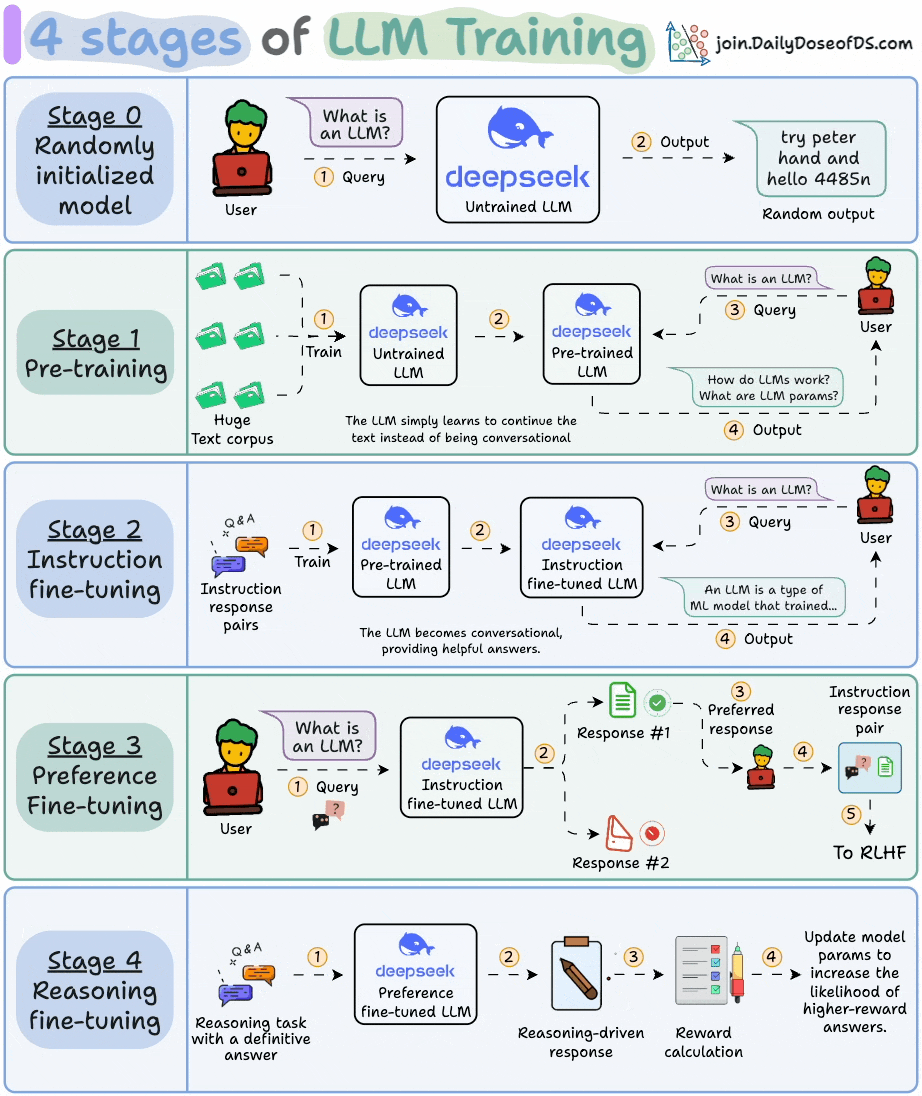
At this point, the model knows nothing.
You ask it “What is an LLM?” and get gibberish like “try peter hand and hello 448Sn”.
It hasn’t seen any data yet and possesses just random weights.

This stage teaches the LLM the basics of language by training it on massive corpora to predict the next token. This way, it absorbs grammar, world facts, etc.
But it’s not good at conversation because when prompted, it just continues the text.
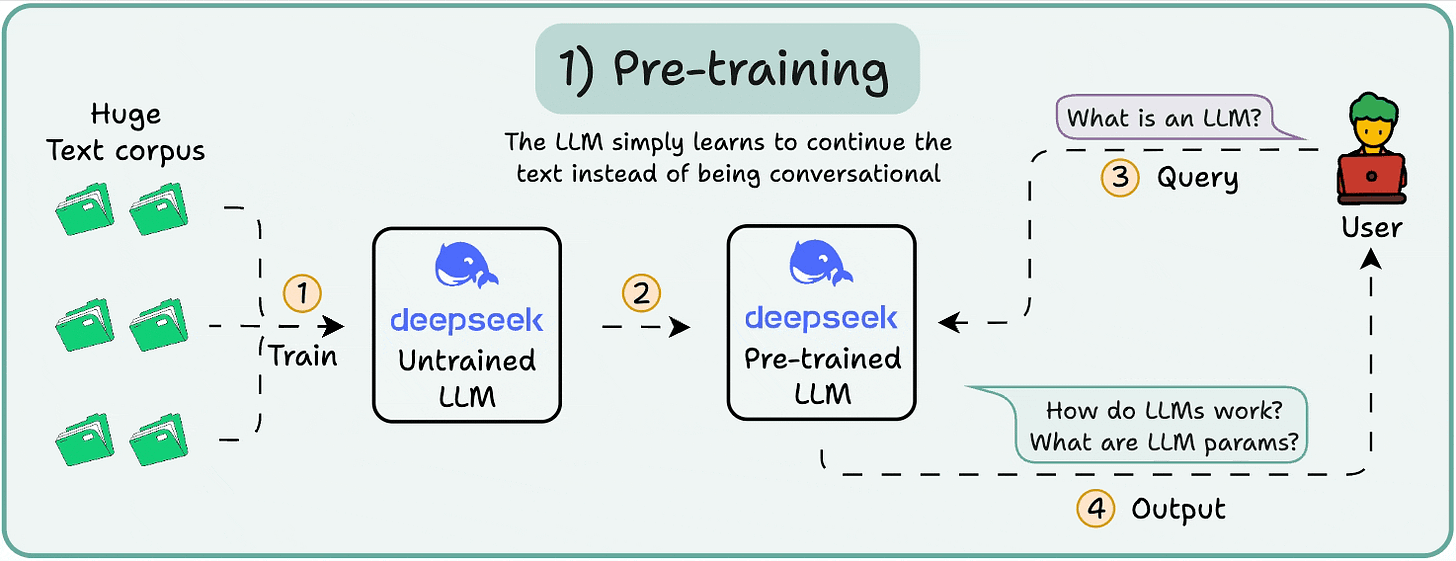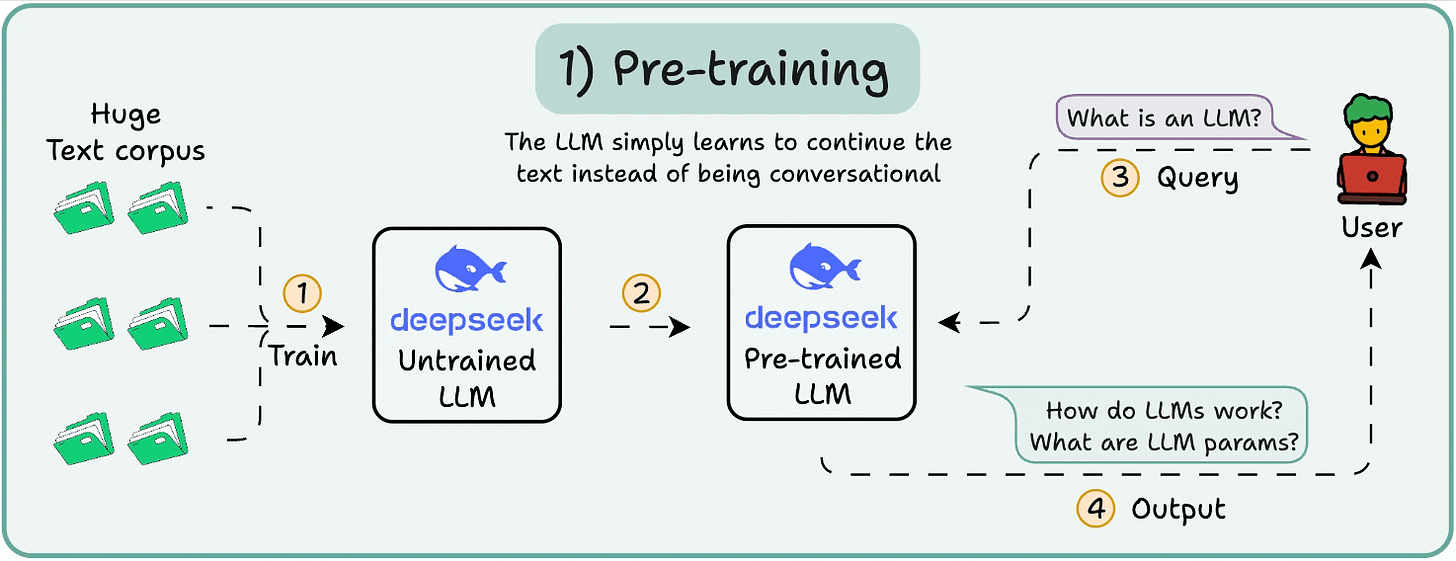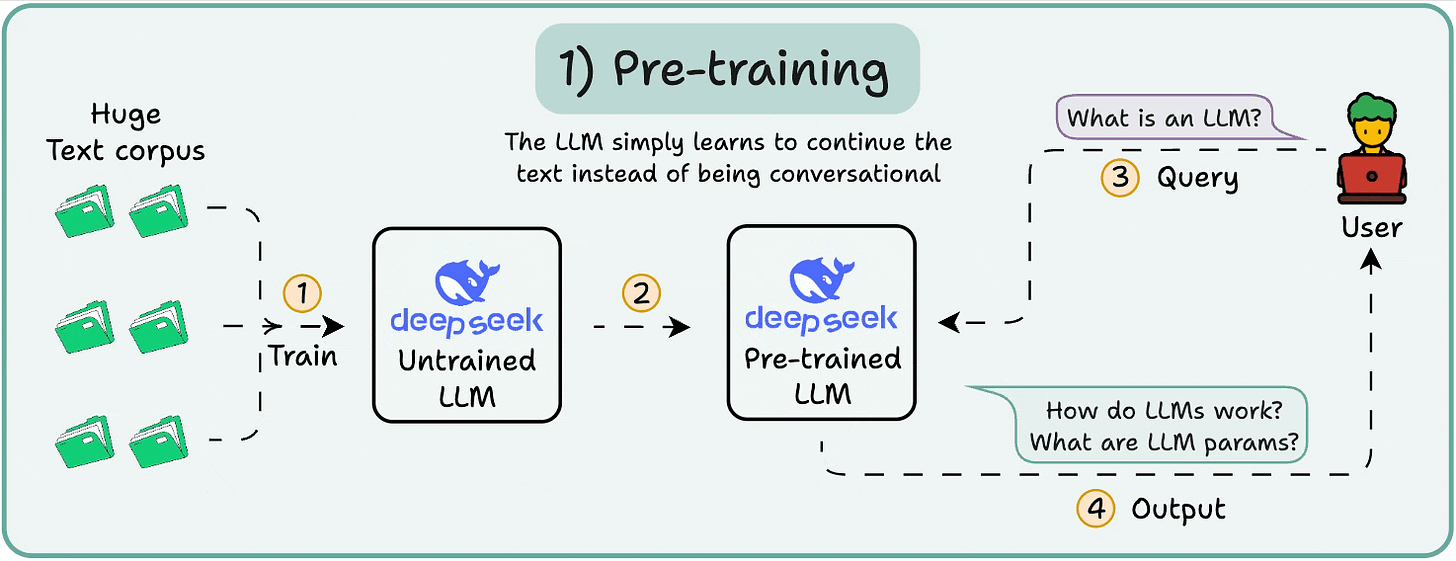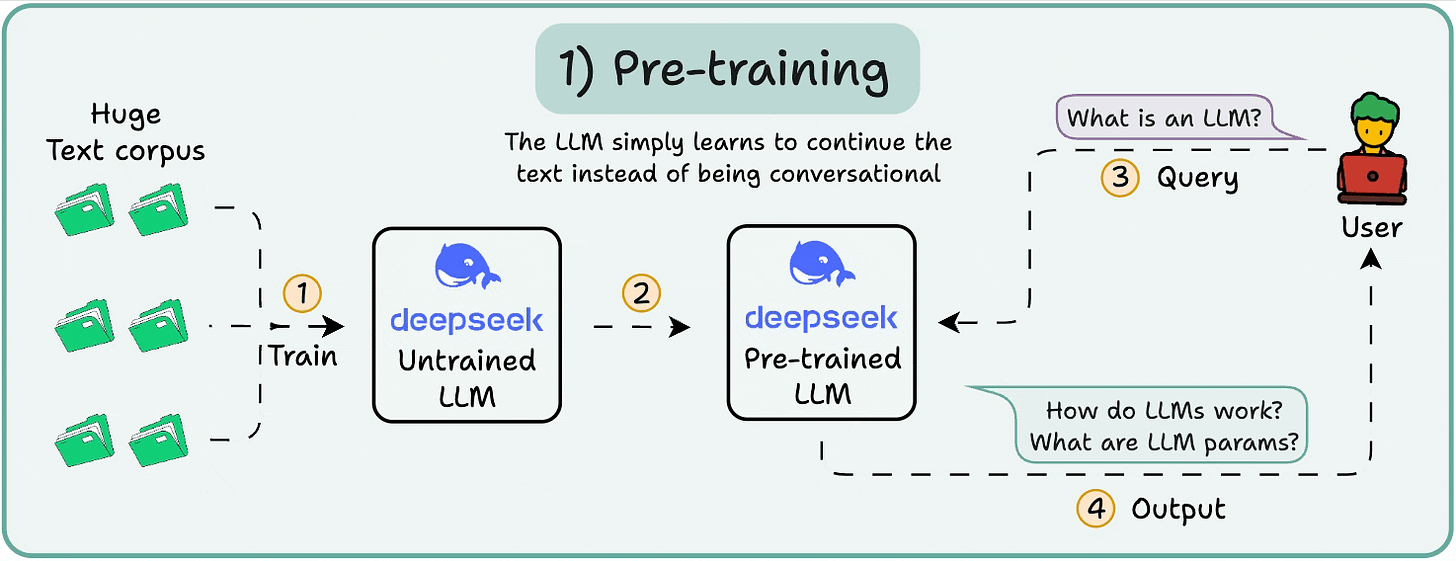
We implemented pre-training of Llama 4 from scratch here →
It covers:
To make it conversational, we do Instruction Fine-tuning by training on instruction-response pairs. This helps it learn how to follow prompts and format replies.
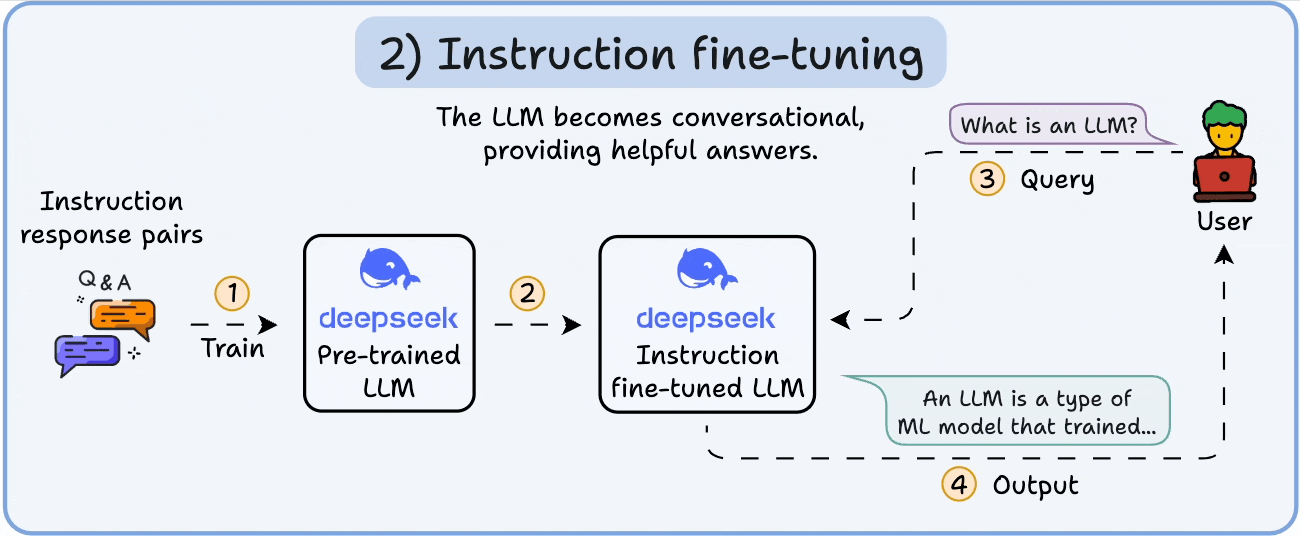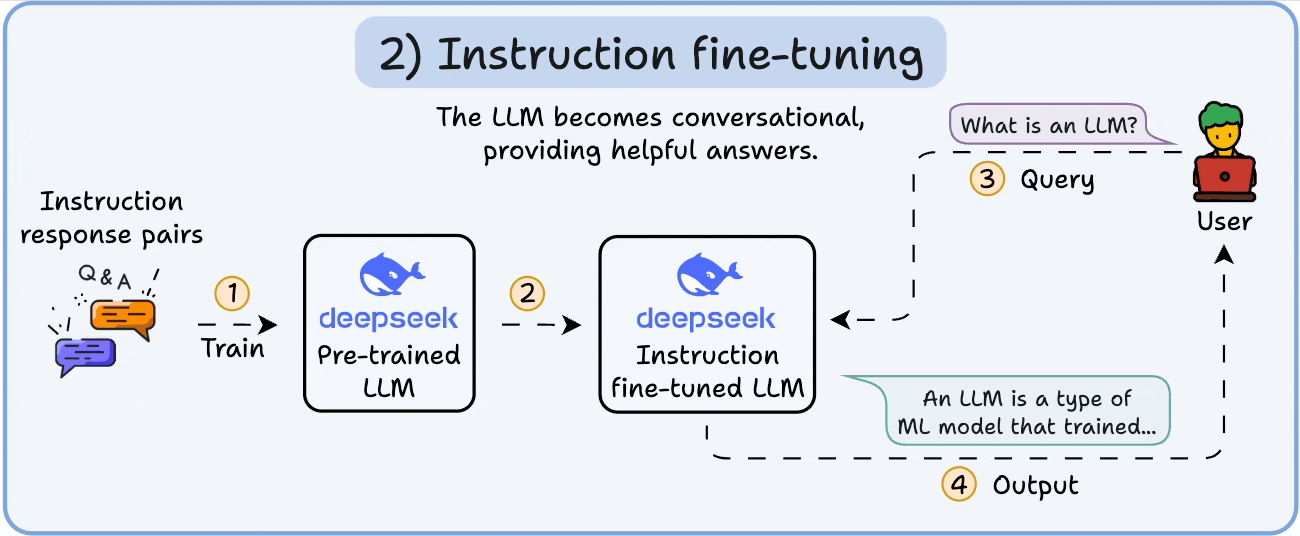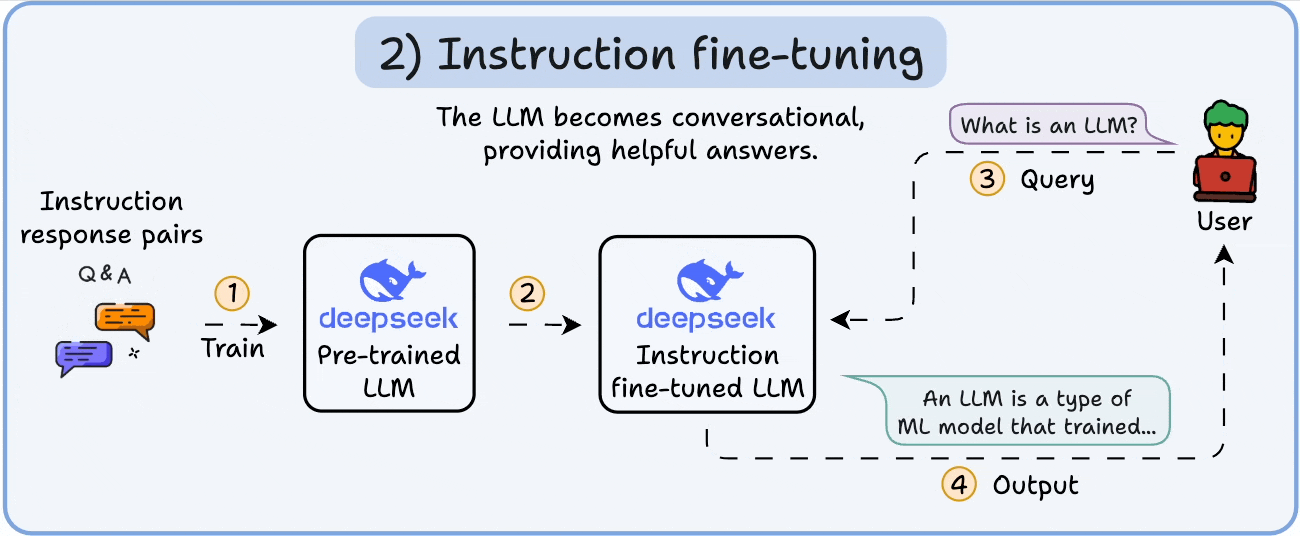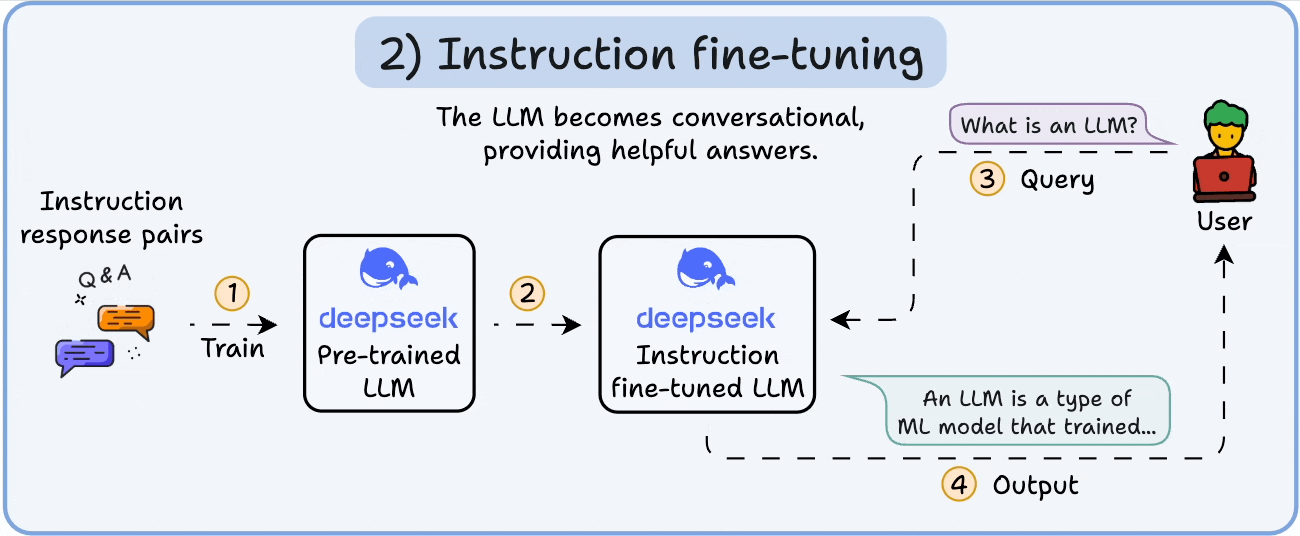
Now it can:
At this point, we have likely:
So what can we do to further improve the model?
We enter into the territory of Reinforcement Learning (RL).
You must have seen this screen on ChatGPT where it asks: Which response do you prefer?
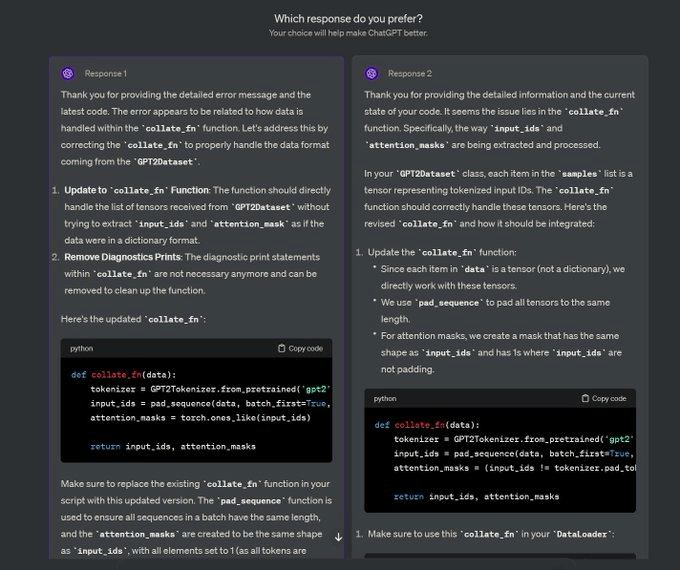
That’s not just for feedback, but it’s valuable human preference data.
OpenAI uses this to fine-tune their models using preference fine-tuning.
In PFT:
The user chooses between 2 responses to produce human preference data.
A reward model is then trained to predict human preference and the LLM is updated using RL.
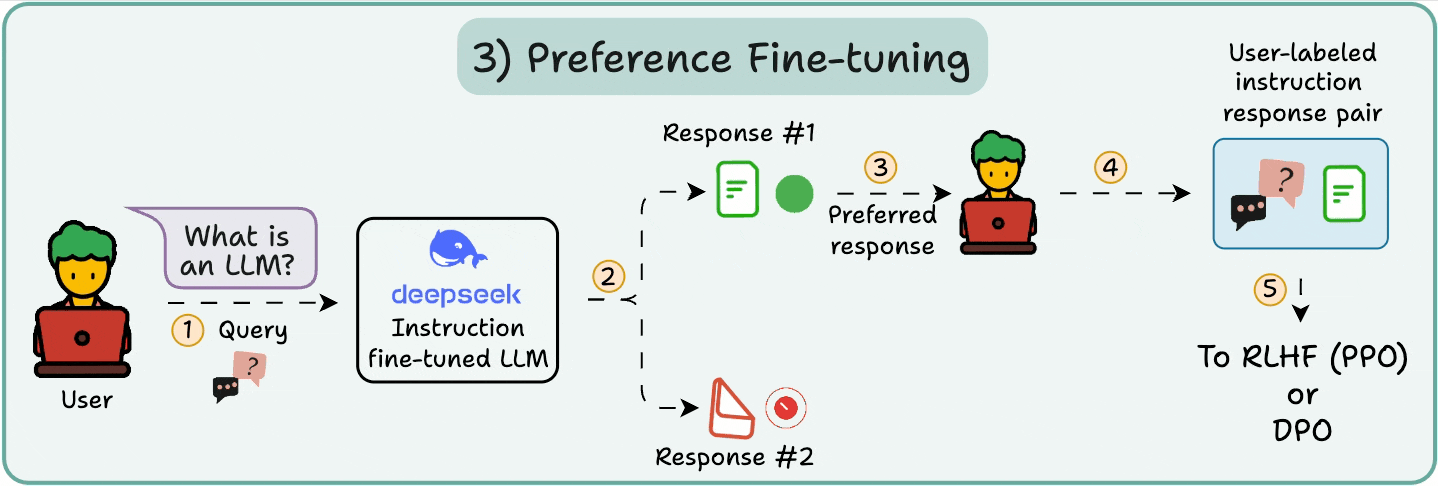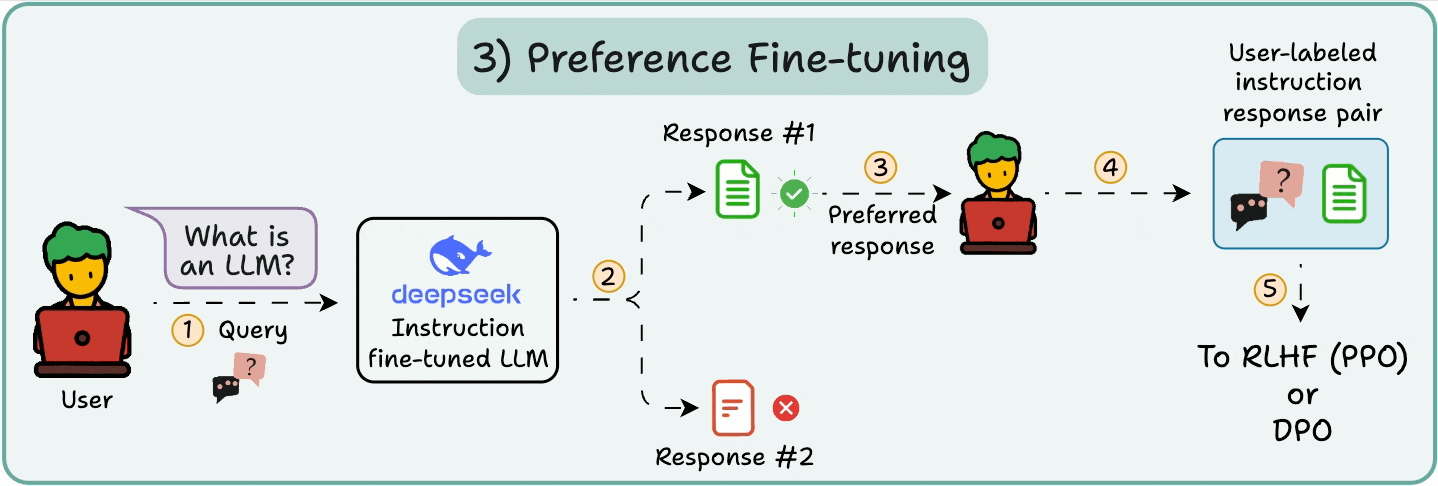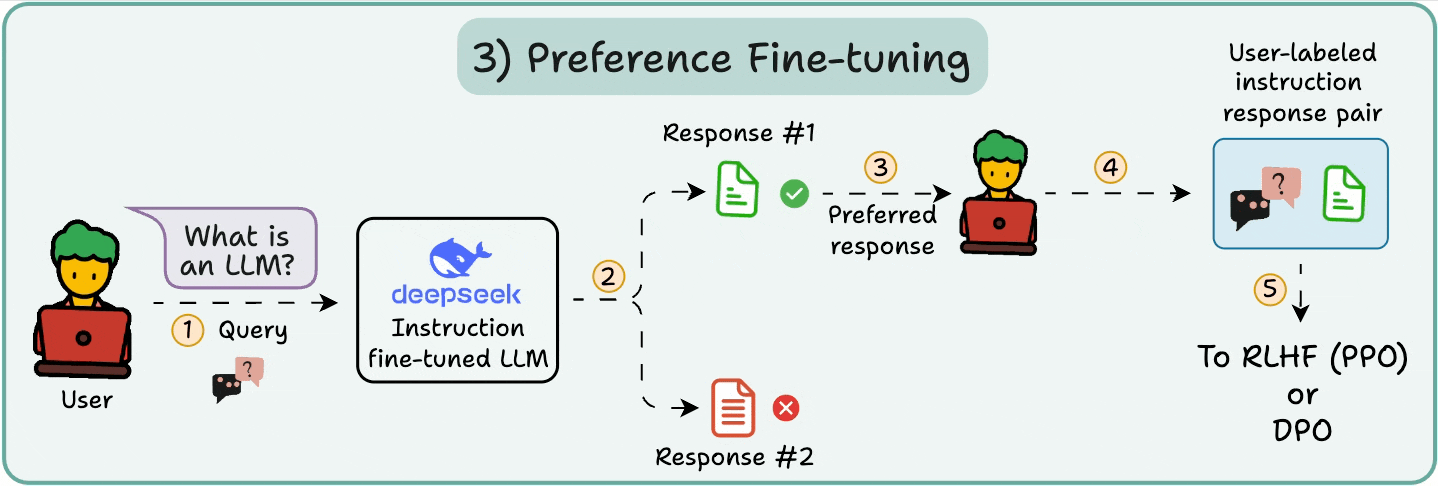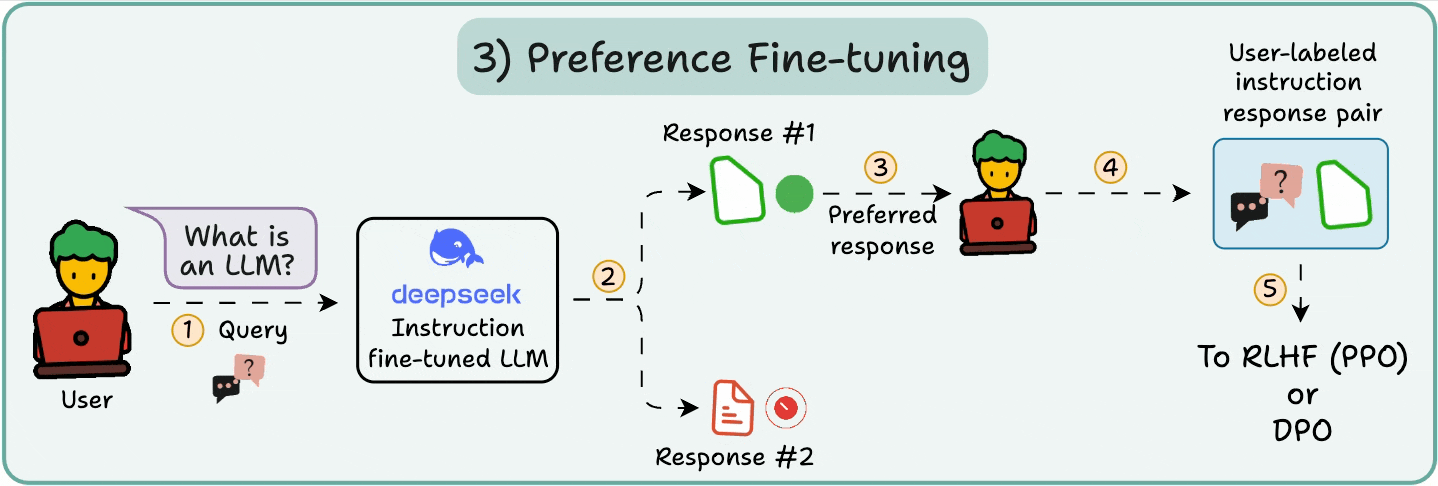
The above process is called RLHF (Reinforcement Learning with Human Feedback), and the algorithm used to update model weights is called PPO.
It teaches the LLM to align with humans even when there’s no "correct" answer.
But we can improve the LLM even more.
In reasoning tasks (maths, logic, etc.), there's usually just one correct response and a defined series of steps to obtain the answer.
So we don’t need human preferences, and we can use correctness as the signal.
This is called reasoning fine-tuning
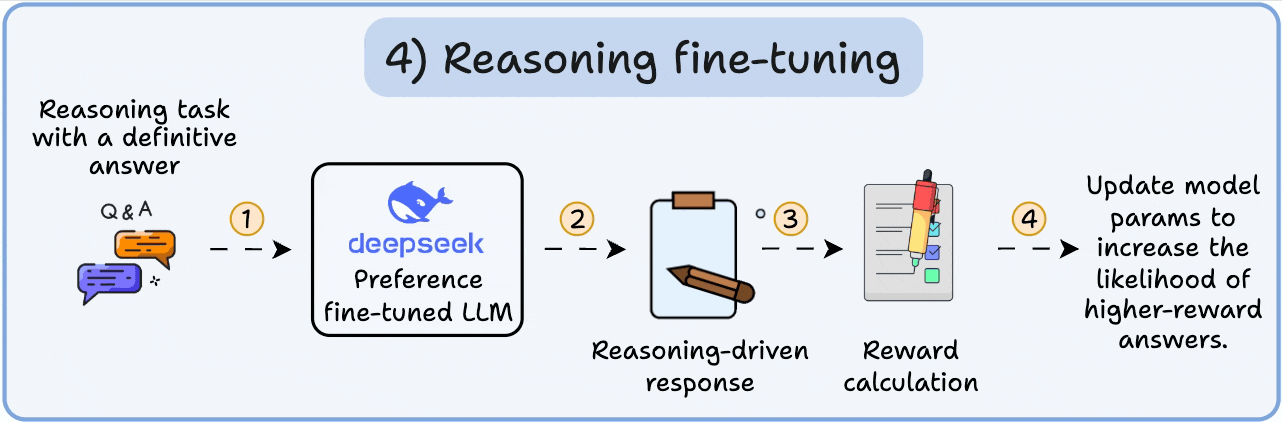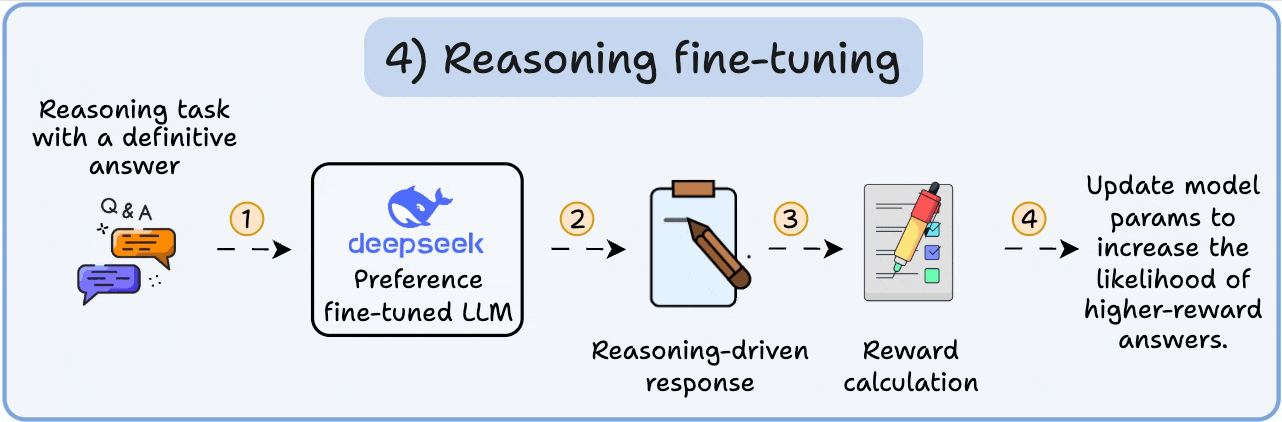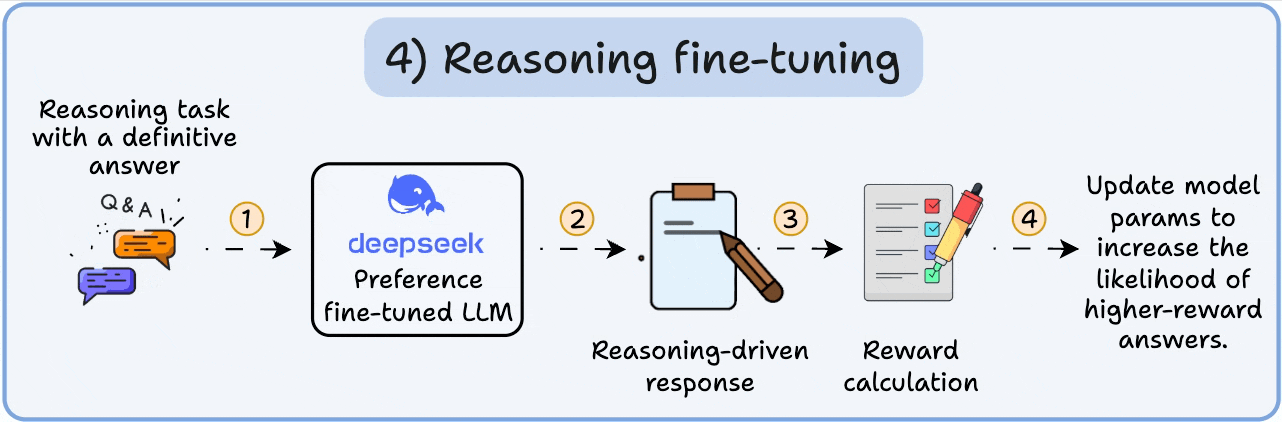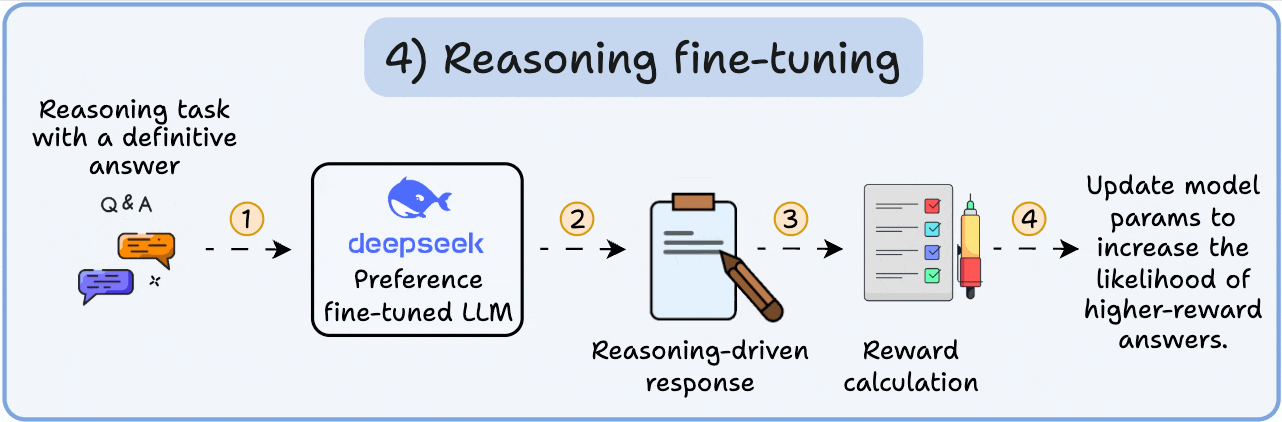
Steps:
This is called Reinforcement Learning with Verifiable Rewards. GRPO by DeepSeek is a popular technique for this.
Those were the 4 stages of training an LLM.
In a future issue, we shall dive into the specific implementation of these.
In the meantime, read this where we implemented pre-training of Llama 4 from scratch here →
It covers:
Thanks for reading!