10 Most Common Regression and Classification Loss Functions
...explained in a single frame.

Avi Chawla
...explained in a single frame.

TODAY'S ISSUE
Loss functions are a key component of ML algorithms.
They specify the objective an algorithm should aim to optimize during its training. In other words, loss functions tell the algorithm what it should minimize or maximize to improve its performance.
Therefore, being aware of the most common loss functions is extremely crucial.
The visual below depicts the most commonly used loss functions for regression and classification tasks.
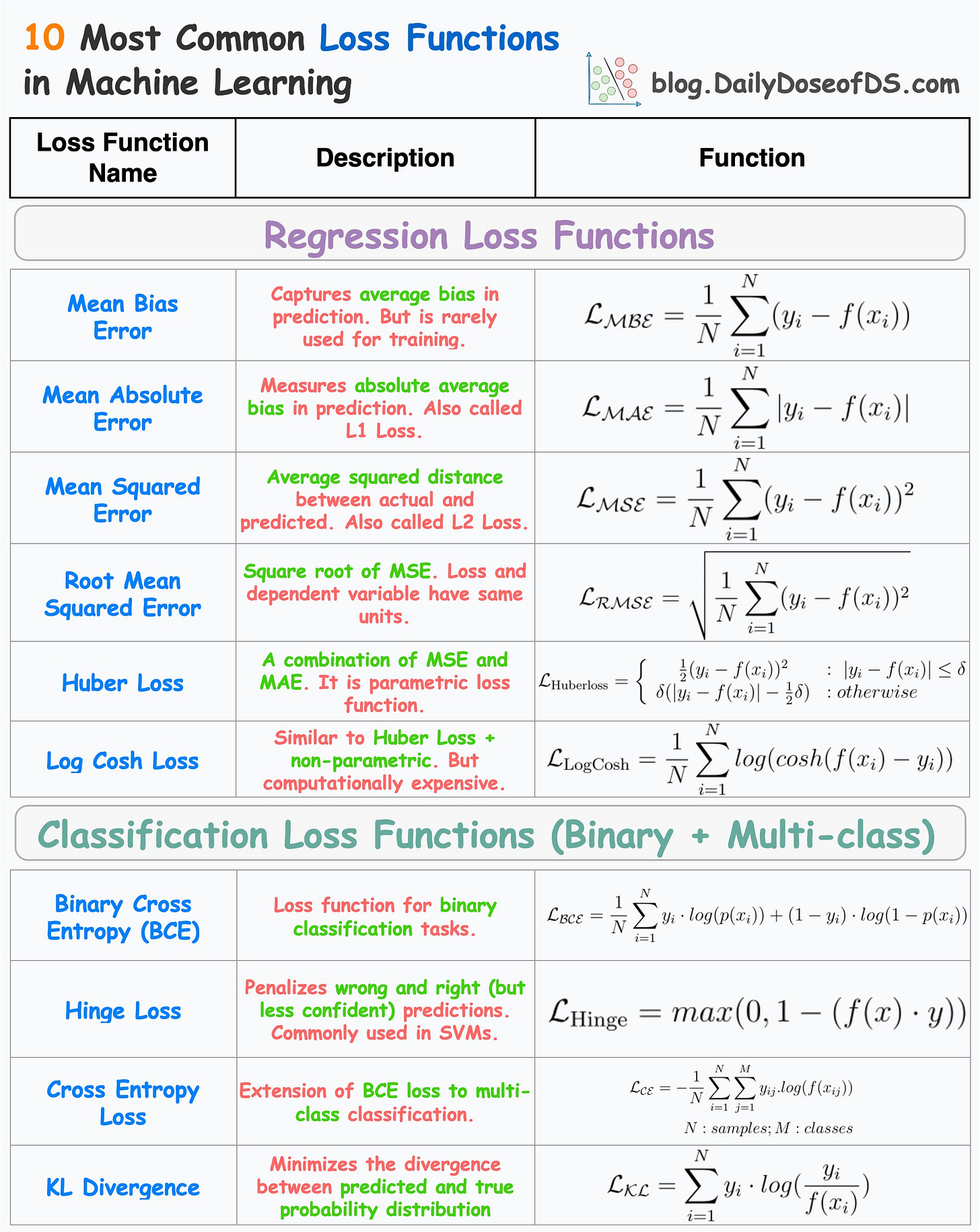
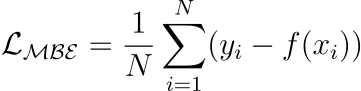
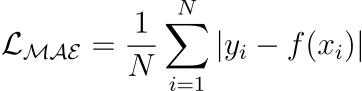
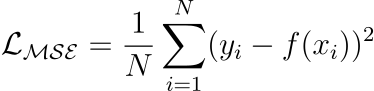
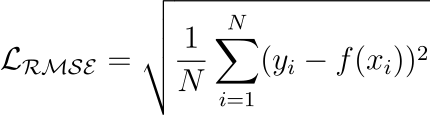
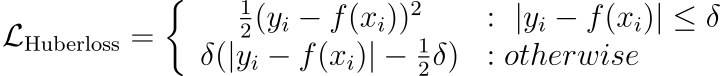
x=0).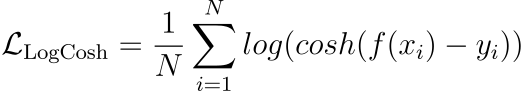
x²/2 — quadratic.|x| - log(2) — linear.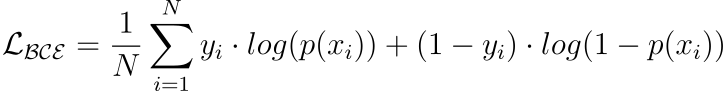
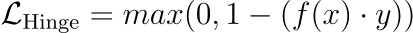
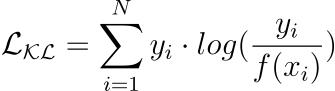
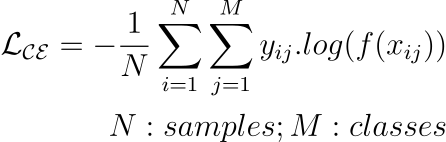
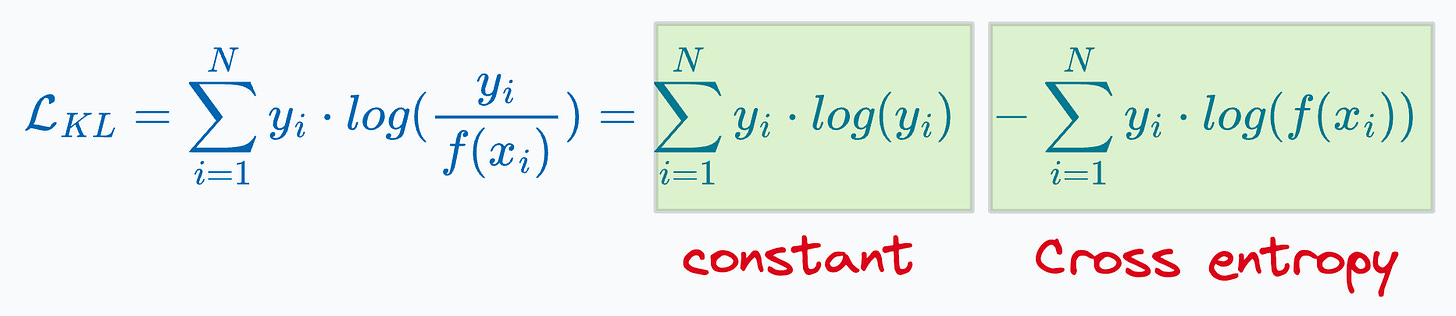
Conformal prediction has gained quite traction in recent years, which is evident from the Google trends results:
The reason is quite obvious.
ML models are becoming increasingly democratized lately. However, not everyone can inspect its predictions, like doctors or financial professionals.
Thus, it is the responsibility of the ML team to provide a handy (and layman-oriented) way to communicate the risk with the prediction.
For instance, if you are a doctor and you get this MRI, an output from the model that suggests that the person is normal and doesn’t need any treatment is likely pretty useless to you.
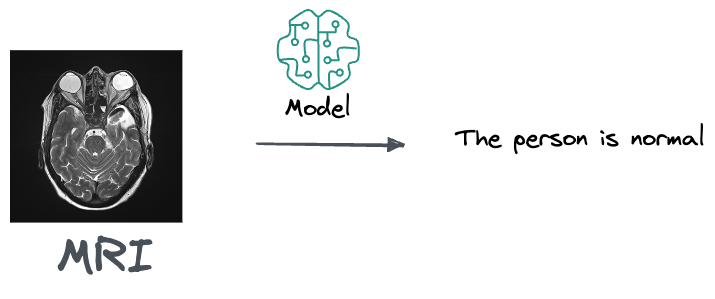
This is because a doctor's job is to do a differential diagnosis. Thus, what they really care about is knowing if there's a 10% percent chance that that person has cancer or 80%, based on that MRI.
Conformal predictions solve this problem.
A somewhat tricky thing about conformal prediction is that it requires a slight shift in making decisions based on model outputs.
Nonetheless, this field is definitely something I would recommend keeping an eye on, no matter where you are in your ML career.
Learn how to practically leverage conformal predictions in your model →
Modern neural networks being trained today are highly misleading.
They appear to be heavily overconfident in their predictions.
For instance, if a model predicts an event with a 70% probability, then ideally, out of 100 such predictions, approximately 70 should result in the event occurring.
However, many experiments have revealed that modern neural networks appear to be losing this ability, as depicted below:
Calibration solves this.
A model is calibrated if the predicted probabilities align with the actual outcomes.
Handling this is important because the model will be used in decision-making and an overly confident can be fatal.
To exemplify, say a government hospital wants to conduct an expensive medical test on patients.
To ensure that the govt. funding is used optimally, a reliable probability estimate can help the doctors make this decision.
If the model isn't calibrated, it will produce overly confident predictions.
There has been a rising concern in the industry about ensuring that our machine learning models communicate their confidence effectively.
Thus, being able to detect miscalibration and fix is a super skill one can possess.
Learn how to build well-calibrated models in this crash course →